目录
- 1.概述
- 2.代码实现
- 3.应用
更多数据结构与算法的相关知识可以查看数据结构与算法这一专栏。
有关字符串模式匹配的其它算法:
【算法】Brute-Force 算法
【算法】KMP 算法
1.概述
(1)Rabin-Karp 算法是由 Richard M. Karp 和 Michael O. Rabin 于 1987 提出的字符串匹配算法,它的基本思想是利用哈希函数对字符串进行编码,通过比较哈希码来判断是否可能发生匹配,并在发生哈希碰撞时进一步验证字符串是否匹配。
(2)Rabin-Karp 算法的步骤如下:
- ① 计算模式字符串的哈希码。
- ② 计算目标串中同样长度的窗口字符串的哈希码。
- ③ 比较窗口字符串的哈希码和模式字符串的哈希码:
- 如果哈希码相同,进行进一步比较确认是否匹配。
- 如果哈希码不同,移动窗口到下一个位置,通过哈希码滑动更新窗口的哈希码。
- ④ 重复步骤 ③,直到找到匹配或遍历完整个文本字符串。
Rabin-Karp 算法的关键点是哈希函数的选择和哈希码的比较。一个好的哈希函数应该能够实现高效计算和压缩成较小的哈希码,以提高算法的效率。而比较哈希码可能会产生哈希碰撞,即不同字符串具有相同的哈希码。当发生哈希碰撞时,需要通过进一步的比较来确定字符串是否匹配。
(3)在Rabin-Karp算法中,计算字符串的哈希值通常采用的方式是基于进制转换的方法。具体而言,我们可以使用多项式哈希 (polynomial hashing) 来计算字符串的哈希值。考虑一个字符串 s,其中包含 n 个字符,字符的 ASCII 值分别为 c1, c2, …, cn。我们选择一个适当的基数,通常是 ASCII 表的大小,这里假设为 256。我们还选择一个素数,通常是 Rabin-Karp 算法的参数,这里假设为 101。那么,字符串 s 的哈希值 H(s) 计算方式如下:
H ( s ) = ( ( c 1 × p ( n − 1 ) ) + ( c 2 × p ( n − 2 ) ) + . . . + ( c n × p 0 ) ) % M H(s) = ((c_1 × p^{(n-1)}) + (c_2 × p^{(n-2)}) + ... + (c_n × p^0)) ~ \% ~ M H(s)=((c1×p(n−1))+(c2×p(n−2))+...+(cn×p0)) % M
其中,p 表示进制数(这里是 256),n 表示字符串的长度,M 表示选择的素数(这里是 101)。例如,模式字符串 “ABAB” 的哈希值为 ((65 × 2563) + (66 × 2562) + (65 × 2561) + (66 × 2560)) % 101 = 13。
通过将字符的 ASCII 值乘以进制数的幂次方,并对结果进行求和,再对素数 M 取模,即可得到字符串的哈希值。这种计算方法具有较好的散列性质,可以在较小的哈希空间中尽可能地减少碰撞的发生。
(4)让我们通过一个例子来说明 Rabin-Karp 算法的工作过程。首先,假设我们有以下文本和模式字符串:文本串 “ABABABABC” 以及模式串 “ABAB”。此外,我们选择基数为 256,素数为 101 作为算法的参数。
- 首先,我们计算模式字符串 “ABAB” 的哈希值为 13。
- 接下来,我们计算文本中第一个与模式字符串等长的子串 “ABAB” 的哈希值。它的哈希值也为 13。
- 由于哈希值相等,我们需要进行进一步的检查。我们比较模式字符串 “ABAB” 和文本中的子串 “ABAB” 字符串是否完全匹配。在此例中,它们是完全匹配的。
- 如果我们没有找到匹配,我们需要通过滑动窗口的方式来更新子串的哈希值。在这种情况下,我们将滑动窗口向右移动一个位置,得到下一个子串 “BABA” 的哈希值。
- 我们重复这些步骤,直到找到所有匹配的位置。
(5)上面需要注意的是,我们可以通过当前窗口字符串 “ABAB” 的哈希值来直接计算下一个窗口字符串 “BABA” 的哈希值,从而避免再次遍历 “BABA” 来计算其哈希值,提高了效率。我们以下图(来自《算法导论》)来说明:
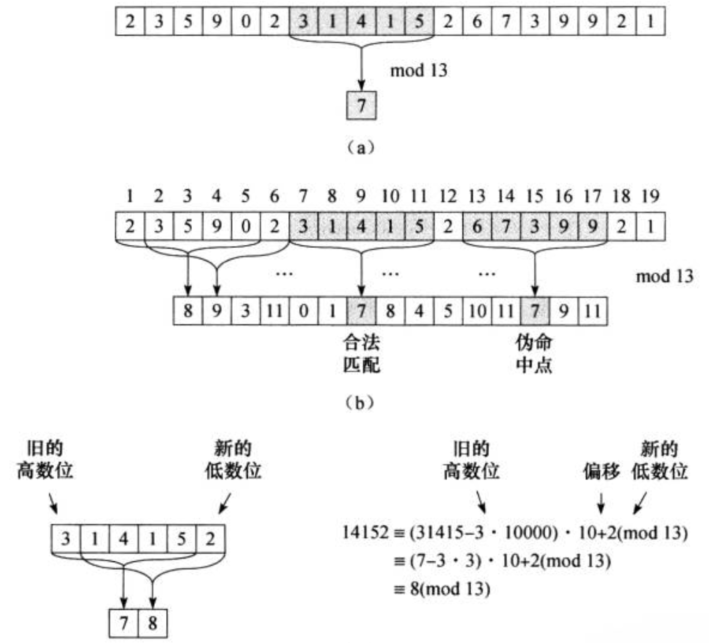
