内容概述
- 磁盘结构
- 分区类型
- 管理分区
- 管理文件系统
- 挂载设备
- 管理swap空间(用来缓解内存空间不足情况)
- RAID 管理
- LVM管理
- LVM快照
1 磁盘结构
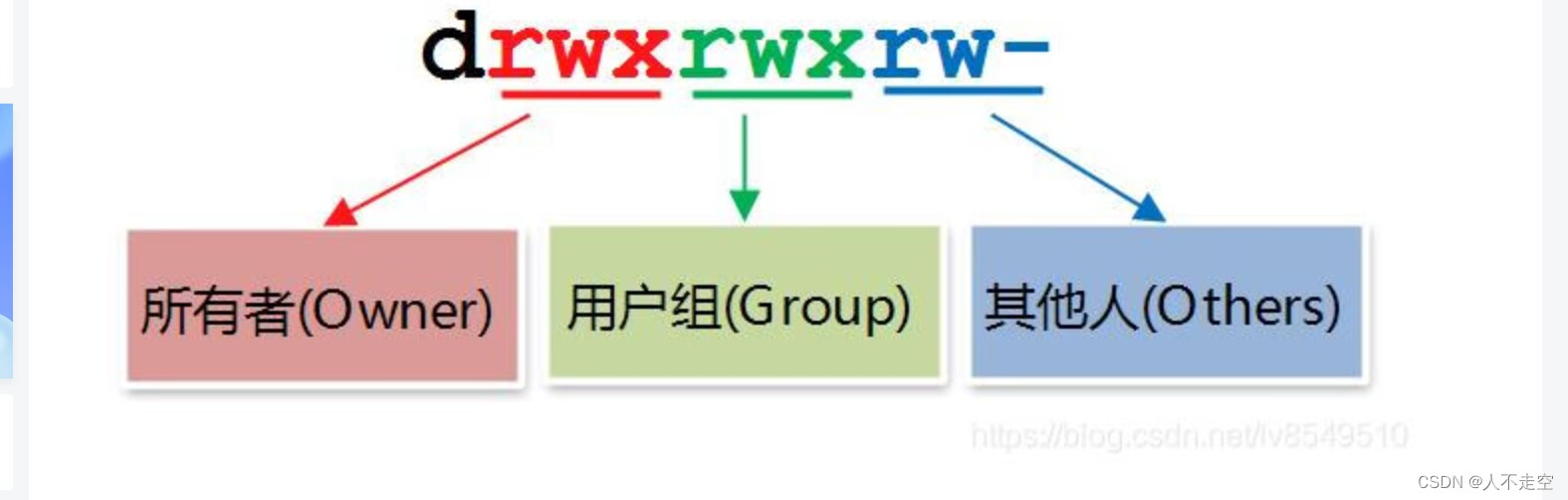
1.1 设备文件
块设备文件:数据的访问单位是块Block,一个块的IO
字符设备文件:数据的访问单位是字符Char,一个字符的IO
一切皆文件:open() ,read() ,write() ,close()
设备文件:关联至一个设备驱动程序,进而能够跟与之对应硬件设备进行通信。
设备号码:
- 主设备号:magor number,标识设备类型
- 次设备号:minor number,标识同一类型下的不同设备
设备类型:
- 块设备:block,存取单位”块“,磁盘
- 字符设备:char,存取单位”字符“,键盘
磁盘设备的设备文件命名:
/dev/DEV_FILE
/dev/sdx #SCSI,SATA,SAS,IDE,USB
/dev/nvme0n# #nvme协议硬盘,如:第一个硬盘:nvme0n1,第二个硬盘:nvme0n2
虚拟磁盘:
/dev/vd
/dev/xvd
不同磁盘标识:a-z,aa,ab,……
示例:
/dev/sda /dev/sdb /dev/sdc
同一设备上的不同分区:1 , 2 , …
示例:
/dev/sda /dev/sda1 /dev/sda2
发展趋势:从以前的买计算机,变成买计算;从以前的买服务器,变成买服务。
范例:创建设备文件
~ df -Th /boot
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda1 xfs 2.0G 245M 1.8G 13% /boot
~ ls -l /dev/sda1
brw-rw----. 1 root disk 8, 1 Jun 2 21:46 /dev/sda1
#查看/boot下的目录文件
~ ls /boot
config-4.18.0-305.3.1.el8.x86_64 initramfs-4.18.0-305.3.1.el8.x86_64.img vmlinuz-0-rescue-29d39d1c773e42fdbc046512dd7d1bd2
efi initramfs-4.18.0-305.3.1.el8.x86_64kdump.img vmlinuz-4.18.0-305.3.1.el8.x86_64
grub2 loader
initramfs-0-rescue-29d39d1c773e42fdbc046512dd7d1bd2.img System.map-4.18.0-305.3.1.el8.x86_64
#复制/dev/sda1创建设备文件
~ mknod /data/partition-sda1 b 8 1
~ ls -l /data/partition-sda1 /dev/sda1
brw-r--r--. 1 root root 8, 1 Jun 2 22:05 /data/partition-sda1
brw-rw----. 1 root disk 8, 1 Jun 2 21:46 /dev/sda1
#挂载
~ mkdir -p /mnt/partition-sda1;mount /data/partition-sda1 /mnt/partition-sda1
~ ls /mnt/partition-sda1
config-4.18.0-305.3.1.el8.x86_64 initramfs-4.18.0-305.3.1.el8.x86_64.img vmlinuz-0-rescue-29d39d1c773e42fdbc046512dd7d1bd2
efi initramfs-4.18.0-305.3.1.el8.x86_64kdump.img vmlinuz-4.18.0-305.3.1.el8.x86_64
grub2 loader
initramfs-0-rescue-29d39d1c773e42fdbc046512dd7d1bd2.img System.map-4.18.0-305.3.1.el8.x86_64#复制/dev/zero创建设备文件
~ ls -l /dev/zero
crw-rw-rw-. 1 root root 1, 5 Jun 2 21:46 /dev/zero
~ mknod /data/zero c 1 5
~ ls -l /data/zero /dev/zero
crw-r--r--. 1 root root 1, 5 Jun 2 22:07 /data/zero
crw-rw-rw-. 1 root root 1, 5 Jun 2 21:46 /dev/zero
再举例:

范例:操纵设备文件
➜ ~ ls -l /dev/zero /dev/null
crw-rw-rw- 1 root root 1, 3 May 15 12:17 /dev/null
crw-rw-rw- 1 root root 1, 5 May 15 12:17 /dev/zero
➜ ~ mknod /data/testdev c 1 5
➜ ~ ls -l /data/testdev
crw-r--r-- 1 root root 1, 5 Jun 2 22:09 /data/testdev
➜ ~ dd if=/data/testdev of=/data/test1.img bs=1 count=10
10+0 records in
10+0 records out
10 bytes (10 B) copied, 0.000190506 s, 52.5 kB/s
➜ ~ ls -l /data/test1.img
-rw-r--r-- 1 root root 10 Jun 2 22:10 /data/test1.img
➜ ~ hexdump -C /data/test1.img
00000000 00 00 00 00 00 00 00 00 00 00 |..........|
0000000a
➜ ~ rm -rf /data/testdev
➜ ~ ls -lh /data/test1.img
-rw-r--r-- 1 root root 10 Jun 2 22:11 /data/test1.img#拷贝设备文件的正确做法
#不能直接使用cp进行拷贝,需要添加参数使其保留原有属性
➜ ~ cp -av /dev/zero /data/zero
‘/dev/zero’ -> ‘/data/zero’
➜ ~ ls -l /data/zero
crw-rw-rw- 1 root root 1, 5 May 15 12:17 /data/zero
1.2 硬盘类型

硬盘接口类型:
- IDE:133MB/s,并行接口,早期家用电脑
- SCSI:640MB/s,并行接口,早期服务器
- SATA(家用电脑磁盘):6Gbps,SATA数据端口与电源端口是分开的,即需要两条线,一条数据线,一条电源线。
- SAS(服务器磁盘):6Gbps,SAS是一整条线,数据端口与电源端口是一体化的,SAS中是包含供电线的,而SATA中不包含供电线。SATA标准其实是SAS标准的一个子集,二者可以兼容,即SATA硬盘可以插入SAS主板上,反之不行。
- USB:480MB/s
- M.2:是一种新的主机接口方案,可以兼容多种通信协议,如sata、PCIe、USB、HSIC、UART、SMBus等。
注意:速度不是由单纯的接口类型决定的,支持Nvme协议硬盘速度是最快的。
服务器硬盘大小:
- LFF:3.5寸,一般见到的那种台式机硬盘的大小
- SFF:Small From Factor 小形状因数,2.5寸,注意不同于2.5寸的笔记本硬盘
L、S分别是大、小的意思,目前服务器或者盘柜采用的是 SFF 规格的硬盘主要是考虑内增大单位密度内磁盘容量,增强散热,减少功耗。
1.3 机械硬盘和固态硬盘
机械硬盘( HDD ):Hard Disk Drive,即是传统普通硬盘,主要由:盘头,磁头,盘片转轴及控制电机,磁头控制器,数据转换器,接口,缓存等几个部分组成。机械硬盘中所有的盘片都装在一个旋转轴上,每张盘片之间是平行的,在每个盘片的存储面上有一个磁头,磁头与盘片之间的距离比头发丝的直径还小,所有的磁头联在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径方向运动,加上盘片每分钟几千转的高速旋转,磁头就可以定位在盘片的指定位置上进行数据的读写操作。数据通过磁头由电磁流来改变极性方式被电磁流写到磁盘上,也可以通过相反方式读取。硬盘为精密设备,进入硬盘的空气必须过滤。
固态硬盘( SSD ):Solid State Drive,用固态电子存储芯片阵列而制成的硬盘,由控制单元和存储单元(FLASH芯片、DRAM芯片)组成。固态硬盘在接口的规范和定义、功能及使用方法上与普通硬盘的完全相同,在产品外形和尺寸上也与普通硬盘一致。
相较于HDD,SSD在防震抗摔、传输速率、功耗、重量、噪音上有明显优势,SSD传输速率性能是HDD的2倍。
相较于SSD,HDD在价格、容量占有绝对优势
硬盘有价,数据无价,目前SSD不能完全取代HHD
机械硬盘结构(HDD)

固态硬盘结构(SSD)

1.4 硬盘存储术语
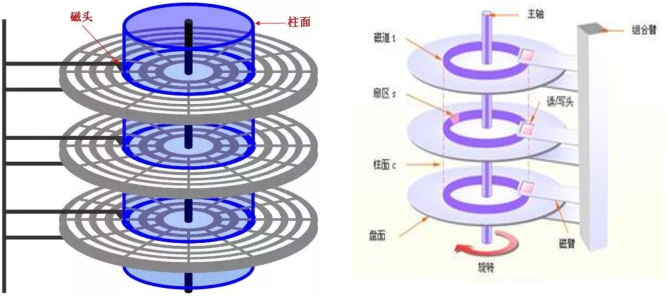
如图:一共有3个盘片,那么就是正反共6个盘面,一个盘面一个磁头,那么就是共6个磁头。
磁盘存储术语 CHS(Cylinder Head Sector)
- head:磁头;每个盘面上一个读写磁头,盘面号即磁头号。所有磁头在磁头臂作用下同时内外移动,即任意时刻,所有磁头所处的磁道号是相同的。(磁头数 = 盘面数)
- track:磁道;每个盘面被划分成许多同心圆,这些同心圆轨迹叫做磁道(属于逻辑上的概念);磁道从外向内从0开始顺序编号。(磁道数 = 柱面数)
- sector:扇区,512 bytes;将一个盘面划分为若干内角相同的扇形,这样盘面上的每个磁道就被分为若干段圆弧,每段圆弧叫做一个扇区。每个扇区中的数据作为一个单元同时读出或写入。硬盘的第一个扇区,叫做引导扇区。
- cylinder:柱面;所有盘面上的同一磁道构成一个圆柱,称作柱面。柱面数据空间= 512 ⨉ sector数/track ⨉ head数。51263255/1024/1024=7.84M,CentOS 5 之前版本Linux 以柱面的整数倍划分分区,CentOS 6之后可以支持扇区划分分区。(0柱面:将磁盘的所有盘面中的最外圈的0磁道抽象出来就是零柱面。同理就可以知道1柱面等。)
CentOS 5之前的版本 Linux 以柱面的整数倍划分分区,CentOS 6之后可以支持以扇区划分分区。
范例:
~ echo "scale=2;512*63*255/1024/1024" | bc
7.84#查看CHS
#CentOS6操作系统
~ fdisk -l /dev/sdaDisk /dev/sda: 536.9 GB, 536870912000 bytes
255 heads, 63 sectors/track, 65270 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00034f2cDevice Boot Start End Blocks Id System
/dev/sda1 * 1 256 2048000 83 Linux
Partition 1 does not end on cylinder boundary.
/dev/sda2 256 13004 102400000 83 Linux
/dev/sda3 13004 25752 102400000 83 Linux
/dev/sda4 25752 65271 317438976 5 Extended
/dev/sda5 25752 26262 4096000 82 Linux swap / Solaris#CentOS6以后的操作系统
~ fdisk -u=cylinders -l /dev/sda
Disk /dev/sda: 500 GiB, 536870912000 bytes, 1048576000 sectors
Geometry: 255 heads, 2 sectors/track, 65270 cylinders
Units: cylinders of 510 * 512 = 261120 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0xc72b9136Device Boot Start End Cylinders Size Id Type
/dev/sda1 * 5 8229 8225 2G 83 Linux
/dev/sda2 8229 419435 411207 100G 83 Linux
/dev/sda3 419435 830641 411207 100G 83 Linux
/dev/sda4 830641 2056032 1225391 298G 5 Extended
/dev/sda5 830645 847093 16449 4G 82 Linux swap / Solaris
范例:识别SSD和机械硬盘的类型
lsblk --help
# 1表示机械硬盘,0表示固态硬盘
~ lsblk -d -o name,rota
NAME ROTA
sda 1
sdb 1
sdc 1
sr0 1~ ls /sys/block
sda sdb sdc sr0
~ cat /sys/block/*/queue/rotational
1
1
1
1
~ cat /sys/block/sda/queue/rotational
1
~ cat /sys/block/sdb/queue/rotational
1
~ cat /sys/block/sdc/queue/rotational
1
~ cat /sys/block/sr0/queue/rotational
1
范例:扫描磁盘
for i in {0..32} ;do echo '- - -' > /sys/class/scsi_host/host$i/scan ; done
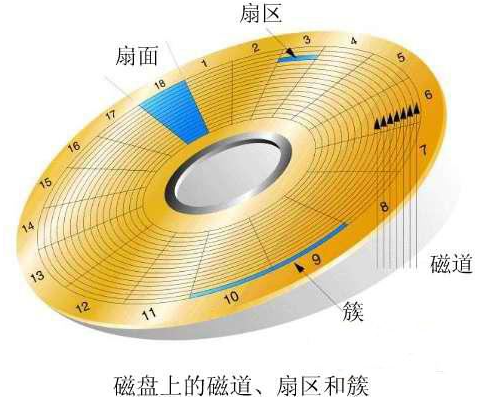
区位记录磁盘扇区结构ZBR(Zoned Bit Recording)

