mongodb快速搭建及使用
- 1.mongodb安装
- 1.1 docker安装启动mongodb
- 2.mongo shell常用命令
- 2.1 插入文档
- 2.1.1 插入单个文档
- 2.1.2 插入多个文档
- 2.1.3 用脚本批量插入
- 2.2 查询文档
- 2.2.1 排序查询
- 2.2.1 分页查询
前言:本篇默认你是对nongodb的基础概念有了了解,操作是非常基础的。但是与关系型数据库的类比默认你已经是了解的。
1.mongodb安装
这里为了快速使用mongodb,我使用了docker安装(如果想了解linux上面的安装可以参考我的另一篇文章《mongdb下载、安装、启动》)。
1.1 docker安装启动mongodb
#拉取mongo镜像
docker pull mongo:4.4.10
#运行mongo镜像
docker run --name mongo-server -p 29017:27017 \
-e MONGO_INITDB_ROOT_USERNAME=root\
-e MONGO_INITDB_ROOT_PASSWORD=root\
-d mongo:4.4.10 --wiredTigerCacheSizeGB 1
默认情况下,Mongo会将wiredTigerCacheSizeGB设置为与主机总内存成比例的值,而不考虑你可能对容器施加的内存限制。
MONGO_INITDB_ROOT_USERNAME和MONGO_INITDB_ROOT_PASSWORD都存在就会启用身份认证(mongod --auth)
#进入容器
docker exec -it mongo-server bash
#进入Mongo shell
mongo -u root-p root
2.mongo shell常用命令
| 命令 | 说明 |
|---|---|
| show dbs/show databases | 显示数据库列表 |
| use 数据库名 | 切换数据库,如果不存在创建数据库 |
| db.dropDatabase() | 删除数据库 |
| show collections/show tables | 显示当前数据库的集合列表 |
| db.createCollection(“集合名”) | 创建集合 |
| db.集合名.stats() | 查看集合详情 |
| db.集合名.drop() | 删除集合 |
| show users | 显示当前数据库的用户列表 |
| show roles | 显示当前数据库的角色列表 |
| db.createUser({user:“用户名”,pwd:“用户密码”,roles:[“角色”]}) | 创建管理员 |
| db.dropUser(“用户名”) | 删除用户 |
| show profile | 显示近发生的操作 |
| load(“xxx.js”) | 执行一个JavaScript脚本文件 |
| exit /quit() | 退出当前shell |
| help | 查看mongodb支持哪些命令 |
| db.help() | 查询当前数据库支持的方法 |
