大数据分析与应用实验任务十
实验目的:
-
通过实验掌握spark SQL的基本编程方法;
-
熟悉RDD到DataFrame的转化方法;
-
通过实验熟悉spark SQL管理不同数据源的方法。
实验任务:
进入pyspark实验环境,在桌面环境打开jupyter notebook,或者打开命令行窗口,输入pyspark,完成下列任务:
实验一、参考教材5.3-5.6节各个例程编写代码,逐行理解并运行。
1. DataFrame 的创建
在编写独立应用程序时,可以通过如下语句创建一个 SparkSession 对象:
from pyspark import SparkContext,SparkConf
from pyspark.sql import SparkSession
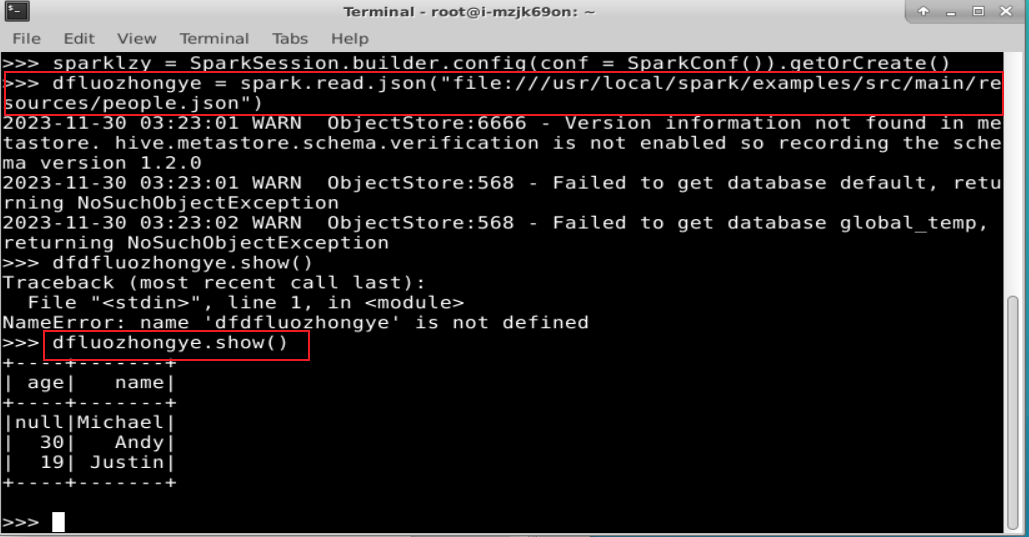
sparklzy = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
读取在“/usr/local/spark/examples/src/main/resources/”目录下的样例数据 people.json
dfluozhongye = spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
dfluozhongye.show()
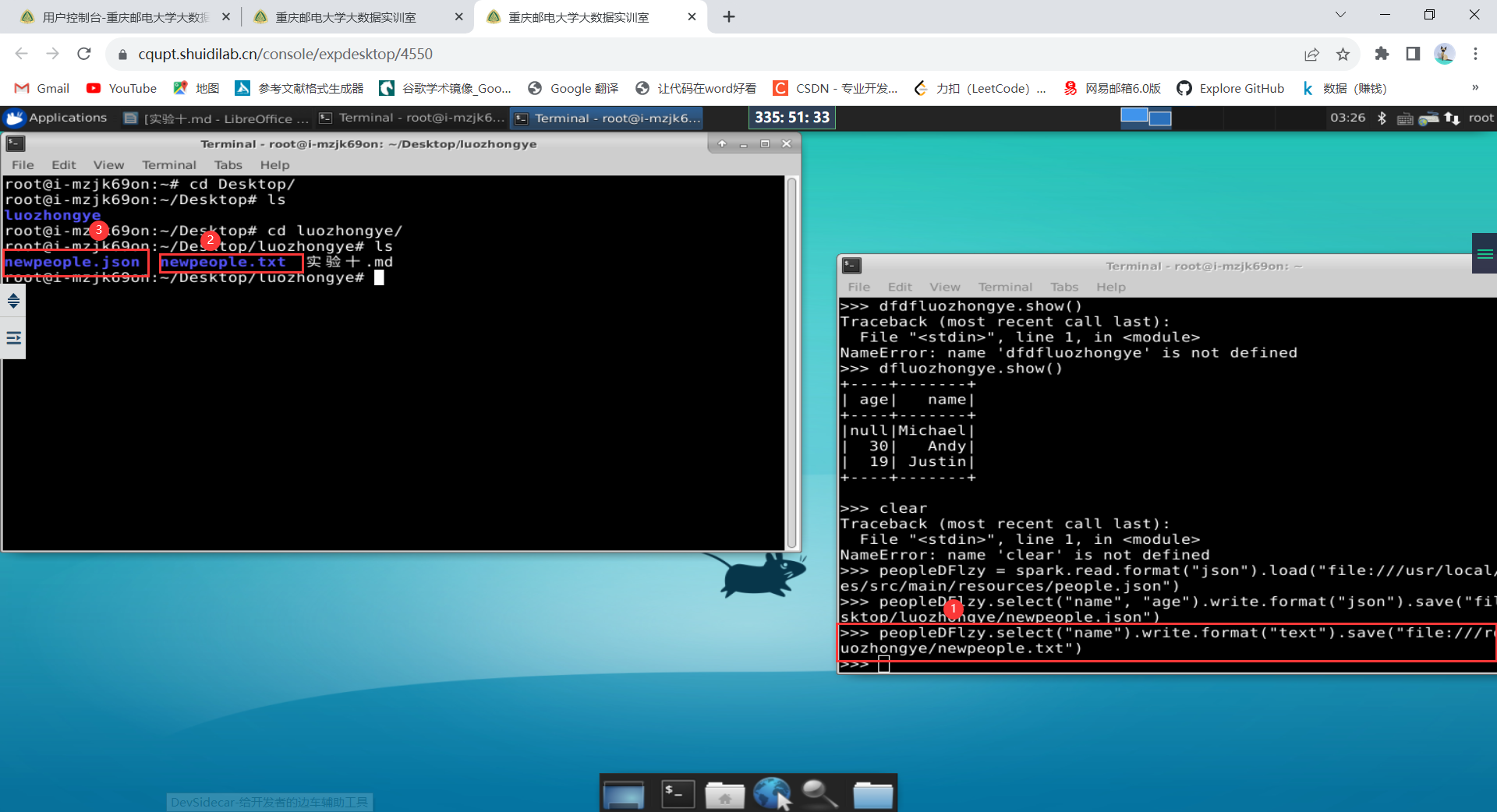
2. DataFrame 的保存
peopleDFlzy = spark.read.format("json").load("file:///usr/local/spark/examples/src/main/resources/people.json") peopleDFlzy.select("name", "age").write.format("json").save("file:///root/Desktop/luozhongye/newpeople.json")peopleDFlzy.select("name").write.format("text").save("file:///root/Desktop/luozhongye/newpeople.txt")
如果要再次读取 newpeople.json 中的数据生成 DataFrame,可以直接使用 newpeople.json 目录名称,而不需要使用 part-00000-3db90180-ec7c-4291-ad05-df8e45c77f4d.json 文件(当然,使用这个文件也可以),代码如下:
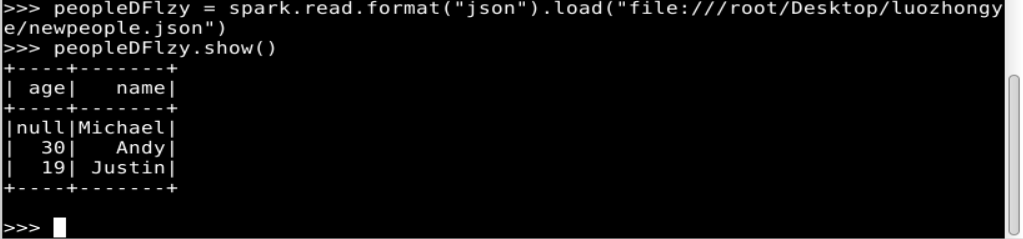
peopleDFlzy = spark.read.format("json").load("file:///root/Desktop/luozhongye/newpeople.json")
peopleDFlzy.show()
3. DataFrame 的常用操作
创建好DataFrame以后,可以执行一些常用的DataFrame操作,包括printSchema()、select()、filter()、groupBy()和 sort()等。在执行这些操作之前,先创建一个 DataFrame:
dflzy=spark.read.json("file:///usr/local/spark/examples/src/main/resources/people.json")
(1) printSchema()
可以使用 printSchema()操作打印出 DataFrame 的模式(Schema)信息
dflzy.printSchema()

(2) select()
select()操作的功能是从 DataFrame 中选取部分列的数据。
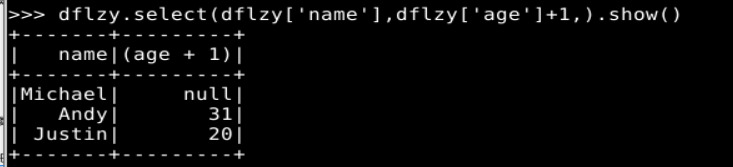
# select()操作选取了 name和 age 这两个列,并且把 age 这个列的值增加 1。
dflzy.select(dflzy['name'],dflzy['age']+1,).show()
(3) filter()
filter()操作可以实现条件查询,找到满足条件要求的记录。
# 用于查询所有 age 字段的值大于 20 的记录。
dflzy.filter(dflzy["age"]>20)

(4) groupBy()
groupBy()操作用于对记录进行分组。
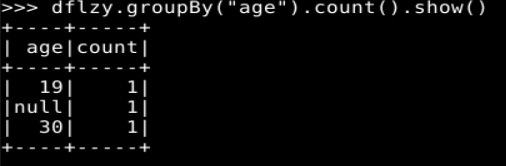
# 根据 age 字段进行分组,并对每个分组中包含的记录数量进行统计
dflzy.groupBy("age").count().show()
(5) sort()
sort()操作用于对记录进行排序。
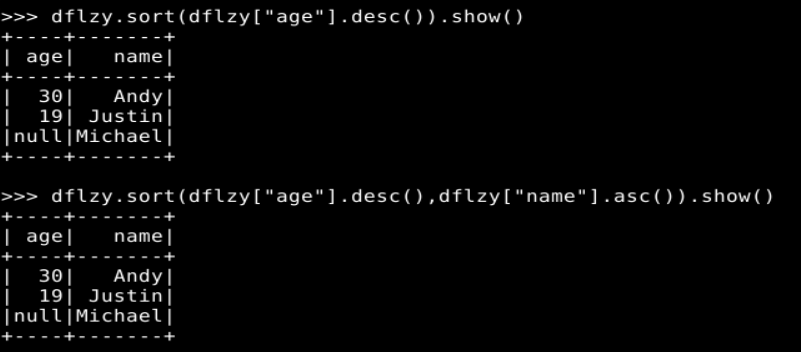
# 表示根据 age 字段进行降序排序;
dflzy.sort(dflzy["age"].desc()).show()
