目录
前言
一、string类
二、初始化
1、无参或带参
2、用字符串变量初始化
3、用字符串初始化
4、指定数量字符
三、容量操作
1、size
2、push_back
3、append编辑
4、+=运算符
5、reserve
6、resize
四、迭代器
1、正向迭代器
2、反向迭代器
3、const迭代器 (正向反向)
五、OJ练习
反转字符
找出字符串中出现一次的字符
前言
string类模板如下,为什么会有好几个呢?
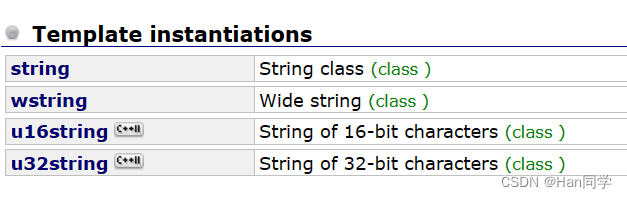
这些不同的string类模板是为了处理不同的字符编码和字符集。每个模板都专门用于处理特定类型的字符数据。
-
std::string:这是最常见的string类模板,用于处理ASCII字符集。它使用单字节字符表示,适用于大多数常规字符串操作。
-
std::wstring:这是宽字符版本的string类模板,用于处理Unicode字符。它使用wchar_t类型来表示字符,适用于需要处理多语言字符集的情况。
-
std::u16string:这是用于处理UTF-16编码的字符串的模板。UTF-16使用16位编码表示字符,适用于处理较大的字符集,如大部分Unicode字符。
-
std::u32string:这是用于处理UTF-32编码的字符串的模板。UTF-32使用32位编码表示字符,适用于处理包含所有Unicode字符的字符集。
这些不同的string类模板提供了对不同字符编码和字符集的支持,以便在处理不同类型的文本数据时能够正确地表示和操作字符。通过选择适当的string类模板,可以确保在不同的应用场景中正确处理和操作字符数据。
我们先来了解一下计算机存储字符的方式:
计算机中都是二进制形式,无法直接存储字母和符号,这时就需要一个映射表,ASCll就诞生了。
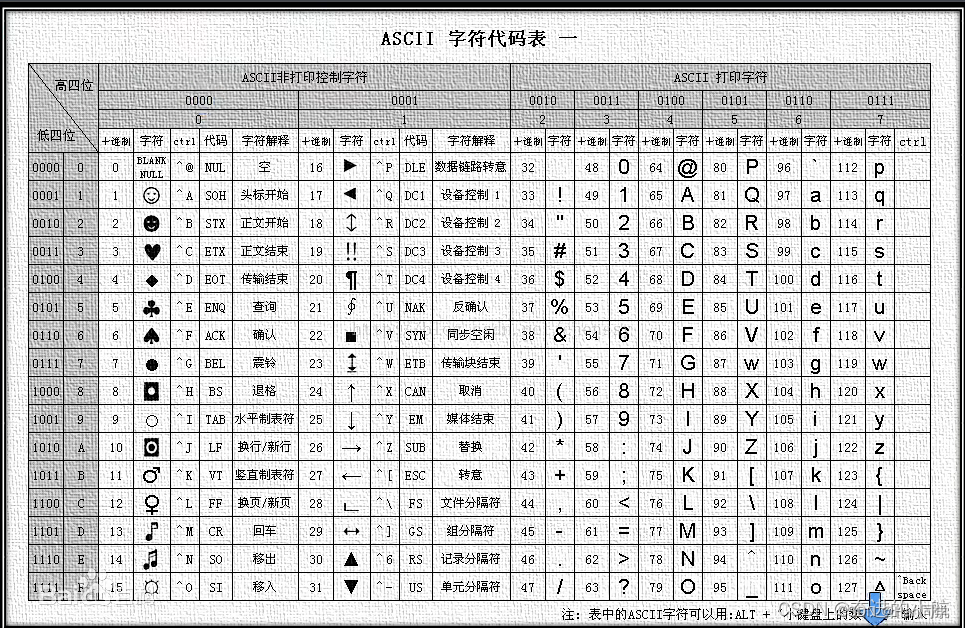
为了可以在计算机上显示多个国家的文字,unicode诞生了
统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
统一码是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
Unicode字符编码方案分为UTF-8、UTF-16和UTF-32,它们被设计用于在计算机系统中表示和处理不同范围的Unicode字符。
-
UTF-8:UTF-8是一种变长编码方案,它使用1到4个字节来表示不同的Unicode字符。它是最常用的Unicode编码方案之一,因为它可以兼容ASCII字符集,并且在表示常见字符时比较节省空间。UTF-8适用于在存储和传输文本数据时节省空间的情况,特别是在互联网和计算机网络中广泛使用。
-
UTF-16:UTF-16是一种定长或变长编码方案,它使用16位编码来表示Unicode字符。对于大部分常见的Unicode字符,UTF-16使用16位编码表示,但对于一些较少使用的字符,它需要使用两个16位编码来表示。UTF-16适用于需要处理较大字符集的情况,如多语言文本处理和国际化应用。
-
UTF-32:UTF-32是一种定长编码方案,它使用32位编码来表示Unicode字符。每个Unicode字符都使用32位编码表示,无论字符是否常见。UTF-32适用于需要处理包含所有Unicode字符的字符集的情况,如某些特定领域的文本处理和字符级操作。
这些不同的Unicode编码方案提供了不同的权衡和适用性,根据具体的需求和应用场景,可以选择适当的编码方案来表示和处理Unicode字符。
其中,UTF-8使用的最多 。