| db.集合名.help() | 显示集合的帮助信息 |
| db.version() | 查看数据库版本 |
2.1 插入文档
2.1.1 插入单个文档
- insertOne: 支持writeConcern
db.collection.insertOne(<document>,{writeConcern: val}
)
writeConcern 决定一个写操作落到多少个节点上才算成功。writeConcern 的取值val包括:
0: 发起写操作,不关心是否成功;
1: 集群最大数据节点数:写操作需要被复制到指定节点数才算成功;
majority: 写操作需要被复制到大多数节点上才算成功
db.emps.insertOne({x:22,y:12},{writeConcern:0})
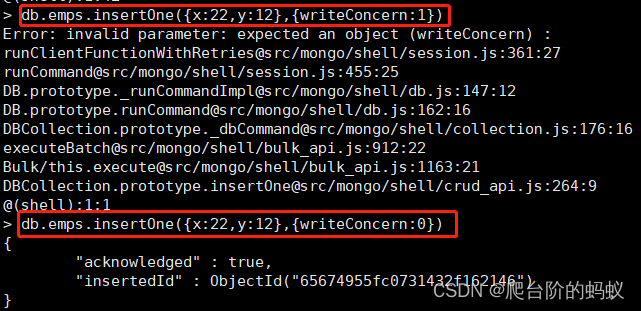
- insert: 若插入的数据主键已经存在,则会抛 DuplicateKeyException 异常,提示主键重复,不保存当前数据
db.emps.insert({x:11,y:22})

- save: 如果 _id 主键存在则更新数据,如果不存在就插入数据
db.emps.save({_id:ObjectId("65674b35fc0731432f162147"),x:12,y:21})

2.1.2 插入多个文档
- insertMany:向指定集合中插入多条文档数据
db.collection.insertMany([ <document 1> , <document 2>, ... ],{writeConcern: <document>,ordered: <boolean> }
)
writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
ordered:指定是否按顺序写入,默认 true,按顺序写入。
db.emps.insertMany([{x:23,y:23},{x:33,y:33}],{writeConcern:0,ordered:true})
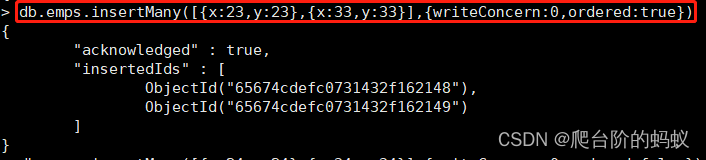
2.1.3 用脚本批量插入
# 退出mongo shell
exit
# docker容器内部也是一个小型的linux环境
# 更新依赖
apt-get update
# 安装vim命令
apt-get install vimcd /data/db/
vim books.js
# 以下内容粘贴在books.js中
var tags = ["nosql","mongodb","document","developer","popular"];
var types = ["technology","sociality","travel","novel","literature"];
var books=[];
