Kafka介绍
ChatGPT对于Apache Kafka的介绍:
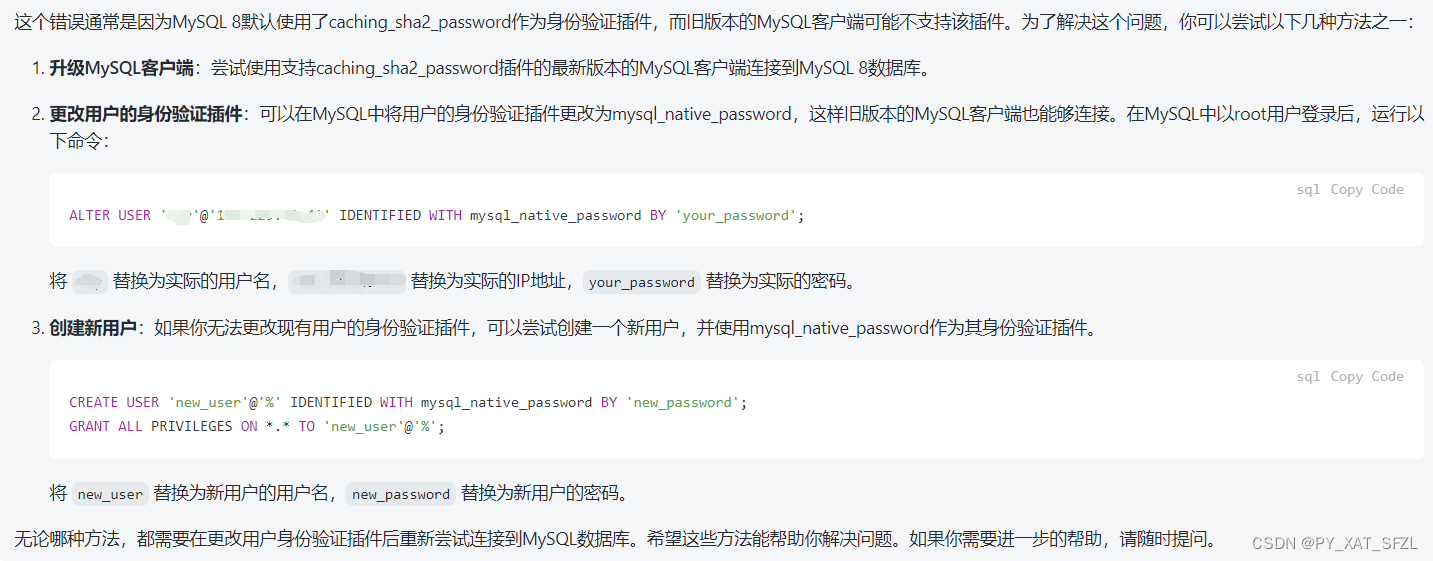
Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发并于2011年开源。它主要用于解决大规模数据的实时流式处理和数据管道问题。
Kafka是一个分布式的发布-订阅消息系统,可以快速地处理高吞吐量的数据流,并将数据实时地分发到多个消费者中。Kafka消息系统由多个broker(服务器)组成,这些broker可以在多个数据中心之间分布式部署,以提供高可用性和容错性。
Kafka的基本架构由生产者、消费者和主题(topic)组成。生产者可以将数据发布到指定的主题,而消费者可以订阅这些主题并消费其中的数据。同时,Kafka还支持数据流的处理和转换,可以在管道中通过Kafka Streams API进行流式计算,例如过滤、转换、聚合等。
Kafka使用高效的数据存储和管理技术,能够轻松地处理TB级别的数据量。其优点包括高吞吐量、低延迟、可扩展性、持久性和容错性等。
Kafka在企业级应用中被广泛应用,包括实时流处理、日志聚合、监控和数据分析等方面。同时,Kafka还可以与其他大数据工具集成,如Hadoop、Spark和Storm等,构建一个完整的数据处理生态系统。
MQ的作用
MQ:MessageQueue,消息队列。 队列,是一种FIFO 先进先出的数据结构。消息则是跨进程传递的数据。一个典型的MQ系统,会将消息消息由生产者发送到MQ进行排队,然后根据一定的顺序交由消息的消费者进行处理。
主要作用:
-
异步
异步能提高系统的响应速度、吞吐量。
-
解耦
1、服务之间进行解耦,才可以减少服务之间的影响。提高系统整体的稳定性以及可扩展性。
2、另外,解耦后可以实现数据分发。生产者发送一个消息后,可以由一个或者多个消费者进行消费,并且消费者的增加或者减少对生产者没有影响。
-
削峰
作用:以稳定的系统资源应对突发的流量冲击。
为什么要用Kafka
典型日志聚合的应用场景:

业务场景决定了产品的特点。
1、数据吞吐量很大: 需要能够快速收集各个渠道的海量日志
2、集群容错性高:允许集群中少量节点崩溃
3、功能不需要太复杂:Kafka的设计目标是高吞吐、低延迟和可扩展,主要关注消息传递而不是消息处理。所以,Kafka并没有支持死信队列、顺序消息等高级功能。
4、允许少量数据丢失:Kafka本身也在不断优化数据安全问题,目前基本上可以认为Kafka可以做到不会丢数据。
Kafka快速上手
实验环境
准备三台CentOS7的虚拟机,预备搭建三台机器的集群。分别配置机器名 worker1,worker2,worker3。
vi /etc/hosts192.168.146.128 worker1
192.168.146.129 worker2
192.168.146.130 worker3关闭防火墙(实验环境建议关闭)
firewall-cmd --state 查看防火墙状态
systemctl stop firewalld.service 关闭防火墙补充:虚拟机centos7遇到问题,bash: jps: 未找到命令... 的解决方案
yum list *openjdk-devel*
#安装适合自己的版本
yum install java-1.8.0-openjdk-devel.x86_64
#安装过程有几个同意步骤,输入y,安装完成测试jps ok!
下载kafka地址:Apache Kafka ,选择kafka_2.13-3.4.0.tgz进行下载。
下载Zookeeper地址 Apache ZooKeeper ,这里选择比较新的3.6.1版本。
下载完成后,将这两个工具包上传到服务器上,解压后,分别放到/app/kafka和/app/zk目录下。并将部署目录下的bin目录路径配置到path环境变量中。
环境变量/etc/profile最终配置:
export ZK_HOME=/app/zk/apache-zookeeper-3.6.4-bin
export KAFKA_HOME=/app/kafka/kafka_2.13-3.4.0