我们中国也有针对汉字的GBK编码,对一些生僻字提供了支持。
一、string类
文档介绍
- 字符串是表示字符序列的类,标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
- string类是使用char(即作为它的字符类型,使用它的默认char_traits和分配器类型(关于模板的更多信息,请参阅basic_string)。
- string类是basic_string模板类的一个实例,它使用char来实例化basic_string模板类,并用char_traits和allocator作为basic_string的默认参数(根于更多的模板信息请参考basic_string)。
- 注意,这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作。
- string是表示字符串的字符串类
- 该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作string的常规操作。
- string在底层实际是:basic_string模板类的别名,typedef basic_string<char, char_traits, allocator> string;
- 不能操作多字节或者变长字符的序列。
在使用string类时,必须包含#include头文件string以及using namespace std;
二、初始化
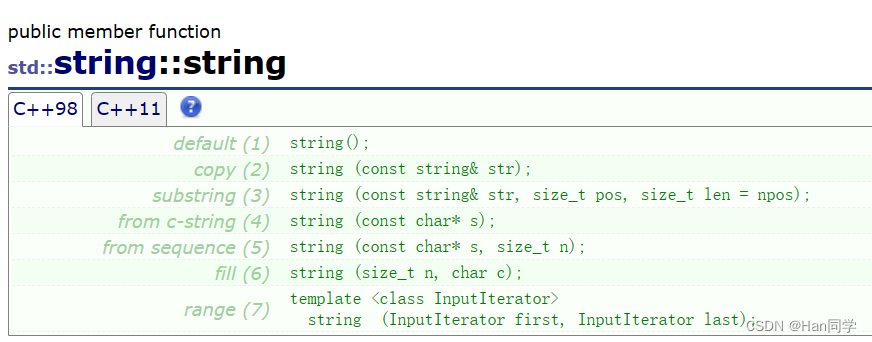
-
默认构造函数
string():创建一个空字符串对象。 -
复制构造函数
string(const string& str):通过复制另一个字符串对象str来创建一个新的字符串对象。 -
子字符串构造函数
string(const string& str, size_t pos, size_t len = npos):从字符串对象str的指定位置pos开始,创建一个新的字符串对象,长度为len。如果未提供len参数,默认创建到字符串末尾的子字符串。 -
从C-String构造函数
string(const char* s):从以空字符结尾的C字符串s创建一个新的字符串对象。 -
从序列构造函数
string(const char* s, size_t n):从C字符串s的前n个字符创建一个新的字符串对象。 -
填充构造函数
string(size_t n, char c):创建一个包含n个字符c的新字符串对象。 -
范围构造函数
template <class InputIterator> string(InputIterator first, InputIterator last):通过迭代器范围[first, last)中的字符创建一个新的字符串对象。这个构造函数可以接受不同类型的迭代器,例如指针、容器的迭代器等。
1、无参或带参
既可以无参初始化, 也可以带参初始化。
int main()
{string s1;string s2("hello world");string s3 = "hello";return 0;
}我们也可以通过[ ]操作符访问字符串某个位置。

