最近,我在做多分类问题。在针对基模型的选择中,我使用了DenseNet作为基本模型。我在阅读论文时,遇到了一种改进方式:
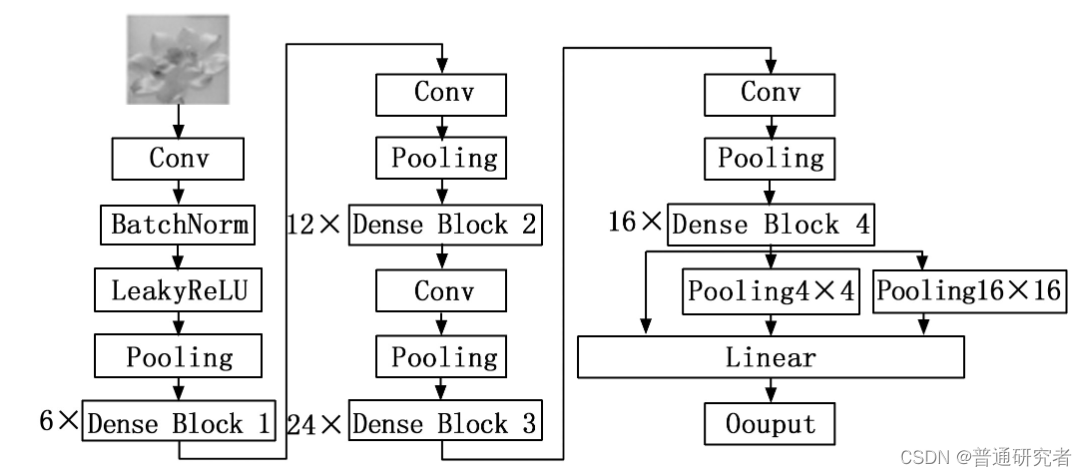
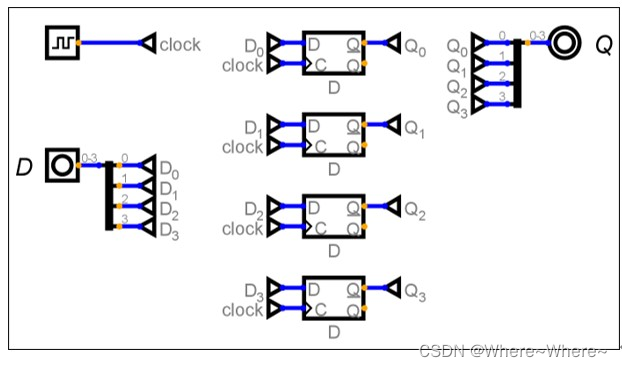
如上图所示,在全连接层之前引入SPP模块:

代码如下:
SPP模块代码:
class SpatialPyramidPooling(nn.Module):def __init__(self, pool_sizes: List[int], in_channels: int):super(SpatialPyramidPooling, self).__init__()self.pool_sizes = pool_sizesself.in_channels = in_channelsself.pool_layers = nn.ModuleList([nn.AdaptiveMaxPool2d(output_size=(size, size)) for size in pool_sizes])def forward(self, x: Tensor) -> Tensor:pools = [pool_layer(x) for pool_layer in self.pool_layers]# Resize the output of each pool to have the same number of channelspools_resized = [F.adaptive_max_pool2d(pool, (1, 1)) for pool in pools]spp_out = torch.cat(pools_resized, dim=1) # Concatenate the resized poolsreturn spp_out
加入SPP代码后的DenseNet网络完整如下:
import re
from typing import List, Tuple, Any
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from torch import Tensorclass _DenseLayer(nn.Module):def __init__(self, input_c: int, growth_rate: int, bn_size: int, drop_rate: float, memory_efficient: bool = False):super(_DenseLayer, self).__init__()self.add_module("norm1", nn.BatchNorm2d(input_c))self.add_module("relu1", nn.ReLU(inplace=True))self.add_module("conv1", nn.Conv2d(in_channels=input_c, out_channels=bn_size * growth_rate,kernel_size=1, stride=1, bias=False))self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate))self.add_module("relu2", nn.ReLU(inplace=True))self.add_module("conv2", nn.Conv2d(bn_size * growth_rate, growth_rate,kernel_size=3, stride=1, padding=1, bias=False))self.drop_rate = drop_rateself.memory_efficient = memory_efficientdef bn_function(self, inputs: List[Tensor]) -> Tensor:concat_features = torch.cat(inputs, 1)bottleneck_output = self.conv1(self.relu1(self.norm1(concat_features)))return bottleneck_output@staticmethoddef any_requires_grad(inputs: List[Tensor]) -> bool:for tensor in inputs:if tensor.requires_grad:return Truereturn False@torch.jit.unuseddef call_checkpoint_bottleneck(self, inputs: List[Tensor]) -> Tensor:def closure(*inp):return self.bn_function(inp)return cp.checkpoint(closure, *inputs)def forward(self, inputs: Tensor) -> Tensor:if isinstance(inputs, Tensor):prev_features = [inputs]else:prev_features = inputsif self.memory_efficient and self.any_requires_grad(prev_features):if torch.jit.is_scripting():raise Exception("memory efficient not supported in JIT")bottleneck_output = self.call_checkpoint_bottleneck(prev_features)else:bottleneck_output = self.bn_function(prev_features)new_features = self.conv2(self.relu2(self.norm2(bottleneck_output_with_cbam)))if self.drop_rate > 0:new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)return new_featuresclass _DenseBlock(nn.ModuleDict):_version = 2def __init__(self, num_layers: int, input_c: int, bn_size: int, growth_rate: int, drop_rate: float,memory_efficient: bool = False):super(_DenseBlock, self).__init__()for i in range(num_layers):layer = _DenseLayer(input_c + i * growth_rate,growth_rate=growth_rate,bn_size=bn_size,drop_rate=drop_rate,memory_efficient=memory_efficient)self.add_module("denselayer%d" % (i + 1), layer)def forward(self, init_features: Tensor) -> Tensor:features = [init_features]for _, layer in self.items():new_features = layer(features)features.append(new_features)return torch.cat(features, 1)class _Transition(nn.Sequential):def __init__(self, input_c: int, output_c: int):super(_Transition, self).__init__()self.add_module("norm", nn.BatchNorm2d(input_c))self.add_module("relu", nn.ReLU(inplace=True))self.add_module("conv", nn.Conv2d(input_c, output_c, kernel_size=1, stride=1, bias=False))self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))class SpatialPyramidPooling(nn.Module):def __init__(self, pool_sizes: List[int], in_channels: int):super(SpatialPyramidPooling, self).__init__()self.pool_sizes = pool_sizesself.in_channels = in_channelsself.pool_layers = nn.ModuleList([nn.AdaptiveMaxPool2d(output_size=(size, size)) for size in pool_sizes])def forward(self, x: Tensor) -> Tensor:pools = [pool_layer(x) for pool_layer in self.pool_layers]# Resize the output of each pool to have the same number of channelspools_resized = [F.adaptive_max_pool2d(pool, (1, 1)) for pool in pools]spp_out = torch.cat(pools_resized, dim=1) # Concatenate the resized poolsreturn spp_outclass DenseNet(nn.Module):def __init__(self, growth_rate: int = 32, block_config: Tuple[int, int, int, int] = (6, 12, 24, 16),num_init_features: int = 64, bn_size: int = 4, drop_rate: float = 0, num_classes: int = 1000,memory_efficient: bool = False):super(DenseNet, self).__init__()# First conv+bn+relu+poolself.features = nn.Sequential(OrderedDict([("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),("norm0", nn.BatchNorm2d(num_init_features)),("relu0", nn.ReLU(inplace=True)),("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))# Each dense blocknum_features = num_init_featuresfor i, num_layers in enumerate(block_config):block = _DenseBlock(num_layers=num_layers,input_c=num_features,bn_size=bn_size,growth_rate=growth_rate,drop_rate=drop_rate,memory_efficient=memory_efficient)self.features.add_module("denseblock%d" % (i + 1), block)num_features = num_features + num_layers * growth_rateif i != len(block_config) - 1:trans = _Transition(input_c=num_features,output_c=num_features // 2)self.features.add_module("transition%d" % (i + 1), trans)num_features = num_features // 2# Final batch normself.features.add_module("norm5", nn.BatchNorm2d(num_features))# Spatial Pyramid Pooling (SPP) layerspp_pool_sizes = [1, 4, 16] # You can adjust pool sizes as neededself.spp = SpatialPyramidPooling(spp_pool_sizes, in_channels=num_features)# FC layerself.classifier = nn.Linear(num_features + len(spp_pool_sizes) * num_features, num_classes)# Initialize weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.constant_(m.bias, 0)def forward(self, x: Tensor) -> Tensor:features = self.features(x)out = F.relu(features, inplace=True)# Apply Spatial Pyramid Poolingspp_out = self.spp(out)# Adjust the number of channels in out to match spp_outout = F.adaptive_avg_pool2d(out, (1, 1))# Concatenate the original feature map with the SPP output along the channel dimensionout = torch.cat([spp_out, out], dim=1)# Flatten the spatial dimensions of outout = torch.flatten(out, 1)# FC layerout = self.classifier(out)return outdef densenet121(**kwargs: Any) -> DenseNet:# Top-1 error: 25.35%# 'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth'return DenseNet(growth_rate=32,block_config=(6, 12, 24, 16),num_init_features=64,**kwargs)
def load_state_dict(model: nn.Module, weights_path: str) -> None:# '.'s are no longer allowed in module names, but previous _DenseLayer# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.# They are also in the checkpoints in model_urls. This pattern is used# to find such keys.pattern = re.compile(r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')state_dict = torch.load(weights_path)num_classes = model.classifier.out_featuresload_fc = num_classes == 1000for key in list(state_dict.keys()):if load_fc is False:if "classifier" in key:del state_dict[key]res = pattern.match(key)if res:new_key = res.group(1) + res.group(2)state_dict[new_key] = state_dict[key]del state_dict[key]model.load_state_dict(state_dict, strict=load_fc)print("successfully load pretrain-weights.")




![[论文精读]利用大语言模型对扩散模型进行自我修正](https://img-blog.csdnimg.cn/direct/c3e4df843fc34f8da407de61f6620427.png#pic_center)

![P1006 [NOIP2008 提高组] 传纸条](https://img-blog.csdnimg.cn/direct/1f97365003ec47a49c9e19b09f600cd4.png)