论文地址:https://arxiv.org/pdf/1901.03003.pdf
代码地址:MORANv2-pytorch版本
1 abstract
不规则文本识别由于有着各种各样的形状,因此仍有较大的困难,本文提出MORAN:包含一个多目标蒸馏网络(multi-object rectification network)和一个基于注意力机制的识别网络。多目标蒸馏网络旨在大致确定文本所在区域以减弱识别难度,它仅需要图片和标签就可以进行训练。注意力识别网络则集中解决预测文本的任务。提出fractional pickup以提高注意力识别网络的灵敏度(sensitivity)。
2 motivation
- irregular text → \rightarrow → shapes and distorted patterns
3 method
- overview
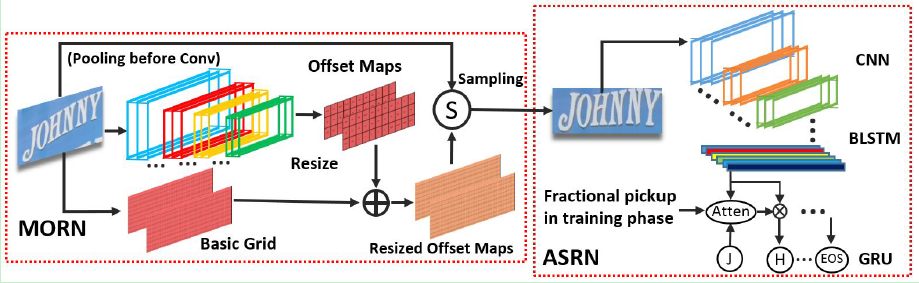
3.1 multi-object rectification network(MORN)
-
常用的修改图片的方法受限于几何约束(即几何约束问题),比如对于affine transformation network,它只能rotation,scaling,translation(平移),但一张图片可能存在形变(deformation),以上三种基本变换无法表示形变(figure 3)。另外一种是deformable conv network,但面对seq2seq问题时网络可能发散。

-
Offset Maps
每个卷积层包含一个conv+BN+ReLU,除了最后一层(具体参数看论文),之后添加一层激活函数Tanh,将结果锁在区间(-1,1)。
最后resize将输出的尺寸更改到和输出相同。
如 input:(1×32×100) → C N N \rightarrow^{CNN} →CNN(2×3×11) → r e s i z e \rightarrow^{resize} →resize(2×32×100)
输出以后:在sampling之前,两个channel分别归一化至[0, W]和[0, H]
- Basic Grid
将图像所有的pixel映射至区间[1,1],左上角为(-1,-1),右下角为(1,1)。原图不同通道(RGB三个channel)同一位置有着相同的basic grid,输出有两个channel,分别代表x轴和y轴。
它的输出尺寸与offset maps输出尺寸一致。
- sampling
I ( i , j ) ′ = I ( i ′ , j ′ ) i ′ = o f f s e t ( 1 , i , j ) ′ , j ′ = o f f s e t ( 2 , i , j ) ′ I'_{(i,j)} = I_{(i',j')}\\ i'=offset'_{(1,i,j)},j'=offset'_{(2,i,j)} I(i,j)′=I(i′,j′)i′=offset(1,i,j)′,j′=offset(2,i,j)′
o f f s e t ′ offset' offset′是Resized Offset Maps的输出, I I I是原图像, I ′ I' I′是sampling的输出
- analysis
- rectified images 在regular文本情况下效果更好
- 能解决之前提到的几何约束问题
3.2 attention-based sequence recognition network(ASRN)
主要是基于CNN-BLSTM结构,具体结构如下:
| Type | Configuration | Size |
|---|---|---|
| Input | – | 1×32×100 |
| conv | 64,k3,s1,p1 | 64×32×100 |
| MaxPooling | k2,s2 | 64×16×50 |
| conv | 128,k3,s1,p1 | 128×16×50 |
| MaxPooling | k2,s2 | 128×8×25 |
| conv | 256,k3,s1,p1 | 256×8×25 |
| conv | 256,k3,s1,p1 | 256×8×25 |
| MaxPooling | k2,s2×1,p0×1 | 256×4×26 |
| conv | 512,k3,s1,p1 | 512×4×26 |