# 表示根据 age 字段进行降序排序,当 age 字段的值相同时,再根据 name 字段的值进行升序排序
dflzy.sort(dflzy["age"].desc(),dflzy["name"].asc()).show()
4. 从 RDD 转换得到 DataFrame
(1) 利用反射机制推断 RDD 模式
把 “/usr/local/spark/examples/src/main/resources/”目录下的people.txt 加载到内存中生成一个 DataFrame,并查询其中的数据。完整的代码及其执行过程如下:
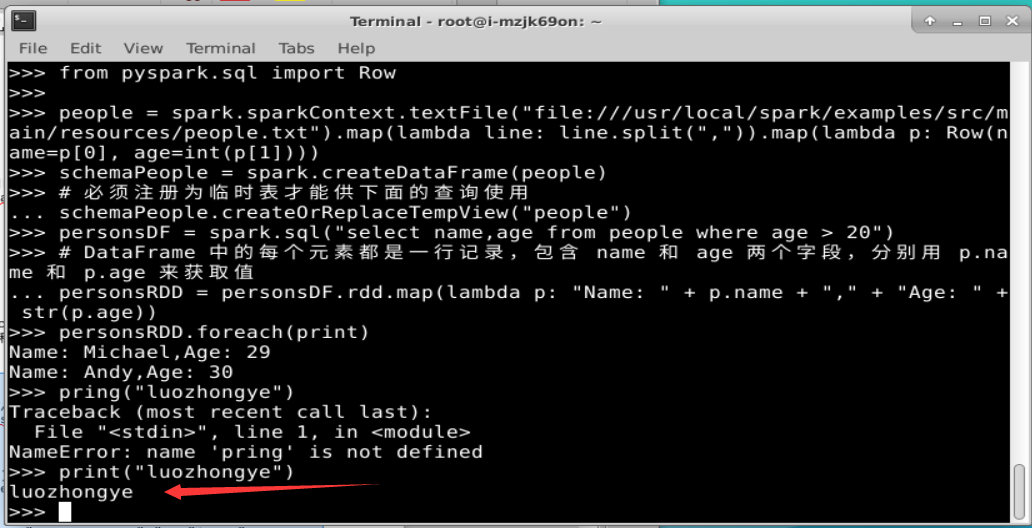
from pyspark.sql import Rowpeople = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").map(lambda line: line.split(",")).map(lambda p: Row(name=p[0], age=int(p[1])))
schemaPeople = spark.createDataFrame(people)
# 必须注册为临时表才能供下面的查询使用
schemaPeople.createOrReplaceTempView("people")
personsDF = spark.sql("select name,age from people where age > 20")
# DataFrame 中的每个元素都是一行记录,包含 name 和 age 两个字段,分别用 p.name 和 p.age 来获取值
personsRDD = personsDF.rdd.map(lambda p: "Name: " + p.name + "," + "Age: " + str(p.age))
personsRDD.foreach(print)
(2)使用编程方式定义 RDD 模式
利用 Spark SQL 查询 people.txt
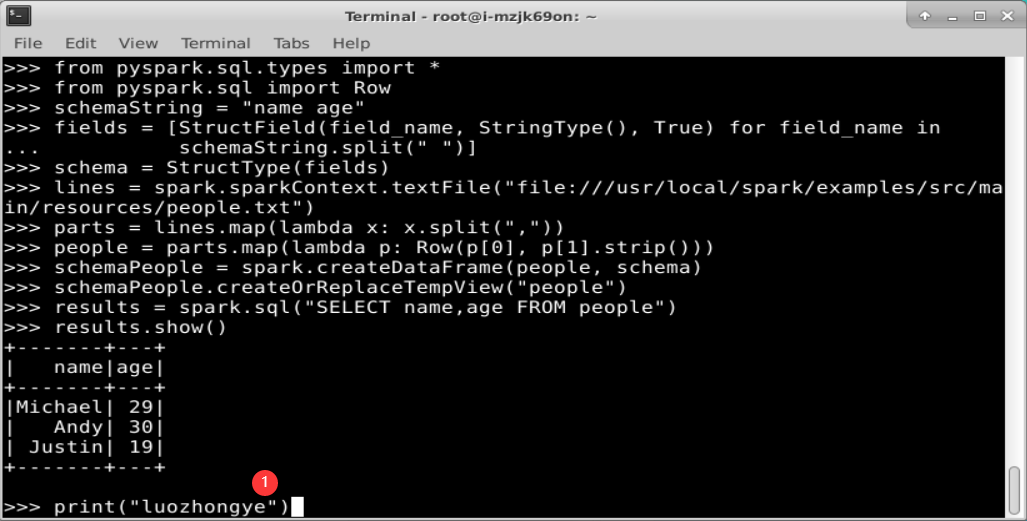
from pyspark.sql.types import *
from pyspark.sql import Row# 下面生成“表头”
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name inschemaString.split(" ")]
