☞ ░ 前往老猿Python博客 ░ https://blog.csdn.net/LaoYuanPython
一、简介
在 VS Code 中,tasks.json 文件中的 problemMatcher 字段用于定义如何解析任务输出中的问题(错误、警告等)。
problemMatcher有三种配置方式,具体可参考《VSCode中的任务什么情况下需要配置多个问题匹配器problemMatcher?多个问题匹配器之间的关系是什么?》的介绍。
本文要介绍的是problemMatcher为一个ProblemMatcher的JSON对象时其下的子对象pattern,pattern用于匹配任务执行时输出的信息,如编译任务输出的告警和错误信息,对符合pattern指定匹配规则的信息则纳入problemMatcher处理。
二、测试的C++代码文件样例
为了测试vscode的问题匹配,下面是一个故意存在多处错误的hello.cpp文件的代码,注意就是一个完整的cpp文件,不存在单独的头文件和其他外部文件:
#include <stdio.h>
#include <stdlib.h>
#include "myhead.h"int main()
{int loop;int i,j;printf("j=%s\n",j);for(loop=0;loop<5;loop++)printf("hello,world!%d\n",i);i++;hell(""); }
大家看得出来几处问题代码吗?
三、问题匹配器中的模式pattern介绍
3.1、vscode中pattern的定义
pattern在vscode中 的定义如下:
pattern: string | ProblemPattern | ProblemPattern[]
关于这个定义,官方文档中有如下说明:The name of a predefined problem pattern, the inline definition of a problem pattern or an array of problem patterns to match problems spread over multiple lines,结合上述定义和文字说明可知,pattern可以为字符串、ProblemPattern类型对象和ProblemPattern数组:
- pattern为字符串的情况,vscode官方说是预定义的匹配模式,老猿查阅了很多资料,也许是统信下的vscode版本1.81.0太低,也许是没找对方法,在vscode1.81.0中反复测试也没有测试通过;
- pattern 为 ProblemPattern类型的对象时,包含有多个子对象,在接下来的3.2节中详细介绍其相关信息;
- pattern 为 ProblemPattern类型的数组时,表明其所在的问题匹配器的匹配模式可以有多种,这些匹配模式按照配置中的先后顺序逐一与输出信息匹配,如果都匹配成功,则整个问题匹配成功,否则就是未匹配,即多个匹配模式是与的关系,这个与问题匹配器problemMatcher多个之间是或的关系是不同的。查阅了vscode的官方文档,这种模式数组是用于匹配多行。不过关于此模式老猿一直未能测试成功,3.3节再介绍测试情况。
3.2、ProblemPattern类型介绍
3.2.1、ProblemPattern类的定义
以下是vscode官方文档中关于ProblemPattern类的定义:
interface ProblemPattern {/** The regular expression to find a problem in the console output of an* executed task.*/regexp: string; /*** Whether the pattern matches a problem for the whole file or for a location* inside a file.* Defaults to "location". */kind?: 'file' | 'location';/*** The match group index of the filename. */file: number;/*** The match group index of the problem's location. Valid location* patterns are: (line), (line,column) and (startLine,startColumn,endLine,endColumn).* If omitted the line and column proper从上面官方文档的介绍可以知道,ProblemPattern包含多个子元素,下面分每个子元素展开介绍。从以上定义的英文注释能理解大部分定义要素的含义,但有些光理解注释的字面意思还不够,老猿结合测试情况对这些ties are used. */location?: number;/** * The match group index of the problem's line in the source file.