前言
书接前文,马不停蹄,博主继续书写Cache的传奇和精彩。
Redis主要用于数据的分布式缓存,通过设置缓存集群,实现数据的快速响应,同时也解决了缓存一致性的困扰。
EhCache主要用于数据的本地缓存,因无法保障数据的安全性,通常用于单节点数据的缓存。如果需要实现分布式,可以搭载Redis实现二级缓存。
今天博主带来Cache新成员:MemCache,它又有哪些独一无二的绝技呢?请各位盆友紧随博主,以防“迷路”。
- 微服务实战系列之EhCache
- 微服务实战系列之Redis
- 微服务实战系列之Cache
- 微服务实战系列之Nginx(技巧篇)
- 微服务实战系列之Nginx
- 微服务实战系列之Feign
- 微服务实战系列之Sentinel
- 微服务实战系列之Token
- 微服务实战系列之Nacos
- 微服务实战系列之Gateway
- 微服务实战系列之加密RSA
- 微服务实战系列之签名Sign

Q:什么是MemCache
看到MemCache一词,首先想到什么?内存。可见它又是一款基于内存的缓存工具。那继续看官方是如何定义的,请转向:
MemCache是一个免费开源、高性能的分布式内存对象缓存系统,旨在通过减轻数据库负载来加速动态web应用程序。
MemCache开放的API可支持Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序语言。
通过以上描述,表明MemCache支持分布式,倘若我们构建分布式缓存时,又多了一件可选择的武器。

既然提到了分布式,那是如何实现的呢?我们继续期待。
Q:MemCache如何实现分布式
这首先要看MemCache是如何运转的。
1. 内存机制
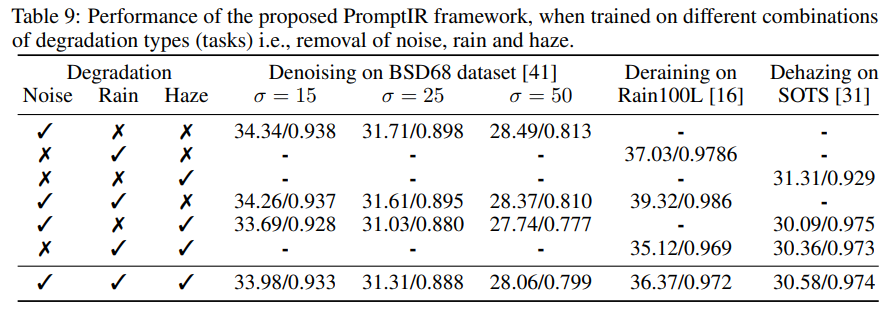
MemCache是一个基于内存的缓存系统,对内存的管理自然有一套严格的标准(slab负责管理),让我们把目光聚焦下图:

MemCache将内存空间分割为若干slab组(class),每个slab又分割为若干page(每个page默认是1M),而每个page又分为若干chunk。总结一句话:“MemCache最终把数据存于chunk中”。
MemCache为了快速管理内存和分配内存,将已使用内存和未使用内存,编制为一个链表结构。对于新加入的数据,先更新header(H);对应过期的数据,先更新Tail(T)。
为了将新加入的数据合理存储,MemCache会通过计算将其放在与其大小“相当”的slab中。因此一定程度上容忍内存“浪费”。
当然鉴于MemCache的内存机制,也提出了一些基础限制。
比如单条数据(Item)最大不超1M,又比如key最大不超250字符等等,在此博主不再赘述,可以另行查阅相关文档。
2. 分布式实现
MemCache的分布式无法自己完成,通常是由MemCache客户端API负责实现。通过基于一致Hash算法,完成节点(node)匹配和节点路由(router),最终实现数据的分布式缓存。

这么来看,MemCache分布式是不是很简洁?博主不禁感叹:“这是一个被算法支配的世界”。
当然如何安装和使用它,可以参考其他博主文章,相对简单,这里不再表述。
Q:MemCache适应场景有哪些
MemCache基于内存,必然消失于内存,比如重启服务器,针对于开发人员而言,简直是个灾难。
因此它适合存储无需持久化的数据且数据量不宜太大,因此分布式是一个很好的选择。正如“鸡蛋不宜放在同一个篮子”一样,数据也不宜放在同一个slab。
结语
MemCache作为分布式缓存的另一选项,势必为微服务提供了一定的技术可能。我们说内存一般决定性能,性能高低势必影响最终的用于体验。
如何选择合适的Cache的工具或系统,取决于业务场景和形式。抛开业务谈技术皆是耍流氓,希望各位盆友明辨取舍的关键。
好了,各位盆友,今天的话题到此结束,期待大家的反馈和分享,甚至讨论(热烈期待中…)。