#include<string>
int main()
{string s2("hello world");for (size_t i = 0; i < s2.size(); ++i) {s2[i]++;}cout << s2 << endl;return 0;
}我们可以通过流插入运算符<<输出string类对象。
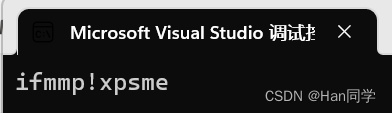
这是因为string类中对流插入运算符<<进行了重载,流提取也进行了重载。
int main()
{string s2;cin >> s2;for (size_t i = 0; i < s2.size(); ++i) {s2[i]++;}cout << s2 << endl;return 0;
} 
2、用字符串变量初始化
用一个字符的指定位置开始指定字符个数为另一个字符初始化。
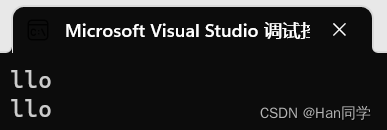
int main()
{string s3 = "hello";string s4(s3, 2, 3);cout << s4 << endl;return 0;
}
如果取字符的个数超过字符总长度,则取到末尾即可。
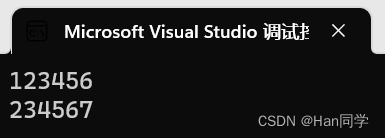
int main()
{string s3 = "hello";string s4(s3, 2, 3);cout << s4 << endl;string s5(s3, 2, 10);cout << s5 << endl;return 0;
} 
第三个参数取字符整数可以缺省,那么从指定位置开始取到末尾结束。
int main()
{string s3 = "hello";string s4(s3, 2, 3);cout << s4 << endl;string s5(s3, 2);cout << s5 << endl;return 0;
}
3、用字符串初始化
也可以把要赋值的字符串直接放在第一个参数位置,第二个参数为赋值字符个数。
int main()
{string s7("hello world", 5);cout << s7 << endl;string s8("hello world", 5 , 6);cout << s8 << endl;return 0;
}- 第一个构造函数中,除字符串如果只有一个参数,则默认从字符串第一个字符开始,赋值第二个参数大小长度。
- 第二个构造函数中,除字符串如果有两个参数,第一个参数为指定起始位置,第二个参数为指定的初始化长度,长度大于实际字符串的长度,则截断为实际字符串的长度。

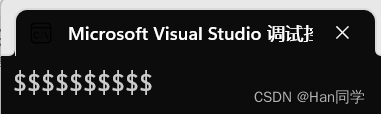
4、指定数量字符
int main()
{string s9(10, '$');cout << s9 << endl;return 0;
}
三、容量操作
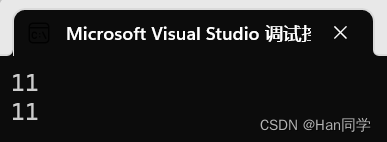
1、size
size()与length()底层实现原理完全相同,都用于获取字符串 有效字符长度, 引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()。
int main()
{string s1("hello world");cout << s1.size() << endl;cout << s1.length() << endl;return 0;
}
下面两个了解即可 :
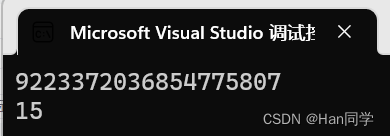
max_size()函数返回一个无符号整数,表示字符串对象可以容纳的最大字符数。这个值通常取决于系统的限制,因此可能会因操作系统和编译器而异。capacity()函数返回一个无符号整数,表示字符串对象当前分配的内存空间大小。这个值可能大于字符串实际包含的字符数,因为字符串类通常会预留一些额外的空间以便进行扩展。
int main()
{string s1("hello world");cout << s1.max_size() << endl;cout << s1.capacity() << endl;return 0;
}64位下输出结果:
2、push_back

