🍅 点击文末小卡片 ,免费获取网络安全全套资料,资料在手,涨薪更快
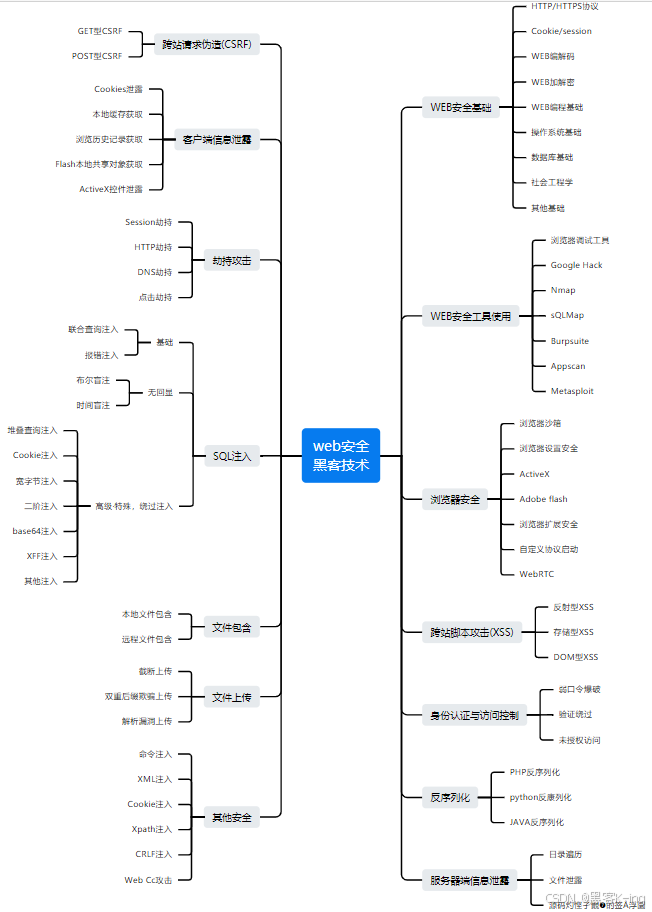
前端常见的网络安全包括:xss(跨站脚本攻击)、csrf(跨站请求伪造)、sql注入攻击等。
1)跨站脚本攻击(xss)
原理:
攻击者往web页面中注入恶意 script 代码(或者在url的查询参数中注入 script 代码),当用户浏览访问时,嵌入的 script 代码就会执行,造成危害。
反射型xss:用户点击攻击连接,服务器解析后响应,在返回的内容中包含xss的恶意攻击脚本,被浏览器执行。一般通过发送恶意url,让用户点击达到目的;
持久型xss:web server 保存了恶意 xss 脚本,每一个访问的用户都被攻击。一般通过博客、论坛等可以动态录入内容的途径,达到攻击的目的;
防御:
对用户的输入内容进行过滤,对输出在网页上的内容进行转译或编码。
常见的过滤 xss 三大技术:过滤(<script><a><img>,有的删除其中的内容,有的过滤掉on事件和javascript字符串)、编码(常见字符如“<”“>”进行编码或转译)、限制(限制url的长度)。
2、跨站请求伪造(csrf)
原理:
用户打开A网站,输入用户名和密码进行登录,获得A网站的访问权限。此时不关闭浏览器,另开一个tab页访问B网站(恶意网站),B网站收到请求后,返回一些攻击性的代码,发请求访问A网站,由于操作用户本身具有A网站的访问权限,因此就能达到攻击的目的。
防御:
验证 http 的 Referrer 字段,确认访问来源;
在请求地址中添加 token,并进行验证;
在 http 头中自定义属性并进行验证(例如:XMLHttpRequest 中可以加入 csrfToken 属性)
3、sql 注入攻击
原理:
把 sql 命令插入 web 表单进行提交,或通过查询字符串进行提交,达到欺骗服务器,到后台执行恶意 sql 脚本的目的。
防御:
后台 sql 语句的执行用查询参数代替,例如:preparedStatement,动态的内容用?代替;
4、其它安全性
1)可以禁止 js 脚本访问 cookie。cookie 属性设置中,加入 httpOnly,然后就无法通过脚本获取 cookie 信息了;
2)可以升级 cookie 的传输协议。cookie 属性设置中,加入 secure,就会强制浏览器以 https 形式传递 cookie 到服务器;
3)X-Frame-Options。在 header 中添加了这个以后,那么用户将无法在 <iframe src=''> 中访问该网站。有三个级别(deny、sameorgin、allow from url);
4)启用内容安全策略 CSP。这个也需要在 header 中添加这个属性,添加后用来防御一定程度的“跨站脚本攻击”和“数据注入攻击”;
5)服务端和客户端的混合渲染,也容易被攻击,好的方式是:进行编码转译或严格过滤;
6)http 本身存在安全问题,例如:消息的明文发送、缺乏对消息完整性的验证;
7)目前针对 express 和 koa 有一个叫 helmet 的 npm 包,可以一次性设置很多的属性,来解决各类攻击问题,值得尝试。网址如下:
https://github.com/helmetjs/helmet
5、三大框架的安全性策略
主流的前端框架都实现了对 xss 的防御,结合服务端的 token 机制,更加可以防御 csrf。例如:vue.js 将所有动态输入的内容都渲染为纯文本,需要显示脚本的用v-html 进行显示。当然,vue 官方仍然建议不要将 v-html 用在动态提交的内容上,尽量避免例如原始 html 和使用 v-pre(跳过编译过程)。
个人统计【3】:2019-05-23、2019-05-24
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
上述所有都有配套的资料,这些资料,对于做【网络安全】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。



