ZBR 区位记录(Zoned-bit recording)是一种物理优化硬盘存储空间的方法,或指对磁道进行分区域,在不同区域采用不同密度以提高磁盘容量的记录方法。特点是内部磁道的扇区数目较少,外部磁道的扇区数目较多。在使用ZBR的硬盘,在最外面的环带中的轨道上的数据将具有最高数据传输率。
数据在划分分区时,越是小的编号,数据读写越快。因为机械硬盘在从外向内的编号是从0开始向内增加,磁头在机械硬盘最外层转一圈读写的数据比内层转一圈读写的数据多和快。
同一时间内,磁头在磁盘的内圈访问的扇区数是远远比外圈访问的扇区数少的。(角速度不同)
硬盘优化性能提高的策略:
在机械硬盘,尽量将经常访问的数据存放在磁盘的外圈。
磁道的编号是最外圈为0,不断向内,编号不断的增加。
CHS 和 LBA
**CHS( Cylinder / Head / Sector ) **
- CHS 采用 24bit 位寻址
- 其中前 10 位表示 cylinder(柱面),中间 8 位表示 head(磁头),后面 6 位表示sector(扇区)。
- 最大寻址空间 8GB
~ echo 2^24*512/1024/1024 | bc
8192
LBA(Logical Block Addressing)
- LBA 称为 逻辑块寻址
- LBA 是一个整数,通过转换成 CHS 格式完成磁盘具体寻址。
- ATA-1 规范中定义了 28 位寻址模式,以每个扇区 512 位组来计算,ATA-1 所定义的 28位LBA 上限到达 128 GiB。2002 年 ATA-6规范采用了 48位LBA,同样以每扇区 512 组计算容量上限可达 128 Petabytes。
由于 CHS 寻址方式的寻址空间在大概 8 GB 以内,所以在磁盘容量小于大概 8GB时,可以使用 CHS 寻址方式或者是 LBA 寻址方式;在磁盘容量大于大概 8GB时,则只能使用 LBA 寻址方式。
2 管理磁盘
使用磁盘空间过程
1.设备分区
2.创建文件系统
3.挂载新的文件系统
2.1 磁盘分区
2.1.1 为什么要分区
- 优化 I/O 性能
- 实现磁盘空间配额限制
- 提高修复速度
- 隔离系统和程序
- 安装多个OS
- 采用不同的文件系统
2.1.2 分区方式
两种分区方式:MBR,GPT
2.1.2.1 MRB 分区
- MBR:Master Boot Record,1982年,使用 32 位表示扇区数,分区不超过 2T
- echo 2^32*512/1024/1024 | bc
2097152 - echo 2^32*512/1024/1024/1024 | bc
2048
划分分区的单位:
- CentOS 5 之前按整柱面分(柱面:所有盘面上的同一磁道构成一个圆柱,称作柱面。柱面= 512 ⨉ sector数/track ⨉ head数)
- CentOS 6 版本后可以按 sector(扇区) 分
0 磁道 0扇区:512bytes
- 446 bytes:boot loader(系统启动相关)
- 64 bytes:分区表,其中每 16 bytes 标识一个分区(分区最多4个的原因)
- 2 bytes:55AA(标记位),表示该硬盘上面是有分区信息的
MBR 分区中一块硬盘最多有 4个主分区,也可以3主分区+1扩展(N个逻辑分区)
主分区即可以存放数据,也可以制作装系统。扩展分区不能直接存放数据,需要划分逻辑分区存放数据。
MBR 分区:主和扩展分区对应的 1 – 4,/dev/sda3,逻辑分区从 5开始,/dev/sda5
MBR 分区结构:
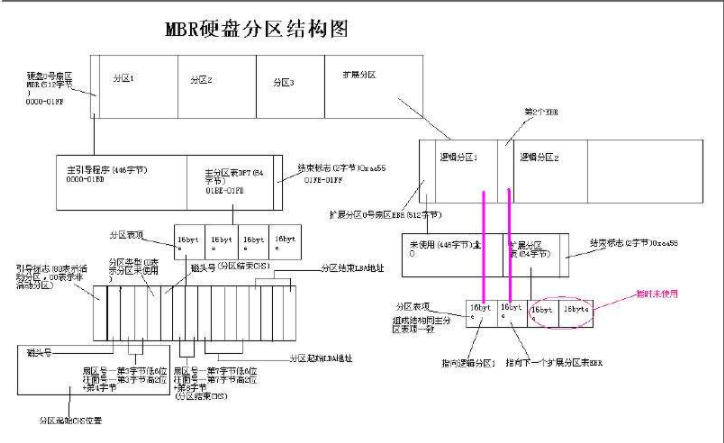
其中:分区起始CHS位置:第二个字节表示:磁头号,第三个字节低6位:扇区号,第三个字节高2位以及第四个字节:柱面号。一共3个字节,(3字节=24位)2^24=8G。只能表示8个G以内的空间,所以一个分区只能是8个G。只能描述8个G以内的数据。
硬盘主引导记录 MBR 由 4个部分组成。

- 主引导程序(偏移地址 0000H-0088H),它负责从活动分区中装载,并运行系统引导程序。
- 出错信息数据区,偏移地址 0089H-00E1H 为出错信息,00E2H-01BDH 全为0字节。
- 分区表(DPT,Disk Partition Table)含有 4个分区项,偏移地址 01BEH-01FDH,每个分区表项长 16 个字节,共 64个字节为分区项1、分区项2、分区项3、分区项4
- 结束标志字,偏移地址 01FE-01FF的2个字节值为结束标志 55AA
MBR中的 DPT 结构:
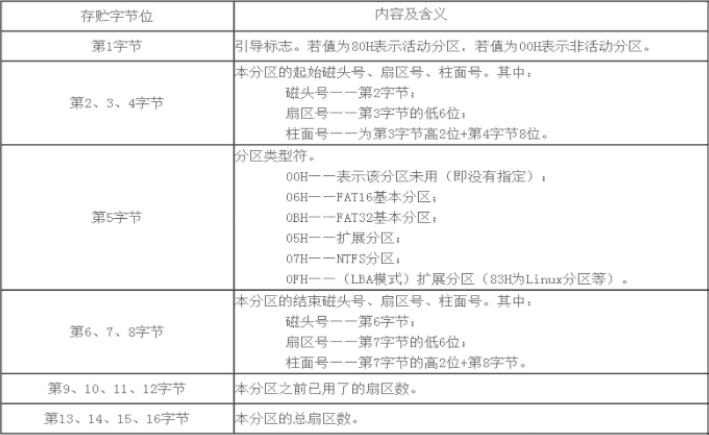
范例:取出分区表
~ dd if=/dev/sda of=/data/mbr bs=1 count=64 skip=446
~ file /data/mbr
/data/mbr: data
#一定需要异地备份,不然就和没有备份一样
~ hexdump -C /data/mbr
00000000 80 04 01 04 83 fe c2 ff 00 08 00 00 00 00 40 00 |..............@.|
00000010 00 fe c2 ff 83 fe c2 ff 00 08 40 00 00 00 80 0c |..........@.....|
00000020 00 fe c2 ff 83 fe c2 ff 00 08 c0 0c 00 00 80 0c |................|
00000030 00 fe c2 ff 05 fe c2 ff 00 08 40 19 00 f8 3f 25 |..........@...?%|
00000040###范例:备份MBR的分区表,并破坏后恢复
#备份MBR分区表
dd if=/dev/sda of=/data/dpt.img bs=1 count=64 skip=446
scp /data/dpt.img root@10.0.0.40:/root/#破坏MBR分区表
dd if=/dev/zero of=/dev/sda bs=1 count=64 seek=446#无法启动
reboot#用光盘启动,进入 rescue mode选项,选择第3项skip to shell#配置网络
ifconfig ens33 10.0.0.10/24
ip addr add 10.0.0.10/24 dev ens33scp root@10.0.0.40:/root/dpt.img .#恢复MBR分区表
dd if=dpt.img of=/dev/sda bs=1 count=64 seek=446
reboot
范例:破坏分区表并恢复之
#破坏实验
~ dd if=/dev/zero of=/dev/sda bs=1 count=64 seek=446
~ hexdump -s 446 -n 64 -v -C /dev/sda
000001be 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000001ce 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000001de 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000001ee 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
000001fe
#或者
~ hexdump -C -n 512 -v /dev/sda
~ reboot## 重启操作系统,挂载操作系统光盘,进入到救援模式
- 解决方法:


“Troubleshooting” --> “Rescue a CentOS Linux system” --> 1) Continue

配置IP地址,进行通信
ifconfig ens33 10.0.0.160 netmask 255.255.255.0 broadcast 10.0.0.255
#或者使用
ip addr add 10.0.0.10/24 dev ens33
测试集群内网络通信

scp root/10.0.0.40:/root/mbr .
hexdump -C -n 512 /dev/sda
#将分区表进行恢复
dd if=./mbf of=/dev/sda bs=1 count=64 seek=446
#检查数据是否已经恢复(建议恢复前备份设备文件,防止出问题)
hexdump -C -n 512 /dev/sda
#立即写入磁盘
sync
#重启生效
reboot
问题:利用分区策略相同的另一台主机的分区来还原和恢复当前主机破坏的分区表?是否可行。
可以利用分区策略相同的另一台主机的分区表来还原和恢复当前主机破坏的分区表
2.1.2.2 GPT 分区
GPT分区模式使用GUID分区表,是源自EFI标准的一种较新的磁盘分区表结构的标准。与普遍使用的主引导记录(MBR)分区方案相比,GPT提供了更加灵活的磁盘分区机制。
GPT:GUID(Globals Unique Identification)partition table 支持128个分区,使用64位,支持8Z(512Byte/block )64Z ( 4096Byte/block扇区)
使用128位UUID(Universally Unique Identifier) 表示磁盘和分区 GPT分区表自动备份在头和尾两份,并有CRC校验位
UEFI (Unified Extensible Firmware Interface 统一可扩展固件接口)硬件支持GPT,使得操作系统可以启动。
GPT 取消了逻辑分区。
GPT 分区结构

GPT 分区结构分为 4 个区域:
- GPT 头
- 分区表
- GPT 分区
- 备份区域
GUID分区表(简称GPT。使用GUID分区表的磁盘称为GPT磁盘)是源自EFI标准的一种较新的磁盘分区表结构的标准。与普遍使用的主引导记录(MBR)分区方案相比,GPT提供了更加灵活的磁盘分区机制。它具有如下优点:
1、支持2TB以上的大硬盘。
2、每个磁盘的分区个数几乎没有限制。为什么说“几乎”呢?是因为Windows系统最多只允许划分128个分区。不过也完全够用了。
3、分区大小几乎没有限制。又是一个“几乎”。因为它用64位的整数表示扇区号。夸张一点说,一个64位整数能代表的分区大小已经是个“天文数字”了,若干年内你都无法见到这样大小的硬盘,更不用说分区了。
4、分区表自带备份。在磁盘的首尾部分分别保存了一份相同的分区表。其中一份被破坏后,可以通过另一份恢复。
5、每个分区可以有一个名称(不同于卷标)。
既然GUID分区方案具有如此多的优点,在分区时是不是可以全部采用这种方案呢?不是的。并不是所有的Windows系统都支持这种分区方案。
2.1.3 BIOS 和 UEFI
BIOS 是固化在电脑主板上的程序,主要用于开机系统自检和引导操作系统。目前新式的电脑基本上都是 UEFI启动。
BIOS(Basic Input Output System 基本输入输出系统)主要完成系统硬件自检和引导操作系统,操作系统开始启动之后,BIOS的任务就完成了。系统硬件自检:如果系统硬件有故障,主板上的扬声器就会发出长短不同的“滴滴”音,可以简单的判断硬件故障,比如“1长1短”通常表示内存故障,“1长3短”通常表示显卡故障。
BIOS在1975年就诞生了,使用汇编语言编写,当初只有16位,因此只能访问1M的内存,其中前640K称为基本内存,后384K内存留给开机和各类BIOS本身使用。BIOS只能识别到主引导记录(MBR)初始化的硬盘,最大支持2T的硬盘,4个主分区(逻辑分区中的扩展分区除外),而目前普遍实现了64位系统,传统的BIOS已经无法满足需求了,这时英特尔主导的EFI就诞生了。
EFI(Extensible Firmware Interface)可扩展固件接口,是 Intel 为 PC 固件的体系结构、接口和服务提出的建议标准。其主要目的是为了提供一组在 OS 加载之前(启动前)在所有平台上一致的、正确指定的启动服务,被看做是BIOS 的继任者。
UEFI是由EFI1.10为基础发展起来的,它的所有者已不再是Intel,而是一个称作Unified EFI Form的国际组织。
UEFI(Unified Extensible Firmware Interface)统一的可扩展固件接口, 是一种详细描述类型接口的标准。UEFI 相当于一个轻量化的操作系统,提供了硬件和操作系统之间的一个接口,提供了图形化的操作界面。最关键的是引入了GPT分区表,支持2T以上的硬盘,硬盘分区不受限制。
BIOS 和 UEFI 的区别
BIOS 采用了16位汇编语言编写,只能运行在实模式(内存寻址方式由16位段寄存器的内容乘以16(10H)当做段基地址,加上16位偏移地址形成20位的物理地址)下,可访问的内存空间为1MB,只支持字符操作界面
UEEI 采用32位或者64位的C语言编写,突破了实模式的限制,可以达到最大的寻址空间,支持图形操作界面,使用文件方式保存信息,支持GRE分区启动,适合和较新的系统和硬件的配合使用
BIOS+MBR 和 UEFI+GPT
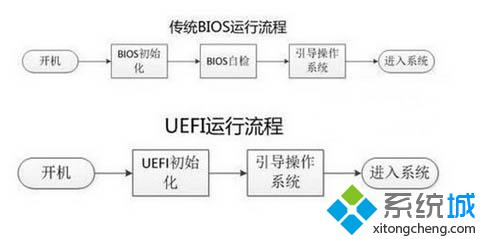
MSDN(Microsoft Developer Network)指出,Windows只能安装于BIOS+MBR或是UEFI+ GRI的组合上,而BIOS+ GPI和UE +MBR是不允许的。但是BIOS+ GPT + GRUB启动Linux是可以的
2.1.4 管理分区
列出块设备
lsblk
创建分区命令
fdisk 管理MBR分区,推荐使用
gdisk 管理GPT分区,推荐使用
parted 高级分区操作,可以是交互或者是非交互式操作。慎用
范例:查看分区命令帮助
~ man fdisk
~ man gdisk
~ man parted
重新设置内存中的内核分区表版本,适用于除了 CentOS6以外的其他版本,5,7,8
#CentOS5,7,8使用
partprobe
2.1.4.1 parted 命令
parted 的操作都是实时生效的,小心使用
格式:
parted [选项] ... [设备 [命令 [参数]...]...]
范例:
parted /dev/sdb mklabel gpt|msdos(MBR)
parted /dev/sdb print
parted /dev/sdb mkpart primary 1 200(默认为 M)
parted /dev/sdb rm 1
parted -l #列出所有硬盘分区的信息,必须掌握
范例:
~ parted /dev/sdb print
Error: /dev/sdb: unrecognised disk label
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 215GB
Sector size (logical/physical): 512B/512B
Partition Table: unknown
Disk Flags:~ parted /dev/sdb mklabel gpt~ parted /dev/sdb print
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 215GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:Number Start End Size File system Name Flags
#创建分区
~ parted /dev/sdb mkpart primary 1 1001
~ parted /dev/sdb mkpart primary 1002 1102
~ parted /dev/sdb print
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 215GB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:Number Start End Size File system Name Flags1 1049kB 1001MB 1000MB primary2 1002MB 1102MB 99.6MB primary
#删除分区
~ parted /dev/sdb rm 2
#将GPT分区方式改为MBR分区方式
~ parted /dev/sdb mklabel msdos
Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue?
Yes/No? Yes~ parted /dev/sdb print
Model: VMware, VMware Virtual S (scsi)
Disk /dev/sdb: 215GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:Number Start End Size Type File system Flags#交互式
parted
2.1.4.2 分区工具 fdisk 和 gdisk
gdisk [device …] 类 fdisk 的 GPT 分区工具(需要安装 yum install -y gdisk)
fdisk -l [-u] [device…] 查看分区
fdisk [device …] 管理 MBR 分区
#CentOS8之后的操作系统,fdisk 已经可以管理MBR也可以管理GPT
#若网络源速度较慢,可以直接使用本地光盘源即可
yum install -y --disablerepo=* --enable=BaseOS gdisk
子命令:
p:分区列表
t:更改分区类型
n:创建新分区
d:删除分区
v:校验分区
u:转换单位
w:保存并退出
q:不保存并退出
查看内核是否已经识别新的分区
cat /proc/partations
CentOS 6 通知内核重新读取硬盘分区表
新增分区用
partx -a /dev/DEVICE
kpartx -a /dev/DEVICE -f:force#示例:
partx -a /dev/sda
删除分区用
partx -d --nr M-N /dev/DEVICE#示例:
partx -d --nr 6-8 /dev/sda
范例:非交互式创建分区
echo -e "n\np\n\n\n+2G\nw\n" | fdisk /dev/sdc
范例:CentOS8使用 fdisk 工具
~ fdisk /dev/sdbWelcome to fdisk (util-linux 2.32.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Command (m for help): mHelp:DOS (MBR)a toggle a bootable flag(可启动标志的开关)b edit nested BSD disklabel(编辑嵌套的BSD磁盘标签)c toggle the dos compatibility flag(切换DOS兼容标志)Genericd delete a partition(删除一个分区)F list free unpartitioned space(列出空闲的未分区空间)l list known partition types(列出已知的分区类型)n add a new partition(添加新的分区)p print the partition table(打印分区表)t change a partition type(修改分区类型)v verify the partition table(验证分区表)i print information about a partition(打印一个分区的信息)Miscm print this menu(打印菜单)u change display/entry units(更改显示/输入单元)x extra functionality (experts only)(额外功能(仅限专家))ScriptI load disk layout from sfdisk script file(从sfdisk脚本文件加载磁盘布局)O dump disk layout to sfdisk script file(转储磁盘布局到sfdisk脚本文件)Save & Exitw write table to disk and exit(写入表到磁盘并退出)q quit without saving changes(退出不保存更改)Create a new label(创建一个新标签)g create a new empty GPT partition table(创建一个新的空的GPT分区表)G create a new empty SGI (IRIX) partition table(创建一个新的空的SGI (IRIX)分区表)o create a new empty DOS partition table(创建一个新的空DOS分区表)s create a new empty Sun partition table(创建一个新的空的Sun分区表)
范例:CentOS6系统同步分区表
#增加了6,7个分区
~ fdisk /dev/sda
Command (m for help): w
The partition tab1e has been altered!Calling ioct1o to re-read partition table .
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.The kernel sti11 uses the old table. The new table wi11 be ysed at
the next reboot or after you run partprobe(8) or kpartx(8)
Syncing disks.#分区表不同步
~ lsblk#CentOS6增加分区,同步分区表
#CentOS6以外的系统使用partprobe命令即可
~ partx -a /dev/sda#删除了6,7分区表
~ fdisk /dev/sda
~ lsblk#CentOS6删除分区,同步分区表
~ partx -d --nr 6-7 /dev/sda
~ lsblk