schema = StructType(fields)
# 下面生成“表中的记录
lines = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda x: x.split(","))
people = parts.map(lambda p: Row(p[0], p[1].strip()))
# 下面把“表头”和“表中的记录”拼装在一起
schemaPeople = spark.createDataFrame(people, schema)
# 注册一个临时表供后面的查询使用
schemaPeople.createOrReplaceTempView("people")
results = spark.sql("SELECT name,age FROM people")
results.show()
实验二、完成p113页实验内容第1题(spark SQL基本操作),另注意自行修改题目中的数据。
1. Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
{ "id":6 , "name":"罗忠烨" }
为 employee.json 创建 DataFrame,并编写 Python 语句完成下列操作:
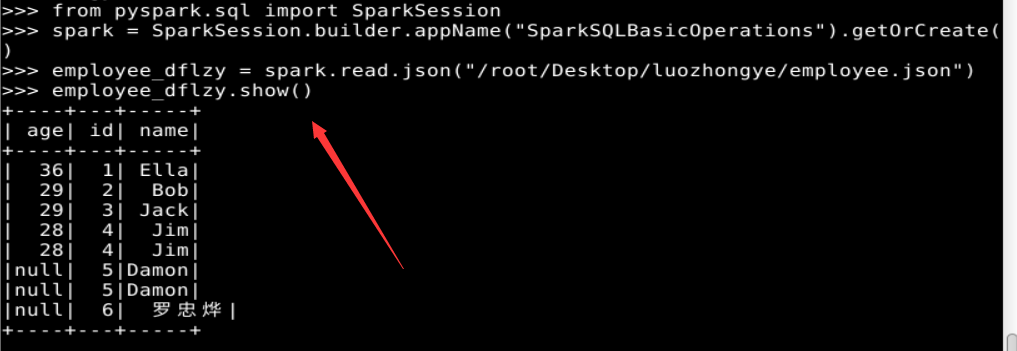
from pyspark.sql import SparkSession# 创建 SparkSession
spark = SparkSession.builder.appName("SparkSQLBasicOperations").getOrCreate()# 读取 JSON 文件并创建 DataFrame
employee_dflzy = spark.read.json("/root/Desktop/luozhongye/employee.json")
(1)查询所有数据;
employee_dflzy.show()
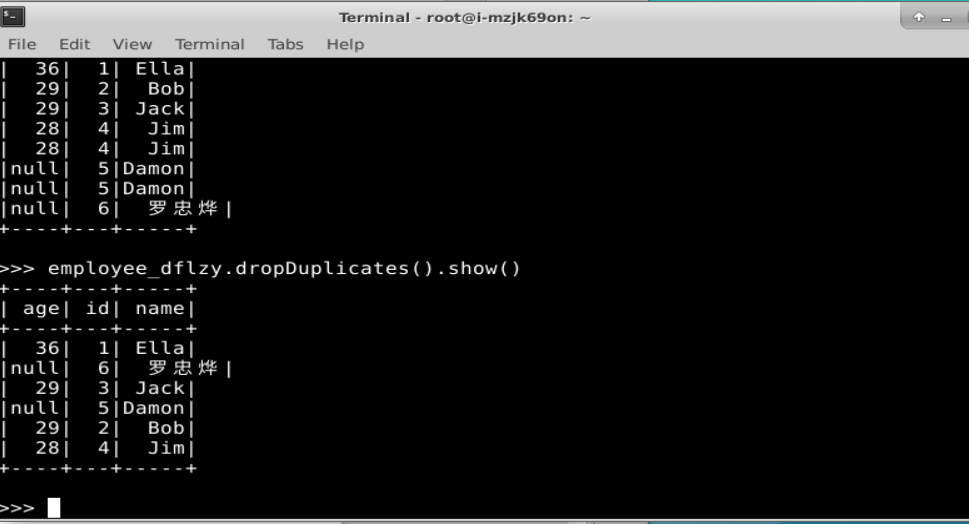
(2)查询所有数据,并去除重复的数据;
employee_dflzy.dropDuplicates().show()
(3)查询所有数据,打印时去除 id 字段;
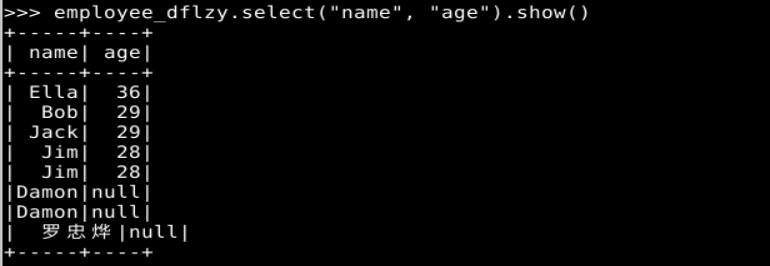