for(var i=0;i<50;i++){var typeIdx = Math.floor(Math.random()*types.length);var tagIdx = Math.floor(Math.random()*tags.length);var favCount = Math.floor(Math.random()*100);var book = {title: "book-"+i,type: types[typeIdx],tag: tags[tagIdx],favCount: favCount,author: "xxx"+i};books.push(book)
}
db.books.insertMany(books);
# 进入mongo shell
mongo -u root -p root
# 加载js文件
load("books.js")

2.2 查询文档
db.collection.find(query, projection)
query :可选,查询的条件
projection :可选,使用投影操作符指定返回的键。默认省略:查询时返回文档中所有键值。_id为1的时候,其他字段必须是1;_id是0的时候,其他字段可以是0;如果没有_id字段约束,多个其他字段必须同为0或同为1。
# 只指定查询条件 tag=nosql
db.books.find({tag:"nosql"})
# 指定查询条件 且 指定title,author不展示
db.books.find({tag:"nosql"},{title:0,author:0})
# 指定查询条件 且 只展示title,author
db.books.find({tag:"nosql"},{title:1,author:1})
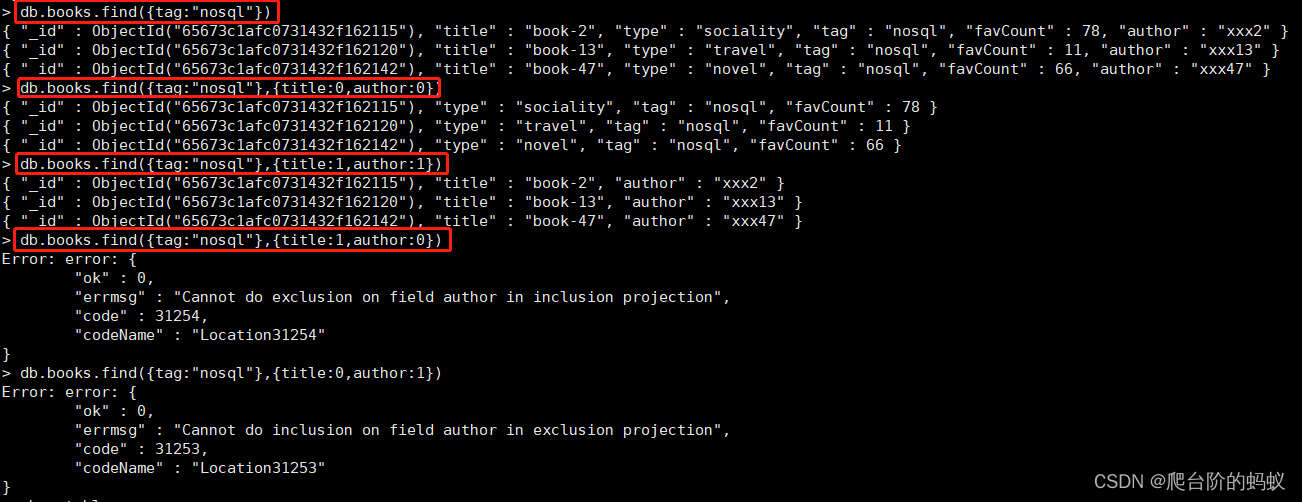
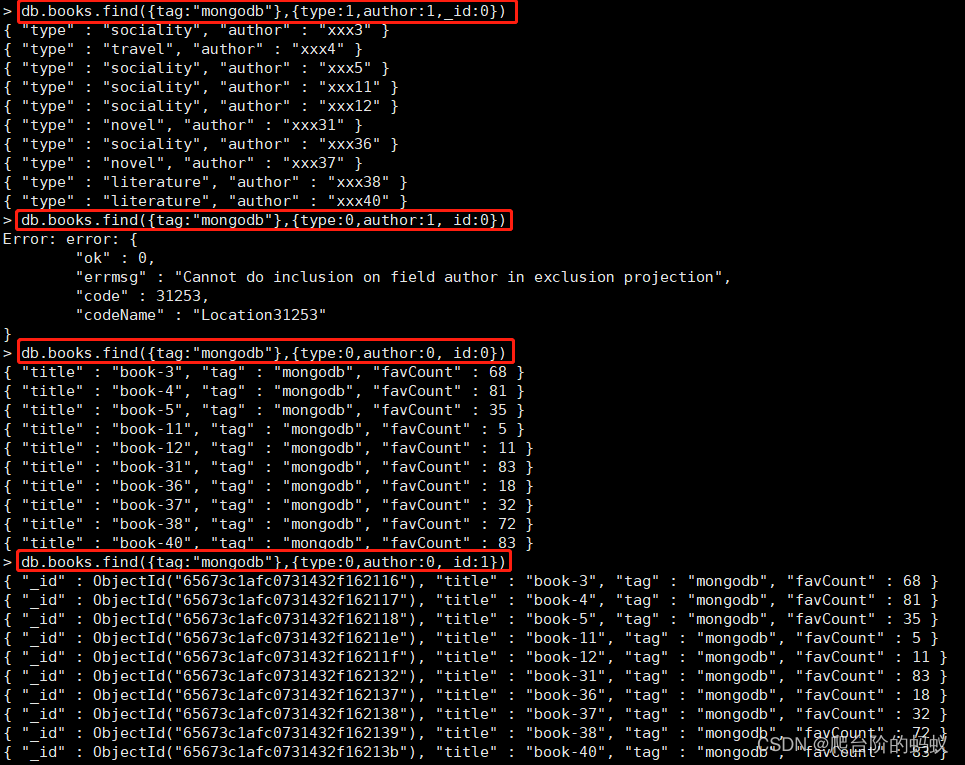
# 指定查询条件 且 只展示title,author,隐藏_id
db.books.find({tag:"mongodb"},{type:1,author:1,_id:0})
# 同时指定0和1仍然会报错
db.books.find({tag:"mongodb"},{type:0,author:1,_id:0})
# 指定查询条件 且 指定title,author不展示,隐藏_id
db.books.find({tag:"mongodb"},{type:0,author:0,_id:0})
# 指定查询条件 且 指定title,author不展示,不隐藏_id
db.books.find({tag:"mongodb"},{type:0,author:0,_id:1})
查询条件对照表
| SQL | MQL |
|---|---|
| a=1 | {a:1} |
| a<>1 | {a:{$ne:1}} |
| a>1 | {a:{$gt:1}} |
| a>=1 | {a:{$gte:1}} |
| a<1 | {a:{$lt:1}} |
| a<=1 | {a:{$lte:1}} |
查询逻辑对照表
| SQL | MQL |
|---|---|
| a=1and b=1 | {a:1,b:1}或{$and:[{a:1},{b:1}]} |
| a=1or b=1 | {$or:[{a:1},{b:1}]} |
| a is null | {a: {$exists: false}} |