范例:批量创建分区
~ echo -e "n\np\n\n\n+2G\nw\n" | fdisk /dev/sdc
~ fdisk /dev/sdb <<EOF
n
p+1G
w
EOF
~ lsblk /dev/sdb
范例:CentOS 5,7,8 使用partprobe同步分区表
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)#解决方法
partprobe [/dev/DEVICE]
2.2 文件系统
2.2.1 文件系统概念
文件系统是操作系统用于明确存储设备或者分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件结构称为文件管理系统,简称文件系统。
从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。具体的说,它负责为用户建立文件,存入,读出,修改,转储文件,控制文件的存取,安全控制,日志,压缩,加密等等。
文件系统一般是有必要,当然文件系统自身会有资源消耗。
支持的文件系统:
#/lib/modules/`uname -r`/kernel/fs
~ ls /lib/modules/`uname -r`/kernel/fs
binfmt_misc.ko.xz ceph cramfs ext4 fscache gfs2 jbd2 mbcache.ko.xz nfs_common nls pstore udf
cachefiles cifs dlm fat fuse isofs lockd nfs nfsd overlayfs squashfs xfs
各种文件系统:https://en.wikipedia.org/wiki/Comparsion_of_file_systems
帮助:man 5 fs
2.2.2 文件系统类型
Linux 常用文件系统:
- ext2:Extend file system 适用于那些分区容量不是太大,更新也不频繁的情况,例如 /boot 分区
- ext3:是 ext2 的改进版本,其支持日志功能,能够帮助系统从非正常关机导致的异常中恢复。
- ext4:是 ext 文件系统的最新版,提供了很多新的特性,包括纳秒级时间戳、创建和使用巨型文件(16TB)、最大 1EB 的文件系统,以及速度的提升
- xfs:SGI,支持最大 8EB 的文件系统,XFS极具伸缩性,非常健壮。所幸的是SGI将其移植到了Linux系统中。在linux环境下。目前版本可用的最新XFS文件系统的为1.2版本,可以很好地工作在2.4核心下。
- swap:交换分区,模拟内存
- iso9660:光盘,是一个标准CD-ROM文件系统,它允许您在PC,Mac和其它主要计算机平台上读CD-ROM文件。
- btrfs (Oracle):由Oracle于2007年宣布并进行中的COW(copy-on-write式)文件系统。目标是取代Linuxext3文件系统,改善ext3的限制,特别是单一文件大小的限制,总文件系统大小限制以及加入文件校验和特性。加入ext3/4未支持的一些功能,例如可写的磁盘快照(snapshots),以及支持递归的快照(snapshots of snapshots),内建磁盘阵列(RAID)支持,支持子卷(Subvolumes)的概念,允许在线调整文件系统大小。
- ReiserFS:是一种新型的文件系统,它通过一种与众不同的方式–完全平衡树结构来容纳数据,包括文件数据,文件名以及日志支持。ReiserFS还以支持海量磁盘和磁盘阵列,并能在上面继续保持很快的搜索速度和很高的效率。
Windows 常用文件系统:
- FAT32:任何USB存储设备都会预装的文件系统,属Windows平台的传统文件格式,兼容性很好。
- NTFS:Windows私有的文件系统,能够支持大容量文件和超大分区,且集合了很多高级的技术,其中包括长文件名、压缩分区、数据保护和恢复等等的功能。
- exFAT:能够增强台式机或笔记本和移动设备之间的互操作能力、同目录下最多65536个文件,且支持访问控制,还有的就是剩余空间分配表改善空间分配
Unix 常用文件系统:
- FFS (Fast)
- UFS (Unix)
- JF32
网络文件系统:
- NFS:是由SUN公司研制的UNIX表示层协议(presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
- CIFS:它使程序可以访问远程Internet计算机上的文件并要求此计算机提供服务。CIFS 使用客户/服务器模式。客户程序请求远在服务器上的服务器程序为它提供服务。服务器获得请求并返回响应。
集群文件系统:
- GF32
- OCF32 (Oracle)
分布式文件系统:
- fastdfs
- ceph
- moosefs
- mogilefs
- glusterfs
- Lustre
RAW 裸文件系统:
未经处理或者未经格式化产生的文件系统,只能通过二进制的方式来存储数据,可以极大程度的提高数据的读写速度,提高性能。需要开发软件来读取0101的二进制的数据。会影响后期的系统管理(没有文件系统,例如:Oracle数据库)
常用的文件系统特性:
FAT32
- 最多只能支持 16 TB的文件系统和 4 GB的文件
NTFS
- 最多只能支持 16 EB的文件系统和 16 EB的文件
EXT3
- 最多只能支持 32 TB的文件系统和 2TB的文件,实际只能容纳 2TB的文件系统和 16GB的文件
- EXT 3目前只支持 32000 个子目录
- EXT 3文件系统使用 32 位空间记录块数量和 inode 数量
- 当数据写入到 EXT 3文件系统中时,EXT 3的数据块分配器每次只能分配一个 4KB 的块
EXT4
- EXT 4 时 Linux系统下的日志文件系统,是 EXT 3文件系统的后继版本
- EXT 4的文件系统容量达到 1EB,而支持单个文件则达到 16TB
- 理论上支持无限数量的子目录
- EXT 4文件系统使用 64 位空间记录块数量和 inode 数量
- EXT 4的多块分配器支持一次调用多个数据块
- 修复速度更快
XFS
- 根据所记录的日志在很短的时间内迅速恢复磁盘文件内容
- 用优化算法,日志记录对整体文件操作影响非常小
- 是一个全 64-bit的文件系统,最大可以支持 8EB 的文件系统,而支持单个文件则达到 8EB
- 能以接近裸设备 I/O 的性能存储数据
查前支持的文件系统:
#cat /proc/filesystems
~ cat /proc/filesystems
nodev sysfs
nodev tmpfs
nodev bdev
nodev proc
nodev cgroup
nodev cgroup2
nodev cpuset
nodev devtmpfs
nodev configfs
nodev debugfs
nodev tracefs
nodev securityfs
nodev sockfs
nodev bpf
nodev pipefs
nodev ramfs
nodev hugetlbfs
nodev devpts
nodev autofs
nodev pstore
nodev mqueuefuseblk
nodev fuse
nodev fusectlxfs
nodev rpc_pipefs
2.2.3 文件系统的组成部分
文件系统是操作系统用于明确存储设备(常见的是磁盘,也有基于NAND Flash的固态硬盘)或分区上的文件的方法和数据结构;即在存储设备上组织文件的方法。操作系统中负责管理和存储文件信息的软件机构称为文件管理系统,简称文件系统。文件系统由三部分组成:文件系统的接口,对对象操纵和管理的软件集合,对象及属性。从系统角度来看,文件系统是对文件存储设备的空间进行组织和分配,负责文件存储并对存入的文件进行保护和检索的系统。具体地说,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。
- 内核中的模块:ext4、xfs、vfat。
- Linux 的虚拟文件系统:VFS
- 用户空间的管理工具:mkfs.ext4、mkfs.xfs、mkfs.vfat
用户空间的数据程序命令通过系统调用,和虚拟文件系统(Virtual file system)打交道。再有虚拟文件系统进行处理再交由文件系统进行处理。

范例:查看操作系统的驱动模块加载情况
#查看操作系统的驱动模块加载情况
lsmod
范例:查看文件系统
#查看设备文件的挂载情况和UUID信息
~ lsblk -f
#查看设备文件的UUID信息
~ blkid
#查看分区的利用率和挂载情况
df -Th
2.2.4文件系统的选择
2.2.4.1 创建文件系统
- mkfs 命令:
- (1)mkfs.FS_TYPE /dev/DEVICE
- ext4
- xfs
- btrfs
- vfat
- (2)mkfs -t FS_TYPE /dev/DEVICE
- -L ‘LABEL’ 设定卷标
- (1)mkfs.FS_TYPE /dev/DEVICE
- mke2fs:ext 系列文件系统专用管理工具
常用选项:
~ mkfs -t
mkfs.ext2: option requires an argument -- 't'
Usage: mkfs.ext2 [-c|-l filename] [-b block-size] [-C cluster-size][-i bytes-per-inode] [-I inode-size] [-J journal-options][-G flex-group-size] [-N number-of-inodes] [-d root-directory][-m reserved-blocks-percentage] [-o creator-os][-g blocks-per-group] [-L volume-label] [-M last-mounted-directory][-O feature[,...]] [-r fs-revision] [-E extended-option[,...]][-t fs-type] [-T usage-type ] [-U UUID] [-e errors_behavior][-z undo_file][-jnqvDFSV] device [blocks-count]
-t{ext2 [ext 3lext4 |xfs} 指定文件系统类型
-b [1024 |2048|4096} 指定块block 大小
-L“LABEL’ 设置卷标
-j 相当于-t ext3,mkfs . ext3 = mkfs -t ext3 = mke2fs -j = mke2fs -t ext3
-i # 为数据空间中每多少个字节创建一个inode,不应该小于block大小
-N # 指定分区中创建多少个inode
-I 一个inode记录占用的磁:盘空间大小,128—4096
-m # 默认5%,为管理人员预留空间占总空问的百分比
-FEATURE[,…] 启用指定特性
-AFEATURE 关闭指定特性
2.2.4.2 查看和管理分区信息
blkid:可以查看块设备的属性信息
格式:
blkid [OPTION]... [DEVICE]
常用选项:
- -U UUID:根据指定的UUID来查找对应的设备
- -L LABEL:根据指定的LABEL来查找对应的设备
e2label:管理ext系列文件系统的LABEL
e2label DEVICE [LABEL]
findfs:查找分区
findfs [options] LABEL=<label>
findfs [options] UUID=<uuid>
范例:findfs 的使用
~ findfs UUID="0ea9011c-474c-40c1-90d1-cb012c3f0769"
/dev/sda5
~ findfs `sed -nr '/data/s@^([^ ]+).*@\1@p' /etc/fstab`
/dev/sda3
tune2fs:重新设定 ext 系列文件系统可以调整参数的值
- -l:查看指定文件系统超级块信息,super block
- -L ‘LABEL’:修改卷标
- -m #: 修改预留给管理员的空间百分比
- -j:将ext2 升级为 ext3
- -O:文件系统属性启用或者禁用,-O ^has–journal
- -o:调整文件系统的默认挂载选项,-o ^acl
- -U UUID:修改 UUID 号
dumpe2fs:显示 ext 文件系统的信息,将磁盘块分组管理
- -h:查看超级块信息,不显示分组信息
范例:查看ext文件系统的元数据和块组信息
#只能用于ext文件系统
~ dumpe2fs /dev/sdb1
dumpe2fs 1.45.6 (20-Mar-2020)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: 40791215-aa2b-439a-9d44-e88a02f24c2f
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file dir_nlink extra_isize metadata_csum
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 655360(节点的数量)
Block count: 2621440(块的数量)
Reserved block count: 131072
Free blocks: 2554687
Free inodes: 655349
First block: 0
Block size: 4096(块的大小)
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1024(保留块数量,预留块数量的5%)
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Flex block group size: 16
Filesystem created: Fri Jun 3 14:21:23 2022
Last mount time: n/a
Last write time: Fri Jun 3 14:21:23 2022
Mount count: 0
Maximum mount count: -1
Last checked: Fri Jun 3 14:21:23 2022
Check interval: 0 (<none>)
Lifetime writes: 4137 kB
Reserved blocks uid: 0 (user root)(保留块数量是root用户使用)
Reserved blocks gid: 0 (group root)(保留块数量是root用户组使用)
First inode: 11
Inode size: 256
Required extra isize: 32
Desired extra isize: 32
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: ceb825a5-ddd2-4618-a895-5c16b349c4bd
Journal backup: inode blocks
Checksum type: crc32c
Checksum: 0xb9937185
Journal features: (none)
Journal size: 64M
Journal length: 16384
Journal sequence: 0x00000001
Journal start: 0
xfs_info:显示未挂载或者已经挂载的 xfs 文件系统信息
xfs_info mountpoint | devname
范例:
#只能用于xfs文件系统
~ xfs_info /dev/sda1
meta-data=/dev/sda1 isize=512 agcount=4, agsize=131072 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=1, sparse=1, rmapbt=0= reflink=1
data = bsize=4096 blocks=524288, imaxpct=25= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
超级块和 INODE TABLE