* Can only be omitted if location is specified. */line?: number;/**The match group index of the problem's column in the source file. */column?: number;/** * The match group index of the problem's end line in the source file.* Defaults to undefined. No end line is captured. */endLine?: number;/** * The match group index of the problem's end column in the source file.** Defaults to undefined. No end column is captured. */endColumn?: number;/*** The match group index of the problem's severity.* Defaults to undefined. In this case the problem matcher's severity* is used. */severity?: number;/*** The match group index of the problem's code.* Defaults to undefined. No code is captured.*/code?: number;/*** The match group index of the message. Defaults to 0. */message: number;/*** Specifies if the last pattern in a multi line problem matcher should* loop as long as it does match a line consequently. Only valid on the* last problem pattern in a multi line problem matcher. */loop?: boolean;
}
3.2.2 ProblemPattern类型的介绍
从上面官方文档的介绍可以知道,ProblemPattern包含多个子元素,从以上定义的英文注释能理解大部分定义要素的含义,但有些光理解注释的字面意思还不够,老猿结合测试情况对这下面分每个子元素展开介绍。
3.2.2.1、 regexp
3.2.2.1.1、regexp概述
regexp对应为匹配输出问题信息的正则表达式,正则表达式使用的元字符与Python的re模块基本一致,如元字符包括:“.*?[]{}[]\+-^$”等,转义符为"\",同时支持转义符定义的特殊序列以及组匹配模式,支持通过组序号方式来访问匹配内容,需要注意转义符在字符串中需要使用双斜杠。关于Python正则表达式的有关介绍请参考老猿在CSDN的博文专栏《Python 支撑正则表达式处理的re模块》。
3.2.2.1.2、regexp正则表达式中常用的元字符及含义
regexp正则表达式中部分常用元字符及其含义:
- ^:匹配字符串的开头
- \s*:匹配零个或多个空格字符
- (.*):匹配任意字符,零个或多个 字符
- (\d+):匹配一个或多个数字字符
- \s+:匹配一个或多个分隔字符 (如空格、回车、tab等)
- (子正则表达式):用于将指定正则匹配的内容进行分组
案例:"^(.*):(\\d+):(\\d+):\\s+(error):\\s+(.*)$"
这个正则语句匹配如下类似的错误信息:hello.cpp:3:10: error: myhead.h: 没有那个文件或目录,其中文件名的匹配组号为1、行号匹配组号位2、列号的匹配组号为3,匹配的问题级别信息“error”的匹配组号为4,具体错误信息匹配组号为5
3.2.2.2、kind
指问题匹配时匹配到问题具体的行列位置还是只需要匹配到文件,有2个取值,一个是“file”,表示只需要匹配到文件,另一个是“location”,匹配到行列指定的具体位置,缺省值是“location”。
我们通过案例来看看问题面板输出的不同,以上面hello.cpp的爆粗信息:hello.cpp:3:10: fatal error: myhead.h: 没有那个文件或目录为例:
- 设置为“location”,问题面板中输出信息文件那栏输出了文件名、行号、列号,如图:

注意,零两个问题不是问题匹配器problem_1输出的,而是扩展组件C++智能感知输出的。 - 设置为“file”,问题面板中输出信息文件那栏输出了文件名、行号、列号,不过行号、列号固定为1,如图:

3.2.2.3、file、line、column
在正则表达式匹配输出信息时识别出来的文件名的匹配组号,有关正则知识请参考老猿在CSDN上《Python基础教程》下的博文《第11.16节 Python正则元字符“()”(小括号)与组(group)匹配模式》的相关介绍。
按照:
案例正则表达式:"^(.*):(\\d+):(\\d+):\\s+(error):\\s+(.*)$"