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$KAFKA_HOME/bin:$ZK_HOME/bin:$JAVA_HOME/bin:$PATH
export CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar单机服务体验
1、启动Kafka之前需要先启动Zookeeper。
#解压命令
tar zxvf apache-zookeeper-3.6.4-bin.tar.gz
tar zxvf kafka_2.13-3.4.0.tgz#这里用Kafka自带的Zookeeper启动脚本
cd kafka_2.13-3.4.0/
nohup bin/zookeeper-server-start.sh config/zookeeper.properties &通过jps指令看到一个QuorumPeerMain进程,确定服务启动成功。zk默认启动在2181端口
启动遇到问题可以查看nohup.out日志文件,注意脚本的执行权限
2、启动Kafka
nohup bin/kafka-server-start.sh config/server.properties &启动完成后,使用jps指令,看到一个kafka进程,确定服务启动成功。服务默认9092端口
3、简单收发消息
Kafka的基础工作机制:消息发送者将消息发送到kafka上指定的topic,消息消费者从指定的topic上消费消息。
简单收到命令:
#创建Topic
bin/kafka-topics.sh --create --topic test --bootstrap-server localhost:9092
#查看Topic
bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
#启动一个消息发送者端,往一个名为test的Topic发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
#启动一个消息接收者端,接收名为test的Topic消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test生产者端示例:

消费者端示例:

注意:消费者启动命令执行后有几秒钟延迟(启动中接收不到消息),默认处理启动成功后接收到的消息
4、其他消费模式
指定消费进度
#通过--from-beginning消费之前发的消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test
#指定从哪一条消息开始消费,offset表示索引/偏移量,索引4也就是第五条消息开始,0号partition
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --partition 0 --offset 4 --topic test分组消费
kafka中的同一条消息,只能被同一个消费者组下的某一个消费者消费。而不属于同一个消费者组的其他消费者,也可以消费到这一条消息。通过--consumer-property group.id=testGroup指定消费者组
#两个消费者实例属于同一个消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test
#这个消费者实例属于不同的消费者组
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup2 --topic test查看消费者组的偏移量
#查看消费者组的情况,包括消费进度。
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup···命令输出结果示例
Consumer group 'testGroup' has no active members. #没有活跃消费者GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
testGroup test 0 20 20 0 ... ... ...