块组描述符表(GDT)
ext文件系统每一个块组信息使用32字节描述,这32个字节称为块组描述符,所有块组的块组描述符组成块组描述符表GDT(group desciptor table)。虽然每个块组都需要块组描述符来记录块组的信息和属性元数据,但是不是每个块组中都存放了块组描述符。将所有块组的块组信息组成一个GDT保存,并将该GDT存放于某些块组中,类似存放superblock和备份superblock的块。
- MBR:磁盘分区表信息
- Partition:分区
- Boot Sector:第一个扇区,默认启动系统扇区
- File System:文件系统类型设置
- Block Group:块组,默认是4K。将文件系统管理的分区进行细分,方便管理
- Super Block 超级块:就是描述文件系统的属性,包括分组等等文件系统的元数据信息。
- GDT :是分组的描述表属于元数据信息。
- Block Bitmap:Block 块的位图(表示块空间的使用情况),标记哪块空间可以使用,哪块空间不能使用
- Inode Bitmap:Inode 节点号的位图(表示节点空间的使用情况),标记哪块空间可以使用,哪块空间不能使用
- Inode Table:节点表,存放文件的元数据属性信息
- Data Blocks:数据块,数据存放的位置
- Block Group:块组,默认是4K。将文件系统管理的分区进行细分,方便管理
2.2.4.3 文件系统检测和修复
文件系统夹故障常发生于死机或者非正常关机之后,挂载为文件系统标记为“no clean”
注意:一定不要在挂载状态下执行下面的命令修复
2.2.4.3.1 fsck:File System Check
fsck.FS_TYPE
fsck -t FS_TYPE
注意:FS_TYPE 一定要与分区上已经文件类型相同
常用选项:
- -a:自动修复
- -r:交互式修复错误
2.2.4.3.2 e2fsck:ext 系列文件系统专用的检测修复工具
常用选项:
- -y:自动回答为yes
- -f:强制修复
- -p:自行进行安全的修复文件相同的问题
2.2.4.3.3 xfs_repair:xfs 文件系统专用的检测修复工具
常用选项:
- -f:修复文件,而设备不修复
- -n:只检测
- -d:允许修复只读的挂载设备,在单用户下修复 / 时使用,然后立刻 reboot
范例:修改破坏的ext文件系统
~ mkdir -p /mnt/dev-sdb1
~ mount /dev/sdb1 /mnt/dev-sdb1
~ cp /etc/fstab /mnt/dev-sdb1/f1.txt
~ cp /etc/issue /mnt/dev-sdb1/f2.txt
~ ls /mnt/dev-sdb1/
f1.txt f2.txt lost+found#进行破坏实验
~ dd if=/dev/zero of=/dev/sdb1 bs=1M count=1
1+0 records in
1+0 records out
1048576 bytes (1.0 MB, 1.0 MiB) copied, 0.000903455 s, 1.2 GB/s
~ tune2fs -l /dev/sdb1
tune2fs 1.45.6 (20-Mar-2020)
tune2fs: Bad magic number in super-block while trying to open /dev/sdb1
~ df -Th /dev/sdb1
Filesystem Type Size Used Avail Use% Mounted on
/dev/sdb1 ext4 64Z 64Z 0 100% /mnt/dev-sdb1
#取消挂载
~ umount /dev/sdb1
#进行ext文件系统修复
~ e2fsck -y /dev/sdb1e2fsck 1.45.6 (20-Mar-2020)
/dev/sdb1 was not cleanly unmounted, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
Block bitmap differences: +(32768--33794) +(98304--99330) +(163840--164866) +(229376--230402) +(294912--295938) +(819200--820226) +(884736--885762) +(1605632--1606658)
Fix? yesFree blocks count wrong for group #0 (23510, counted=23511).
Fix? yesFree blocks count wrong (2554686, counted=2554687).
Fix? yesFree inodes count wrong for group #0 (8181, counted=8179).
Fix? yesFree inodes count wrong (655349, counted=655347).
Fix? yesPadding at end of inode bitmap is not set. Fix? yes/dev/sdb1: ***** FILE SYSTEM WAS MODIFIED *****
/dev/sdb1: 13/655360 files (0.0% non-contiguous), 66753/2621440 blocks
#重新挂载
~ mount /dev/sdb1 /mnt/dev-sdb1/
~ ls /mnt/dev-sdb1/
~ tune2fs -l /dev/sdb1
2.2.5 文件系统的扩容和缩容
底层分区需要使用 LVM 逻辑卷的技术。可以先了解并掌握逻辑卷功能后,再来查看该步骤。
扩容:先扩逻辑卷,后扩文件系统
缩容:先缩文件系统,后缩逻辑卷
#sdb和sdc各创建两块硬盘,并设置为"Linux LVM"分区类型
echo -e "n\np\n\n\n+10G\nt\n\n8e\nw\n" | fdisk /dev/sdb #用于ext文件系统
echo -e "n\np\n\n\n+10G\nt\n\n8e\nw\n" | fdisk /dev/sdc #用于xfs文件系统#加入到物理卷中
pvcreate /dev/sdb1 /dev/sdb2
pvcreate /dev/sdc1 /dev/sdc2#加入到卷组中
vgcreate vg_ext /dev/sdb1 /dev/sdb2
vgcreate vg_xfs /dev/sdc1 /dev/sdc2
~ vgsVG #PV #LV #SN Attr VSize VFree vg_ext 2 0 0 wz--n- 19.99g 19.99gvg_xfs 2 0 0 wz--n- 19.99g 19.99g#加入到逻辑卷中(各自创建15G的逻辑卷)
lvcreate -n lv_ext -L +15G vg_ext
lvcreate -n lv_xfs -L +15G vg_xfs
~ lvsLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert lv_ext vg_ext -wi-a----- 15.00g lv_xfs vg_xfs -wi-a----- 15.00g#创建各自的目录进行挂载(方便后续的扩容缩容数据变化)
~ mkdir -p /mnt/{ext,xfs}
~ ls -ld /mnt/{ext,xfs}
~ lsblk -fp
#创建相应的文件系统FileSystem
~ mkfs -t ext4 -L "EXT4 FileSystem" /dev/mapper/vg_ext-lv_ext
#xfs文件系统的标签最大12个字符
~ mkfs.xfs -L "XFS_FS" /dev/mapper/vg_xfs-lv_xfs #进行挂载操作
~ mount /dev/mapper/vg_ext-lv_ext /mnt/ext
~ mount /dev/mapper/vg_xfs-lv_xfs /mnt/xfs#存放测试到挂载目录中
cp /etc/fstab /mnt/ext/ ; cp /etc/passwd /mnt/ext/ ; cp /etc/issue /mnt/ext/
cp /etc/fstab /mnt/xfs/ ; cp /etc/passwd /mnt/xfs/ ; cp /etc/issue /mnt/xfs/
ls -l /mnt/ext /mnt/xfs
2.2.5.1 ext4文件系统进行扩容
#ext4文件系统进行扩容
#方法1:分区空间和文件系统单独扩容(15G-->16G)
~ lvextend -L +1G /dev/vg_ext/lv_extSize of logical volume vg_ext/lv_ext changed from 15.00 GiB (3840 extents) to 16.00 GiB (4096 extents).
~ lvs | grep lv_extlv_ext vg_ext -wi-ao---- 16.00g
~ lsblk -fp
#文件系统扩容
~ df -Th
~ resize2fs /dev/mapper/vg_ext-lv_ext
~ df -Th | grep /dev/mapper/vg_ext-lv_ext
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_ext-lv_ext ext4 16G 45M 15G 1% /mnt/ext#方法2:分区空间和文件系统一起扩容(16G-->17G)
~ lvextend -L +1G -r /dev/vg_ext/lv_ext
~ lsblk /dev/mapper/vg_ext-lv_ext
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vg_ext-lv_ext 253:3 0 17G 0 lvm /mnt/ext
~ df -Th
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_ext-lv_ext ext4 17G 45M 15G 1% /mnt/ext### /mnt/ext目录下的内容依旧存在
2.2.5.2 ext4文件系统进行缩容
#ext4文件系统进行缩容
#方法1:分区空间和文件系统单独缩容(17G-->16G)
~ umount /mnt/ext
#文件系统缩容
~ e2fsck -f /dev/mapper/vg_ext-lv_ext
~ resize2fs /dev/mapper/vg_ext-lv_ext 16G
#逻辑卷缩容
~ lvreduce -L -1G /dev/mapper/vg_ext-lv_ext
~ lvs
#重新进行挂载
~ mount /dev/mapper/vg_ext-lv_ext /mnt/ext
~ /mnt/ext#方法2:分区空间和文件系统一起缩容(16G-->15G)
~ umount /mnt/ext
#文件系统和逻辑卷缩容
~ lvreduce -L -1G /dev/mapper/vg_ext-lv_ext
~ lvs
#重新进行挂载
~ mount /dev/mapper/vg_ext-lv_ext /mnt/ext
~ ls -lh /mnt/ext
### /mnt/ext目录下的内容依旧存在,但是缩容一定要进行数据的备份
2.2.5.3 xfs文件系统进行扩容
#xfs文件系统进行扩容
#方法1:分区空间和文件系统单独扩容(15G-->16G)
~ lvextend -L +1G /dev/mapper/vg_xfs-lv_xfsSize of logical volume vg_xfs/lv_xfs changed from 15.00 GiB (3840 extents) to 16.00 GiB (4096 extents).
~ lvs | grep lv_xfslv_xfs vg_xfs -wi-ao---- 16.00g
~ lsblk /dev/mapper/vg_xfs-lv_xfs
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vg_xfs-lv_xfs 253:4 0 16G 0 lvm /mnt/xfs#文件系统扩容
~ df -Th
~ xfs_growfs /dev/mapper/vg_xfs-lv_xfs
~ df -Th /dev/mapper/vg_xfs-lv_xfs
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_xfs-lv_xfs xfs 16G 33M 16G 1% /mnt/xfs#方法2:分区空间和文件系统一起扩容(16G-->17G)
~ lvextend -L +1G -r /dev/mapper/vg_xfs-lv_xfs
~ lsblk /dev/mapper/vg_xfs-lv_xfs
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vg_xfs-lv_xfs 253:4 0 17G 0 lvm /mnt/xfs
~ df -Th /dev/mapper/vg_xfs-lv_xfs
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg_xfs-lv_xfs xfs 17G 33M 17G 1% /mnt/xfs### /mnt/xfs目录下的内容依旧存在
2.2.5.4 xfs文件系统进行缩容
#xfs文件系统只能扩容而无法收缩,如果要想收缩,可以先备份,之后再进行减容重建,再恢复数据。
#必须要这样写xfsdump -f /data/lv_xfs.img /mnt/lv_xfs(即/lv_xfs后面的/不能要)这样才能成功
~ yum install -y xfsdump
~ xfsdump -f /data/lv_xfs.img /mnt/xfs
~ mkdir -p /data/lv_xfs_backup
~ cp -av /mnt/xfs/* /data/lv_xfs_backup#xfs文件系统进行缩容
#方法:分区空间和文件系统缩容(17G-->16G)
~ umount /mnt/ext
#逻辑卷缩容
~ lvreduce -L -1G /dev/mapper/vg_xfs-lv_xfs
~ lvs
#强制重新进行部署文件系统
~ mkfs -t xfs -L "XFS-FS" -f /dev/mapper/vg_xfs-lv_xfs
#重新进行挂载并导入之前数据
~ mount /dev/mapper/vg_xfs-lv_xfs /mnt/xfs
~ xfsrestore -f /data/lv_xfs.img /mnt/xfs/
~ ls -lh /mnt/xfs
### /mnt/xfs目录下的内容依旧存在,但是缩容一定要进行数据的备份
2.3 挂载
挂载:将额外文件系统与根文件系统某现存的目录建立起关联关系,进而使得此目录做为其他文件访问入口的行为
卸载:为解除此关联关系的过程
把设备关联挂载点:mount Point
挂载点下原有文件在挂载完成后会被临时隐藏,因此挂载点目录一般为空
进程正在使用中的设备无法卸载
一个文件夹只能挂载一个设备文件(当然Docker技术中所使用的联合文件系统AUFS则是打破了该限制)
一个设备文件可以挂载多个空的文件夹
范例:
~ df -Th
2.3.1 挂载文件系统 mount
格式:
mount [-fnrsvw] [-t vfstype] [-o options] device mountpoint
device:指明要挂载的设备
- 设备文件:例如 /dev/sda5
- 卷标:-L ‘LABEL’,例如 -L ‘MYDATA’
- UUID:-U ’UUID‘,例如:-U ‘0ea9011c-474c-40c1-90d1-cb012c3f0769’
- 伪文件系统名称:proc sysfs devtmpfs configfs
mountpoint:挂载点
- 要事先存在,建议使用空目录
mount 常用选项:
- -t vsftype:指定要挂载的设备上的文件系统类型
- -r:readonly,只读挂载
- -w:read and write 读写挂载
- -n:不更新 /etc/mtab,mount 不可见(CentOS 7之后就没有实际意义)
- -a:自动挂载所有支持自动挂载的设备(定义在了/etc/fstab文件中,并且挂载选项中有auto功能)
- -L ’LABEL‘:以卷标指定挂载设备
- -U ’UUID‘:以UUID指定要挂载的设备
- -B,–bind:绑定目录到另一个目录上
- -o options:(挂载文件系统的选项),多个选项使用逗号分隔
- async:异步模式,内存更改时,写入缓存区 buffer 中,过一点时间,再写入磁盘中(当内存把数据更新之后,会先写入缓存,再写入到磁盘中)
- sync:同步模式,内存更改时,同时写磁盘(当内存把数据更新之后,会立即写入磁盘,不好写缓存)
- atime/noatime:包含目录和文件(最后一次读时间)
- diratime/nodiratime:目录的访问时间戳
- auto/noauto:是否支持自动挂载,是否支持 -a 选项
- exec/noexec:是否支持此文件系统上运行的应用程序(例如:脚本)
- dev/nodev:是否支持在此文件系统上使用设备文件(例如:/dev/zero)
- suid/nosuid:是否支持 suid 和 sgid 权限
- remount:重新挂载
- ro:只读;
- rw:读写;
- user/nouser:是否允许普通用户挂载此设备,/etc/fstab 使用
- acl:启用此文件系统上的acl 功能
- loop:使用 loop 设备,把文件(带文件系统的文件)往文件夹里挂载
- _netdev:当网络可用时才对网络资源进行挂载,如:NFS文件系统
- defaults:相当于rw,suid,dev,exec,auto,nouser,async
挂载规则:
- 一个挂载点,同一时间只能挂载一个设备
- 一个挂载点,同一时间挂载了多个设备,只能看到最后一个设备的数据,其他设备上的数据将被隐藏
- 一个设备可以同时挂载到多个挂载点
- 通常一个挂载点一般是为已经存在空的目录
2.3.2 卸载文件系统 umount
卸载时:可使用设备,也可以使用挂载点
umount 设备名 | 挂载点

范例:取消挂载出现设备忙碌的情况
umount: <MountPoint>: target is busy.#若需要修改设备文件挂载的参数,可以使用remount的参数
~ mount -o remount,rw /mnt/dev-sdb1
~ mount | grep /mnt/dev-sdb1###若就是想要将该设备文件取消挂载
#查看用户使用该目录文件的信息
~ fuser -v /mnt/dev-sdb1USER PID ACCESS COMMAND
/mnt/dev-sdb1: root kernel mount /mnt/dev-sdb1root 36378 ..c.. bash
#会直接将用户踢出终端
~ fuser -km /mnt/dev-sdb1
/mnt/dev-sdb1: 36378c
#取消挂载
~ umount /mnt/dev-sdb1
2.3.3 查看挂载情况
查看挂载
# 通过查看 /etc/mtab 文件显示当前已经挂载的所有设备
mount
# 查看内核追踪到的已经挂载的所有设备
cat /proc/mounts
查看挂载点情况
findmnt MOUNT_POINT | device
范例:判断某个目录是否为挂载点
~ findmnt /mnt/dev-sdb1
TARGET SOURCE FSTYPE OPTIONS
/mnt/dev-sdb1 /dev/sdb1 ext4 rw,relatime,seclabel
查看正在访问指定文件系统的进程:lsof fuser
lsof MOUNT_POINT
fuser -v MOUNT_POINT
终止所有正在访问指定文件系统的进程:fuser
fuser -km MOUNT_POINT
范例:
#查看正在访问指定文件系统的进程
~ lsof /mnt/dev-sdb1
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
bash 86647 root cwd DIR 8,17 4096 2 /mnt/dev-sdb1
~ fuser -v /mnt/dev-sdb1USER PID ACCESS COMMAND
/mnt/dev-sdb1: root kernel mount /mnt/dev-sdb1root 86647 ..c.. bash
#终止所有正在访问指定文件系统的进程
~ fuser -km /mnt/dev-sdb1# -B:将挂载文件以块设备的形式进行挂载
➜ ~ mkdir -p /mnt/dev-boot
➜ ~ mount /boot /mnt/dev-boot
mount: /boot is not a block device
➜ ~ mount -B /boot /mnt/dev-boot
➜ ~ ls /mnt/dev-boot
config-3.10.0-1160.el7.x86_64 initramfs-3.10.0-1160.el7.x86_64.img
efi symvers-3.10.0-1160.el7.x86_64.gz
grub System.map-3.10.0-1160.el7.x86_64
grub2 vmlinuz-0-rescue-cc2c86fe566741e6a2ff6d399c5d5daa
initramfs-0-rescue-cc2c86fe566741e6a2ff6d399c5d5daa.img vmlinuz-3.10.0-1160.el7.x86_64
➜ ~ ls /boot
config-3.10.0-1160.el7.x86_64 initramfs-3.10.0-1160.el7.x86_64.img
efi symvers-3.10.0-1160.el7.x86_64.gz
grub System.map-3.10.0-1160.el7.x86_64
grub2 vmlinuz-0-rescue-cc2c86fe566741e6a2ff6d399c5d5daa
initramfs-0-rescue-cc2c86fe566741e6a2ff6d399c5d5daa.img vmlinuz-3.10.0-1160.el7.x86_64
#相当于软链接
➜ ~ ls -ld /mnt/dev-boot
dr-xr-xr-x. 5 root root 4096 Oct 30 2020 /mnt/dev-boot
➜ ~ umount /mnt/dev-boot
2.3.4 持久挂载
将挂载保存到 /etc/fstab 中可以下次开机时,自动启用挂载
/etc/fstab 格式:帮助 man 5 fstab
每行定义一个要挂载的文件系统,其中包括共 6 项
- 1.要挂载的设备或者伪文件系统
- 设备文件
- LABEL:LABEL=“”
- UUID:UUID=“”“
- 伪文件系统名称:proc、sysfs
- 2.挂载点:必须是事先存在的目录
- 3.文件系统类型:ext4、xfs、iso9660、nfs、none
- 4.挂载选项:defaults、acl、bind
- 5.转储频率:0:不做备份 1:每天转储 2:每隔一天转储
- 6.fsck 检查的文件系统的顺序:允许的数字是 0 1 2
- 0:不自检 1:首先自检;一般只有 rootfs 才用 2:非 rootfs 使用
添加新的挂载项,需要执行下面命令生效:
mount -a
范例:持久挂载
~ blkid | grep sdb1
/dev/sdb1: UUID="40791215-aa2b-439a-9d44-e88a02f24c2f" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="6375efad-01"~ vim /etc/fstab
UUID=40791215-aa2b-439a-9d44-e88a02f24c2f /mnt/mysql ext4 defaults 0 0~ mount -a
~ mount | grep /dev/sdb1
/dev/sdb1 on /mnt/mysql type ext4 (rw,relatime,seclabel)
范例:CentOS 7,8 /etc/fstab 的分区 UUID 错误,无法启动
# CentOS 8 /etc/fstab 的分区 UUID 错误,无法启动
~ blkid
/dev/sdb1: LABEL="/mnt/sdb1" UUID="01ebcdcd-3569-4ecc-a397-92a0b7808008" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="9d02f6ff-46bc-2741-ae42-dcb6df6ed2be"~ cat /etc/fstab
UUID=1ebcdcd-3569-4ecc-a397-92a0b7808008 /mnt/sdb1 ext4 defaults,noexec,acl 0 0
~ reboot# 处理方法:进入救援模式
# 将有问题的UUID注释掉或者修改正确
~ mount -o remount,rw /
~ cat /etc/fstab
UUID=01ebcdcd-3569-4ecc-a397-92a0b7808008 /mnt/sdb1 ext4 defaults,noexec,acl 0 0
~ cat /etc/fstab
# UUID=01ebcdcd-3569-4ecc-a397-92a0b7808008 /mnt/sdb1 ext4 defaults,noexec,acl 0 0
~ reboot
#就可以正常的进入操作系统了。### 马哥教育推荐过程(与以上操作一致)
#自动进入emergency mode,输入root密码
cat /proc/mounts #可以查看到/ 以 rw方式挂载
vim /etc/fstab #注释或者将错误的地方进行纠正后保存退出
reboot #重启即可
范例:CentOS6 /etc/fstab 的分区UUID错误,无法启动
# CentOS 6 /etc/fstab 的分区 UUID 错误,无法启动
~ blkid
/dev/sda3: UUID="df82123a-8c1f-483b-82b3-94b5d46554fa" TYPE="ext4"~ vim /etc/fstab
UUID=f82123a-8c1f-483b-82b3-94b5d46554fa /data ext4 defaults 1 2# 处理方法:进入救援模式
# 将有问题的UUID注释掉或者修改正确或者将fsck检查设置为0
~ mount -o remount,rw /
~ vim /etc/fstab
# UUID=f82123a-8c1f-483b-82b3-94b5d46554fa /data ext4 defaults 1 2
~ vim /etc/fstab
UUID=df82123a-8c1f-483b-82b3-94b5d46554fa /data ext4 defaults 1 2
~ vim /etc/fstab
UUID=df82123a-8c1f-483b-82b3-94b5d46554fa /data ext4 defaults 1 0### 马哥教育推荐过程(与以上操作一致)
#如果/etc/fstab的挂载设备出错,比如文件系统故障,并且文件系统检测项(即第6项为非0),将导致无法启动
cat /proc/mounts #可以查看到/ 以 ro方式挂载
#重新挂载/根目录
mount -o remount,rw /
vim /etc/fstab #注释或者将错误的地方进行纠正后保存退出
#将故障行的最后1项,即第6项修改为0,开机不检测此项挂载设备的健康性,从而忽略错误,能够实现启动
reboot #重启即可
范例:/etc/fstab格式
~ cat /etc/fstab
UUID=350eb3e0-4b6a-4036-a1c0-fcbcc1b58140 / xfs defaults 0 0
/disk/img /data/disk xfs defaults 0 0
/etc /mnt/etc none bind 0 0CentOS6~ cat /etc/fstab
/disk/img /data/disk ext4 loop 0 0
2.4 处理交换文件和分区
2.4.1 swap 分区介绍
swap 交换分区是系统RAM的补充,swap 分区支持虚拟内存,当没有足够的RAM 保存系统处理的数据时会将数据写入 swap 分区,当系统缺乏 swap 空间时,内核会因 RAM 内存耗尽而终止进程。配置过多 swap 空间会造成存储设备处于分配状态但是闲置,造成浪费,过多的 swap 空间还会掩盖内存泄漏。
注意:为了优化性能,可以将 swap 发布存放,或者高性能磁盘存放。
官方推荐系统swap空间:官方推荐系统 swap 空间
| 系统中的RAM是 | 推荐的 swap 空间 | 允许休眠的建议 swap 空间大小 |
|---|---|---|
| 低于 2 GB | RAM 容量的2倍数 | RAM 容量的三倍 |
| 2 GB - 8 GB | 等于 RAM 容量 | RAM 容量的倍数 |
| 8 GB - 64 GB | 4 GB 到 RAM 容量的 0.5倍 | RAM 容量的 1.5倍 |
| 超过 64 GB | 独立负载(至少 4GB) | 不建议使用休眠功能 |
范例:查看当前系统的内存空间
free -h
2.4.2 交换分区实现过程
1.创建交换分区或者文件
2.使用 mkswap 写入特殊签名
3.在 /etc/fstab 文件中添加适当的条目
4.使用 swapon -a 激活交换分区
启用 swap 分区
swapon [OPTIONS]... [DEVICE]
选项:
- -a:激活所有的交换分区
- -p PRIORITY:指定优先级,也可以在 /etc/fstab 在第四列指定:pri=value
范例:创建swap分区
~ echo -e "n\np\n\n\n+2G\nt\n82\nw\n" | fdisk /dev/sdc
~ mkswap fdisk /dev/sdc
~ blkid /dev/sdc#持久挂载
~ vim /etc/fstab
/dev/sdc swap swap defaults 0 0
~ free -h
~ cat /proc/swaps
禁用 swapon 分区:
swapoff [OPTIONS]... [DEVICE]
范例:禁用swap空间
#禁用swap空间
sed -i.bak -r '/swap/s@(.*)@#\1@ig' /etc/fstab
sed -i.bak '/swap/d' /etc/fstab#临时禁用swap空间
swapoff -a
SWAP 的优先级
可以指定 swap 分区 0 到 32768 的优先级,值越大优先级越高
如果用户没有指定,那么核心会自动给 swap 指定一个优先级,这个优先级从 -1 开始,每加入一个新的没有用户指定优先级的 swap,会给这个优先级减一
先添加的 swap 的缺省优先级比较高,除非用户自己指定一个优先级,而用户指定的优先级(是正数)永远高于核心缺省指定的优先级(是负数)
范例:修改swap分区的优先级
~ vim /etc/fstab
/dev/sdc1 swap swap defaults,pri=10 0 0
范例:以文件实现 swap 功能
~ dd if=/dev/zero of=/swapfile bs=1M count=1024
~ chmod a= /swapfile
#创建swap格式
~ mkswap /swapfile
~ blkid /swapfile
/swapfile: UUID="2eac6ac6-23a0-4195-a08f-da1605997382" TYPE="swap"#挂载
~ vim /etc/fstab
/swapfile swap swap defaults 0 0
~ swapon -a
~ swapon -s
Filename Type Size Used Priority
/swapfile file 2097148 0 -4#取消挂载
~ swapoff /swapfile #或者使用swapoff -a,swap空间全部清空
~ swapon -s
#移动到其他的分区
~ mv /swapfile /data~ vim /etc/fstab
#将该文件的挂载行注释掉即可
~ swapon -a
2.4.3 swap 的使用策略
/proc/sys/vm/swappiness 的值决定了当内存到达一定的百分比时,会启用 swap 分区的空间
范例:
~ ls -l /proc/sys/vm/swappiness
-rw-r--r-- 1 root root 0 Aug 8 12:33 /proc/sys/vm/swappiness
~ cat /proc/sys/vm/swappiness
30
说明:当内存在使用到 100 - 30 = 70% 的时候,就开始出现有交换分区的使用,简单来说这个参数定义了系统对 swap 的使用倾向,默认值为 30 ,值越大表示越倾向于使用 swap 。可以设为 0。这样做并不会禁止对 swap 的使用,只是最大限度的降低使用 swap 的可能性。
2.5 移动介质
挂载意味着使外来的文件系统看起来如同是主目录树的一部分,所有的移动介质也需要挂载,挂载点通常在 /media 或者 /mnt 下。
访问前:介质必须被挂载
摘除时:介质必须被卸载
按照默认设置,非根用户只能挂载某些设备(光盘、DVD、软盘、USB等等)
2.5.1 使用光盘
在图形环境下自动启动挂载 /run/media//
mount /dev/cdrom /mnt
范例:
~ ll /dev/cdrom
lrwxrwxrwx 1 root root 3 Aug 8 12:33 /dev/cdrom -> sr0
操作光盘
eject # 弹出光盘
eject -t # 弹入光盘
创建 ISO 文件
~ cp /dev/cdrom /root/centos.iso
~ mkisofs -r -o /root/etc.iso /etc #来自于genisoimage包
刻录光盘
wodim -v -eject centos.iso
将ISO制作为U盘工具Rufus
官网站点:http://rufus.ie/
Rufus是一个开源免费的快速制作U盘系统启动盘和格式化USB的实用小工具,它可以快速把)ISO格式的系统镜像文件快速制作成可引导的USB启动安装盘,支持Windows 或 Linux启动。Rufus 小巧玲珑,软件体积仅7百多KB,然而麻雀虽小,它却五脏俱全。
2.5.2 USB介质
查看 USB 设备是否识别
lsusb #来自于usbuntils包
被内核探测为SCSI设备
/dev/sdaX、/dev/sdbX 或者类似的设备文件
在图形环境下自动启动挂载 /run/media//
手动挂载
mount /dev/sdX# /mnt
范例:插入U盘后可以看到日志信息