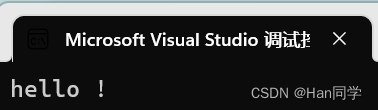
添加单个字符到字符串末尾
int main()
{string s1("hello");s1.push_back(' ');s1.push_back('!');cout << s1 << endl;return 0;
}
3、append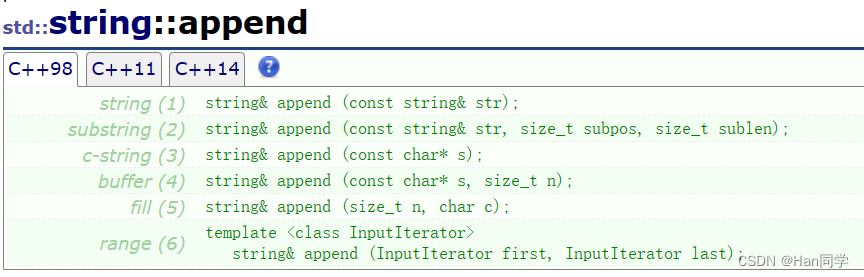
我们还可以使用append在字符串末尾添加单个字符或字符串 ,这种是最常用的形式。
int main()
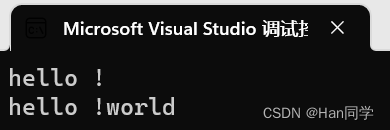
{string s1("hello");s1.push_back(' ');s1.push_back('!');cout << s1 << endl;s1.append("world");cout << s1 << endl;
}
4、+=运算符
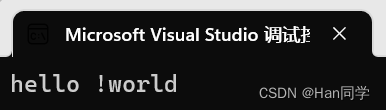
我们还可以使用+=运算符在字符串末尾添加字符或字符串,+=底层是调用push_back或append,在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
int main()
{string s1("hello");s1 += ' ';s1 += '!';s1 += "world";cout << s1 << endl;
}
5、reserve
先看下面代码:
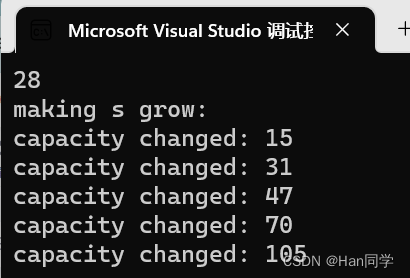
int main()
{size_t sz = s.capacity();cout << "making s grow:\n";cout << "capacity changed: " << sz << '\n';for (int i = 0; i < 100; ++i){s.push_back('c');if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << '\n';}}
}上述演示了如何使用push_back()函数向字符串对象中添加字符,并观察字符串的容量变化
- 首先,在
main()函数中声明了一个size_t类型的变量sz,并将其初始化为字符串对象s的容量(假设s是之前已经定义的字符串对象)。 - 然后,通过使用
cout对象和<<运算符,输出一条提示信息"making s grow:"。 - 接下来,使用一个循环,从0到99,逐个向字符串对象