对错误信息:hello.cpp:3:10: error: myhead.h: 没有那个文件或目录
进行匹配,file的匹配组号为1,即第一个括号内匹配到的内容为文件名,类似的line、column为匹配到错误位置行号、列号的匹配组号,在上面例子中分别对应组号2和3。
3.2.2.4、endLine、endColumn
endLine、endColumn与line、column类似,不过有些代码的编译构建程序会输出错误代码的起止行号和列号,line、column匹配开始行号和列号,而endLine、endColumn匹配终止行号和列号。C++的编译器没有输出相关信息,因此无需配置。
3.2.2.5、severity
问题输出信息中匹配到的问题级别的匹配组号,在上面的例子中就是(error)这个匹配信息对应的匹配组号。problemMatcher和ProblemPattern都存在“severity”的属性,ProblemPattern又是problemMatcher的子属性,二者的“severity”属性关系请见《VSCode任务tasks.json中的问题匹配器problemMatcher和ProblemPattern的severity属性关系》的分析,相关情况请参考本文后面的测试情况说明。
3.2.2.6、code
用于设置正则表达式匹配问题报错信息中给出的错误源代码的匹配组号,在C++中的报错信息中存在有源代码信息,但是在报错信息后面单独一行输出,由于涉及多行匹配,老猿一直无法验证成功。
没测试成功的原因可能有3个:
- vscode的版本过低,因为老猿使用的是国产操作系统,安装的vscode的版本是1.81.0,而windows下已经至少是1.20.0的版本了;
- 多行问题匹配器不适合C++的编译错误信息,可能在别的语言构建时可以;
- 老猿的配置方法不对。
老猿觉得前面两个原因的可能性占多数,因为老猿做了很多测试都无法支持多行输出信息的处理,详细请见博文下面的介绍。
3.2.2.7、message
用于设置正则表达式匹配问题报错信息中给出的具体错误信息的匹配组号,如果没有配置或配置为0,默认就是包含文件名等在内的整个问题信息。
3.2.2.8、loop
loop这个属性老猿仅从字面理解了,是指定多行问题匹配器中的最后一个模式是否应循环,只要它与一行匹配即可,仅对多行问题匹配器中的最后一个问题模式有效。老猿理解为多行问题信息匹配需要多个匹配器来匹配多行的信息,如果loop为true,则只要这个问题匹配器匹配到任意一行的输出信息即可。
因为涉及多行匹配,与code属性一样,用C++程序测试时没有测试通过,因此也不知道理解是否正确。
四、问题匹配器的一些测试案例及结果介绍
4.1、编译hello.cpp的tasks.json的基本配置
下面是老猿使用的编译hello.cpp的tasks.json的基本配置:
{"version": "2.0.0","tasks": [{"type": "cppbuild","label": "C/C++: g++ 生成活动文件","command": "/usr/bin/g++","args": ["-fdiagnostics-color=always","-g","-Wall","-Wextra","-O0","${workspaceFolder}/hello.cpp","-o","${fileDirname}/${fileBasenameNoExtension}"],"options": {"cwd": "${fileDirname}"},"problemMatcher": [ "$gcc"],"group": {"kind": "build","isDefault": true},"detail": "编译器: /usr/bin/g++"}]
}
这是初始配置,问题匹配器用的是预定义的$gcc。用该配置编译上述hello.cpp时,在终端窗口输出的错误信息如下:
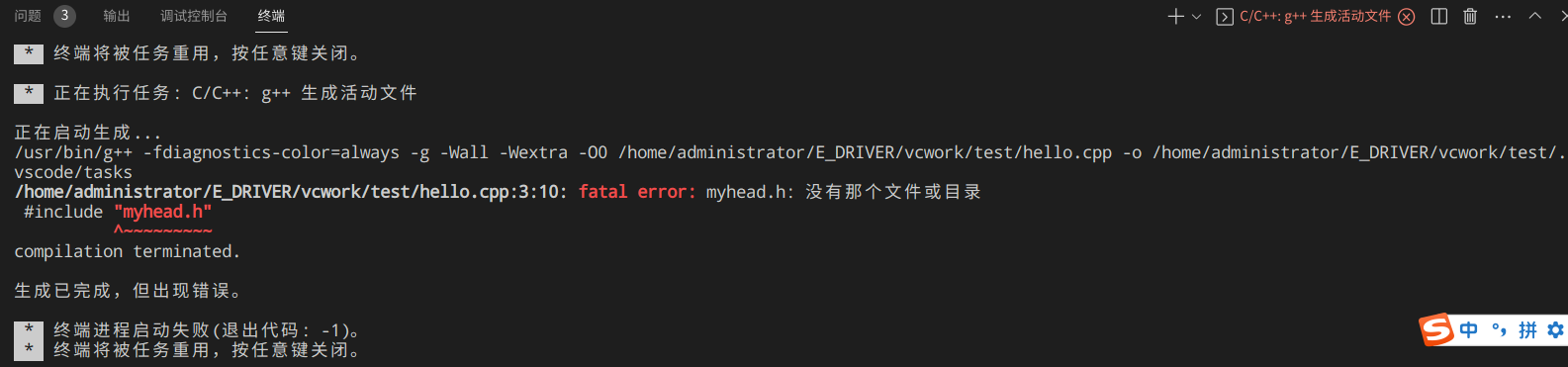
目前看到仅一个报错:“/home/administrator/E_DRIVER/vcwork/test/hello.cpp:3:10: fatal error: myhead.h: 没有那个文件或目录”,这是因为遇到了致命错误,所以没有继续往下执行编译。下面是此时在问题控制面板的输出信息:

可以看到输出了三个error级别的错误信息,其中前2个是VSCODE的C++插件IntelliSense输出的,第三个是cpptools输出的,实际上就是上面配置的问题匹配器$gcc输出的。
4.2、测试新增一个问题匹配器以及problemMatcher和ProblemPattern的severity属性关系
修改问题匹配器配置如下:
"problemMatcher": [ {"owner": "problem_1","severity": "warning","fileLocation": "absolute","pattern": {"regexp": "^(.*):(\\d+):(\\d+):\\s+(fatal).*:\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 5}}, "$gcc"]