文件的权限是文件系统控制的。文件系统来控制是否区分大小写。
~ tail -f /var/log/message
~ dmesg
范例:格式化U盘为 FAT32 文件系统
~ yum install -y dosfstools
~ mkfs.xfat /dev/sdd1
~ mount /dev/sdd1 /mnt/sdd1
范例:查看USB设备(USB 介质识别)
~ yum install -y usbutils
~ lsusb
Bus 001 Device 006: ID 0930:6545 Toshiba Corp. Kingston DataTraveler 102/2.0 / HEMA Flash Drive 2 GB / PNY Attache 4GB Stick
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Bus 002 Device 004: ID 0e0f:0008 VMware, Inc.
Bus 002 Device 003: ID 0e0f:0002 VMware, Inc. Virtual USB Hub
Bus 002 Device 002: ID 0e0f:0003 VMware, Inc. Virtual Mouse
Bus 002 Device 001: ID 1d6b:0001 Linux Foundation 1.1 root hub
~ lsblk -f
~ mount /dev/sde /media
~ ls /media
2.6 磁盘常见工具
2.6.1 文件系统空间占用等信息的查看工具 df
df 查看的是文件系统的占用空间的大小
df [OPTIONS]… [FILE]…
常用选项:
- -H:以 10 为单位
- -T:文件系统类型
- -h:human-readable
- -i:inodes instead of blocks,显示 inodes 节点表
- -P:以 Posix 兼容的格式输出
范例:
#查看文件系统的空间大小
~ df -Th
~ lsblk -f
~ lsblk#空洞文件,稀疏文件(不占资源空间)
dd if=/dev/zero of=bigfile bs=1M count=0 seek=1024
#以 Posix 兼容的格式输出
~ df -P
2.6.2 查看某个目录总体空间占用状态 du
du 查看的是文件夹的占用空间大小,可能会存在跨设备的情况,即目录下可能有其他的设备文件的挂载点,du 也会记录挂载点的空间大小
du [OPTION]… DIR
常用选项:
- -h:human-readable
- -s:summary
- –max-depth=# :指定最大目录层级
- -x, --one-file-system :忽略不在同一个文件系统的目录
范例:
~ du -sh /*
~ du -h -x --max-depth /
大厂面试题:df 和 du 的区别,什么时候df > du,什么时候 du > df?
#目录内挂载有其他分区时的情况
#当删除文件但不释放空间时,有什么不同?
du 查看文件空间释放,df 不释放#df 和 du 的区别
df:查看文件系统空间占用的大小
du:查看目录总体空间占用的大小#什么时候 df > du,什么时候 du > df
目录内挂载有其它分区时的情况
2.6.3 工具 dd
Linux dd 命令用于读取、转换并输出数据。
dd 可从标准输入或文件中读取数据,根据指定的格式来转换数据,再输出到文件、设备或标准输出。
dd 命令:convert and copy a file
格式:
dd if=/PATH/FROM/SRC of=/PATH/TO/DEST bs=# count=#
参数说明:
- if=文件名:输入文件名,默认为标准输入。即指定源文件。
- of=文件名:输出文件名,默认为标准输出。即指定目的文件。
- ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes:同时设置读入/输出的块大小为bytes个字节。 - cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。
- skip=blocks:从输入文件开头跳过blocks个块后再开始复制。
- seek=blocks:从输出文件开头跳过blocks个块后再开始复制。
- count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。
- conv=conversion[,conversion…]:用指定的参数转换文件,关键字可以有以下11种:
- conversion:用指定的参数转换文件。
- ascii:转换ebcdic为ascii
- ebcdic:转换ascii为ebcdic
- ibm:转换ascii为alternate ebcdic
- block:把每一行转换为长度为cbs,不足部分用空格填充
- unblock:使每一行的长度都为cbs,不足部分用空格填充
- lcase:把大写字符转换为小写字符
- ucase:把小写字符转换为大写字符
- swap:交换输入的每对字节
- noerror:出错时不停止
- notrunc:不截短输出文件
- sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。
- fdatasync :写完成前,物理写入输出文件
- –help:显示帮助信息
- –version:显示版本信息
范例:
#备份MBR
dd if=/dev/sda of=/tmp/mbr.bak bs=512 count=1#破坏MBR中的bootloader
dd if=/dev/zero of=/dev/sda bs=64 count=1 seek=446#有一个大与2K的二进制文件fileA。现在想从第64个字节位置开始读取,需要读取的大小是128Byts。又有fileB, 想把上面读取到的128Bytes写到第32个字节开始的位置,替换128Bytes,实现如下
dd if=fileA of=fileB bs=1 count=128 skip=63 seek=31 conv=notrunc#将本地的/dev/sdx整盘备份到/dev/sdy
dd if=/dev/sdx of=/dev/sdy#将/dev/sdx全盘数据备份到指定路径的image文件
dd if=/dev/sdx of=/path/to/image#备份/dev/sdx全盘数据,并利用gzip压缩,保存到指定路径
dd if=/dev/sdx | gzip >/path/to/image.gz#将备份文件恢复到指定盘
dd if=/path/to/image of=/dev/sdx#将压缩的备份文件恢复到指定盘
gzip -dc /path/to/image.gz | dd of=/dev/sdx#将内存里的数据拷贝到root目录下的mem.bin文件
dd if=/dev/mem of=/root/mem.bin bs=1024#拷贝光盘数据到root文件夹下,并保存为cdrom.iso文件
dd if=/dev/cdrom of=/root/cdrom.iso#销毁磁盘数据
dd if=/dev/urandom of=/dev/sda1#通过比较dd指令输出中命令的执行时间,即可确定系统最佳的block size大小
dd if=/dev/zero of=/root/1Gb.file bs=1024 count=1000000
dd if=/dev/zero of=/root/1Gb.file bs=2048 count=500000
dd if=/dev/zero of=/root/1Gb.file bs=4096 count=250000#测试硬盘写速度
dd if=/dev/zero of=/root/1Gb.file bs=1024 count=1000000#测试硬盘读速度
dd if=/root/1Gb.file bs=64k | dd of=/dev/null
范例:
➜ ~ echo "abcdef" > f1.txt
➜ ~ echo "123465789" > f2.txt
➜ ~ dd if=f1.txt of=f2.txt bs=1 count=2 skip=3 seek=4
2+0 records in
2+0 records out
2 bytes (2 B) copied, 0.000151979 s, 13.2 kB/s
➜ ~ cat f2.txt
1234de➜ ~ dd if=f1.txt of=f2.txt bs=1 count=2 skip=3 seek=4 conv=notrunc
2+0 records in
2+0 records out
2 bytes (2 B) copied, 0.000166856 s, 12.0 kB/s
➜ ~ cat f2.txt
1234de789
2.7 练习
# 1、创建一个2G的文件系统,块大小为2048byte,预留1%可用空间,文件系统ext4,卷标为TEST,要求此分区开机后自动挂载至/test目录,且默认有acl挂载选项
# 2、写一个脚本,完成如下功能:
# (1) 列出当前系统识别到的所有磁盘设备
# (2) 如磁盘数量为1,则显示其空间使用信息
# 否则,则显示最后一个磁盘上的空间使用信息
# 3、将CentOS6的CentOS-6.10-x86_64-bin-DVD1.iso和CentOS-6.10-x86_64-bin-DVD2.iso两个文件,合并成一个CentOS-6.10-x86_64-Everything.iso文件,并将其配置为yum源
# 1、创建一个2G的文件系统,块大小为2048byte,预留1%可用空间,文件系统ext4,卷标为TEST,
# 要求此分区开机后自动挂载至/test目录,且默认有acl挂载选项
~ lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 200G 0 disk
~ echo -e "n\np\n\n\n+2G\nw\n" | fdisk /dev/sdb
~ lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 200G 0 disk
└─sdb1 8:17 0 2G 0 part
#块大小为2048byte,预留1%可用空间,文件系统ext4,卷标为TEST
~ mkfs.ext4 -b 2048 -m 1 -L "TEST" /dev/sdb1
#此分区开机后自动挂载至/test目录,且默认有acl挂载选项
~ mkdir /test
~ echo "/dev/sdb1 /test ext4 defaults,acl 0 0" >> /etc/fstab
~ mount -a
#验证
~ lsblk -fp /dev/sdb
NAME FSTYPE LABEL UUID MOUNTPOINT
/dev/sdb
└─/dev/sdb1 ext4 TEST 5fbfec76-edd0-4c00-9788-bb90808c4028 /test
~ dumpe2fs /dev/sdb1 | less# 2、写一个脚本,完成如下功能:
# (1) 列出当前系统识别到的所有磁盘设备
# (2) 如磁盘数量为1,则显示其空间使用信息
# 否则,则显示最后一个磁盘上的空间使用信息
~ vim checkdisk_use.sh
#!/bin/bash#SHELL ENV
DISKNAME=$(lsblk | grep -Eo "^[svh]d[a-z]")
DISKCOUNT=$(lsblk | grep -Eo "^[svh]d[a-z]" | wc -l)
BASECOLOR="\E[1;32m"
ENDCOLOR="\E[0m"echo -e "${BASECOLOR}当前系统识别到的所有磁盘设备 : ${ENDCOLOR}\n${DISKNAME}"if [ ${DISKCOUNT} -eq 1 ]
thenecho -e "${BASECOLOR}显示其空间使用信息 : ${ENDCOLOR}"fdisk -l /dev/${DISKNAME}
else#获取最后一个磁盘名称echo -e "${BASECOLOR}最后一个磁盘上的空间使用信息 : ${ENDCOLOR}"LASTDISKNAME=$(lsblk | grep -Eo "^[svh]d[a-z]" | tail -n1)fdisk -l /dev/${LASTDISKNAME}
fi# 3、将CentOS6的CentOS-6.10-x86_64-bin-DVD1.iso和CentOS-6.10-x86_64-bin-DVD2.iso两个文件,合并成一个CentOS-6.10-x86_64-Everything.iso文件,并将其配置为yum源
# 方法一:推荐
~ mkdir -pv /mnt/DVD{1..2}
~ mount -o loop,rw /data/CentOS-6.10-x86_64-bin-DVD1.iso /mnt/DVD1/
~ mount -o loop,rw /data/CentOS-6.10-x86_64-bin-DVD2.iso /mnt/DVD2/
~ mkdir -pv /mnt/CentOS6-Everything
~ cp -av /mnt/DVD1/* /mnt/CentOS6-Everything/
~ cp -av /mnt/DVD2/Packages/*.rpm /mnt/CentOS6-Everything/Packages/
~ cat /mnt/DVD{1..2}/TRANS.TBL | sort > /mnt/CentOS6-Everything/TRANS.TBL
~ mkisofs -r -o /data/CentOS-6.10-x86_64-Everything.iso /mnt/CentOS6-Everything# 方法二
~ mkdir -pv /mnt/DVD{1..2}
~ mount -o loop,rw /data/CentOS-6.10-x86_64-bin-DVD1.iso /mnt/DVD1/
~ mount -o loop,rw /data/CentOS-6.10-x86_64-bin-DVD2.iso /mnt/DVD2/
~ mkdir -pv everything
~ cp -av /mnt/DVD1/* /data/everything/
~ cp -av /mnt/DVD2/* /data/everything/
~ du -sh /data/everything/
~ cat /mnt/DVD{1..2}/TRANS.TBL | sort > /mnt/CentOS6-Everything/TRANS.TBL
~ mkisofs -r -o /data/CentOS-6.10-x86_64-Everything.iso /data/everything### 将其配置为yum源
~ mkdir -pv /mnt/CentOS6-Everything
~ mount -o loop,rw /data/CentOS-6.10-x86_64-Everything.iso /mnt/CentOS6-Everything
~ ls /mnt/CentOS6-Everything/Packages/ | wc -l
6714
~ df -Th
Filesystem Type Size Used Avail Use% Mounted on
/data/CentOS-6.10-x86_64-Everything.iso iso9660 5.8G 5.8G 0 100% /mnt/CentOS6-Everything
~ cat /etc/yum.repos.d/CentOS-Everything.repo
[CentOS-Everything]
name=CentOS-Everything
baseurl=file:///mnt/CentOS6-Everything
enabled=1
gpgecheck=0
3 RAID
3.1 什么是 RAID
“RAID”—词是由Daid Patterson, Garth A.Gibson, Randy Katz于1987年在加州大学伯克利分校发明的。在1988年6月SIGMOD会议上提交的论文"A Case forRedundant Arrays of lnexpensive Disks""中提出,当时性能最好的大型机不断增长的个人电脑市场开发的一系列廉价驱动器的性能所击败。尽管故障与驱动器数量的比例会上升,但通过配置冗余,阵列的可靠性可能远远超过任何大型单个驱动器的可靠性
独立硬盘冗余阵列(RAID, Redundant Aray of ndependent Disks),旧称廉价磁盘冗余阵列(Redundant Array of lnexpensive Disks),简称磁盘阵列。利用虚拟化存储技术把多个硬盘组合起来,成为一个或多个硬盘阵列组,目的为提升性能或数据冗余,或是两者同时提升。
RAID层级不同,数据会以多种模式分散于各个硬盘,RAID层级的命名会以RAID开头并带数字,例如: RAIDO、RAID1、RAID 5、RAID 6、RAlD7、RAID01、RAID10、RALD 50、RAID 60。每种等级都有其理论上的优缺点,不同的等级在两个目标间获取平衡,分别是增加数据可靠性以及增加存储器(群)读写性能。
简单来说,RAID把多个硬盘组合成为一个逻辑硬盘,因此,操作系统只会把它当作一个实体硬盘。RAID常被用在服务器电脑上,并且常使用完全相同的硬盘作为组合。由于硬盘价格的不断下降与RAID功能更加有效地与主板集成,它也成为普通用户的一个选择,特别是需要大容量存储空间的工作,如:视频与音频制作。
RAID:Redundant Arrays of Inexpensive(Independent)Disks
1988 年由加利福尼亚大学伯克利分校(University of California-Berkeley)“A Case for Redundant Arrays of Inexpensive Disks”
多个磁盘合成一个“陈列”来提供更好的性能、冗余、或者两者都提供。
RAID
- 提供IO能力 ,磁盘并行读写
- 提高耐用性 ,磁盘冗余来实现
- RAID实现的方式:
- 外接式磁盘陈列:通过扩展卡提供适配能力
- 内接式 RAID:主板集成 RAID 控制器,安装 OS 前在 BIOS 里配置
- 软件 RAID(软RAID):通过 OS 实现,比如:群晖的NAS
3.2 RAID 级别
- 级别:多块磁盘组织在一起的工作方式有所不同
- 参考链接:https://zh.wikipedia.org/wiki/RAID
RAID-0:条带卷,strip
RAID-1:镜像卷,mirror
RAID-2
…
RAID-5
RAID-6
RAID-10
RAID-01
RAID-50
…
通常情况下,做RAID的硬盘容量大小是一样的。不然会出现"木桶效应"。
3.2.1 RAID-0
以 chunk 单位读写数据,因为读写时都可以并行处理,所以在所有的级别中,RAID0 的速度是最快的。但是RAID0 既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失。(企业生产环境中基本上不会使用)
单块硬盘可以做 RAID0,但是没有任何意义,也提供不了其他的RAID的特性。企业中只有一块硬盘,另一块硬盘还没有到位,但又急着配置。那么就拿现存的一块硬盘配RAID0,然后再将后续的硬盘到位后插到存储服务器上,组成RAID0。
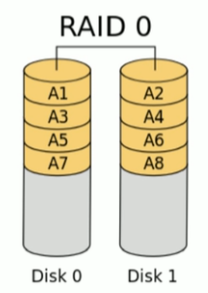
读写性能提升
- 可用空间:N * min(S1 , S2 ,…)
- 无容错能力
- 最少磁盘数:1+
3.2.2 RAID-1
也称为镜像,两组以上的N个磁盘相互作镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与RAID0 相同。另外写入速度有微小的降低。(企业生产环境中一般用于系统盘)
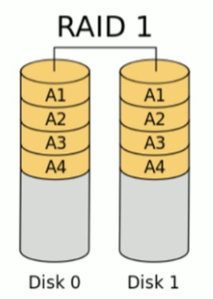
读性能提升,写性能略有下降
- 可用空间:1 * min(S1 , S2 ,…)
- 磁盘利用率:50%
- 有容错能力
- 最少磁盘数:2+
3.2.3 RAID-4
多块数据盘异或运算值存于专用校验盘,RAID4即带奇偶校验码的独立磁盘结构。
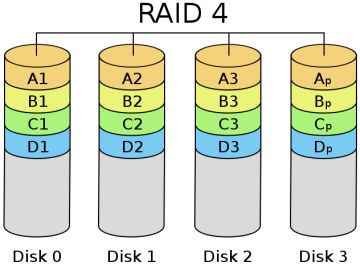
读写性能提升
- 有冗余能力
- 至少 3 块硬盘才可以实现,最少磁盘数:3+
- 磁盘利用率:(N-1) / N
- 有容错能力:允许最多 1块 磁盘损坏
3.2.4 RAID-5
RAID 5 是一种存储性能、数据安全和存储成本兼顾的存储解决方案。 RAID 5可以理解为是RAID 0和RAID 1的折中方案。RAID 5可以为系统提供数据安全保障,但保障程度要比Mirror低而磁盘空间利用率要比Mirror高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低,是运用较多的一种解决方案。(之前企业生产环境中用于数据盘)