为了方便说明,我们可以将字符串看作对应的数字字符串,再上图中,我们可以快速通过哈希值 31415 来计算下一个窗口的哈希值 14152(取模之后再计算也是一样的效果)。其主要思想在于 31415 的低 4 位与 14152 的高 4 位相同,并且我们知道 31415 的最高位与 14152 的最低位哦,因此只需要简单的数学计算便可以得到下一个窗口字符串的哈希值,从而保证在常数时间内更新下一个窗口字符串的哈希值。
2.代码实现
(1)Rabin-Karp 算法的代码实现如下:
class RabinKarpAlgorithm {//用于取哈希值时的除法因子private static final int PRIME = 101;//字符集的大小private static final int RADIX = 256;/** s: 目标串* t: 模式串* 返回值: 模式串在目标串中所有匹配成功的位置* */public List<Integer> rabinKarp(String s, String t) {List<Integer> indices = new ArrayList<>();int sLen = s.length();int tLen = t.length();int h = 1;for (int i = 0; i < tLen - 1; i++) {h = (h * RADIX) % PRIME;}//初始化窗口内字符串和模式串的哈希值int sHash = 0;int tHash = 0;for (int i = 0; i < tLen; i++) {sHash = (sHash * RADIX + s.charAt(i)) % PRIME;tHash = (tHash * RADIX + t.charAt(i)) % PRIME;}for (int i = 0; i <= sLen - tLen; i++) {//当前窗口中字符串的哈希码与模式串的哈希码相同if (sHash == tHash) {//检查窗口中字符串 s[i...i + tLen - 1] 是否与模式串 t 相等int j;for (j = 0; j < tLen; j++) {if (s.charAt(i + j) != t.charAt(j)) {break;}}if (j == tLen) {//匹配成功indices.add(i);}}if (i == sLen - tLen) {return indices;}//更新窗口中字符串的哈希值sHash = ((sHash - s.charAt(i) * h) * RADIX + s.charAt(i + tLen)) % PRIME;if (sHash < 0) {sHash += PRIME;}}return indices;}
}
(2)上述代码的测试如下:
class Test {public static void main(String[] args) {RabinKarpAlgorithm rabinKarpAlgorithm = new RabinKarpAlgorithm();String s = "cvbzxcvbnmacvb";String t = "cvb";List<Integer> indices = rabinKarpAlgorithm.rabinKarp(s, t);System.out.println(indices);}
}
输出结果如下:
[0, 5, 11]
3.应用
(1)Rabin-Karp 算法是一种常用的字符串匹配算法,适用于以下几个应用场景:
- 字符串匹配:Rabin-Karp 算法可以用于在一个长文本串中高效地查找一个模式串的出现位置。它通过使用哈希函数和滚动哈希的技巧,在线性时间内完成匹配操作。
- 模式匹配:Rabin-Karp 算法可用于检测一个文本串中是否包含指定的模式串。这在文本搜索、文件内容查找等应用中非常有用。
- 字符串去重:Rabin-Karp 算法可以用于快速识别和去重重复的子串。通过计算子串的哈希值,并使用哈希表或哈希集合来记录已经出现的子串,可以高效地实现字符串去重的功能。
- 数据校验:Rabin-Karp 算法可以用于快速计算数据块的哈希值,可以在数据传输或存储过程中用来验证数据的完整性。通过对比哈希值,可以判断数据是否被篡改或损坏。
(2)大家可以去 LeetCode 上找相关的字符串匹配的题目来练习,或者也可以直接查看 LeetCode 算法刷题目录 (Java) 这篇文章中的字符串章节。如果大家发现文章中的错误之处,可在评论区中指出。