注意该问题匹配器的配置有如下要点:
- problemMatcher."severity"的值为 “warning”;
- pattern."severity"的值为4,对应regexp的第4个匹配组号,对应匹配内容为
(fatal); - 配置了2个问题匹配器,分别是自定义的
problem_1和预定义的$gcc。
这样配置后,执行生成构建任务后,问题面板的输出信息如下:

可以看到:
- 原来基本配置显示的最左边的严重级别图标为error,修改问题匹配器后显示为warning对应的图标;
- 问题来源显示为新配置的problem_1;
- 错误信息由原来的“myhead.h: 没有那个文件或目录”变成了“没有那个文件或目录”。
结合上述问题匹配器大家去理解一下为什么会有这些变化,有疑问在评论区提问。
通过这个配置可以说明如下情况:
- problemMatcher的severity属性优先ProblemPattern的severity属性;
- 多个问题匹配器是按顺序匹配的,匹配到一个后面的不再匹配。
4.3、去除problemMatcher的severity配置场景
将自定义的问题匹配器的problemMatcher的severity属性配置注释掉,同时将message的匹配组号调整为4,与pattern."severity"的值相同,配置如下:
"problemMatcher": [ {"owner": "problem_1",// "severity": "warning","fileLocation": "absolute","pattern": {"regexp": "^(.*):(\\d+):(\\d+):\\s+(fatal).*:\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 4}}, "$gcc"],
可以看到执行构建任务时,问题面板输出内容如下:

可以看到输出的消息变为:fatal,问题严重级别图标变为error,相关结论大家可以参考《VSCode任务tasks.json中的问题匹配器problemMatcher和ProblemPattern的severity属性关系》的介绍。
4.3、新增两个定制化的problemMatcher配置场景
4.3.1、测试背景说明
由于测试代码中的#include "myhead.h"存在致命错误,导致编译程序无法往下执行,为了测试本场景,要求本次测试的代码是注释或去除了该行代码,此时编译报错信息为:
hello.cpp:10:12: warning: format ‘%s’ expects argument of type ‘char*’, but argument 2 has type ‘int’ [-Wformat=]printf("j=%s\n",j);^~~~~~~~ ~
hello.cpp:14:5: error: ‘hell’ was not declared in this scopehell("");^~~~
hello.cpp:14:5: note: suggested alternative: ‘ftell’hell("");^~~~ftell生成已完成,但出现错误。* 终端进程启动失败(退出代码: -1)。
4.3.2、测试的问题匹配器配置
配置了三个问题匹配器,分别是problem_error、problem_warning和预定义的gcc,三个问题匹配器本身都没有配置severity属性。具体配置如下:
"problemMatcher": [ {"owner": "problem_error","fileLocation": "absolute","pattern": {"regexp": "^(.*):(\\d+):(\\d+):\\s+(.*error).*:\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 5}}, {"owner": "problem_warning","fileLocation": "absolute","pattern": {"regexp": "^(.*):(\\d+):(\\d+):\\s+(.*warning|note).*:\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 5}}, "$gcc"]
进行编译构建后,输出问题面板内容如下:
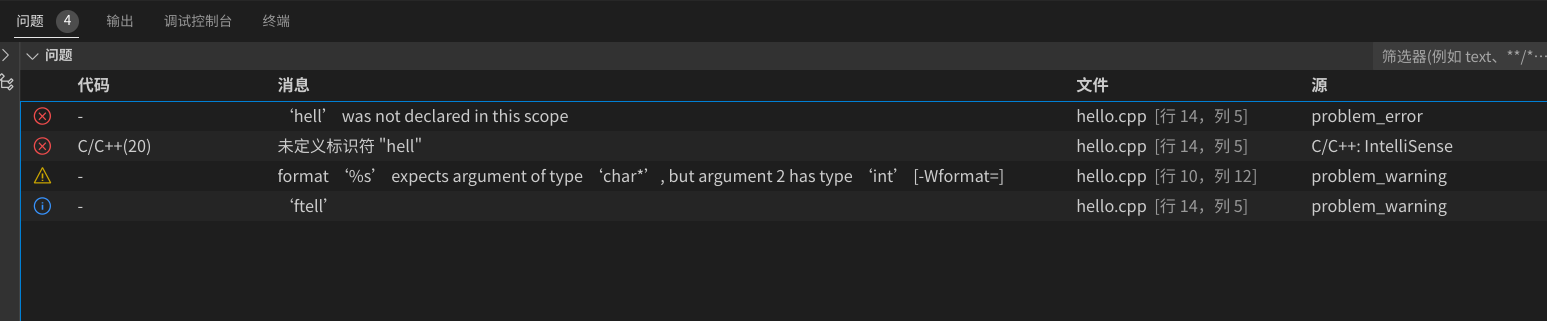
可以看到输出了4个问题,其中一个是C++ InelliSense输出的,其他三个是自定义问题匹配器输出的,大家应该可以理解输出信息为什么是这样吧?特别是最后一个显示的信息为什么是‘ftell’?不理解的在评论区提问吧。
4.4、测试捕获输出了源代码的问题
将问题匹配器换成如下:
"problemMatcher": [ {"owner": "problem_code","fileLocation": "absolute","pattern": {"regexp": "^.*(printf).*$","file":1,"message": 1 }}, "$gcc"]