读、写性能提升
- 可用空间:(N - 1) * min(S1 , S2 ,…) -> (N - 1) / N
- 有容错能力:允许最多 1块 磁盘损坏
- 最少磁盘数:3,3+
3.2.5 RAID-6
RAID6技术是在RAID 5基础上,为了进一步加强数据保护而设计的一种RAID方式,实际上是一种扩展RAID 5等级。与RAID 5的不同之处于除了每个硬盘上都有同级数据XOR校验区外,还有一个针对每个数据块的XOR校验区。当然,当前盘数据块的校验数据不可能存在当前盘而是交错存储的,具体形式见图。这样一来,等于每个数据块有了两个校验保护屏障(一个分层校验,一个是总体校验),因此RAID 6的数据冗余性能相当好。但是,由于增加了一个校验,所以写入的效率较RAID 5还差,而且控制系统的设计也更为复杂,第二块的校验区也减少了有效存储空间。

双份校验位,算法更加复杂
读、写性能提升
- 可用空间:(N - 2) * min(S1 , S2 ,…) -> (N - 2) / N
- 有容错能力:允许最多 2块 磁盘损坏
- 最少磁盘数:4,4+
3.2.6 RAID-10
RAID-10 和 RAID-01 中推荐使用 RAID-10.(RAID-10:企业生产环境中用于数据盘)
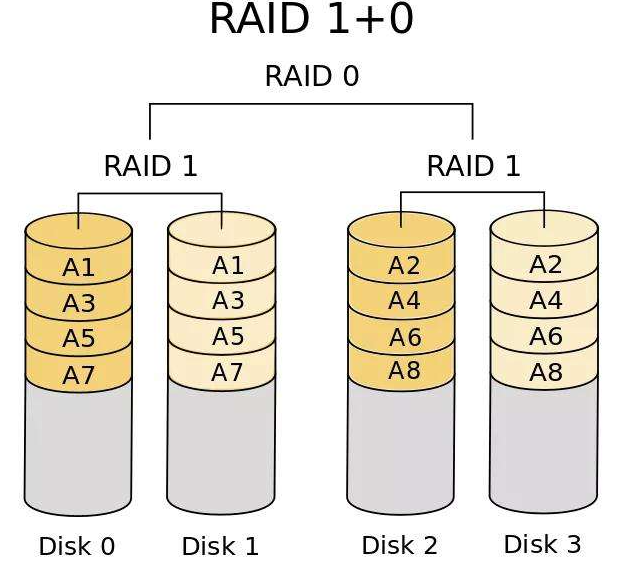
多块磁盘先实现 RAID 1 ,再组合成 RAID 0
读、写性能提升
- 可用空间:N * min(S1 , S2 ,…)/2
- 有容错能力:每组镜像最多只能坏掉一块硬盘;如果有一组 RAID 1中磁盘坏掉了,则Disk 1和另一组的RAID 进行匹配提供服务,若真的无法提供服务的概率则是有一组RAID 1磁盘全部坏掉,则失败概率为 1/3
- 最少磁盘数:4,4+
3.2.7 RAID-01
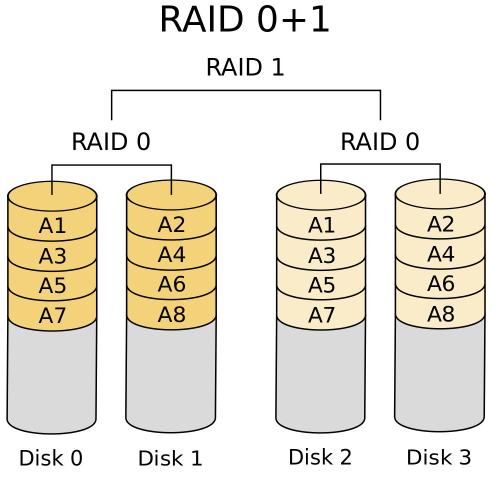
多块磁盘先实现 RAID 0 ,再组合成 RAID 1
读、写性能提升
- 可用空间:N * min(S1 , S2 ,…)/2
- 有容错能力:每组镜像最多只能坏掉一块硬盘;如果有一组 RAID 0中磁盘坏掉了,则只能由另一组的RAID 0提供服务,如果另一组RAID 0中的其中一块磁盘坏掉,则没有办法提供服务,即失败概率为 2/3
- 最少磁盘数:4,4+
3.2.8 RAID-50

多块硬盘先实现 RAID 5,再组合成 RAID 0。
- 具备更高的容错能力
- 最少磁盘数:6,6+
3.2.9 RAID-60
具备更高的容错性,支持同时两块硬盘出现故障的修复功能,和更高的读性能。技术上还存在一定的问题,不够成熟,目前很少使用者。

3.2.10 其他级别
JBON:Just Bunch Of Disk 只是一堆磁盘

功能:将多块磁盘的空间合并成一个大的连续空间使用;RAID JBOD将所有的磁盘串联成一个单一的,容量是使用的磁盘的总和的存储设备供操作系统使用。比如使用3块容量是80GB的磁盘,建立的RAID JBOD设备的容量就是240GB,再比如使用3块容量分别是60GB,80GB,100GB的磁盘,建立的RAID JBOD设备容量是240GB。
第一块硬盘存放所有磁盘的分段信息,如果损坏,整个陈列会失败。
后续磁盘损坏只会影响本块磁盘的数据
可用空间:sum( S1 , S2 ,… )
RAID 7
RAID7并非公开的RAID标准,而是美国公司的Storage Computer Corporation的专利硬件产品名称,RAID7是以RAID 3及RAID4为基础所发展,但是经过强化以解决原来的一些限制。另外,在实现中使用大量的缓冲存储器以及用以实现异步数组管理的专用即时处理器,使得RAID7可以同时处理大量的l0要求,所以性能甚至超越了许多其他RAID标准的实际产品。但也因为如此,在价格方面非常的高昂.RAID7可以理解为一个独立存储计算机,自身带有操作系统和管理工具,可以独立运行,理论上性能最高的RAID模式。
可以理解为独立存储计算机,自身带有操作系统和管理工具,可以独立运行,理论上性能最高的RAID模式
SHR(Synology Hybrid RAID)
群晖公司的技术,适合不了解RAID的普通用户
根据磁盘个数自动组成不同的RAID,1块普通磁盘,2块RAID1,3块RAID4,SHR2类似于RAID6
只支持群晖系统
3.2.10 RAID 总结
常用级别:
RAID-0 ; RAID-1 ; RAID-5 ; RAID-10 ; RAID-50 ; JBOD

磁盘陈列比较表
| RAID等级 | 最少硬盘 | 最大容错 | 可用容量 | 读取性能 | 写入性能 | 安全性 | 目的 | 应用场景 |
|---|---|---|---|---|---|---|---|---|
| 单一硬盘 | (参考) | 0 | 1 | 1 | 1 | 无 |
|
|
| JBOD | 1 | 0 | n | 1 | 1 | 无(同RAID0) | 增加容量 | 个人(暂时)存储备份 |
| 0 | 1 | 0 | n | n | n | 一个硬盘异常,全部硬盘都会异常 | 追求最大容量,速度 | 影片剪接缓存用途 |
| 1 | 2 | n-1 | 1 | n | 1 | 高,一个正常即可 | 追求最大安全性 | 个人,企业备份 |
| 5 | 3 | 1 | n-1 | n-1 | n-1 | 高 | 追求最大容量,最小预算 | 个人,企业备份 |
| 6 | 4 | 2 | n-2 | n-2 | n-2 | 安全性较RAID5高 | 同RAID5,但较安全 | 个人,企业备份 |
| 10 | 4 |
|
|
|
| 高 | 综合RAID0/1优点,理论速度较快 | 大型数据库,服务器 |
| 50 | 6 |
|
|
|
| 高 | 提升数据安全 |
|
| 60 | 8 |
|
|
|
| 高 | 提升数据安全 |
|
3.2.11 各个RAID 的区别
| RAID 级别 | 可用空间 | 读写性能 | 容错能力 | 最少磁盘数 |
|---|---|---|---|---|
| RAID-0 | N * min (S1 , S2 ,…) | 读、写性能提升 | 无容错能力 | 2,2+ |
| RAID-1 | 1 * min (S1 , S2 ,…) | 读性能提升、写性能略有下降 | 有冗余能力 | 2,2N |
| RAID-4 | (N - 1) / N | 读、写性能提升 | 有冗余能力 | 至少3块硬盘 |
| RAID-5 | (N - 1) * min (S1 , S2 ,…) | 读、写性能提升 | 允许最多1块磁盘损坏 | 3,3+ |
| RAID-6 | (N - 2) * min(S1 , S2 ,…) | 读、写性能提升 | 允许最多2块磁盘损坏 | 4,4+ |
| RAID-7 | 属于独立的存储计算机独立运行 | 读、写性能提升 | 自身系统管理 | 自身系统管理 |
| RAID-10 | N * min(S1 , S2 ,…) / 2 | 读、写性能提升 | 每组镜像最多只能坏一块 | 4,4+ |
| RAID-01 | N * min(S1 , S2 ,…) / 2 | 读、写性能提升 | 有冗余能力 | 4,4+ |
| RAID-50 |
| 读、写性能提升 | 有冗余能力 | 6,6+ |
3.3 实现软RAID
mdadm 工具:为软 RAID 提供管理界面,为空余磁盘添加冗余,结合内核中的 md (multi devices)
RAID 设备可以命名为 /dev/md0、/dev/md1、/dev/md2、/dev/md3等等。
mdadm:模式化的工具,支持的RAID级别:LINEAR、RAID0、RAID4、RAID5、RAID6、RAID10
命令的语法格式:
mdadm [mode] <raiddevice> [options] <component-devices>
3.3.1 命令的语法格式
mdadm [mode] [options]
3.3.2 模式
- 创建:-C
- 装配:-A
- 监控:-F
- 管理:-f,-r,-a
:/dev/md#
:任意块设备
- -C:创建模式
- -n # :使用 # 个块设备来创建此 RAID
- -l # :指明要创建的 RAID 的级别
- -a {yes | no} :自动创建目标 RAID 设备的设备文件
- -c CHUNK_SIZE :指明块大小,单位 K
- -x # :指明空闲盘的个数
- -n # :指定阵列中主用设备的数量
- -D:显示 RAID 的详细信息
- mdadm -D /dev/md#
- -S :停止 RAID 磁盘陈列
- -Q:查看 RAID 的摘要信息
管理模式:
- -f:标记指定磁盘为损坏
- -a:添加磁盘
- -r:移除磁盘
观察 md 的状态:cat /proc/mdstat
3.3.3 范例
# 使用 mdadm 创建并定义RAID设备
# -C:创建模式;-a yes:添加磁盘;-l:指明RAID级别;-n:指定阵列中主用设备的数量;-x:指明空闲盘的个数;
mdadm -C /dev/md0 -a yes -l 5 -n 3 -x 1 /dev/sd{b,c,d,e}1
# 用文件系统对每个RAID设备进行格式化
mkfs.xfs /dev/md0# 使用 mdadm 检查 RAID 设备的状况
mdadm --detail | D /dev/md0# 增加新的成员
mdadm -G /dev/md0 -n 4 -a /dev/sdf1# 模拟磁盘故障
mdadm /dev/md0 -f /dev/sda1# 移除磁盘
mdadm /dev/md0 -r /dev/sda1# 在备用驱动器上重建分区
mdadm /dev/md0 -a /dev/sda1# 系统日志信息
cat /proc/mdstat
生成配置文件:
mdadm -D -s >> /etc/mdadm.conf
3.3.4 停止设备
mdadm -S /dev/md0
3.3.5 激活设备
mdadm -A -s /dev/md0
3.3.6 强制启动
mdadm -R /dev/md0
3.3.7 删除 RAID 信息
mdadm --zero-superblock /dev/sdb1
3.3.8 练习
# 1:创建一个可用空间为1G的RAID1设备,文件系统为ext4,有一个空闲盘,开机可自动挂载至/backup目录
# 2:创建由三块硬盘组成的可用空间为2G的RAID5设备,要求其chunk大小为256k,文件系统为ext4,开机可自动挂载至/mydata目录
~ yum install -y mdadm
# 1:创建一个可用空间为1G的RAID1设备,文件系统为ext4,有一个空闲盘,开机可自动挂载至/backup目录
#创建一个可用空间为1G的RAID1设备,文件系统为ext4,有一个空闲盘
~ echo -e "n\np\n\n\n+1G\nw\n" | fdisk /dev/sdb
~ echo -e "n\np\n\n\n+1G\nw\n" | fdisk /dev/sdc #执行两遍,有一块盘作为空闲盘使用
~ mdadm -C /dev/md0 -a yes -l 1 -n 2 -x 1 /dev/sdb1 /dev/sdc1 /dev/sdc2
~ lsblk /dev/md0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md0 9:0 0 1022M 0 raid1
~ lsblk
~ mkfs.ext4 /dev/md0
~ dumpe2fs /dev/md0
#开机可自动挂载至/backup目录
~ mkdir /backup
~ echo "/dev/md0 /backup ext4 defaults 0 0" >> /etc/fstab
~ mount -a
~ df -Th /dev/md0
Filesystem Type Size Used Avail Use% Mounted on
/dev/md0 ext4 990M 2.6M 921M 1% /backup# 2:创建由三块硬盘组成的可用空间为2G的RAID5设备,要求其chunk大小为256k,文件系统为ext4,开机可自动挂载至/mydata目录
#可用空间为2G的RAID5设备:需要3块1G的磁盘文件(sdb2,sdb3,sdc3)
~ echo -e "n\np\n\n\n+1G\nw\n" | fdisk /dev/sdb
~ echo -e "n\np\n\n\n+1G\nw\n" | fdisk /dev/sdc
~ mdadm -C /dev/md1 -a yes -l 5 -n 3 -c 256 /dev/sdb2 /dev/sdb3 /dev/sdc3
~ lsblk /dev/md1
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md1 9:1 0 2G 0 raid5
~ lsblk
~ mkfs.ext4 /dev/md1
~ dumpe2fs /dev/md1
#开机可自动挂载至/mydata目录
~ mkdir /mydata
~ echo "/dev/md1 /mydata ext4 defaults 0 0" >> /etc/fstab
~ mount -a
~ df -Th /dev/md1
Filesystem Type Size Used Avail Use% Mounted on
/dev/md1 ext4 2.0G 6.0M 1.9G 1% /mydata
分区的特点就是所有的空间必须来自同一块硬盘的连续空间,分区分完之后并不能进行扩容缩容的功能。Linux 工具并没有提供。分区的使用是固定的。分区存在缺点:容错性差 --> 解决方法:RAID(一般通过使用硬件:磁盘陈列卡),RAID的扩容和缩容会影响正常使用。
4 逻辑卷管理器(LVM)
4.1 LVM 介绍
LVM:Logical Volume Manager 可以允许对卷进行方便操作的抽象层,包括重新设定文件系统的大小,允许再多个物理设备间重新组织文件系统。
LVM 可以动态弹性的更改 LVM 的容量。