s中添加字符'c'。在每次添加字符之后,通过比较之前记录的容量sz和当前字符串对象s的容量,来判断容量是否发生了变化。 - 如果容量发生了变化,将新的容量值赋给
sz,并使用cout对象和<<运算符输出一条提示信息"capacity changed:",以及新的容量值。
这里输出的容量不包括 \0,也就是实际容量要再加1.
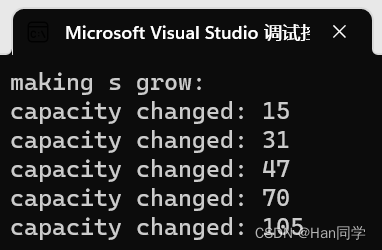
在监视中可以看到,,实际上将字符存入了_Buf数组中。
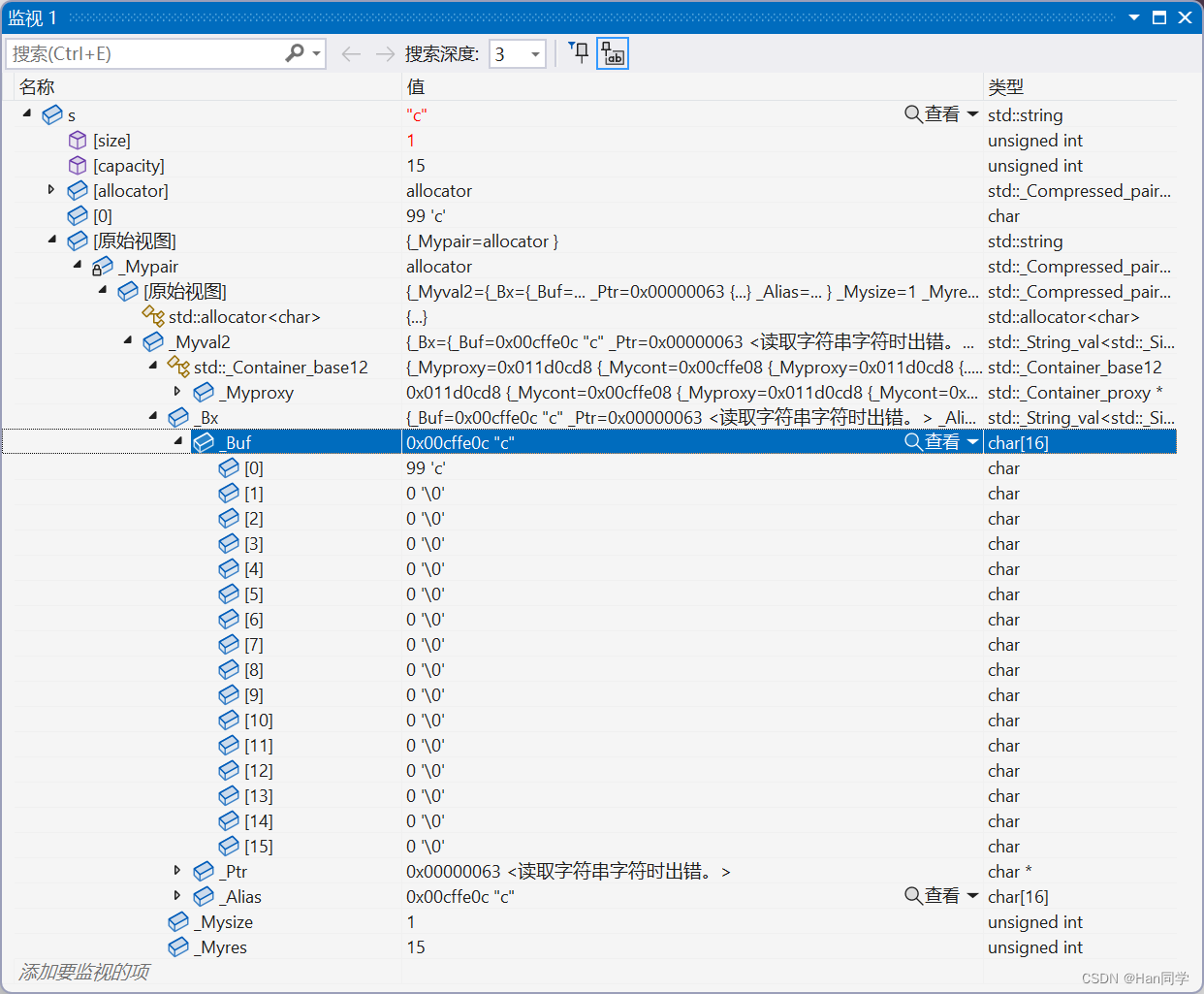
在C++的实现中,std::string类通常使用两个数组来存储字符串的字符。当字符串的长度小于等于15个字符时,字符串的字符被存储在一个名为_Buf的内部固定大小数组中,该数组长度为16。这样可以避免动态内存分配,提高性能。
当字符串的长度超过15个字符时,字符串的字符将被存储在一个名为_Ptr的动态分配的数组中,该数组的长度将根据需要进行动态调整。这样可以容纳更长的字符串,并且可以根据需要动态分配内存。
这种设计可以在字符串较短时节省内存,并在字符串较长时提供足够的存储空间。具体的实现可能会因编译器和标准库的不同而有所差异,但这种区分短字符串和长字符串的策略是常见的优化技术之一
vs下string的结构:string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定string中字符串的存储空间:
- 当字符串长度小于16时,使用内部固定的字符数组来存放
- 当字符串长度大于等于16时,从堆上开辟空间
union _Bxty
{ // storage for small buffer or pointer to larger onevalue_type _Buf[_BUF_SIZE];pointer _Ptr;char _Alias[_BUF_SIZE]; // to permit aliasing
} _Bx;- 这种设计也是有一定道理的,大多数情况下字符串的长度都小于16,那string对象创建好之后,内
- 部已经有了16个字符数组的固定空间,不需要通过堆创建,效率高。
- 其次:还有一个size_t字段保存字符串长度,一个size_t字段保存从堆上开辟空间总的容量
- 最后:还有一个指针做一些其他事情。
- 故总共占16+4+4+4=28个字节。
输出查看一下string类对象s的大小
string s;cout << sizeof(s) << endl;可以看到是28,那么它在堆上起始就是大小32。