···描述:
PARTITION 分区
CURRENT-OFFSET 当前消费进度
LOG-END-OFFSET 日志种最大消息进度
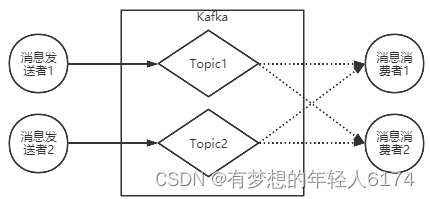
LAG 未消费消息数虽然业务上是通过Topic来分发消息的,但是实际上,消息是保存在Partition这样一个数据结构上
理解Kakfa的消息传递机制
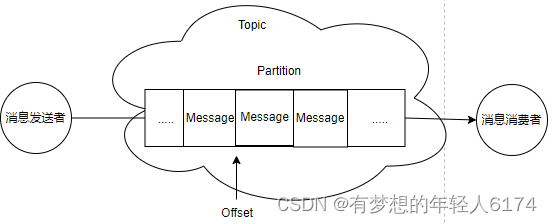
Kafka的消息发送者和消息消费者通过Topic这样一个逻辑概念来进行业务沟通。但是实际上,所有的消息是存在服务端的Partition这样一个数据结构当中的。
-
客户端Client: 包括消息生产者和消息消费者。
-
消费者组:每个消费者可以指定一个所属的消费者组,相同消费者组的消费者共同构成一个逻辑消费者组。每一个消息会被多个感兴趣的消费者组消费,但是在每一个消费者组内部,一个消息只会被消费一次。
-
服务端Broker:一个Kafka服务器就是一个Broker。
-
话题Topic:这是一个逻辑概念,一个Topic被认为是业务含义相同的一组消息。客户端都通过绑定Topic来生产或者消费自己感兴趣的话题。
-
分区Partition:Topic只是一个逻辑概念,而Partition就是实际存储消息的组件。每个Partiton就是一个queue队列结构。所有消息以FIFO先进先出的顺序保存在这些Partition分区中。
Kafka集群服务
为什么要用集群?
单机服务下,Kafka已经具备了非常高的性能。TPS能够达到百万级别。但是,在实际工作中使用时,单机搭建的Kafka会有很大的局限性。
一方面:消息太多,需要分开保存。Kafka是面向海量消息设计的,一个Topic下的消息会非常多,单机服务很难存得下来。这些消息就需要分成不同的Partition,分布到多个不同的Broker上。这样每个Broker就只需要保存一部分数据。这些分区的个数就称为分区数。
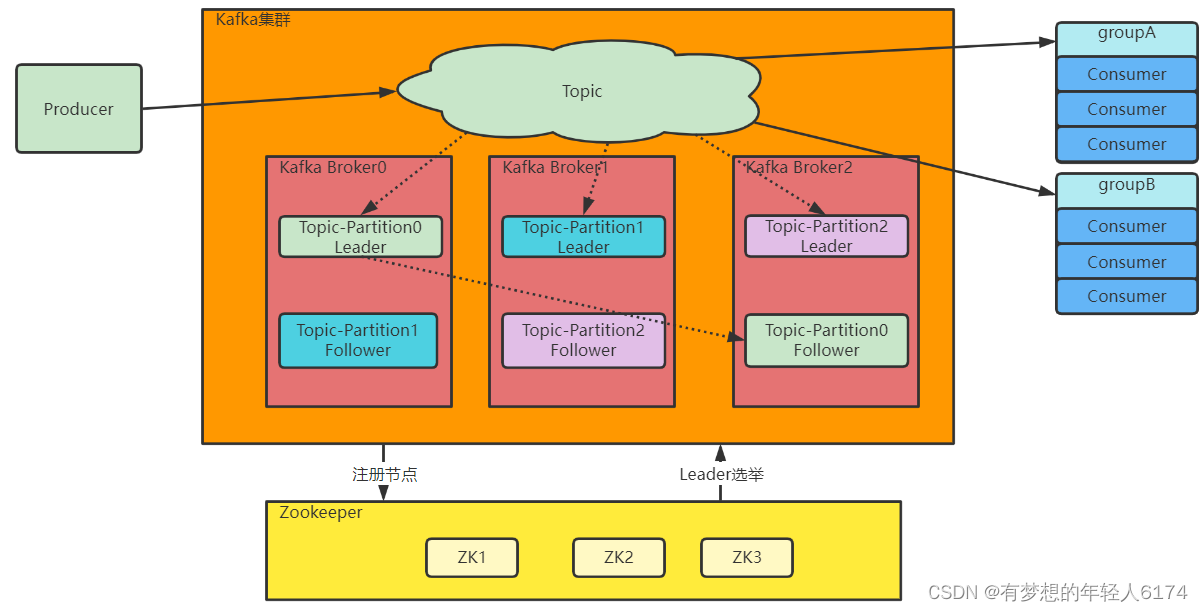
另一方面:服务不稳定,数据容易丢失。单机服务下,如果服务崩溃,数据就丢失了。为了保证数据安全,就需要给每个Partition配置一个或多个备份,保证数据不丢失。Kafka的集群模式下,每个Partition都有一个或多个备份。Kafka会通过一个统一的Zookeeper集群作为选举中心,给每个Partition选举出一个主节点Leader,其他节点就是从节点Follower。主节点负责响应客户端的具体业务请求,并保存消息。而从节点则负责同步主节点的数据。当主节点发生故障时,Kafka会选举出一个从节点成为新的主节点。
最后:Kafka集群中的这些Broker信息,包括Partition的选举信息,都会保存在额外部署的Zookeeper集群当中,这样,kafka集群就不会因为某一些Broker服务崩溃而中断。
Kafka集群架构:
1、部署Zookeeper集群
Zookeeper是一种多数同意的选举机制,允许集群中少半数节点出现故障。因此,在搭建集群时,通常采用奇数节点,这样可以最大化集群的高可用特性。
先将下载下来的Zookeeper解压到/app/zk目录。
然后进入conf目录,修改配置文件。在conf目录中,提供了一个zoo_sample.cfg示例文件。只需要将这个文件复制一份zoo.cfg,并修改其中的关键配置:
#Zookeeper的本地数据目录,默认是/tmp/zookeeper。这是Linux的临时目录,随时会被删掉。
dataDir=/app/zk/data
#Zookeeper的服务端口
clientPort=2181
#集群节点配置
server.1=192.168.146.128:2888:3888
server.2=192.168.146.129:2888:3888
server.3=192.168.146.130:2888:3888clientPort 2181是对客户端开放的服务端口。
集群配置部分, server.x这个x就是节点在集群中的myid。后面的2888端口是集群内部数据传输使用的端口。3888是集群内部进行选举使用的端口。
zookeeper启动时data目录会自动创建,但是需要手动在data目录下面添加一个myid文件
#启动服务
bin/zkServer.sh --config conf start
#查看服务状态
bin/zkServer.sh status2、部署Kafka集群
kafka服务并不需要进行选举,因此也没有奇数台服务的建议。
首先将Kafka解压到/app/kafka目录下,然后进入config目录,修改server.properties。重点关注的配置:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#数据文件地址。同样默认是给的/tmp目录。
log.dirs=/app/kafka/logs
#默认的每个Topic的分区数
num.partitions=1
#zookeeper的服务地址
zookeeper.connect=worker1:2181,worker2:2181,worker3:2181多个Kafka服务注册到同一个zookeeper集群上的节点,会自动组成集群。
server.properties文件中比较重要的核心配置:
| Property | Default | Description |
|---|---|---|
| broker.id | 0 | broker的“名字”,你可以选择任意你喜欢的数字作为id,只要id是唯每个broker都可以用一个唯一的非负整数id进行标识;这个id可以作为一的即可。 |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯一的,可以是多个,路径之间只需要使用逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进行。 |
| listeners | PLAINTEXT://127.0.0.1:9092 | server接受客户端连接的端口,ip配置kafka本机ip即可 |
| zookeeper.connect | localhost:2181 | zookeeper连接地址。hostname:port。如果是Zookeeper集群,用逗号连接。 |
| log.retention.hours | 168 | 每个日志文件删除之前保存的时间。 |
| num.partitions | 1 | 创建topic的默认分区数 |
| default.replication.factor | 1 | 自动创建topic的默认副本数量 |