该问题匹配器试图匹配输出信息存在printf的语句,但经测试该问题匹配器无法捕获到问题,具体原因未知,如果有哪位大佬可以解惑,欢迎在评论区留言,老猿感激不尽。
4.5、测试捕获多行问题信息
将问题匹配器改成如下:
"problemMatcher": [ {"owner": "problem_multiline","fileLocation": "absolute","pattern": [ {"regexp": "^(.*):(\\d+):(\\d+):\\s+(warning|note|error):\\s+(.*)$","file": 1,"line": 2,"column": 3,"severity": 4,"message": 5},{"regexp": "(.*)","file":1,"message": 1,"loop":true}]}, "$gcc"]
上面的问题匹配器数组包含了两个问题匹配器,一个自定义的problem_multiline,一个gcc,其中problem_multiline配置了两个ProblemPattern问题模式。运行编译任务后,可以看到问题面板输出信息如下:

这个输出结果可以看到,针对note的告警信息,匹配了problem_multiline这个问题匹配器,其他的问题输出信息都没有匹配到problem_multiline,匹配到的问题匹配器的输出信息感觉是两个ProblemPattern对note所在的首行输出信息进行匹配之后叠加一起作为message输出,为什么这样老猿也没搞懂,欢迎各位大佬指教。
五、小结
本文介绍了VSCode任务tasks.json中的问题匹配器problemMatcher的配置项问题匹配模式ProblemPattern,包括官方定义以及老猿对每个ProblemPattern子对象的解读,有些内容是老猿测试验证后独家公布,同时对相关知识老猿也存在多处没有理解的地方,在正文中都以加粗字体显示,期待各位大佬指导。
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
更多关于vscode使用方面的问题的内容请参考专栏《国产信创之光》的相关文章。
关于老猿的付费专栏
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_9607725.html 使用PyQt开发图形界面Python应用》专门介绍基于Python的PyQt图形界面开发基础教程,对应文章目录为《 https://blog.csdn.net/LaoYuanPython/article/details/107580932 使用PyQt开发图形界面Python应用专栏目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10232926.html moviepy音视频开发专栏 )详细介绍moviepy音视频剪辑合成处理的类相关方法及使用相关方法进行相关剪辑合成场景的处理,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/107574583 moviepy音视频开发专栏文章目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10581071.html OpenCV-Python初学者疑难问题集》为《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的伴生专栏,是笔者对OpenCV-Python图形图像处理学习中遇到的一些问题个人感悟的整合,相关资料基本上都是老猿反复研究的成果,有助于OpenCV-Python初学者比较深入地理解OpenCV,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/109713407 OpenCV-Python初学者疑难问题集专栏目录 》
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10762553.html Python爬虫入门 》站在一个互联网前端开发小白的角度介绍爬虫开发应知应会内容,包括爬虫入门的基础知识,以及爬取CSDN文章信息、博主信息、给文章点赞、评论等实战内容。
前两个专栏都适合有一定Python基础但无相关知识的小白读者学习,第三个专栏请大家结合《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的学习使用。
对于缺乏Python基础的同仁,可以通过老猿的免费专栏《https://blog.csdn.net/laoyuanpython/category_9831699.html 专栏:Python基础教程目录)从零开始学习Python。
如果有兴趣也愿意支持老猿的读者,欢迎购买付费专栏。
老猿Python,跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░
VSCODE的tasks.json的problemMatcher的子配置项patternMatcher可以有哪些下级子配置项,其用途分别是什么?