| a in (1, 2, 3) | {a:{$gte:1}} |
| a<1 | {a:{$in:[1,2,3]}} |
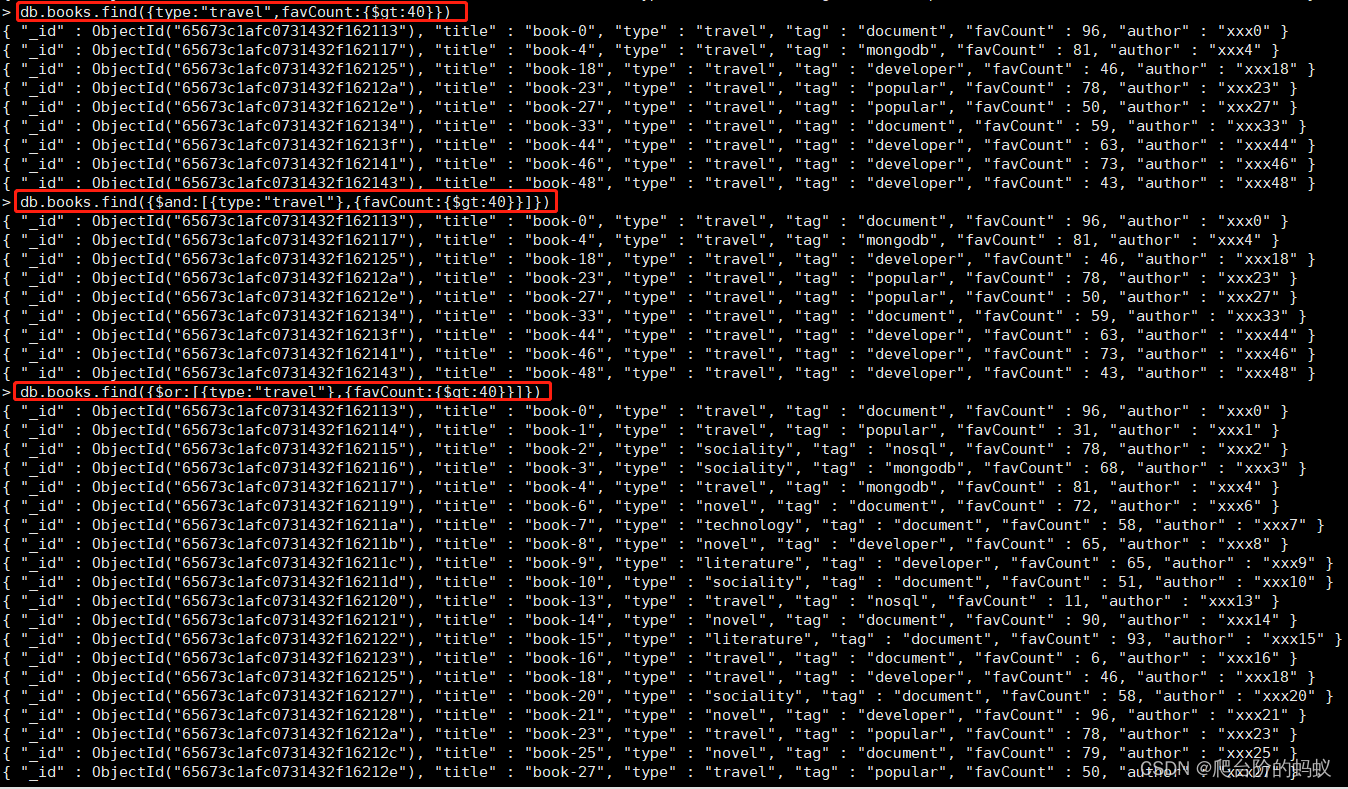
# 查询条件 type=travel 且 favCount > 40
db.books.find({type:"travel",favCount:{$gt:40}})
# 查询条件 type=travel 且 favCount > 40
db.books.find({$and:[{type:"travel"},{favCount:{$gt:40}}]})
# 查询条件 type=travel 或者 favCount > 40
db.books.find({$or:[{type:"travel"},{favCount:{$gt:40}}]})
2.2.1 排序查询
db.books.find({type:"travel"}).sort({favCount:1})
db.books.find({type:"travel"}).sort({favCount:-1})
1 为升序排列,而 -1 是用于降序排列

2.2.1 分页查询
skip用于指定跳过记录数,limit则用于限定返回结果数量。可以在执行find命令的同时指定skip、limit参数,以此实现分页的功能。比如,假定每页大小为8条,查询第3页的book文档(查询第三页即跳过2*8=16条,限定展示8条):
db.books.find().skip(16).limit(8)

处理分页问题 – 巧分页
数据量大的时候,应该避免使用skip/limit形式的分页。
替代方案:使用查询条件+唯一排序条件;
例如:
第一页:db.posts.find({}).sort({_id: 1}).limit(20);
第二页:db.posts.find({_id: {KaTeX parse error: Expected 'EOF', got '}' at position 17: …t: <第一页最后一个_id>}̲}).sort({_id: 1…gt: <第二页最后一个_id>}}).sort({_id: 1}).limit(20);
处理分页问题 – 避免使用 count
尽可能不要计算总页数,特别是数据量大和查询条件不能完整命中索引时。
考虑以下场景:假设集合总共有 1000w 条数据,在没有索引的情况下考虑以下查询:
db.coll.find({x: 100}).limit(50);
db.coll.count({x: 100});
前者只需要遍历前 n 条,直到找到 50 条 x=100 的文档即可结束;
后者需要遍历完 1000w 条找到所有符合要求的文档才能得到结果。 为了计算总页数而进行的 count() 往往是拖慢页面整体加载速度的原因




![BUUCTF [GXYCTF2019]BabyUpload 1详解(.htaccess配置文件特性)](https://img-blog.csdnimg.cn/img_convert/b8f9c756a0bbff74a6e0622fa5212c2a.png)