在本文中,我将分享4个在一行代码中完成的Pandas操作。这些操作可以有效地解决特定的任务,并以一种好的方式给出结果。

从列表中创建字典
我有一份商品清单,我想看看它们的分布情况。更具体地说:希望得到唯一值以及它们在列表中出现的次数。
Python字典是以这种格式存储数据的好方法。键将是字典,值是出现的次数。
这里可以使用value_counts和to_dict函数,这项任务可以在一行代码中完成。
这里有一个简单的例子来说明这种情况:
importpandasaspdgrades= ["A", "A", "B", "B", "A", "C", "A", "B", "C", "A"]pd.Series(grades).value_counts().to_dict()# output{'A': 5, 'B': 3, 'C': 2}
将列表转换为Pandas Series,这是Pandas的一维数据结构,然后应用value_counts函数来获得在Series中出现频率的唯一值,最后将输出转换为字典。这个操作非常高效且易于理解。
从JSON文件创建DataFrame
JSON是一种常用的存储和传递数据的文件格式。
当我们清理、处理或分析数据时,我们通常更喜欢使用表格格式(或类似表格的数据)。由于json_normalize函数,我们可以通过一个操作从json格式的对象创建Pandas DataFrame。
假设数据存储在一个名为data的JSON文件中。一般情况我们都是这样读取:
importjsonwithopen("data.json") asf:data=json.load(f)data# output{'data': [{'id': 101,'category': {'level_1': 'code design', 'level_2': 'method design'},'priority': 9},{'id': 102,'category': {'level_1': 'error handling', 'level_2': 'exception logging'},'priority': 8}]}
如果我们将这个变量传递给DataFrame构造函数,它将创建如下的DataFrame,这绝对不是一个可用的格式:
df=pd.DataFrame(data)

但是如果我们使用json_normalize函数将得到一个整洁的DataFrame格式:
df=pd.json_normalize(data, "data")

Explode函数
如果有一个与特定记录匹配的项列表。需要重新格式化它,为该列表中的每个项目提供单独的行。
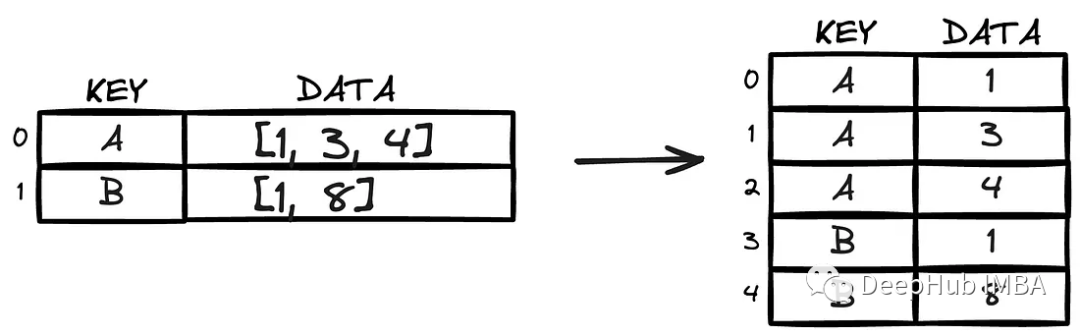
这是一个经典的行分割成列的问题。有许多的不同的方法来解决这个任务。其中最简单的一个(可能是最简单的)是Explode函数。
我们以这个df为例