| conv | 512,k3,s1,p1 | 512×4×26 |
| MaxPooling | k2,s2×1,p0×1 | 512×2×27 |
| conv | 512,k3,s1 | 512×1×26 |
| BLSTM | hidden unit:256 | 256×1×26 |
| BLSTM | hidden unit:256 | 256×1×26 |
| GRU | hidden unit:256 | 256×1×26 |
BLSTM:bidirectional-LSTM
GRU:包含在attention-based decoder中
主要用到的计算公式:
y t = S o f t m a x ( W o u t s t + b o u t ) s t = G R U ( y p r e v , g t , s t − 1 ) y p r e v = E m b e d d i n g ( y t − 1 ) g t = ∑ i = 1 L ( α t , h i ) α t , i = e x p ( e t , i ) / ∑ j = 1 L ( e x p ( e t , j ) ) e t , i = T a n h ( W s s t − 1 + W h h i + b ) y_t = Softmax(W_{out}s_t+b_{out}) \\ s_t=GRU(y_{prev},g_t,s_{t-1})\\ y_{prev}=Embedding(y_{t-1})\\ \\ g_t=\sum_{i=1}^L(\alpha_t,h_i)\\ \alpha_{t,i}=exp(e_{t,i})/\sum_{j=1}^L(exp(e_{t,j}))\\ e_{t,i}=Tanh(W_ss_{t-1}+W_hh_i+b)\\ yt=Softmax(Woutst+bout)st=GRU(yprev,gt,st−1)yprev=Embedding(yt−1)gt=i=1∑L(αt,hi)αt,i=exp(et,i)/j=1∑L(exp(et,j))et,i=Tanh(Wsst−1+Whhi+b)
其中, s t s_t st为t时刻hidden state; h i h_i hi是seq feature vector,是最后一个LSTM的输出
L是特征图的长度, α t , i \alpha_{t,i} αt,i是attention weights的向量
-
Fractional Pickup
decoder的每一步都加上FP操作
迭 代 公 式 : { α t , k = β α t , k + ( 1 − β ) α t , k + 1 α t , k + 1 = ( 1 − β ) α t , k + β α t , k + 1 β = r a n d ( 0 , 1 ) k = r a n d [ 1 , T − 1 ] , T = m a x _ n u m ( s t e p s ) 迭代公式:\begin{cases} \alpha_{t,k}=\beta\alpha_{t,k}+(1-\beta)\alpha_{t,k+1} \\ \alpha_{t,k+1}=(1-\beta)\alpha_{t,k}+\beta\alpha_{t,k+1} \end{cases} \\ \beta = rand(0,1) \ k=rand[1,T-1], \ T=max\_num(steps) 迭代公式:{αt,k=βαt,k+(1−β)αt,k+1αt,k+1=(1−β)αt,k+βαt,k+1β=rand(0,1) k=rand[1,T−1], T=max_num(steps)
对第k+1步而言,FP提供了第k步的信息并允许其遗忘,提升了ASRN的鲁棒性
4 experiments
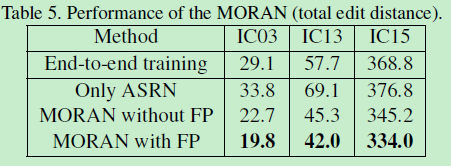
4.1 MORAN各结构影响的实验
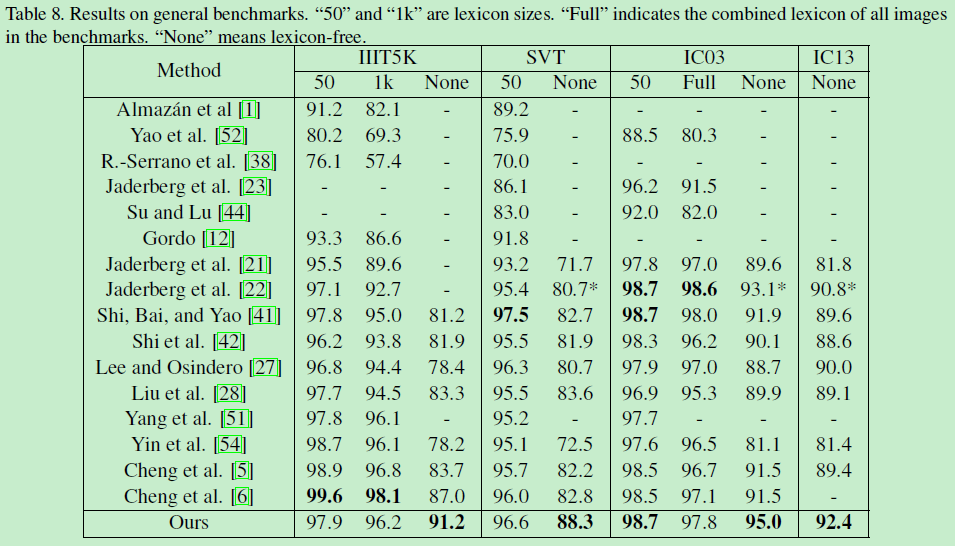
4.2 with benchmarks
4.3 irregular results
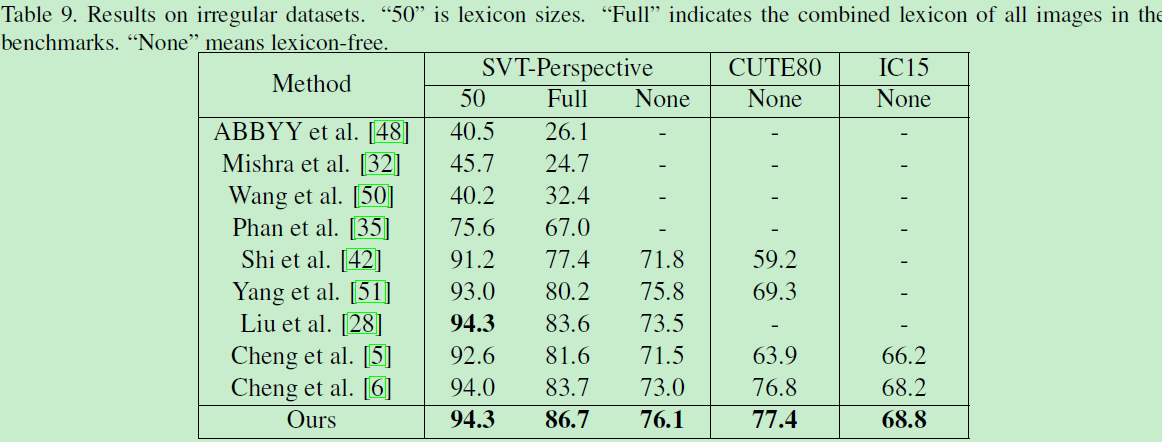
(除此之外还有几个实验:与STAR-Net、RARE的对比)
一点想法:
由于笔者目前主要研究的方向是针对规则文本,因此我主要提炼的是论文中MORN部分。而未精读ASRN部分,感兴趣的读者可以从文章开头的论文地址链接中下载全文阅读。