大家好,我是不才陈某~
什么是 Chat2DB
Chat2DB 是一款有开源免费的多数据库客户端工具,支持 Windows、MAC 本地安装,也支持服务器端部署,Web 网页访问。和传统的数据库客户端软件Navicat、DBeaver 相比 Chat2DB 集成了 AIGC 的能力,能够将自然语言转换为 SQL,也可以将 SQL 转换为自然语言,可以给出研发人员 SQL 的优化建议,极大地提升人员的效率,是 AI 时代数据库研发人员的利器。未来即使不懂SQL的运营业务也可以使用快速查询业务数据、生成报表能力。
下载安装
项目 Releases 地址:
https://github.com/alibaba/Chat2DB/releases
大家根据自己的电脑环境选择对应版本即可,博主这里使用的 MacOS X64(Intel芯片)版本。
安装配置
正常双击打开拖动到 Applications 进行安装,安装完成后配置 Chat2DB AI SQL 功能。找到设置,填写 Open AI 的密钥(登录 OpenAI 官网,右上角View API keys 创建即可)。
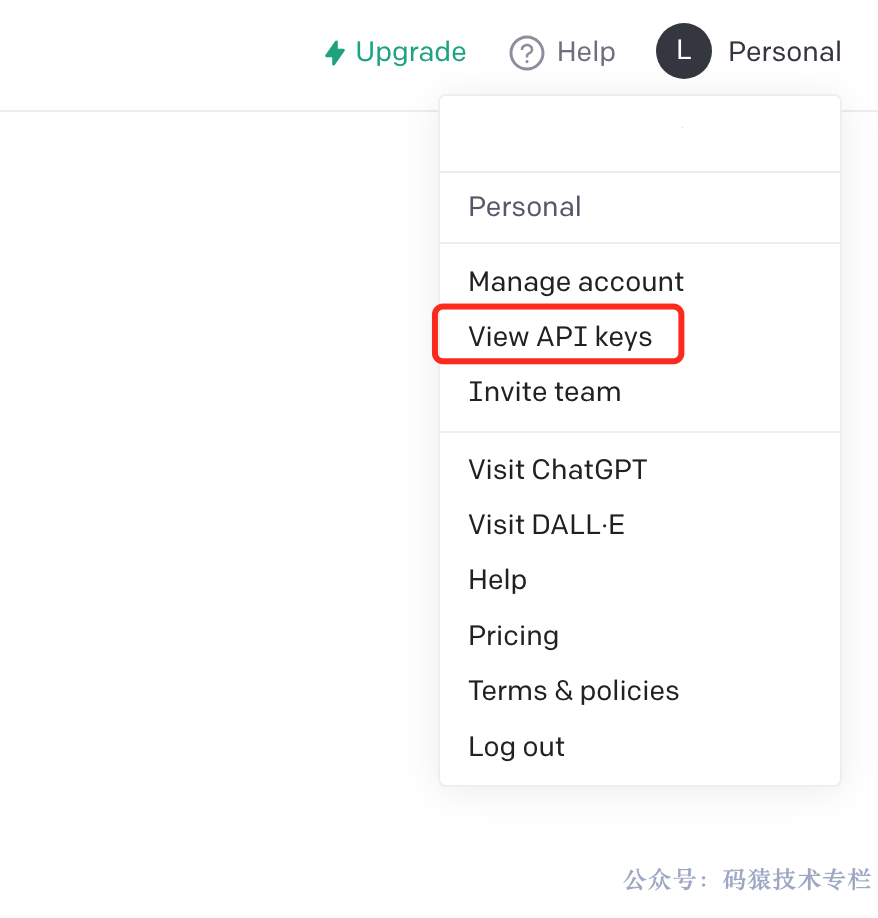
创建完成后,在设置中输入刚刚获取的 OpenAI 密钥。
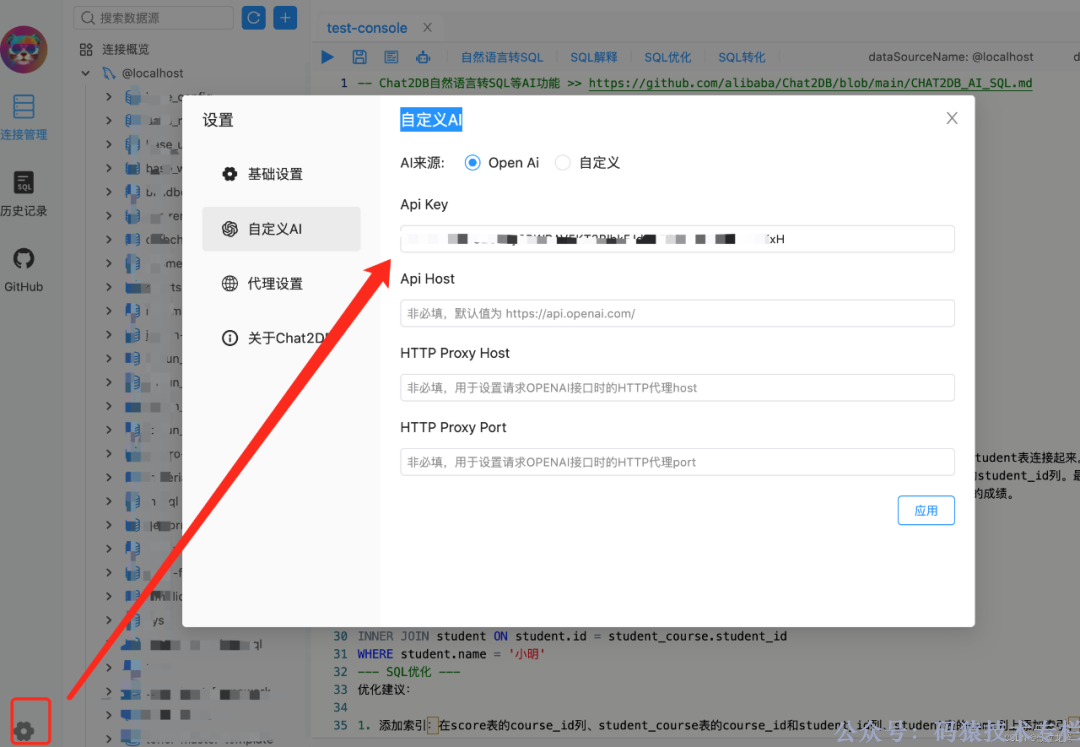
至此,我们已经完成了基础的配置,下面我们来感受一下 Chat2DB。
Chat2DB 初体验
配置数据源
这里以 MySQL 为例,点击加号(+)新建数据源。
填写相关链接信息,选择数据库,这里 test 为例:
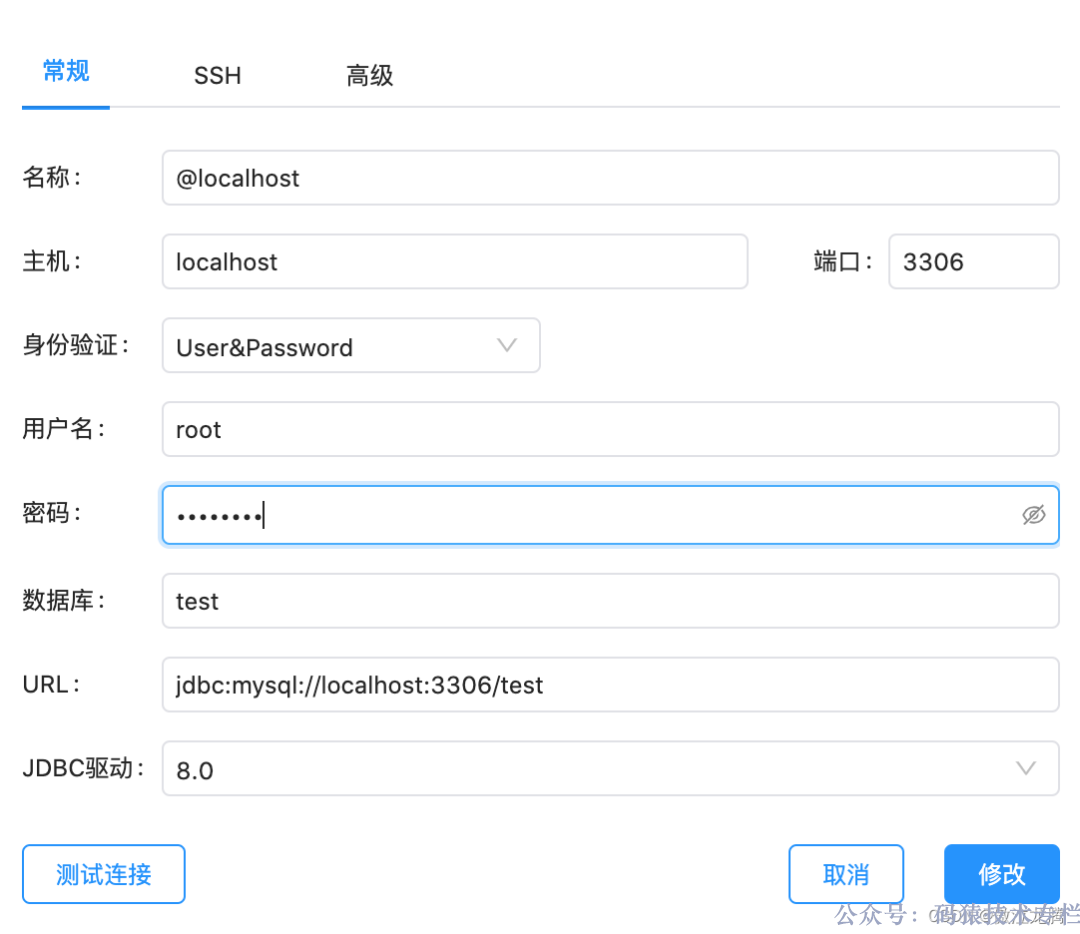
目前 MAC 版本选择了数据库 test,但是实际上依旧还是将整个 localhost 的所有数据库列出来了。这是个已知 Bug,博主也提交了 Issue,建议官方不选择数据库默认所有,指定了数据库就单独显示某个库。
准备测试数据
这里博主准备了一份测试数据表,分别是:科目表、学生成绩表、学生信息表、学生选修科目表,大家可以复制执行即可。