使用explosion函数并指定列名:
df_new=df.explode(column="data").reset_index(drop=True)
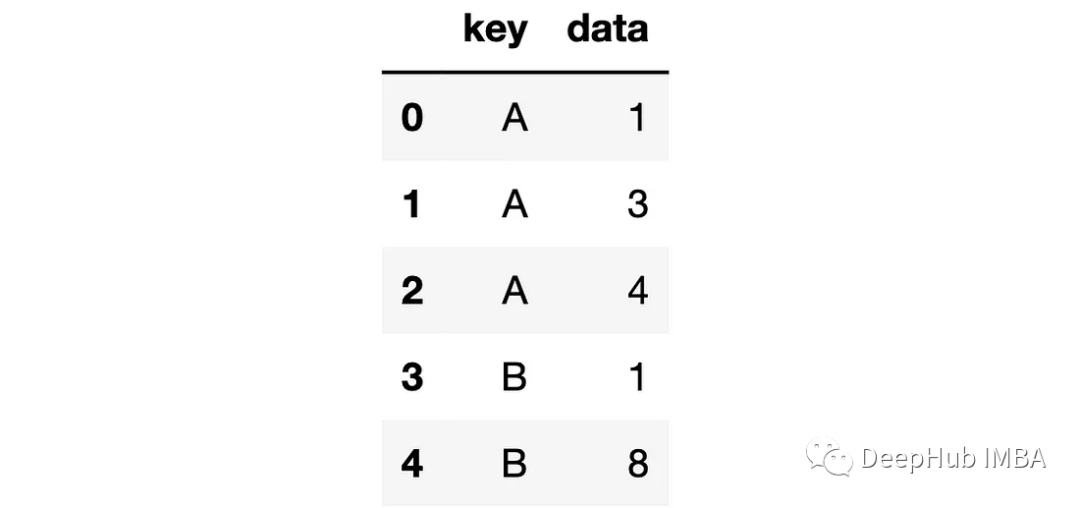
reset_index会为DataFrame分配一个新的整数索引。
combine_first函数
combine_first函数用于合并两个具有相同索引的数据结构。
它最主要的用途是用一个对象的非缺失值填充另一个对象的缺失值。这个函数通常在处理缺失数据时很有用。在这方面,它的作用与SQL中的COALESCE函数相同。
df=pd.DataFrame({"A": [None, 0, 12, 5, None], "B": [3, 4, 1, None, 11]})
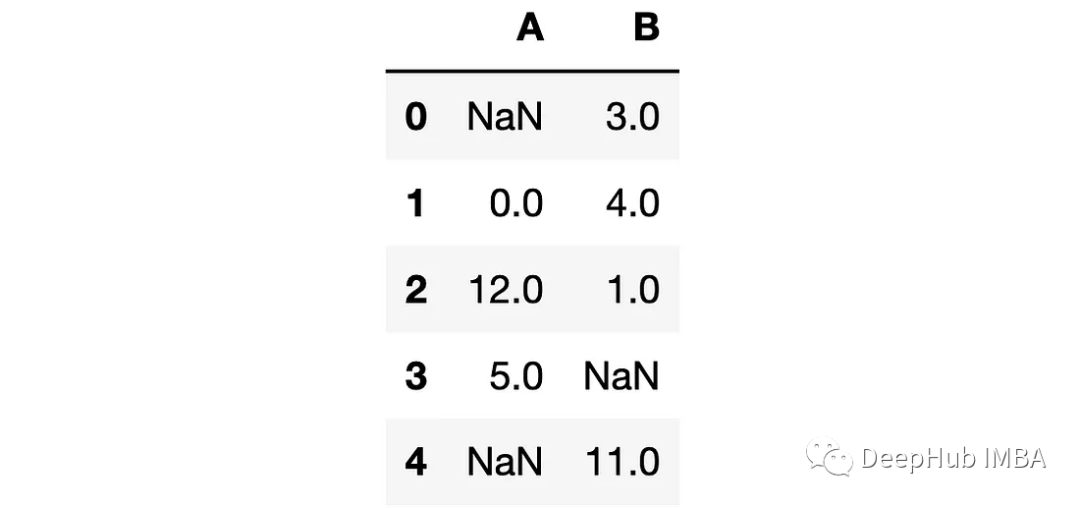
我们需要a列中的数据。如果有一行缺少值(即NaN),用B列中同一行的值填充它。
df["A"].combine_first(df["B"])# output0 3.01 0.02 12.03 5.04 11.0Name: A, dtype: float64
可以看到的列A的第一行和最后一行取自列B。
如果我们想要使用3列,我们可以链接combine_first函数。下面的代码行首先检查列a。如果有一个缺失的值,它从列B中获取它。如果列B中对应的行也是NaN,那么它从列C中获取值。
df["A"].combine_first(df["B"]).combine_first(df["C"])
我们还可以在DataFrame级别使用combine_first函数。在这种情况下,所有缺失的值都从第二个DataFrame的相应值(即同一行,同列)中填充。
df1=pd.DataFrame({'A': [1, 2, np.nan, 4], 'B': [5, np.nan, 7, 8]}, index=['a', 'b', 'c', 'd'])df2=pd.DataFrame({'A': [10, np.nan, 30, 40], 'B': [50, 60, np.nan, 80]}, index=['a', 'b', 'c', 'd'])result_df=df1.combine_first(df2)
在合并的过程中,
df1
中的非缺失值填充了
df2
中对应位置的缺失值。这有助于处理两个数据集合并时的缺失值情况。
MergedDataFrame:A Ba 1.0 5.0b 2.0 60.0c 30.0 7.0d 4.0 8.0
总结
从计算简单的统计数据到高度复杂的数据清理过程,Pandas都可以快速解决任务。上面的代码可能不会经常使用,但是当你需要处理这种任务时,它们是非常好的解决办法。
https://avoid.overfit.cn/post/1e70db7ef5534ff0801316609a1499b1
作者:Soner Yıldırım