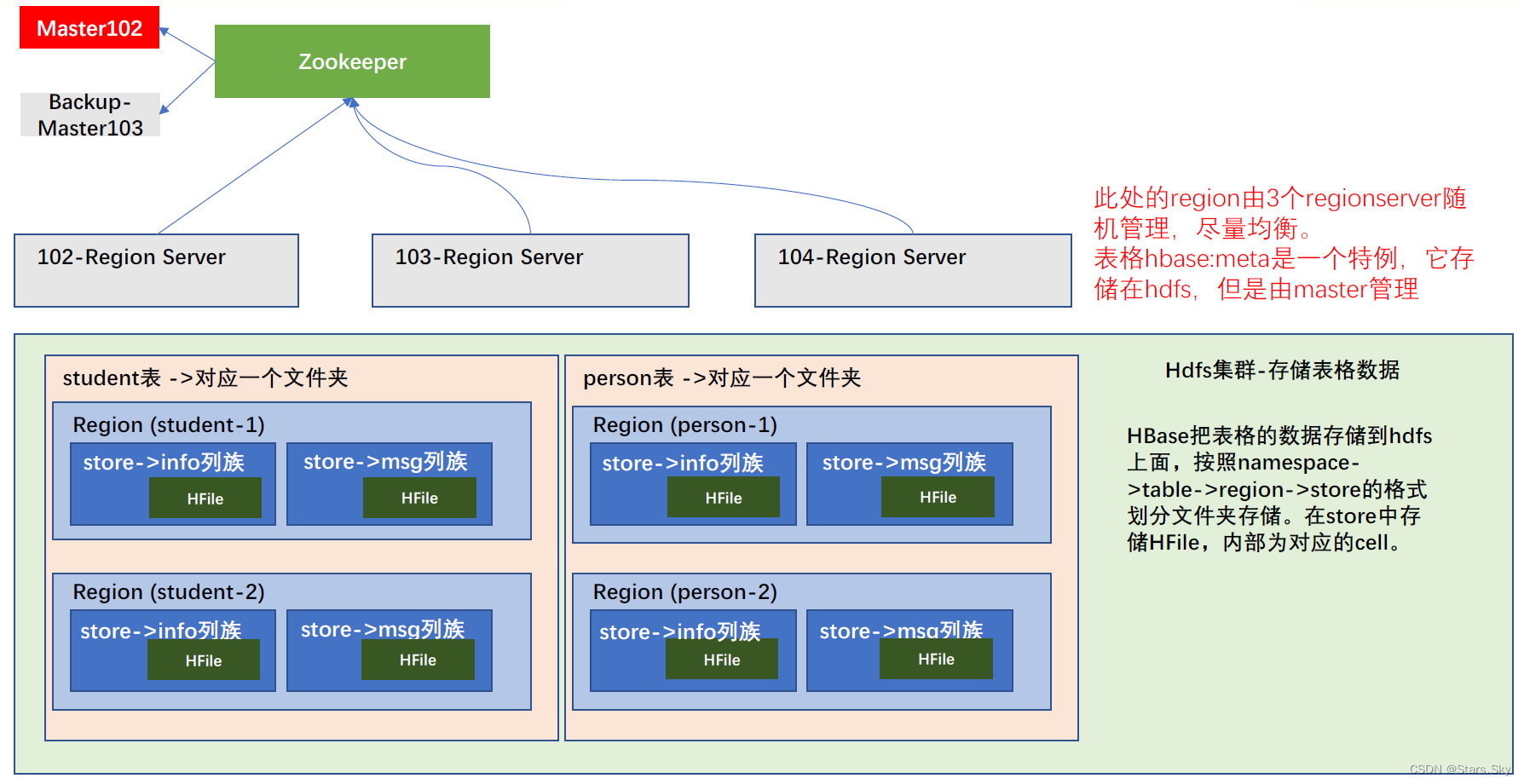
系列文章目录
深度探索Linux操作系统 —— 编译过程分析
深度探索Linux操作系统 —— 构建工具链
深度探索Linux操作系统 —— 构建内核
深度探索Linux操作系统 —— 构建initramfs
深度探索Linux操作系统 —— 从内核空间到用户空间
深度探索Linux操作系统 —— 构建根文件系统
深度探索Linux操作系统 —— 构建桌面环境
深度探索Linux操作系统 —— Linux图形原理探讨
文章目录
- 系列文章目录
- 前言
- 一、渲染和显示
- 1、渲染
- 2、显示
- 二、显存
- 1、动态显存技术
- 2、Buffer Object
- 三、2D渲染
- 1、创建前缓冲
- 2、GPU渲染
- 3、CPU渲染
- (1)映射 BO 到用户空间
- (2)使用 CPU 在映射到用户空间的 BO 上进行绘制
- 四、3D渲染
- 1、创建帧缓冲
- 2、渲染Pipleline
- 3、交换前缓冲和后缓冲
- (1)谁来负责交换
- (2)交换的时机
- (3)交换的方法
- 五、Wayland
前言
本质上,谈及图形原理必会涉及渲染和显示两部分。但是显示过程比较简单和直接,而渲染过程要复杂得多,更重要的是,渲染牵扯到操作系统内部的组件更多,因此,本章我们主要讨论渲染过程。我们不想只浮于理论,结合具体的 GPU 进行讨论更有助于深度理解计算机的图形原理。相比于 NV 及 ATI 的 GPU ,我们选择相对更开放一些的 Intel 的 GPU 进行讨论。Intel 的 GPU 也在不断的演进,本书写作时主要针对的是用在 Sandy Bridge 和 Ivy Bridge 架构上的 Intel HD Graphics 。
显存是图形渲染的基础,也是理解图形原理的基础,因此,本章我们从讨论显存开始。或许读者会说,显存有什么好讨论的,不就是一块存储区吗?早已是陈词滥调。但是事实并非如此,通过显存的讨论,我们会注意到 CPU 和 GPU 融合的脚步,会看到它们是如何的和谐共享物理内存的。或许,已经有 GPU 和 CPU 完美地进行统一寻址了。
然后,我们分别讨论 2D 和 3D 的渲染过程。在其间,我们将看到到底何谓硬件加速,我们也会从更深的层次去展示 3D 渲染过程中所谓的 Pipeline 。以往,很多教材都会为了辅助 OpenGL 的应用开发,多少从理论上谈及一点 Pipeline ,而在这一章中,我们从操作系统角度和 Pipeline 进行一次亲密接触。