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (`id` int NOT NULL AUTO_INCREMENT COMMENT '科目ID',`name` varchar(50) NOT NULL COMMENT '科目名称',`teacher` varchar(50) NOT NULL COMMENT '授课教师',`credit` int NOT NULL COMMENT '科目学分',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='科目表';-- ----------------------------
-- Records of course
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES (1, '语文', '张老师', 100);
INSERT INTO `course` VALUES (2, '数学', '王老师', 100);
COMMIT;-- ----------------------------
-- Table structure for score
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (`id` int NOT NULL AUTO_INCREMENT COMMENT '成绩ID',`student_id` int NOT NULL COMMENT '学生ID',`course_id` int NOT NULL COMMENT '科目ID',`score` int NOT NULL COMMENT '成绩',PRIMARY KEY (`id`),KEY `student_id` (`student_id`),KEY `course_id` (`course_id`),CONSTRAINT `score_ibfk_1` FOREIGN KEY (`student_id`) REFERENCES `student` (`id`),CONSTRAINT `score_ibfk_2` FOREIGN KEY (`course_id`) REFERENCES `course` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生成绩表';-- ----------------------------
-- Records of score
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES (1, 1, 1, 90);
INSERT INTO `score` VALUES (2, 1, 2, 95);
INSERT INTO `score` VALUES (3, 2, 1, 100);
INSERT INTO `score` VALUES (4, 2, 2, 99);
COMMIT;-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (`id` int NOT NULL AUTO_INCREMENT COMMENT '学生ID',`name` varchar(50) NOT NULL COMMENT '学生姓名',`gender` varchar(10) NOT NULL COMMENT '学生性别',`birthday` date NOT NULL COMMENT '学生生日',`address` varchar(100) NOT NULL COMMENT '学生住址',`phone` varchar(20) NOT NULL COMMENT '学生联系方式',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生信息表';-- ----------------------------
-- Records of student
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES (1, '小明', '男', '2023-06-16', '广州', '13724889158');
INSERT INTO `student` VALUES (2, '小羊', '女', '2023-06-16', '广州', '13800126000');
COMMIT;-- ----------------------------
-- Table structure for student_course
-- ----------------------------
DROP TABLE IF EXISTS `student_course`;