通过交换 PE 来进行资料的转换,将原来 LV 内的 PE 转移到其他的设备中以降低 LV 的容量,或将其他设备中的 PE 加到 LV 中以加大容量中。
实现过程
- 将设备指定为物理卷
- 用一个或者多个物理卷来创建一个卷组,物理卷是用固定大小的物理区域(Physical Extent ,PE)来定义的
- 在物理卷上创建的逻辑卷,是由物理区域(PE)组成的
- 可以在逻辑卷上创建文件系统并进行挂载

第一个逻辑卷对应设备名:/dev/dm.-#
dm:device mapper,将一个或者多个块设备组成一个逻辑设备的模块
软连接:
- /dev/mapper/VG_NAME-LV-NAME
- /dev/VG_NAME/LV_NAME
范例:
/dev/mapper/vol0-root
/dev/vol0/root
4.2 实现逻辑卷
相关工具来自于 lvm2 包
需要将设备文件的类型设置为 8e ‘Linux LVM’
4.2.1 pv 管理工具
显示 PV 信息:
pvs:用于输出格式化的物理卷信息报表。使用pvs命令仅能得到物理卷的概要信息,如果要得到更加详细的信息可以使用pvdisplay命令。
pvdisplay:用于显示物理卷的属性。pvdisplay命令显示的物理卷信息包括:物理卷名称、所属的卷组、物理卷大小、PE大小、总PE数、可用PE数、已分配的PE数和UUID。
pvs:简要 PV 信息显示
pvdisplay:详细 PV 信息显示
pvs 参数说明:
- –noheadings:不输出标题头;
- –nosuffix:不输出空间大小的单位。
pvdisplay 参数说明:
- -s:以短格式输出;
- -m:显示PE到LE的映射。
创建 PV:用于将物理硬盘分区初始化为物理卷,以便LVM使用。
pvcreate /dev/DEVICE
pvcreate 参数说明:
- -f:强制创建物理卷,不需要用户确认;
- -u:指定设备的UUID;
- -y:所有的问题都回答“yes”;
- -Z:是否利用前4个扇区。
删除 PV:用于删除一个存在的物理卷。使用pvremove指令删除物理卷时,它将LVM分区上的物理卷信息删除,使其不再被视为一个物理卷。
pvremove /dev/DEVICE
pvremove 参数说明:
- -d:调试模式;
- -f:强制删除;
- -y:对提问回答“yes”。
更改PV:允许管理员改变物理卷的分配许可。如果物理卷出现故障,可以使用pvchange命令禁止分配物理卷上的PE。
pvchange(选项)(参数)
pvchange [-x | -u] /dev/DEVICE
pvchange 参数说明:
- -u:生成新的UUID;
- -x:是否允许分配PE。
范例:
#创建物理卷
~ pvcreate /dev/sdb1
~ pvcreate /dev/sdc1
#得到物理卷的概要信息
~ pvsPV VG Fmt Attr PSize PFree/dev/sdb1 lvm2 --- 10.00g 10.00g/dev/sdc1 lvm2 --- 20.00g 20.00g
#查看物理卷详细信息显示
~ pvdisplay
4.2.2 vg 管理工具
显示 VG 卷组:
vgs:简要 VG 信息显示
vgdisplay:详细VG信息显示(用于显示LVM卷组的信息。如果不指定"卷组"参数,则分别显示所有卷组的属性。)
vgdisplay 参数说明:
- -A:仅显示活动卷组的属性;
- -s:使用短格式输出的信息。
创建 VG 卷组:用于创建LVM卷组。卷组(Volume Group)将多个物理卷组织成一个整体,屏蔽了底层物理卷细节。在卷组上创建逻辑卷时不用考虑具体的物理卷信息。
vgcreate [-s #[kKmMgGtTpPeE]] VolumeGroupName PhysicalDevicePath [PhysicalDevicePath...]#示例
vgcreate -s 16M vg0 /dev/sdb /dev/sdc #指定PE的大小,默认为4MB
vgcreate 参数说明:
- -l:卷组上允许创建的最大逻辑卷数;
- -p:卷组中允许添加的最大物理卷数;
- -s:卷组上的物理卷的PE大小。
管理 VG 卷组:
vgextend : 用于动态扩展LVM卷组,它通过向卷组中添加物理卷来增加卷组的容量。LVM卷组中的物理卷可以在使用vgcreate命令创建卷组时添加,也可以使用vgextend命令动态的添加。
vgreduce : 通过删除LVM卷组中的物理卷来减少卷组容量。不能删除LVM卷组中剩余的最后一个物理卷。
vgextend VolumeGroupName PhysicalDevicePath [PhysicalDevicePath...]
vgreduce VolumeGroupName PhysicalDevicePath [PhysicalDevicePath...]
vgextend 参数说明:
- -d:调试模式;
- -t:仅测试。
vgreduce 参数说明:
- -a:如果命令行中没有指定要删除的物理卷,则删除所有的空物理卷;
- –removemissing:删除卷组中丢失的物理卷,使卷组恢复正常状态。
更改 VG 卷组:
vgchange:用于修改卷组的属性,经常被用来设置卷组是处于活动状态或非活动状态。处于活动状态的卷组无法被删除,必须使用vgchange命令将卷组设置为非活动状态后才能删除。
vgchange(选项)(参数)
vgchange 参数说明:
- -a:设置卷组的活动状态。
删除 VG 卷组:
- 先做 pvmove
- 再做 vgremove
#用于用户删除LVM卷组。当要删除的卷组上已经创建了逻辑卷时,vgremove命令需要进行确认删除,防止误删除数据。
vgremove VolumeGroupName
vgremove 参数说明:
- -f:强制删除。
范例:
#默认PE的大小空间为4MB
#-s:指定PE的空间大小
~ vgcreate -s 4M vg0 /dev/sdb1 /dev/sdc1Volume group "vg0" successfully created
~ vgsVG #PV #LV #SN Attr VSize VFreevg0 2 0 0 wz--n- 29.99g 29.99g
~ vgdisplay
4.2.3 lv 管理工具
显示 LV 逻辑卷:
lvs:概要性的查看LVM逻辑卷信息
lvdisplay:用于显示LVM逻辑卷空间大小、读写状态和快照信息等属性。如果省略"逻辑卷"参数,则lvdisplay命令显示所有的逻辑卷属性。否则,仅显示指定的逻辑卷属性。
lvs:简要 LV 信息显示
lvdisplay:详细 LV 信息显示
创建 LV 逻辑卷:
lvcreate:用于创建LVM的逻辑卷。逻辑卷是创建在卷组之上的。逻辑卷对应的设备文件保存在卷组目录下
例如:在卷组"vg1000"上创建一个逻辑卷"lvol0",则此逻辑卷对应的设备文件为"/dev/vg1000/lvol0"。
lvcreate -L #[mMgGtT] -n NAME VolumeGroup
lvcreate 参数说明:
- -L:指定逻辑卷的大小,单位为“kKmMgGtT”字节;
- -l:指定逻辑卷的大小(LE数)。
范例:
lvcreate -l 60%VG -n mylv testvg
lvcreate -l 100%FREE -n yourlv testvg
删除 LV 逻辑卷:
lvremove:用于删除指定LVM逻辑卷。如果逻辑卷已经使用mount命令加载,则不能使用lvremove命令删除。必须使用umount命令卸载后,逻辑卷方可被删除。
lvremove /dev/VG_NAME/LV_NAME
lvremove 参数说明:
- -f:强制删除。
重设文件系统的大小
fsadm [options] resize device [new_size[BKMGTEP]]#只用于ext文件系统类型
resize2fs [-f] [-F] [-M] [-P] [-p] device [new_size]#只用于xfs文件系统类型
xfs_growfs /mountpoint
范例:使用逻辑卷建立文件系统
#创建物理卷
pvcreate /dev/sda3#为卷组分配物理卷
vgcreate vg0 /dev/sda3#从卷组创建逻辑卷
lvcreate -L 256M -n data vg0
#查看逻辑卷信息
lvs
lvdisplay
#mkfs.xfs /dev/vg0/data#加载服务配置文件
systemctl daemon-reload#挂载
mount /dev/vg0/data /mnt/data#
systemctl daemon-reload: 重新加载某个服务的配置文件,如果新安装了一个服务,归属于 systemctl 管理,要是新服务的服务程序配置文件生效,需重新加载。
范例:测试逻辑卷速度
#普通分区IO性能速度
~ dd if=/dev/zero of=/mnt/bigfile.img bs=1M count=800
800+0 records in
800+0 records out
838860800 bytes (839 MB, 800 MiB) copied, 6.13092 s, 137 MB/s
#后续执行dd命令将可能会走缓存
~ free -htotal used free shared buff/cache(缓存) available
Mem: 3.6Gi 657Mi 1.7Gi 10Mi 1.3Gi 2.7Gi
Swap: 0B 0B 0B
#将缓存数据清除(一般用于测试性能)
~ find /proc/ -name "drop*" #找到/proc/sys/vm/drop_caches
~ cat /proc/sys/vm/drop_caches
0
#3是清理缓存
~ echo 3 > /proc/sys/vm/drop_caches
~ free -htotal used free shared buff/cache available
Mem: 3.6Gi 636Mi 2.8Gi 10Mi 247Mi 2.8Gi
Swap: 0B 0B 0B
#逻辑卷的IO性能速度较快
~ dd if=/dev/zero of=/mnt/mysql/bigfile.img bs=1M count=800
800+0 records in
800+0 records out
838860800 bytes (839 MB, 800 MiB) copied, 2.22195 s, 378 MB/s
4.2.4 扩展和缩减逻辑卷
4.2.4.1 在线扩展逻辑卷
lvextend命令来自于英文词组“logical volume extend”的缩写,其功能是用于扩展逻辑卷设备。LVM逻辑卷管理器技术具有灵活调整卷组与逻辑卷的特点,逻辑卷设备容量可以在创建时规定,亦可以后期根据业务需求进行动态扩展或缩小。
常用参数:
| -L | 指定逻辑卷的大小(容量单位) |
|---|---|
| -l | 指定逻辑卷的大小(PE个数) |
| -r | 扩展逻辑卷同时同步文件系统空间 |
#两步实现
#第一步实现逻辑卷的空间扩展
lvextend -L [+]#[mMgGtT] /dev/VG_NAME/LV_NAME#第二步实现文件系统的扩展(十分重要,否则无法在 df 命令中查看到对应挂载点的扩容空间)
#针对ext文件系统
resize2fs /dev/VG_NAME/LV_NAME
#针对xfs文件系统
xfs_growfs MOUNTPOINT#一步逻辑卷和文件系统的扩展
lvextend -r -l +100%FREE /dev/VG_NAME/LV_NAME
4.2.4.2 缩减逻辑卷
注意:缩减有数据损坏的风险,建议先备份再缩减,xfs文件系统不支持缩减
umount /dev/VG_NAME/LV_NAME
e2fsck -f /dev/VG_NAME/LV_NAME
resize2fs /dev/VG_NAME/LV_NAME #[mMgGtT]
lvreduce -L [-]#[mMgGtT] /dev/vG_NAME/LV_NAME
mount /dev/vG_NAME/LV_NAME mountpoint
范例:
#ext4文件系统缩容
~ blkid /dev/vg0/mysql
/dev/vg0/mysql: UUID="f578bc7d-9a7a-4a8c-bde0-f8c46c9c4150" BLOCK_SIZE="4096" TYPE="ext4"
~ lvs /dev/vg0/mysqlLV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convertmysql vg0 -wi-ao---- 3.00g
df -Th /dev/vg0/mysql
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/vg0-mysql ext4 2.9G 9.0M 2.8G 1% /mnt/mysql#第一步 备份数据(必须要做)
~ du -sh /mnt/mysql
1.1G /mnt/mysql
~ cp /mnt/mysql /data/backup#第二步 取消逻辑卷挂载
~ umount /dev/vg0/mysql#第三步 ext文件系统空间缩容
~ e2fsck -f /dev/vg0/mysql
e2fsck 1.45.6 (20-Mar-2020)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/vg0/mysql: 1937/196608 files (0.2% non-contiguous), 300921/786432 blocks
~ resize2fs /dev/vg0/mysql 2G
resize2fs 1.45.6 (20-Mar-2020)
resize2fs: New size smaller than minimum (560305)#第四步 逻辑卷空间缩容
~ lvreduce -L 2G /dev/vg0/mysql#第五步 重新挂载
~ mount /dev/vg0/mysql /mnt/mysql
4.2.5 跨主机迁移卷组
该步骤作为了解即可
源计算机上:
- 在旧的系统中,umount 所有卷组上的逻辑卷
- 禁用卷组
vgchange -a -n vg0
lvdisplay
- 导出卷组
vgexport vg0
pvscan
vgdisplay
- 拆下旧硬盘在目标计算机上,并导入卷组
vgimport vg0
- 启用
vgchange -ay vg0
- mount 所有卷组上的逻辑卷
4.2.6 拆除指定的PV存储设备
范例:拆除指定的PV存储设备
#挑选需要拆除的PV存储设备
#举例:以sdc硬盘为例进行演示
#查看是否已经使用了sdc硬盘
~ lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 100G 0 disk
└─sdc1 8:33 0 20G 0 part└─vg1-oracle 253:4 0 1G 0 lvm /mnt/oracle
#查看sdc硬盘卷组是否有多余空间进行转移数据
~ pvs /dev/sdc1PV VG Fmt Attr PSize PFree/dev/sdc1 vg1 lvm2 a-- <20.00g <19.00g
~ pvs | grep vg1/dev/sdb3 vg1 lvm2 a-- <20.00g <20.00g/dev/sdc1 vg1 lvm2 a-- <20.00g <19.00g
~ vgdisplay vg1
#进行数据迁移
~ pvmove /dev/sdc1
~ pvs | grep vg1/dev/sdb3 vg1 lvm2 a-- <20.00g <19.00g/dev/sdc1 vg1 lvm2 a-- <20.00g <20.00g
#将sdc移除卷组并移除物理卷
~ vgreduce vg1 /dev/sdc1
~ pvremove /dev/sdc1
~ pvs | grep /dev/sdc1
#已经没有结果。就可以拆除该PV的存储设备
#干净的硬盘
~ lsblk /dev/sdc
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 100G 0 disk
└─sdc1 8:33 0 20G 0 part
4.3 逻辑卷快照
4.3.1 逻辑卷快照原理