最后,我们讨论了很多读者认为神秘而陌生的 Wayland 。其实,Wayland 既不神秘也不陌生,它是在 DRI 和复合扩展发展的背景下产生的,基于 DRI 和复合扩展演进的成果。从某个角度,Wayland 更像是去除了基于网络的服务器/客户端的 X 和复合管理器的一次整合。
一、渲染和显示
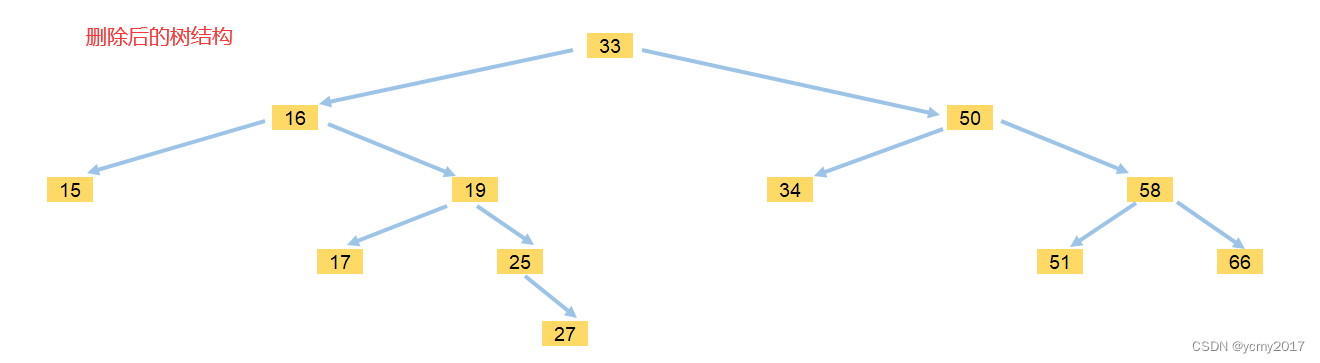
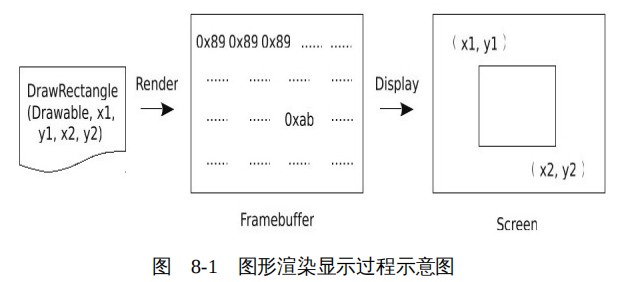
计算机将图形显示到显示设备上的过程,可以划分为两个阶段:第一阶段是渲染(render)过程,第二阶段是显示(display)过程,如图 8-1 所示。
1、渲染
所谓渲染就是将使用数学模型描述的图形,如 “DrawRectangle(x1,y1,x2,y2)” ,转化为像素阵列,或者叫像素数组。像素数组中的每个元素是一个颜色值或者颜色索引,对应图像的一个像素。对于 X 窗口系统,数组中的元素是一个颜色索引,具体的颜色根据这个索引从颜色映射(Colormap)中查询得来。
渲染通常又被分为两种:一种渲染过程是由 CPU 完成的,通常称为软件渲染,另外一种是由 GPU 完成的,通常称为硬件渲染,也就是我们常常提到的硬件加速。
谈及渲染,不得不提的另外一个关键概念就是帧缓冲(Framebuffer)。从字面意义上讲,frame 表示屏幕上的某个时刻对应的一帧图像,buffer 就是一段存储区了,因此,在狭义上,合起来的这个词就是指存储一帧屏幕图像像素数据的存储区。
但是从广义上,帧缓冲则是多个缓冲区的统称。比如在 OpenGL 中,帧缓冲包括用于输出的颜色缓冲(Color Buffer),以及辅助用来创建颜色缓冲的深度缓冲( Depth Buffer )和模板缓冲( Stencil Buffer)等。即使在 2D 环境中,帧缓冲这个概念也不仅指屏幕上的一帧图像,还包含用于存储命令的缓冲(Command Buffer)等。每一个应用都有自己的一套帧缓冲。
在 OpenGL 环境中,为了避免渲染和显示过程交叉导致冲突,从而出现如撕裂(tearing)以及闪烁(flicker)等现象,颜色缓冲又被划分为前缓冲(front buffer)和后缓冲(back buffer)。如果为了支持立体效果,则前缓冲和后缓冲又分别划分为左和右各两个缓冲区,我们不讨论这种情况。前缓冲和后缓冲中的内容都是像素阵列,每个像素或者是一个颜色值,或者是一个颜色索引。只不过前缓冲用于显示,后缓冲用于渲染。