观察扩容情况可以发现从大小32开始,每次1.5倍扩容。
在已知所需空间大小时,我们可以使用reserve提前开辟空间,减少扩容,提高效率。

使用reverse一次性开辟100个字符空间。
int main()
{string s;s.reserve(100);size_t sz = s.capacity();cout << "making s grow:\n";cout << "capacity changed: " << sz << '\n';for (int i = 0; i < 100; ++i){s.push_back('c');if (sz != s.capacity()){sz = s.capacity();cout << "capacity changed: " << sz << '\n';}}
}这时就不需要一次次扩容了。
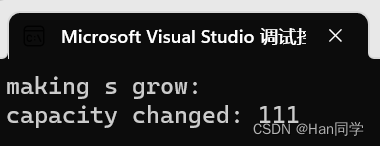
对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
6、resize

resize将字符串大小调整为n个字符的长度。
- 如果n小于当前字符串长度,则将当前值缩短到前n个字符,删除第n个字符以外的字符。
- 如果n大于当前字符串长度,则通过在末尾插入尽可能多的字符来扩展当前内容,以达到n的大小。
- 如果指定了填充字符c,则新元素被初始化为c的副本,否则,它们是值初始化的字符(空字符)。
int main()
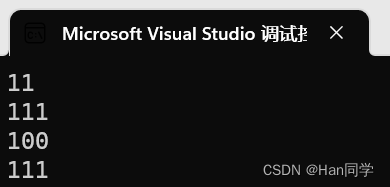
{// 扩容string s1("hello world");s1.reserve(100);cout << s1.size() << endl;cout << s1.capacity() << endl;// 扩容+初始化string s2("hello world");s2.resize(100);cout << s2.size() << endl;cout << s2.capacity() << endl;return 0;
}resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小。
四、迭代器
1、正向迭代器

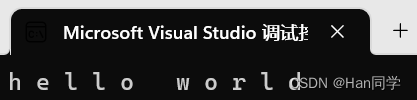
begin指向字符串第一个字符,end指向字符串最后一个字符的后一个位置,功能和指针类似。

int main()
{string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()) {cout << *it << " ";++it;}return 0;
} 
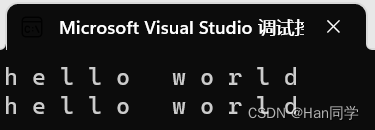
范围for底层就是调用迭代器实现的。
int main()
{string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()) {cout << *it << " ";++it;}cout << endl;for (auto ch : s1) {cout << ch << " ";}cout << endl;
} 
2、反向迭代器

rbegin指向字符串最后一个字符,rend指向字符串的第一个字符的前一个位置。
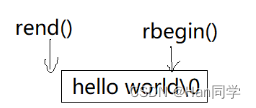
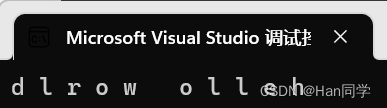
int main()
{string::reverse_iterator rit = s1.rbegin();while (rit != s1.rend()) {cout << *rit << " ";++rit;}cout << endl;return 0;
}
3、const迭代器 (正向反向)
const正向反向迭代器只能遍历和读数据。
int main()
{string s1("hello world");string::const_iterator it = s1.begin();while (it != s1.end()) {cout << *it << " ";++it;}cout << endl;string::const_reverse_iterator rit = s1.rbegin();while (rit != s1.rend()) {cout << *rit << " ";++rit;}cout << endl;cout << s1 << endl;return 0;
}
这时可以借助auto自动推导类型。
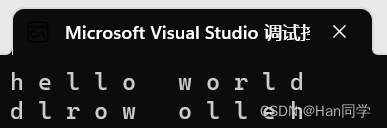
int main()
{//string::const_iterator it = s1.begin();auto it = s1.begin();while (it != s1.end()) {cout << *it << " ";++it;}cout << endl;//string::const_reverse_iterator rit = s1.rbegin();auto rit = s1.rbegin();while (rit != s1.rend()) {cout << *rit << " ";++rit;}cout << endl;return 0;
} 
五、OJ练习
反转字符
917. 仅仅反转字母 - 力扣(LeetCode)
采用快速排序的思路。
class Solution {
public:string reverseOnlyLetters(string s) {size_t begin = 0, end=s.size()-1;while(begin<end){while(begin<end&&!isalpha(s[begin]))++begin;while(begin<end&&!isalpha(s[end]))--end;swap(s[begin],s[end]);++begin;--end;}return s;}
};找出字符串中出现一次的字符
387. 字符串中的第一个唯一字符 - 力扣(LeetCode)
采用计数排序的思路。
class Solution {
public:int firstUniqChar(string s) {int count[26]={0};for(auto ch:s){count[ch-'a']++;}for(int i=0;i<s.size();i++){if(count[s[i]-'a']==1)return i;}return -1;}
};








![[LeetCode周赛复盘] 第 374 场周赛20231203](https://img-blog.csdnimg.cn/direct/3ba5ab09ae574b1f9fd2a0f9d0e9d84f.png)