employee_dflzy.select("name", "age").show()
(4)筛选出 age>30 的记录;
employee_dflzy.filter(employee_dflzy["age"] > 30).show()

(5)将数据按 age 分组;
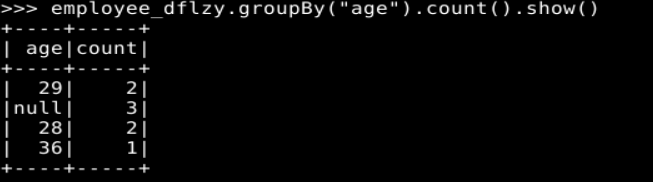
employee_dflzy.groupBy("age").count().show()
(6)将数据按 name 升序排列;
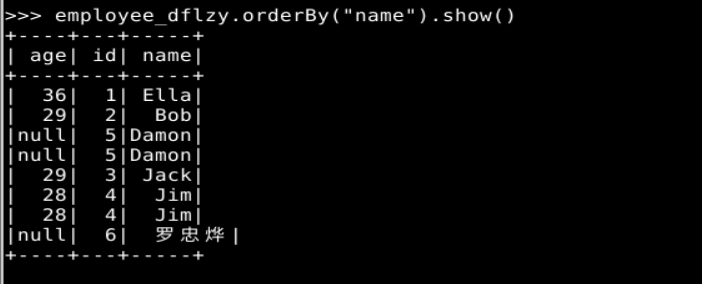
employee_dflzy.orderBy("name").show()
(7)取出前 3 行数据;
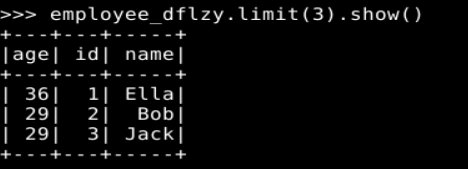
employee_dflzy.limit(3).show()
(8)查询所有记录的 name 列,并为其取别名为 username;
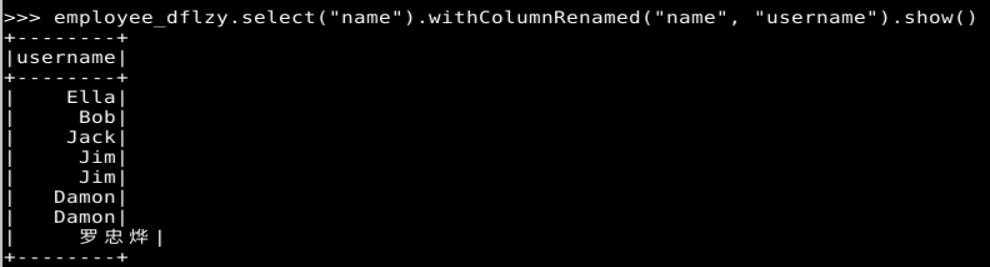
employee_dflzy.select("name").withColumnRenamed("name", "username").show()
(9)查询年龄 age 的平均值;
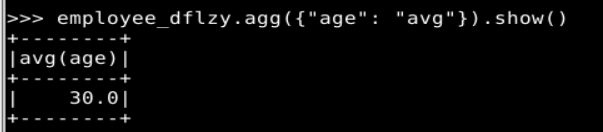
employee_dflzy.agg({"age": "avg"}).show()
(10)查询年龄 age 的最小值。
employee_dflzy.agg({"age": "min"}).show()

(11)停止 SparkSession
spark.stop()
2. 编程实现将 RDD 转换为 DataFrame
源文件employee.txt内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
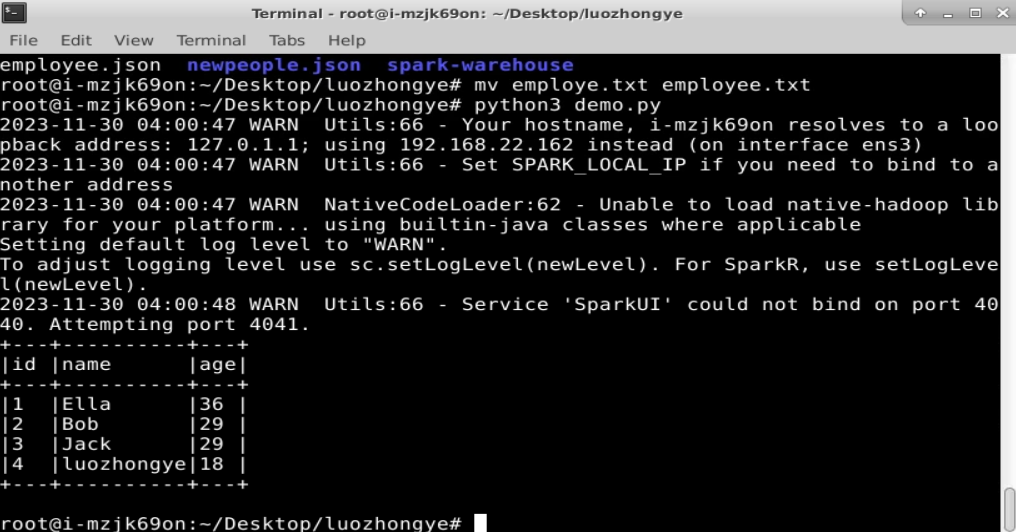
实现从 RDD 转换得到 DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType# 创建 SparkSession
spark = SparkSession.builder.appName("RDDtoDataFrame").getOrCreate()# 读取文本文件并创建 RDD