| min.insync.replicas | 1 | 当producer设置acks为-1时,min.insync.replicas指定replicas的最小数目(必须确认每一个repica的写数据都是成功的),如果这个数目没有达到,producer发送消息会产生异常 |
| delete.topic.enable | false | 是否允许删除主题 |
启动服务:
bin/kafka-server-start.sh -daemon config/server.properties理解服务端的Topic、Partition和Broker
# 创建一个分布式的Topic
bin/kafka-topics.sh --bootstrap-server worker1:9092 --create --replication-factor 2 --partitions 4 --topic disTopic
# 列出所有的Topic
bin/kafka-topics.sh --bootstrap-server worker1:9092 --list
# 查看列表情况
bin/kafka-topics.sh --bootstrap-server worker1:9092 --describe --topic disTopic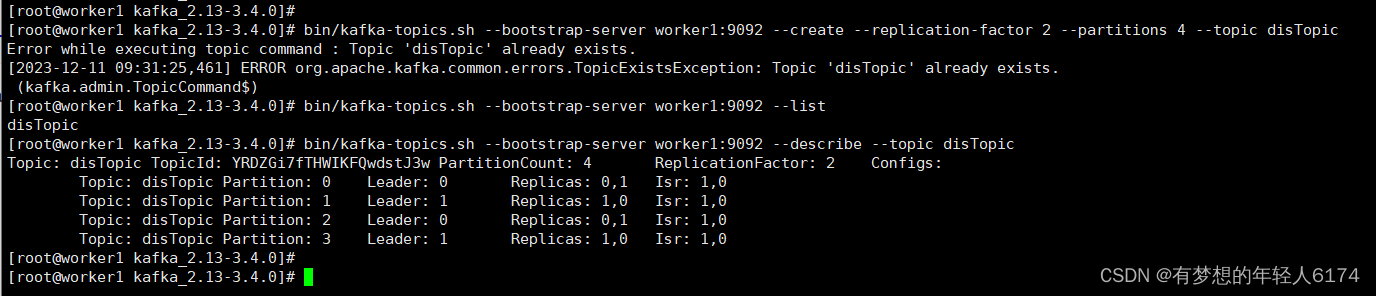
这里硬件资源有限,只启动了两台(上面截图)
1、--create创建集群,可以指定一些补充的参数。大部分的参数都可以在配置文件中指定默认值。
-
partitons参数表示分区数,这个Topic下的消息会分别存入这些不同的分区中。
-
replication-factor表示每个分区有几个备份。
2、--describe查看Topic信息。
-
partiton参数列出了四个partition,后面带有分区编号,用来标识这些分区。
-
Leader表示这一组partiton中的Leader节点是哪一个。这个Leader节点就是负责响应客户端请求的主节点。从这里可以看到,Kafka中的每一个Partition都会分配Leader,也就是说每个Partition都有不同的节点来负责响应客户端的请求。这样就可以将客户端的请求做到尽量的分散。
-
Replicas参数表示这个partition的多个备份是分配在哪些Broker上的。也称为AR。这里的0,1就对应配置集群时指定的broker.id。但是,Replicas列出的只是一个逻辑上的分配情况,并不关心数据实际是不是按照这个分配。甚至有些节点服务挂了之后,Replicas中也依然会列出节点的ID。
-
ISR参数表示partition的实际分配情况。他是AR的一个子集,只列出那些当前还存活,能够正常同步数据的那些Broker节点。
之前在配置Kafka集群时,指定了一个log.dirs属性,指向了一个服务器上的日志目录。进入这个目录,就能看到每个Broker的实际数据承载情况。
Kafka当中,Topic是一个数据集合的逻辑单元。同一个Topic下的数据,实际上是存储在Partition分区中的,Partition就是数据存储的物理单元。而Broker是Partition的物理载体,这些Partition分区会尽量均匀的分配到不同的Broker机器上。offset,就是每个消息在partition上的偏移量。
Kafka为何要这样来设计Topic、Partition和Broker的关系呢?