在VSCode的tasks.json文件中,problemMatcher是一个关键配置项,它可以确定问题面板中显示的内容。特别要注意的是,它的子属性patternMatcher可以进一步定义问题的匹配规则。
patternMatcher的属性值可以是以下几种:
“default”: {}:使用默认的匹配规则。
“strict”: {}:使用严格的匹配规则,只有完全匹配的问题才会显示。
“off”: {}:关闭问题匹配功能,不显示任何问题。
“word”: /\b(?:if|else|while|for)\b/g:针对特定的关键词进行匹配,这里的示例是针对C++中的if、else、while和for等关键字。
“regexp”: /^((?!\b(?:if|else|while|for)b).)*$/gm:使用正则表达式进行更复杂的匹配,例如检测C++代码中是否存在语法错误。
“not”: { “match”: “string”, “message”: “string” }:排除与指定字符串完全匹配的问题。
“any”: [{}, {}]:或运算,只要满足其中一个规则就可以匹配。
“all”: [{}, {}]:与运算,必须满足所有规则才能匹配。
在 VS Code 的 tasks.json 中,problemMatcher 的 patternMatcher 子配置项用于指定问题匹配器的模式匹配器。它可以是一个字符串或一个对象,用于进一步定义问题的匹配方式。
对于 patternMatcher 子配置项,可以根据不同的任务和编译器输出格式进行自定义配置。以下是一些可能的下级子配置项及其用途:
type:指定模式匹配器的类型。可以是 “regex” 或 “literal”。“regex” 表示使用正则表达式进行匹配,“literal” 表示直接匹配字符串。
pattern:指定模式匹配的模式。如果是 “regex” 类型,则 pattern 是一个正则表达式;如果是 “literal” 类型,则 pattern 是一个字符串。
file:指定要匹配的文件路径。可以是一个字符串或一个字符串数组,用于指定要匹配的文件。
line:指定要匹配的行号。可以是一个整数或一个整数数组,用于指定要匹配的行号范围。
column:指定要匹配的列号。可以是一个整数或一个整数数组,用于指定要匹配的列号范围。
message:指定要匹配的错误信息内容。可以是一个字符串或一个字符串数组,用于指定要匹配的错误信息内容。
VSCODE的tasks.json的problemMatcher的patternMatcher可以有哪些下级子配置项,其用途分别是什么?
根据引用,在tasks.json中,problemMatcher的patternMatcher可以有以下下级子配置项:
fileLocation: 指定问题界面文件目录的查找方式,可以是绝对路径或相对路径。
uri: 指定问题界面文件的URI。
severity: 指定问题的严重程度,可以是error、warning或info。
code: 指定问题的代码。
message: 指定问题的消息。
loop: 指定是否循环匹配问题。
location: 指定问题的位置。
line: 指定问题所在的行数。
column: 指定问题所在的列数。
endLine: 指定问题结束的行数。
endColumn: 指定问题结束的列数。
relatedInformation: 指定相关信息。
其中,fileLocation和uri用于指定问题界面文件的位置,severity用于指定问题的严重程度,code用于指定问题的代码,message用于指定问题的消息,location用于指定问题的位置,line和column用于指定问题所在的行数和列数,endLine和endColumn用于指定问题结束的行数和列数,relatedInformation用于指定相关信息。