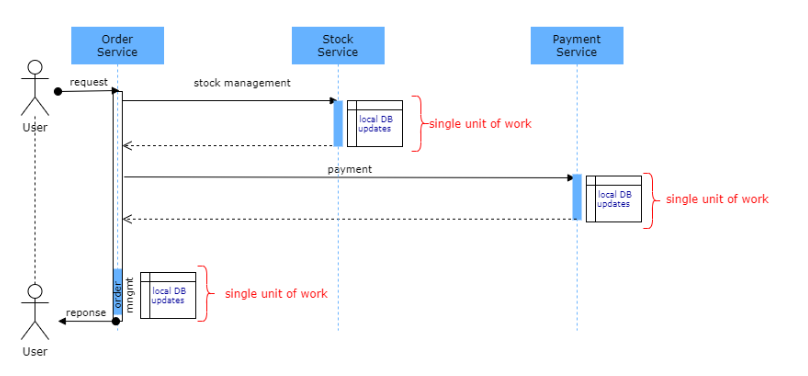
Rune和Byte,字符和字符串有什么不一样
String
Go语言中,string
就是只读的采用
utf8
编码的字节切片(slice) 因此用
len
函数获取到的长度并不是字符个数,而是字节个数。 for循环遍历输出的也是各个字节。
Rune
rune
是
int32
的别名,代表字符的Unicode编码,采用4个字节存储,将
string
转成
rune
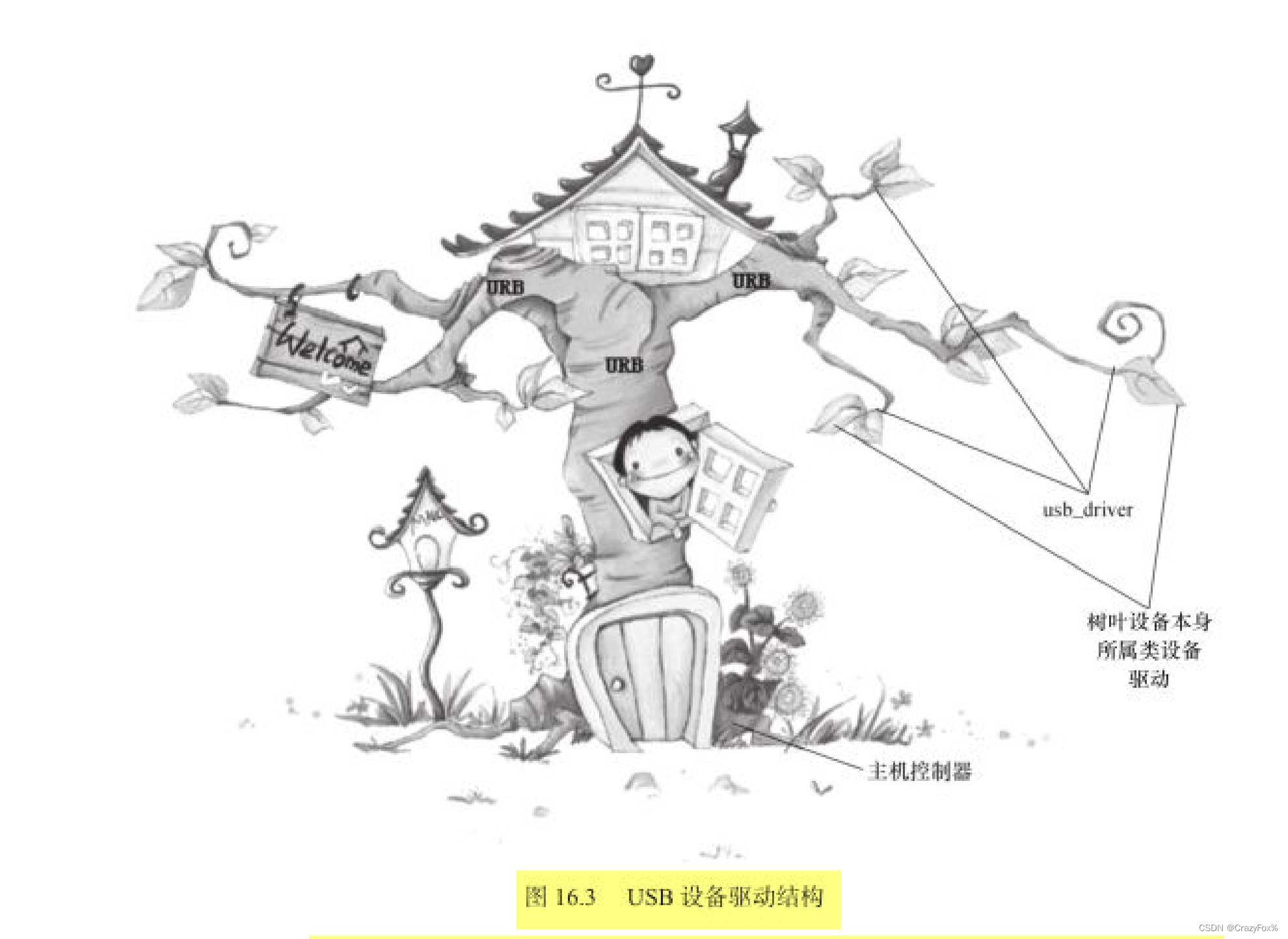
就意味着任何一个字符都用4个字节来存储其unicode值,这样每次遍历的时候返回的就是unicode值,而不再是字节了,这样就可以解决乱码问题了
byte
bytes操作的对象也是字节切片,与string的不可变不同,byte是可变的,因此string按增量方式构建字符串会导致多次内存分配和复制,使用bytes就不会因而更高效一点
在Go语言中,所谓的Rune和Byte其实分别就是int32有符号整数类型和uint8无符号整数类型的别称
也就是说
Rune=int32
Byte=unit8
为了理解Rune和Byte的作用,我们必须知道字符和字符串的区别。
字符和字符串的区别在于字符表达的是单一的字母、数字、空格、标点符号,而字符串表达的是一个或多个字母、数字、空格和标点符号。和C、Java等语言不同,Go语言中并没有char这个专门用来表示字符的数据类型,而是使用Rune和Byte来表达字符。因此Rune虽然是有符号整数类型的一种,但它通常不用于表示231 到 231-1这些整数,而是用来表示长度可以达到32bit的字符(比如Unicode编码格式的字符),之前我们讲到在对中文字符串做切片时必须将字符串先从默认的8bit的Byte(前面讲到了,在Go中,所谓字符串就是一组字节的切片(slice of bytes))转换成32bit的Rune否则的话会出现乱码就是这个原因,因为汉字通常需要3个字节(24bit)来表示。
而和unit8等价的Byte其实就是我们通常理解的字节,既计算机中最常见的存储单位(1 byte = 8 bits, 1024 bytes = 1 kilobyte, 1024 kilobytes = 1 megabyte…)。和Rune类似,Byte虽然是无符号整数类型的一种,但是它主要的作用并不是用来表示0到255这些整数,而是用来表示长度为8bit的字符。
和用双引号声明的字符串不一样,在Go中我们用单引号来声明一个字符,字符有两种数据类型:Rune和Byte,默认情况下字符的类型为Rune(即隐式声明字符变量时其类型为Rune),举例如下:
func main() {var a rune = 'A'fmt.Println(a)fmt.Printf("%T\n", a)var b = '中'fmt.Println(b)fmt.Printf("%T\n", b)
}输出:

这里我们以显示的方式声明了字符变量a,以隐式的方式声明了字符变量b,此时a和b的类型都为Rune,即int32。
这里你也许会问:为什么我们赋值给变量a的是字符“A”,赋值给变量b的是字符“中”,但变量a和b打印出来的结果却是整数65和20013?这是因为不管是Rune还是Byte,它们的本质还是整数,而字符“A”对应的整数即为65,字符“中”对应的整数即为20013。如果要想将变量a和变量b打印出的内容以原本的字符内容显示,则需要用到格式码%c或者string()函数来将字符转变为字符串,举例如下:
func main() {var a rune = 'A'fmt.Printf("%c\n", a)fmt.Printf("%T\n", a)var b = '中'fmt.Println(string(b))fmt.Printf("%T\n", b)
}输出:

因为默认情况下字符的类型为Rune,如果要创建一个Byte类型的字符变量的话,则必须显示声明变量的类型,举例如下:
func main() {var a byte = 'A'fmt.Printf("%c\n", a)fmt.Printf("%T\n", a)var b byte = '中'fmt.Printf("%c\n", b)fmt.Printf("%T\n", b)
}
输出:

这里在运行该程序时出现了“.\integer.go:9:6: constant 20013 overflows byte”的报错,原因也很简单:Byte对应的是无符号整数类型uint8,而uint8的范围是0到255,而字符"中"对应的整数为20013,显然20013不在unit8的范围内,因此会报错。解决的办法就是避免将中文字符赋值以Byte的类型赋值给变量,因为Byte对应的是ASCII编码,而中文对应的是Unicode或UTF-8,需要用到Rune。
最后再强调一次:字符表达的是单一的字母、数字、空格、标点符号,在使用rune或者byte来声明一个字符变量时,如果字符内容里哪怕只多出1个字母、数字、空格、标点符号,那都是无效的字符,Go会返回"more than one character in rune literal"的异常,举例如下:
func main() {var r1 rune = 'a'fmt.Println(string(r1))var r2 rune = 'ab'fmt.Println(string(r2))
}输出:

这里我们分别声明了r1和r2两个rune类型的字符,r1是正常的字符,而r2仅仅因为在字符a后面多加了一个b就导致了Go返回了"more than one character in rune literal"这个异常。
字符串
字符串,可以说是大家很熟悉的数据类型之一。定义方法很简单var mystr string = "hello"
上面说的byte 和 rune 都是字符类型,若多个字符放在一起,就组成了字符串,也就是这里要说的 string 类型。
比如 hello ,对照 ascii 编码表,每个字母对应的编号是:104,101,108,108,111
如下示例:
func main() {var mystr01 string = "hello"var mystr02 [5]byte = [5]byte{104, 101, 108, 108, 111}fmt.Printf("mystr01: %s\n", mystr01)fmt.Printf("mystr02: %s", mystr02)
}输出:

mystr01 和 mystr02 输出一样,说明了 string 的本质,其实是一个 byte数组
通过以上学习,我们知道字符分为 byte 和 rune,占用的大小不同。
那 hello,中国 占用几个字节?
要回答这个问题,你得知道 Go 语言的 string 是用 uft-8 进行编码的,
英文字母占用一个字节,而中文字母占用 3个字节,
所以 hello,中国 的长度为 5+1+(3*2)= 12个字节。
func main() {var country string = "hello,中国"fmt.Println(len(country))
}输出:

以上虽然我都用双引号表示 一个字符串,但这并不是字符串的唯一表示方式。
除了双引号之外 ,你还可以使用反引号。
大多情况下,二者并没有区别,但如果你的字符串中有转义字符\ ,这里就要注意了,它们是有区别的。
使用反引号号包裹的字符串,相当于 Python 中的 raw 字符串,会忽略里面的转义。
比如我想表示 \r\n 这个 字符串,使用双引号是这样写的,这种叫解释型表示法
var mystr01 string = "\\r\\n"
而使用反引号,就方便多了,所见即所得,这种叫原生型表示法
var mystr02 string = `\r\n`