1、Kafka设计需要支持海量的数据,而这样庞大的数据量,一个Broker是存不下的。那就拆分成多个Partition,每个Broker只存一部分数据。这样极大的扩展了集群的吞吐量。
2、每个Partition保留了一部分的消息副本,如果放到一个Broker上,就容易出现单点故障。所以就给每个Partition设计Follower节点,进行数据备份,从而保证数据安全。另外,多备份的Partition设计也提高了读取消息时的并发度。
3、在同一个Topic的多个Partition中,会产生一个Partition作为Leader。这个Leader Partition会负责响应客户端的请求,并将数据往其他Partition分发。
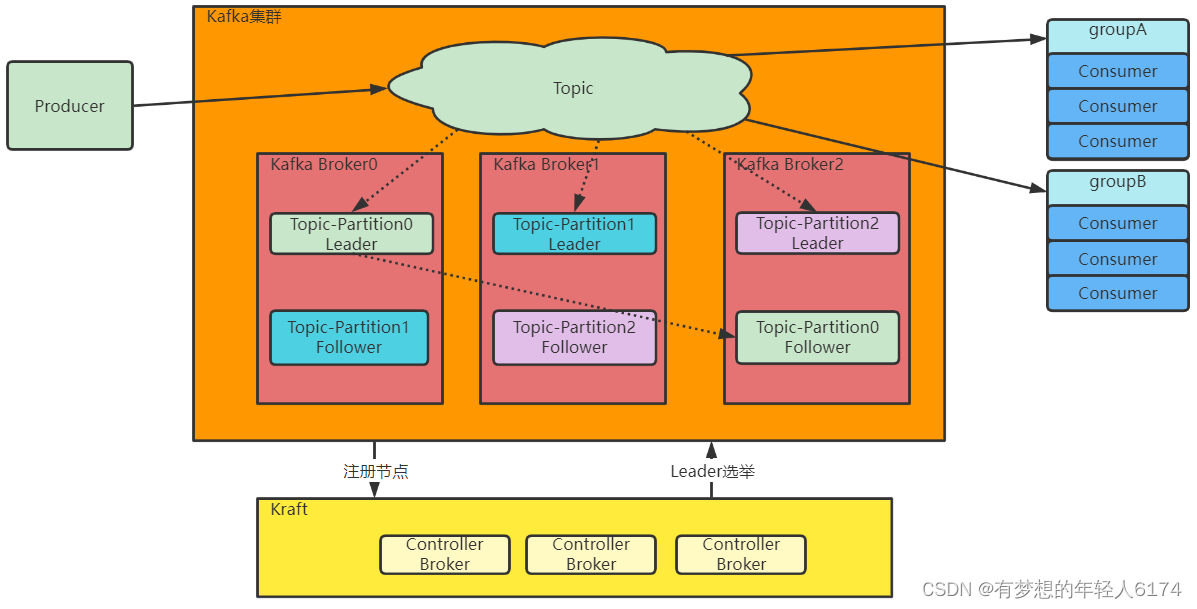
Kafka集群的整体结构

1、Topic是一个逻辑概念,Producer和Consumer通过Topic进行业务沟通。
2、Topic并不存储数据,Topic下的数据分为多组Partition,尽量平均的分散到各个Broker上。每组Partition包含Topic下一部分的消息。每组Partition包含一个Leader Partition以及若干个Follower Partition进行备份,每组Partition的个数称为备份因子 replica factor。
3、Producer将消息发送到对应的Partition上,然后Consumer通过Partition上的Offset偏移量,记录自己所属消费者组Group在当前Partition上消费消息的进度。
4、Producer发送给一个Topic的消息,会由Kafka推送给所有订阅了这个Topic的消费者组进行处理。但是在每个消费者组内部,只会有一个消费者实例处理这一条消息。
5、最后,Kafka的Broker通过Zookeeper组成集群。然后在这些Broker中,需要选举产生一个担任Controller角色的Broker。这个Controller的主要任务就是负责Topic的分配以及后续管理工作。在我们实验的集群中,这个Controller实际上是通过ZooKeeper产生的。
Kraft集群--了解
Kraft集群简介
Kraft是Kafka从2.8.0版本开始支持的一种新的集群架构方式。其目的主要是为了摆脱Kafka对Zookeeper的依赖。因为以往基于Zookeeper搭建的集群,增加了Kafka演进与运维的难度,逐渐开始成为Kakfa拥抱云原生的一种障碍。使用Kraft集群后,Kafka集群就不再需要依赖Zookeeper,将之前基于Zookeeper管理的集群数据,转为由Kafka集群自己管理。
虽然官方规划会在未来完全使用Kraft模式代替现有的Zookeeper模式,但是目前来看,Kraft集群还是没有Zookeeper集群稳定,所以现在大部分企业还是在使用Zookeeper集群。
2022年10月3日发布的3.3.1版本才开始将KRaft标注为准备用于生产。KIP-833: Mark KRaft as Production Ready。 这离大规模使用还有比较长的距离。
实际上,Kafka摆脱Zookeeper是一个很长的过程。在之前的版本迭代过程中,Kafka就已经在逐步减少Zookeeper中的数据。在Kafka的bin目录下的大量脚本,早期都是要指定zookeeper地址,后续长期版本更迭过程中,逐步改为通过--bootstrap-server参数指定Kafka服务地址。到目前版本,基本所有脚本都已经抛弃了--zookeeper参数了。
传统的Kafka集群,会将每个节点的状态信息统一保存在Zookeeper中,并通过Zookeeper动态选举产生一个Controller节点,通过Controller节点来管理Kafka集群,比如触发Partition的选举。而在Kraft集群中,会固定配置几台Broker节点来共同担任Controller的角色,各组Partition的Leader节点就会由这些Controller选举产生。原本保存在Zookeeper中的元数据也转而保存到Controller节点中。
Raft协议是目前进行去中心化集群管理的一种常见算法,类似于之前的Paxos协议,是一种基于多数同意,从而产生集群共识的分布式算法。Kraft则是Kafka基于Raft协议进行的定制算法。
新的Kraft集群相比传统基于Zookeeper的集群,有一些很明显的好处:
-
Kafka可以不依赖于外部框架独立运行。这样减少Zookeeper性能抖动对Kafka集群性能的影响,同时Kafka产品的版本迭代也更自由。
-
Controller不再由Zookeeper动态选举产生,而是由配置文件进行固定。这样比较适合配合一些高可用工具来保持集群的稳定性。
-
Zookeeper的产品特性决定了他不适合存储大量的数据,这对Kafka的集群规模(确切的说应该是Partition规模)是极大的限制。摆脱Zookeeper后,集群扩展时元数据的读写能力得到增强。
不过,由于分布式算法的复杂性。Kraft集群和同样基于Raft协议定制的RocketMQ的Dledger集群一样,都还不太稳定,在真实企业开发中,用得相对还是比较少。
配置Kraft集群
在Kafka的config目录下,提供了一个kraft的文件夹,在这里面就是Kraft协议的参考配置文件。在这个文件夹中有三个配置文件,broker.properties,controller.properties,server.properties,分别给出了Kraft中三种不同角色的示例配置。
-
broker.properties:数据节点
-
controller.properties:Controller控制节点
-
server.properties:即可以是数据节点,又可以是Controller控制节点。
这里同样列出几个比较关键的配置项,按照自己的环境定制。
#配置当前节点的角色。Controller相当于Zookeeper的功能,负责集群管理。Broker提供具体的消息转发服务。
process.roles=broker,controller
#配置当前节点的id。与普通集群一样,要求集群内每个节点的ID不能重复。
node.id=1
#配置集群的投票节点。其中@前面的是节点的id,后面是节点的地址和端口,这个端口跟客户端访问的端口是不一样的。通常将集群内的所有Controllor节点都配置进去。
controller.quorum.voters=1@worker1:9093,2@worker2:9093,3@worker3:9093
#Broker对客户端暴露的服务地址。基于PLAINTEXT协议。
advertised.listeners=PLAINTEXT://worker1:9092
#Controller服务协议的别名。默认就是CONTROLLER
controller.listener.names=CONTROLLER
#配置监听服务。不同的服务可以绑定不同的接口。这种配置方式在端口前面是省略了一个主机IP的,主机IP默认是使用的java.net.InetAddress.getCanonicalHostName()
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
#数据文件地址。默认配置在/tmp目录下。
log.dirs=/app/kafka/kraft-log
#topic默认的partition分区数。
num.partitions=2将配置文件分发,并修改每个服务器上的node.id属性和advertised.listeners属性。
由于Kafka的Kraft集群对数据格式有另外的要求,所以在启动Kraft集群前,还需要对日志目录进行格式化。
[root@worker1 kafka_2.13-3.4.0]# bin/kafka-storage.sh random-uuid
vRqZXTz0QT6FJKmeyEU7Yw
[root@worker1 kafka_2.13-3.4.0]# bin/kafka-storage.sh format -t vRqZXTz0QT6FJKmeyEU7Yw -c config/kraft/server.properties
Formatting /tmp/kraft-combined-logs with metadata.version 3.4-IV0.-t 表示集群ID,三个服务器上可以使用同一个集群ID。
接下来就可以指定配置文件,启动Kafka的服务了。 例如,在Worker1上,启动Broker和Controller服务。
bin/kafka-server-start.sh -daemon config/kraft/server.properties 等三个服务都启动完成后,就可以像普通集群一样去创建Topic,并维护Topic的信息了。