CREATE TABLE `student_course` (`id` int NOT NULL AUTO_INCREMENT COMMENT '关系ID',`student_id` int NOT NULL COMMENT '学生ID',`course_id` int NOT NULL COMMENT '科目ID',PRIMARY KEY (`id`),KEY `student_id` (`student_id`),KEY `course_id` (`course_id`),CONSTRAINT `student_course_ibfk_1` FOREIGN KEY (`student_id`) REFERENCES `student` (`id`),CONSTRAINT `student_course_ibfk_2` FOREIGN KEY (`course_id`) REFERENCES `course` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='学生选修科目表';-- ----------------------------
-- Records of student_course
-- ----------------------------
BEGIN;
INSERT INTO `student_course` VALUES (1, 1, 1);
INSERT INTO `student_course` VALUES (2, 1, 2);
INSERT INTO `student_course` VALUES (3, 2, 1);
INSERT INTO `student_course` VALUES (4, 2, 2);
COMMIT;SET FOREIGN_KEY_CHECKS = 1;认识几个功能菜单
当你选择好对应的数据库表后,你会发现有这么 4 个菜单:

自然语言转 SQL:简单来说就是 使用中文描述,软件自动帮我们生成 SQL;
SQL 解释:SQL 语句转中文解释(有的时候我们会遇到非常复杂的 SQL,有的甚至成百上千行的SQL,要读懂这段 SQL 语句可能需要几个小时甚至几天时间。通过 Chat2DB就可以快速了解这段 SQL 的含义)
有的时候我们写了一段 SQL 性能不好,Chat2DB 也可以帮我们优化 SQL,提升查询性能;关注公众号:码猿技术专栏,回复关键词:1111 获取阿里内部Java性能调优手册!
