参考:深度学习:GPT1、GPT2、GPT-3_HanZee的博客-CSDN博客
Zero-shot Learning / One-shot Learning-CSDN博客
Zero-shot(零次学习)简介-CSDN博客
GPT-2 模型由多层单向transformer的解码器部分构成,本质上是自回归模型,自回归的意思是指,每次产生新单词后,将新单词加到原输入句后面,作为新的输入句
gpt2与gpt1区别:
1.模型架构上变得更大,参数量达到了1.5B,数据集改为百万级别的WebText,,Bert当时最大的参数数量为0.34B,但是作者发现模型架构与数据集都扩大的情况下,与同时期的Bert的优势并不大。
2.gpt2 pre-training方法与gpt1一致,但在做下游任务时,不再进行微调,只进行简单的Zero-Shot,就能与同时期微调后的模型性能相差不大。
Zero-Shot(零次学习),成品模型对于训练集中没有出现过的类别,能自动创造出相应的映射: XX -> YY。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
Zero-Shot表现在GPT2中就是在训练样本中加入了下游任务的相关描述(从而在测试集上给出一个没在pre-training时训练的任务例如句子分类,gpt2也能执行?):


3.在模型结构上,调整了每个block Layer Normalization的位置

gpt3与gpt2区别:
GPT3 可以理解为 GPT2 的升级版,使用了 45TB 的训练数据,拥有 175B 的参数量
GPT3 主要提出了两个概念:
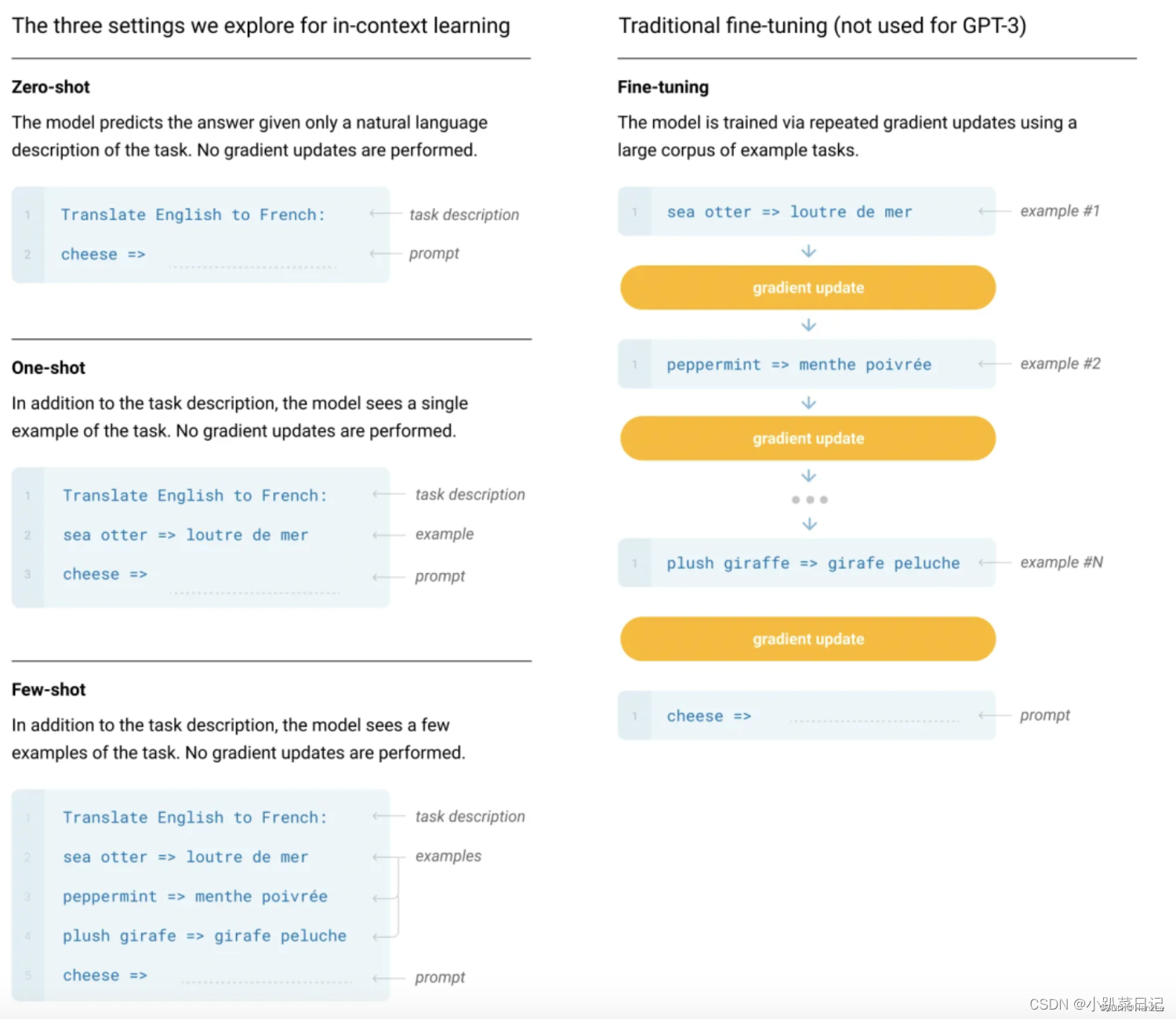
情景(in-context)学习:就是对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入:请把以下英文翻译为中文:Today is a good day。这样模型就能够基于这一场景做出回答了,其实跟 GPT2 中不同任务的 token 有异曲同工之妙,只是表达更加完善、更加丰富了。
Zero-shot, one-shot and few-shot:GPT3 打出的口号就是“告别微调的 GPT3”,它可以通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务。下面是对比微调模型和 GPT3 三种不同的样本推理形式图。