流式处理引擎,颠覆50年未变的数据库内核
流式处理的概念
2001年9月11日,美国世贸大楼被袭击,美国国防部第一次将“主动预警”纳入国防的宏观战略规划。而IBM作为当时全球最大的IT公司,承担了大量基础支撑软件研发的任务。其中2009年正式发布的IBM InfoSphere Streams,就是全球最早真正意义上的商业化流数据处理引擎之一。
典型的流处理框架,如Apache Storm、Spark Streaming、Flink等也都是基于IBM的设计理念,采用“请求发送+结果返回”的模式进行了研发,并大量应用于实时互联网类型的业务中,对前方产生的海量事件进行实时预处理。
Gartner在《2022中国数据库管理系统市场指南》中,将流处理定义为:涉及对“事件”(event)的观察和触发,通常在“边缘”采集,包括将处理结果传输至其他业务阶段。并将在未来五年中,获得更多关注。

图:Gartner对于流/事件处理的定义
传统部署架构的痛点
但是,不论Apache Storm、Spark Streaming、还是Flink等流处理框架的设计,都是将目光集中在“处理”本身。由于其自身不具备数据库的能力,当需要与其他数据进行关联、临时存储等互动时,则需要进行复杂的数据抽取。这使得大量的开发人员,还需要编写复杂的Java/C++/Scala代码,用最传统的方式对记录进行一条条预处理,并且还需要经常从其他外部的缓存/数据库中实时调取额外数据进行手工关联,开发和运维的负担极大。
在亚信科技AntDB数据库发展的十几年中,我们看到大量运营商对核心数据处理加工的业务场景。这些需求中,有些能够很容易地使用传统技术满足,但还有一些一定需要采用流式计算等实时处理能力才能支持。
数据库与流式处理的有机融合
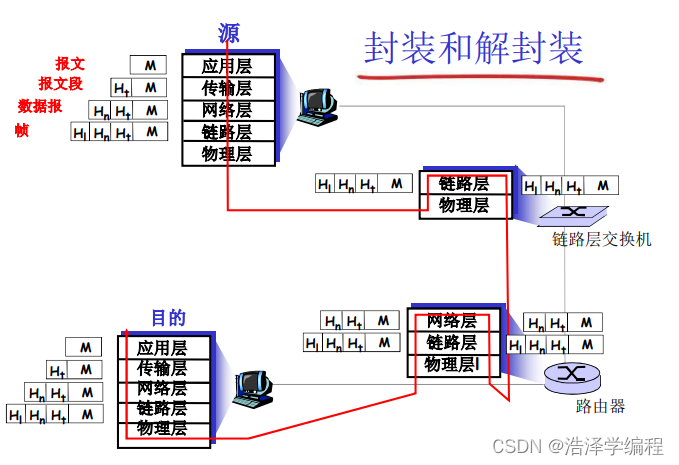
流数据处理模式与传统数据库的内核设计有着极大的区别。其核心本质在于,传统数据库架构设计中,应用与数据库之间是“请求-响应“的关系,即业务发起SQL请求,数据库随即执行请求并返回结果。
而流处理内核则是“订阅-推送“的模式。通过预先定义好的数据处理模型,对数据承载的业务“事件”进行处理,之后将处理后的结果推送给下游应用进行展现或入库。
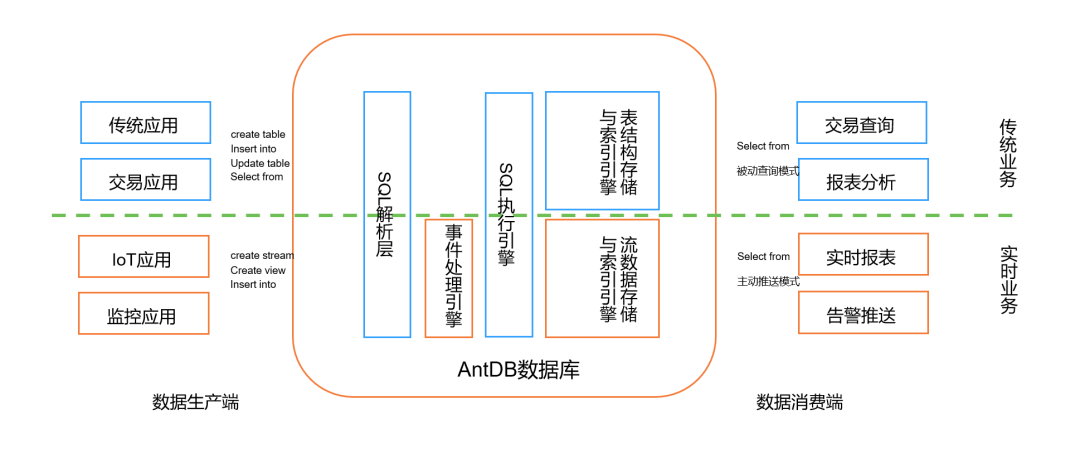 图:AntDB数据库流式处理引擎的基础架构
图:AntDB数据库流式处理引擎的基础架构
因此在流式数据实时处理领域,亚信科技AntDB数据库做了大量从零开始的创新性探索与研究,于2022年底推出AntDB-S流处理数据库引擎,彻底将流式计算与传统交易、分析型数据存储进行了融合,让用户可以在数据库引擎内,通过标准SQL自由定义数据的结构以及实时处理逻辑。
同时数据在数据库内部的流对象、表对象之间自由流转的过程中,用户可以随时通过建立索引、流表关联、触发器、物化视图等方式对数据进行性能优化、数据加工、集群监控、以及业务逻辑定制。
功能优势
-
技术堆栈简化:在实时流事件的处理上,AntDB数据库流式处理一体引擎将大量的实时数据处理做到数仓内部,更进一步向通用事务靠拢。
-
标准SQL定义:传统流处理方式对于SQL的处理很弱,还要写大量业务代码,而AntDB-S可以通过统一SQL语句进行处理,在流的使用上更便捷。
-
统一数据接口:支持流批模式的转换,AntDB数据库统一超融架构,实现了对外的接口统一,数据的采集与处理无需分开,流批都用SQL即可全部搞定。
-
支持完整事务处理:传统流处理过程中不支持数据的修改,AntDB-S支持流处理中对数据的修改和事务操作。
-
实时结果更准确:通过分布式事务的ACID特性,解决实时流数据处理中,数据容灾和一致性的问题,可以精确判断数据故障点,完成流事件的矫正计算和重统计。
关于AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。