不同数据库 SQL 语法有略微的差异,也可以通过 Chat2DB 让它帮我们去转换这个 SQL 的语法(比如 MySQL 转 SQLServer 语句)
开始测试
自然语言转 SQL
终端输入查询学生小明的各科目成绩,包括科目名称、教师名字段,点击自然语言转 SQL。

在弹出的选择表中选择本次查询所涉及到的几个表:course、score、student。
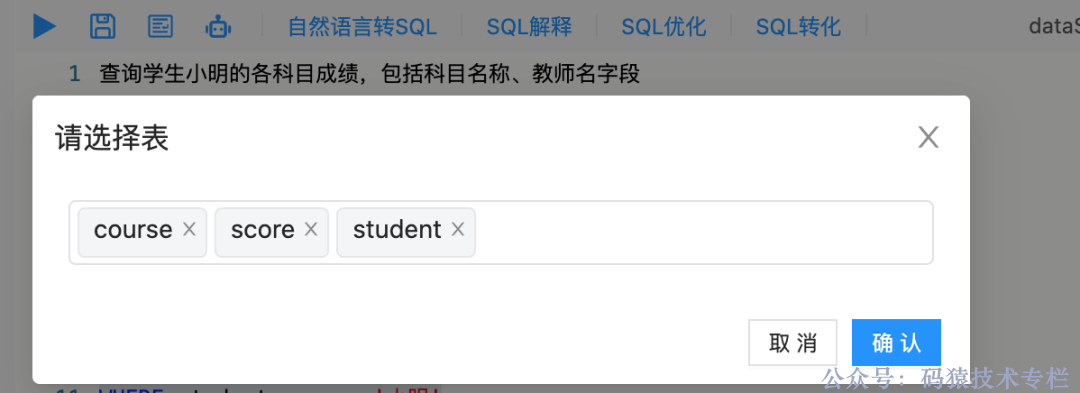
最终生成如下:
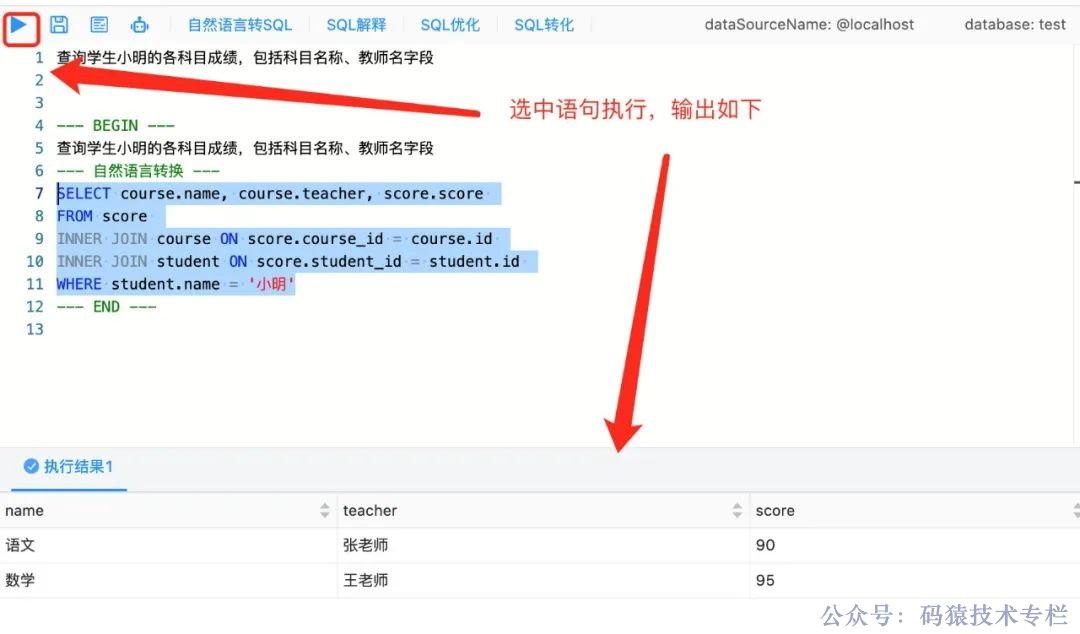
SQL 解释
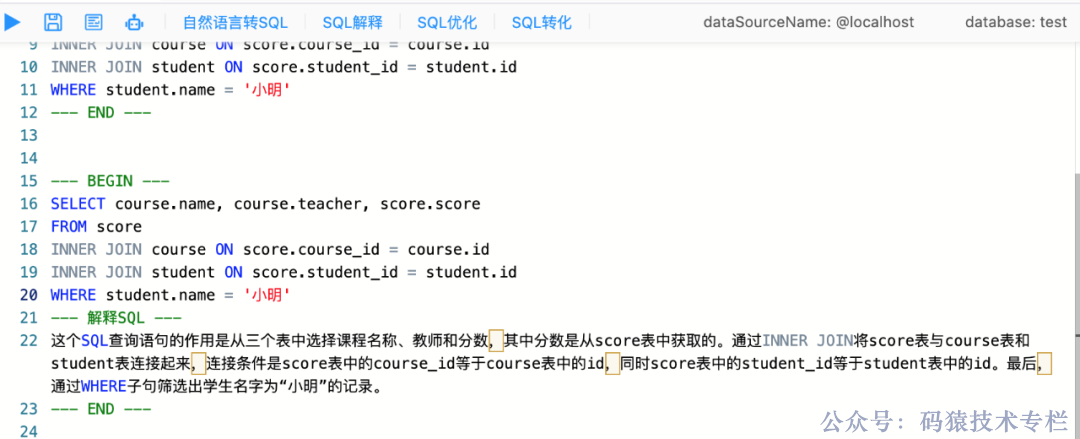
那么,我们使用这段生成的 SQL 语句反过来看看 Chat2DB 会帮我们解释成什么。选中生成的 SQL 点击 SQL 解释,输出如下:
--- BEGIN ---
SELECT course.name, course.teacher, score.score
FROM score
INNER JOIN course ON score.course_id = course.id
INNER JOIN student ON score.student_id = student.id
WHERE student.name = '小明'
--- 解释SQL ---
这个SQL查询语句的作用是从三个表中选择课程名称、教师和分数,其中分数是从score表中获取的。通过INNER JOIN将score表与course表和student表连接起来,连接条件是score表中的course_id等于course表中的id,同时score表中的student_id等于student表中的id。最后,通过WHERE子句筛选出学生名字为“小明”的记录。
--- END ---SQL 优化
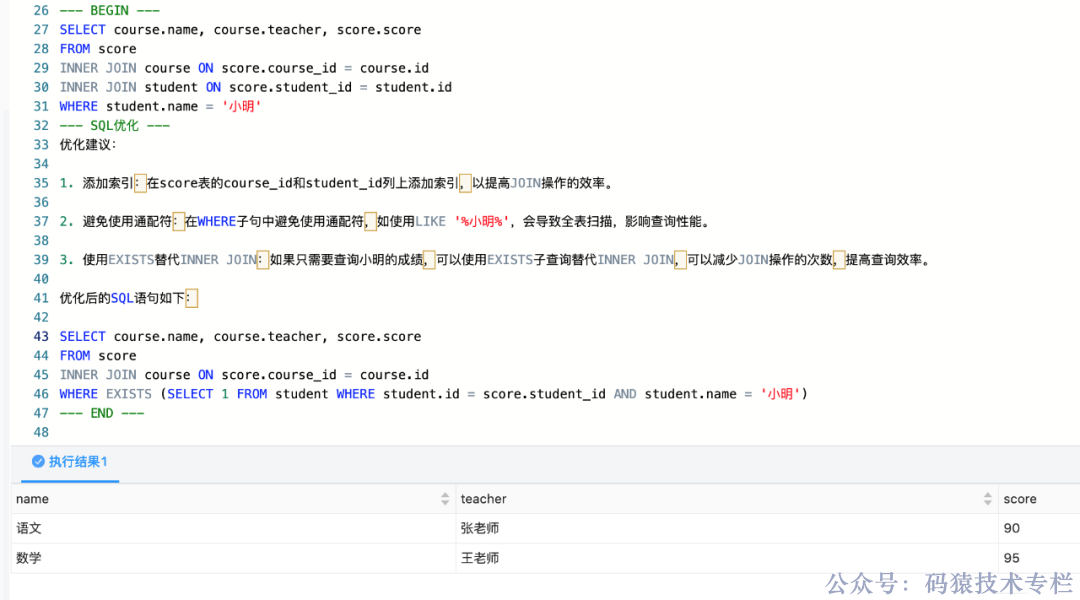
依旧使用这段生成的 SQL 看看 Chat2DB 会给我们一些什么优化建议:
--- BEGIN ---
SELECT course.name, course.teacher, score.score
FROM score
INNER JOIN course ON score.course_id = course.id