快照是特殊的逻辑卷,它是在生成快照时存在的逻辑卷的准确拷贝,对于需要备份或者复制的现有数据临时拷贝以及其他操作来说,快照是最合适的选择,快照只有它们和原来的逻辑卷不同时才会消耗空间,建立快照的卷大小小于原始逻辑卷,也可以使用 lvextend 扩展快照。
逻辑卷管理快照:
快照就是将当前的系统信息记录下来,就好像照相一般,若将来有任何数据改动,则原始数据会将被移动到快照区,没有改动的区域则由快照区和文件系统共享。
逻辑卷快照工作原理:
- 在生成快照时会分配给它一定的空间,但是只有在原来的逻辑卷或者快照有所改变才会使用这些空间
- 当原来的逻辑卷中有所改变时,会将旧的数据复制到快照中
- 快照中只含有原来的逻辑卷中更改的数据或者自动生成快照后的快照中更改的数据
由于快照区与原来的 LV 共用很多 PE 的区块,因此快照与被快照的 LV 必须是同一个 VG 中,系统恢复的时候的文件数量不能高于快照区的实际容量。
快照特点:
- 备份速度快,瞬间完成
- 应用场景是测试环境,不能完成代替备份
- 快照后,逻辑卷的修改速度会一定有影响
4.3.2 实现逻辑卷快照
# 为现有逻辑卷创建快照
# -s:创建逻辑卷快照
# -n:指定逻辑卷名
# -p r:设置只读
lvcreate -l 64 -s -n data-snapshot -p r /dev/vg0/data# 挂载快照
mkdir -pv /mnt/snap
mount -o ro /dev/vg0/data-snapshot /mnt/snap# 恢复快照
umount /dev/vg0/data-snapshot
umount /dev/vg0/data
lvconvert --merge /dev/vg0/data-snapshot# 删除快照
umount /mnt/databackup
lvremove /dev/vg0/databackup
范例:
###ext文件系统进行快照
mkfs.ext4 /dev/vg0/data
mount /dev/vg0/data/ /mnt/data#为现有逻辑卷创建快照,注意ext4必须使用-pr实现只读
lvcreate -l 64 -s -n data-snapshot -pr /dev/vg0/data#挂戟快照,xfs注意要使用-o ro实现只读,访止快照被修改makdir -p/mnt/snap
mount -o ro,nouuid /dev/vg0/data-snapshot /mnt/snap#恢复快照
umount /dev/vg0/data-snapshot
umount /dev/vg0/data
lvconvert --merge /dev/vg0/data-snapshot #执行该命令后,快照将会自动消失
mount /dev/vg0/data /mnt/data###xfs文件系统进行快照
mkfs.xfs /dev/vg0/data
mount /dev/vg0/data/ /mnt/data#为现有逻辑卷创建快照,注意ext4必须使用-pr实现只读
lvcreate -l 64 -s -n data-snapshot -pr /dev/vg0/data#挂戟快照,xfs注意要使用-o ro实现只读,访止快照被修改
mkdir -p /mnt/snap
mount -o ro,nouuid /dev/vg0/data-snapshot /mnt/snap#恢复快照
umount /dev/vg0/data-snapshot
umount /dev/vg0/data
lvconvert --merge /dev/vg0/data-snapshot #执行该命令后,快照将会自动消失
mount /dev/vg0/data /mnt/data###删除快照
umount /mnt/snap
lvremove /dev/vg0/data-snapshot
4.3.3 练习
# 1、创建一个至少有两个PV组成的大小为20G的名为testvg的VG;要求PE大小为16MB, 而后在卷组中创建大小为5G的逻辑卷testlv;挂载至/users目录
# 2、新建用户archlinux,要求其家目录为/users/archlinux,而后su切换至archlinux用户,复制/etc/pam.d目录至自己的家目录
# 3、扩展testlv至7G,要求archlinux用户的文件不能丢失
# 4、收缩testlv至3G,要求archlinux用户的文件不能丢失
# 5、对testlv创建快照,并尝试基于快照备份数据,验证快照的功能
# 1、创建一个至少有两个PV组成的大小为20G的名为testvg的VG;要求PE大小为16MB, 而后在卷组中创建大小为5G的逻辑卷testlv;挂载至/users目录
#PV卷磁盘名称为(sdb5,sdc5)
~ echo -e "n\n\n+10G\nt\n\n8e\nw\n" | fdisk /dev/sdb
~ echo -e "n\n\n+10G\nt\n\n8e\nw\n" | fdisk /dev/sdc
#逻辑卷制作
~ pvcreate /dev/sdb5 /dev/sdc5
~ pvs && pvdisplay
~ vgcreate -s 16M testvg /dev/sd{b,c}5
~ vgs && vgdisplay
~ lvcreate -n testlv -L 5G testvg
~ lvs && lvdisplay
~ lsblk
#挂载至/users目录
~ mkdir /users
~ mkfs.ext4 /dev/testvg/testlv
~ mount /dev/testvg/testlv /users
~ df -Th /dev/testvg/testlv
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/testvg-testlv ext4 4.8G 20M 4.6G 1% /users# 2、新建用户archlinux,要求其家目录为/users/archlinux,而后su切换至archlinux用户,复制/etc/pam.d目录至自己的家目录
~ useradd -d /users/archlinux -m archlinux
~ echo "Admin@h3c" | passwd --stdin archlinux
~ su - archlinux
~ pwd
/users/archlinux
~ cp /etc/pam.d/* /users/archlinux# 3、扩展testlv至7G,要求archlinux用户的文件不能丢失
~ lvextend -L 7G /dev/testvg/testlv
~ lvdisplay /dev/testvg/testlv--- Logical volume ---LV Path /dev/testvg/testlvLV Name testlvVG Name testvgLV UUID mier0I-pfSf-gDLO-4l51-1JUE-2yfc-2ppdwVLV Write Access read/writeLV Creation host, time ansible-node01, 2022-06-06 15:04:35 +0800LV Status available# open 1LV Size 7.00 GiBCurrent LE 448Segments 1Allocation inheritRead ahead sectors auto- currently set to 8192Block device 253:3
~ resize2fs /dev/testvg/testlv## lvextend -r -L 7G /dev/testvg/testlv# 4、收缩testlv至3G,要求archlinux用户的文件不能丢失
#将archlinux用户退出登录,取消挂载
~ umount /users
~ df -Th | grep /users
#收缩testlv至3G
~ e2fsck -f /dev/testvg/testlv
~ resize2fs /dev/testvg/testlv 3G
~ lvreduce -L 3G /dev/testvg/testlv
~ lvs && lvdisplay
#重新挂载
~ mount /dev/testvg/testlv /users
~ df -Th /users
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/testvg-testlv ext4 2.9G 16M 2.7G 1% /users
~ ls /users/archlinux/
#可以查看到有数据在archlinux家目录中# 5、对testlv创建快照,并尝试基于快照备份数据,验证快照的功能
#testlv创建快照
~ lvcreate -s -n testlv-snapshot -L 100M /dev/testvg/testlv
#查看逻辑卷快照
~ lvs && lvdisplay#验证快照功能
#删除archlinux家目录中的所有数据
~ rm -rf /users/archlinux/* && ls /users/archlinux
#恢复快照
~ umount /users
~ lvconvert --merge /dev/testvg/testlv-snapshot
~ mount /dev/testvg/testlv /users
~ ls /users/archlinux
#archlinux家目录数据回来了
5 高级文件系统管理
范例:迁移/home目录到新的独立分区中
~ mount /dev/testvg/testlv /users
~ fdisk /dev/sda
~ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
├─sda1 8:1 0 2G 0 part /boot
├─sda2 8:2 0 100G 0 part /
├─sda3 8:3 0 100G 0 part /data
├─sda4 8:4 0 512B 0 part
├─sda5 8:5 0 4G 0 part [SWAP]
└─sda6 8:6 0 50G 0 part
~ mkfs.ext4 /dev/sda6 -L '/home'
# 将原有的家目录进行备份
~ mkdir -pv /mnt/home
~ mount /dev/sda6 /mnt/home/
~ blkid /dev/sda6
/dev/sda6: LABEL="/home" UUID="2a0490bd-73b3-431b-8bcc-0880a0a195ff" TYPE="ext4"
~ cp -av /home/* /mnt/home/
~ ll /mnt/home/
total 24
drwx------ 2 root root 16384 Sep 20 16:16 lost+found
drwx------ 3 wang wang 4096 Sep 20 16:18 wang
drwx------. 3 zzw zzw 4096 Jul 11 20:42 zzw
# 永久挂载
~ vim /etc/fstab
UUID=2a0490bd-73b3-431b-8bcc-0880a0a195ff /home ext4 defaults 0 0# 切换到单用户界面,并且将网络断开。让其他用户退出该系统
~ init 1
# 删除原有的家目录
~ rm -rf /home/*
~ mount -a
# 切换到字符界面
~ init 3
~ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
├─sda1 8:1 0 2G 0 part /boot
├─sda2 8:2 0 100G 0 part /
├─sda3 8:3 0 100G 0 part /data
├─sda4 8:4 0 1K 0 part
├─sda5 8:5 0 4G 0 part [SWAP]
└─sda6 8:6 0 50G 0 part /home
~ reboot
5.1 设定文件系统配额
1、综述
- 在内核中执行
- 以文件系统为单位启用
- 对不同组或者用户的策略不同
2、根据块或者节点进行限制
- 执行软限制(soft limit)
- 硬限制(hard limit)
3、初始化
- 分区挂载选项:usrquota、grpquota
- 初始化数据库:quotacheck
5.1.1 quotacheck
扫描挂入系统的分区,并在各分区的文件系统根目录下产生quota.user和quota.group文件,设置用户和群组的磁盘空间限制。
选项:
- -u,–user检查用户文件
- -g,–group检查组文件
- -c,–create-files创建新的配额文件
- -b,–backup创建旧配额文件的备份
- -f,–force强制检查,即使配额已经启用
- -i,–interactive交互模式
- -n,–use-first-dquot使用复制结构的第一个副本
- -v,–verbose输出更多信息
- -d,–debug打印更多的消息
- -m,–no-remount不以只读方式重新挂载文件系统
- -M,–try-remount以只读方式重新安装文件系统,即使失败了也要继续
- -R,–exclude-root在检查所有文件系统时排除root
- -F,–format=formatname检查指定格式的配额文件
- -a,–all检查所有文件系统
- -h,–help显示此消息并退出
- -V,–version显示版本信息并退出
范例:
~ fdisk /dev/sdb
~ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 100G 0 disk
└─sdb1 8:17 0 50G 0 part
~ mount -o usrquota,grpquota /dev/sdb1 /test
~ \cp -av /home/* /test/
~ quotacheck -cvug /test/
quotacheck: Your kernel probably supports journaled quota but you are not using it. Consider switching to journaled quota to avoid running quotacheck after an unclean shutdown.
quotacheck: Scanning /dev/sdb1 [/test] done
quotacheck: Checked 15 directories and 10 files
5.1.2 quotaon
开启磁盘配额:quotaon
选项:
- -a 开启在 /ect/fstab 文件里,有加入 quota 设置的分区的空间限制。
- -g 开启群组的磁盘空间限制。
- -u 开启用户的磁盘空间限制。
- -v 显示指令指令执行过程。
- -p 显示是否启用了磁盘配额
范例:
~ quotaon /test# 查看是否启用
~ quotaon -p /test
group quota on /test (/dev/sdb1) is on
user quota on /test (/dev/sdb1) is on
5.1.3 quotaoff
关闭磁盘配额:quotaoff
范例:
~ quotaoff /test/
~ quotaon -p /test/
group quota on /test (/dev/sdb1) is off
user quota on /test (/dev/sdb1) is off
5.2 为用户设定配额
- 开启或者取消配额:quotaon、quotaoff
- 直接编辑配额:edquota username
- 在shell中直接编辑:setquota username 4096 5120 40 50 /foo
- 定义原始标准用户:edquota -p user1 user2
5.2.1 edquota
直接编辑配额:edquota username
选项:
- -u 设置用户的磁盘配额,这是预设的参数。
- -g 设置群组的磁盘配额。
- -p<源用户名称> 将源用户的磁盘配额设置套用至其他用户或群组。
- -t 设置宽限期限。
范例:
# -u 设置用户的磁盘配额,这是预设的参数
~ edquota zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks soft hard inodes soft hard
/dev/sda6 52 80000 10000 13 150 200
/dev/sdb1 52 0 0 13 0 0# -g 设置群组的磁盘配额
~ edquota -g g1
Disk quotas for group g1 (gid 1005):
Filesystem blocks soft hard inodes soft hard
/dev/sda6 4 800000 1000000 2 0 0
/dev/sdb1 0 800000 1000000 0 0 0
范例:定义原始标准用户
~ edquota -p zzw wang
~ quota -u zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda6 52 80000 10000 14 150 200
~ quota -u wang
Disk quotas for user wang (uid 1001):
Filesystem blocks quota limit grace files quota limit grace/dev/sda6 28 80000 10000 7 150 200
5.2.2 setquota
在 shell 中直接编辑:setquota
格式:
- setquota -u 用户名 容量软限制 容量硬限制 文件个数软限制 文件个数硬限制 分区名
~ setquota -u wang 500000 1000000 1000 2000 /dev/sdb1
~ repquota -a
*** Report for user quotas on device /dev/sda6
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 52 80000 10000 14 150 200
wang -- 28 0 0 7 0 0*** Report for user quotas on device /dev/sdb1
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 52 0 0 13 0 0
wang -- 28 500000 1000000 7 1000 2000
5.3 报告配额状态
- 用户调查:quota username
- 配额概述:repquota /mountpoint
- 其他工具:warnquota
5.3.1 quota
Linux quota命令用于显示磁盘已使用的空间与限制。
执行quota指令,可查询磁盘空间的限制,并得知已使用多少空间。
选项:
- -g 列出群组的磁盘空间限制。
- -q 简明列表,只列出超过限制的部分。
- -u 列出用户的磁盘空间限制,这是预设的参数。
- -v 显示该用户或群组,在所有挂入系统的存储设备的空间限制。
- -V 显示版本信息。
范例:
# -u 默认选项,可以省略
~ quota -u zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda6 52 80000 10000 14 150 200~ quota zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda6 52 80000 10000 14 150 200~ quota -g g1
Disk quotas for group g1 (gid 1005):
Filesystem blocks quota limit grace files quota limit grace/dev/sda6 4 800000 1000000 2 0 0
5.3.2 repquota
Linux repquota命令用于检查磁盘空间限制的状态。
执行repquota指令,可报告磁盘空间限制的状况,清楚得知每位用户或每个群组已使用多少空间。
选项:
- -a 列出在/etc/fstab文件里,有加入quota设置的分区的使用状况,包括用户和群组。
- -g 列出所有群组的磁盘空间限制。
- -u 列出所有用户的磁盘空间限制。
- -v 显示该用户或群组的所有空间限制。
范例:
~ repquota -a
*** Report for user quotas on device /dev/sda6
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 52 80000 10000 14 150 200
wang -- 28 0 0 7 0 0*** Report for user quotas on device /dev/sdb1
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 52 0 0 13 0 0
wang -- 28 0 0 7 0 0~ repquota -ag
*** Report for group quotas on device /dev/sda6
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
Group used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 48 0 0 12 0 0
wang -- 28 0 0 7 0 0
g1 -- 4 800000 1000000 2 0 0*** Report for group quotas on device /dev/sdb1
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
Group used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 52 0 0 13 0 0
wang -- 28 0 0 7 0 0
~ repquota -aug
范例:控制用户使用的空间大小(独立分区)磁盘配额
# 开启磁盘配额的选项
~ mount
/dev/sda6 on /home type ext4 (rw,relatime,quota,data=ordered)# 选项:可以通过man mount,搜索ext4分区选项设置,/ext4
# usrquota:对用户进行磁盘配额
# grpquota:对用户组进行磁盘配额
~ cat /etc/fstab
UUID=2a0490bd-73b3-431b-8bcc-0880a0a195ff /home ext4 usrquota,grpquota,default s 0 0
~ mount -o remount /home/
~ mount
/dev/sda6 on /home type ext4 (rw,relatime,quota,usrquota,grpquota,data=ordered)# 创建磁盘配额的数据库
~ cd /home/
# 关闭SELinux功能
~ setenforce 0
~ quotacheck -cug /home
~ ls /home/
aquota.group aquota.user lost+found wang zzw
~ file /home/aquota.user
/home/aquota.user: data
~ file /home/aquota.group
/home/aquota.group: dat~ quotaon -p /home/
group quota on /home (/dev/sda6) is off
user quota on /home (/dev/sda6) is off
~ quotaon /home/
~ quotaon -p /home/
group quota on /home (/dev/sda6) is on
user quota on /home (/dev/sda6) is on
# 设置磁盘配额的数据库,是根据文件的所有者来进行判定
# 显示用户的磁盘配额
~ edquota zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks soft hard inodes soft hard
/dev/sda6 48 80000 10000 12 150 200~$ quota zzw
Disk quotas for user zzw (uid 1000):
Filesystem blocks quota limit grace files quota limit grace
/dev/sda6 48 80000 10000 12 150 200# 以报告的方式显示磁盘配额
~ repquota /home/
*** Report for user quotas on device /dev/sda6
Block grace time: 7days; Inode grace time: 7days
Block limits File limits
User used soft hard grace used soft hard grace
----------------------------------------------------------------------
root -- 20 0 0 2 0 0
zzw -- 48 80000 10000 13 150 200
wang -- 28 0 0 7 0 0
范例:控制用户组使用的空间大小(独立分区)磁盘配额
# 设置用户组的磁盘配额
~ edquota -g g1
Disk quotas for group g1 (gid 1005):
Filesystem blocks soft hard inodes soft hard
/dev/sda6 0 800000 1000000 0 0 0
~ setquota -g g1 800000 1000000 0 0 /dev/sda6# 设置磁盘配额的数据库,是根据文件的用户组来进行判定
~ quota -g g1
Disk quotas for group g1 (gid 1005):
Filesystem blocks quota limit grace files quota limit grace/dev/sda6 4 800000 1000000 2 0 0