文章目录
- 前言
- 一、安装库 scikit-fuzzy
- 二、具体程序代码(复制可运行)
- 三、结果展示
- 总结
前言
模糊C均值(Fuzzy C-means,FCM)聚类是一种软聚类方法,它允许数据点属于多个聚类,每个数据点对所有聚类的隶属度都不同。这种方法在处理具有不确定性和模糊性的数据时非常有效。
一、安装库 scikit-fuzzy
pip install scikit-fuzzy -i https://pypi.tuna.tsinghua.edu.cn/simple
二、具体程序代码(复制可运行)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import skfuzzy as fuzz
import matplotlib
matplotlib.use('TkAgg')# 加载鸢尾花数据集
iris = datasets.load_iris()
data = iris.data# 设置模糊C均值聚类的参数
n_clusters = 3 # 聚类数目
max_iter = 100 # 最大迭代次数
fuzziness = 2.0 # 模糊度# 运行模糊C均值聚类算法
cntr, u, u0, d, jm, p, fpc = fuzz.cluster.cmeans(data.T, n_clusters, m=fuzziness, error=0.005, maxiter=max_iter, init=None)# 获取最大隶属度的聚类标签
cluster_labels = np.argmax(u, axis=0)# 绘制聚类图
colors = ['r', 'g', 'b']
for i in range(n_clusters):cluster_points = data[cluster_labels == i]plt.scatter(cluster_points[:, 0], cluster_points[:, 1], c=colors[i], label=f'Cluster {i+1}')plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
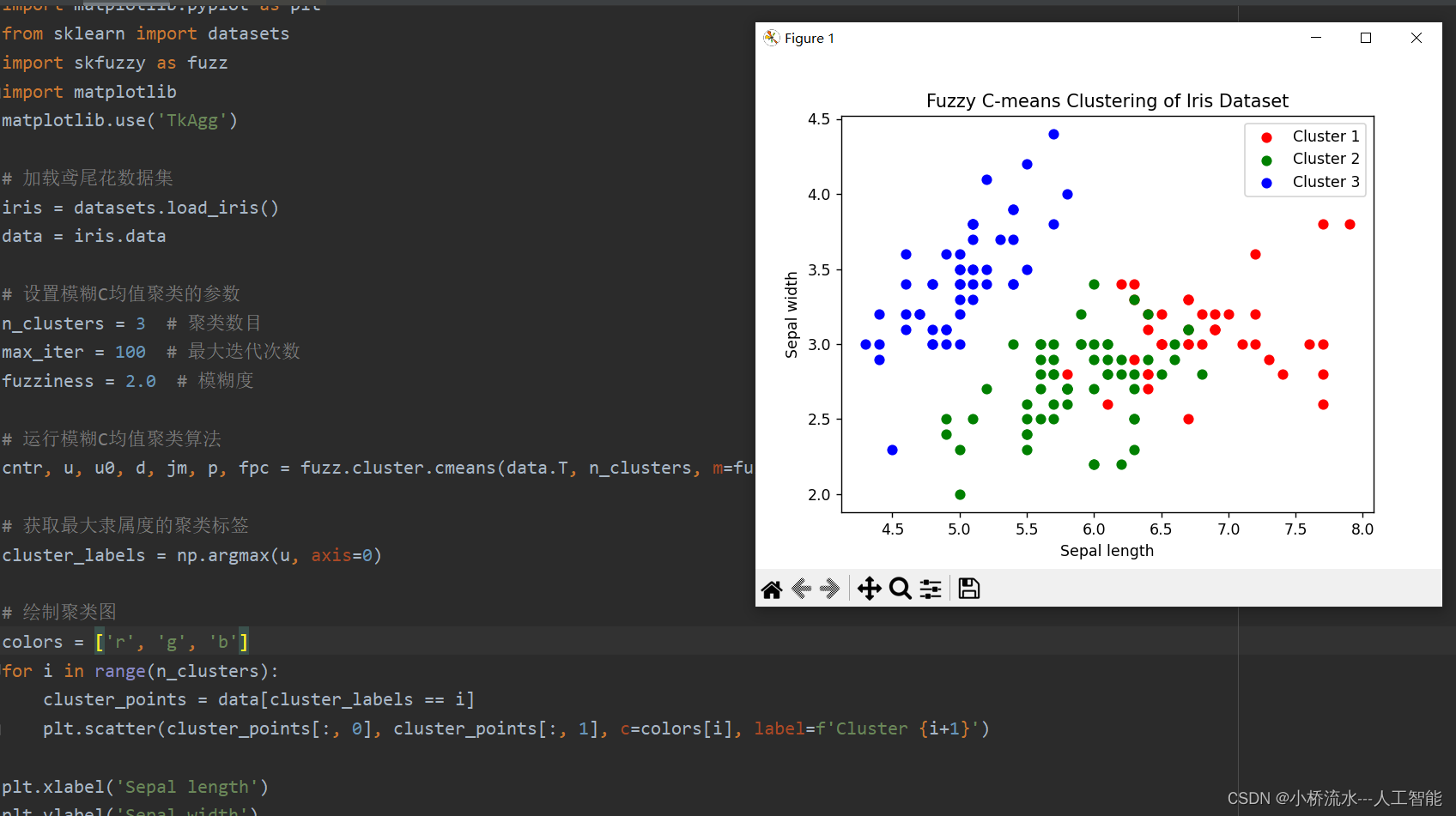
plt.title('Fuzzy C-means Clustering of Iris Dataset')
plt.legend()
plt.show()
三、结果展示
总结
详细的代码解释请看我的下一篇博客!