INNER JOIN student ON score.student_id = student.id
WHERE student.name = '小明'
--- SQL优化 ---
优化建议:1. 添加索引:在score表的course_id和student_id列上添加索引,以提高JOIN操作的效率。2. 避免使用通配符:在WHERE子句中避免使用通配符,如使用LIKE '%小明%',会导致全表扫描,影响查询性能。3. 使用EXISTS替代INNER JOIN:如果只需要查询小明的成绩,可以使用EXISTS子查询替代INNER JOIN,可以减少JOIN操作的次数,提高查询效率。优化后的SQL语句如下:SELECT course.name, course.teacher, score.score
FROM score
INNER JOIN course ON score.course_id = course.id
WHERE EXISTS (SELECT 1 FROM student WHERE student.id = score.student_id AND student.name = '小明')
--- END ---使用总结
通过上面的简单实用,相信大家已经知道 Chat2DB 的使用方法。其次,通过一些简单的命令,它也能帮我们生成我们想要的 SQL 语句。博主测试过一些复杂的业务 SQL 可能暂时还无法给到很正确提示,在 SQL 优化方面也给出了一定的建议,博主感觉这些建议都是可以供参考的,当然实际的情况还是需要根据我们的业务场景来决定。
后续功能
目前该开源项目还会提供支持环境隔离、支持团队协作,支持创建、修改、删除表,支持非关系型数据库的迭代版本,后续有新的功能版本,博主再来和大家分享,一下是项目的未来规划:

来源:blog.csdn.net/lhmyy521125/article/details/131247494
最后说一句(别白嫖,求关注)
陈某每一篇文章都是精心输出,如果这篇文章对你有所帮助,或者有所启发的话,帮忙点赞、在看、转发、收藏,你的支持就是我坚持下去的最大动力!
点击阅读:《Spring Cloud 进阶》
点击阅读:《Spring Boot 进阶》
点击阅读:《Mybatis 进阶》
关注公众号:【码猿技术专栏】,公众号内有超赞的粉丝福利,回复:加群,可以加入技术讨论群,和大家一起讨论技术,吹牛逼!