rdd = spark.sparkContext.textFile("/root/Desktop/luozhongye/employee.txt")# 定义数据模式
schema = StructType([StructField("id", IntegerType(), True),StructField("name", StringType(), True),StructField("age", IntegerType(), True)
])# 将 RDD 转换为 DataFrame
employee_df = rdd.map(lambda line: line.split(",")).map(lambda x: (int(x[0]), x[1], int(x[2]))).toDF(schema=schema)# 打印 DataFrame 的所有数据
employee_df.show(truncate=False)# 停止 SparkSession
spark.stop()
3. 编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee, 包含下表 所示的两行数据。
| id | name | gender | age |
|---|---|---|---|
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
-- 创建数据库
CREATE DATABASE IF NOT EXISTS sparktest;-- 切换到 sparktest 数据库
USE sparktest;-- 创建 employee 表
CREATE TABLE IF NOT EXISTS employee (id INT PRIMARY KEY,name VARCHAR(255),gender CHAR(1),age INT
);-- 插入数据
INSERT INTO employee VALUES (1, 'Alice', 'F', 22), (2, 'John', 'M', 25);(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入表 5-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
| id | name | gender | age |
|---|---|---|---|
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
from pyspark.sql import SparkSession
from pyspark.sql import DataFrame# 创建 SparkSession
#"/path/to/mysql-connector-java-x.x.xx.jar":实际的 MySQL Connector/J JAR 文件路径。
spark = SparkSession.builder.appName("MySQLDataFrame").config("spark.jars", "/path/to/mysql-connector-java-x.x.xx.jar"
).getOrCreate()# 读取数据到 DataFrame
employee_data = [(3, 'Mary', 'F', 26), (4, 'Tom', 'M', 23)]
columns = ["id", "name", "gender", "age"]
new_data_df = spark.createDataFrame(employee_data, columns)# 配置 MySQL 连接信息
mysql_url = "jdbc:mysql://localhost:3306/sparktest"
mysql_properties = {"user": "your_username",# 实际的 MySQL 用户名"password": "your_password",# 实际的 MySQL 密码"driver": "com.mysql.cj.jdbc.Driver"
}# 将数据写入 MySQL 表
new_data_df.write.jdbc(url=mysql_url, table="employee", mode="append", properties=mysql_properties)# 从 MySQL 中读取数据到 DataFrame
employee_df = spark.read.jdbc(url=mysql_url, table="employee", properties=mysql_properties)# 打印 DataFrame 的所有数据
employee_df.show()# 打印 age 的最大值和总和
employee_df.agg({"age": "max", "age": "sum"}).show()# 停止 SparkSession
spark.stop()
本文结束欢迎点赞,收藏,有问题可以在评论区讨论!