2D 可以看作 3D 的一个特例,因此,我们将 2D 程序中用于输出的缓冲区称为前缓冲。为了避免歧义,在容易引起混淆的地方我们尽量不使用这个多义的帧缓冲一词。
2、显示
一般而言,显示设备也使用像素来衡量,比如屏幕的分辨率为 1366×768,那么其可以显示 1049 088 个像素,一个像素对应屏幕上的一个点,图像就是通过这些点显示出来的。通常,图像中一个像素对应屏幕上的一个像素,那么将图像显示到屏幕的过程就是逐个读取帧缓冲中存储的图像的像素,根据其所代表的颜色值,控制显示器上对应的点显示相应颜色的过程。
通常,显示过程基本上要经过如下几个组件:显示控制器(CRTC)、编码器(Encoder)、发射器(Transmitter)、连接器(Connector),最后显示在显示器上。
(1)显示控制器
显示控制器负责读取帧缓冲中的数据。对于 X 来说,帧缓冲中存储的是颜色的索引,显示控制器读取索引值后,还需要根据索引值从颜色映射中查询具体的颜色值。显示控制器也负责产生同步信号,典型的如水平同步信号(HSYNC)和垂直同步信号(VSYNC)。水平同步信号目的是通知显示设备开始显示新的一行,垂直同步信号通知显示设备开始显示新的一帧。所谓同步,以垂直同步信号为例,我们可以这样来通俗地理解它:显示控制器开始扫描新的一帧数据了,因此它通过这个信号告诉显示器开始显示,跟上我,不要掉队,这就是同步的意思。以 CRT 显示器为例,这两个信号控制着电子枪的移动,每显示完一行,电子枪都会回溯到下一行的开始,等待下一个水平同步信号的到来。每显示完一帧,电子枪都会回溯到屏幕的左上角,等待一下垂直同步信号的到来。
(2)编码器
对于帧缓冲中每个像素,可能使用 8 位、16 位、32 位甚至更多的位来表示颜色值,但是对于具体的接口来说,却远没有这么多的数据线供使用,而且不同的接口有不同的格式规定。比如对于 VGA 接口来说,总共只有三根数据线,每个颜色通道占用一根数据线;对于 LVDS 来说,数据是串行传输的。因此,需要将 CRTC 读取的数据编码为适合具体物理接口的编码格式,这就是编码器的作用。
(3)发射器
发射器将经过编码的数据转变为物理信号。读者可以将其想象成:发射器将 1 转化为高电平,将 0 转化为低电平。当然,这只是一个形象的说法。
(4)连接器
连接器有时也被称为端口(Port),比如 VGA 、LVDS 等。它们直接连接着显示设备,负责将发射器发出的信号传递给显示设备。
二、显存
Intel 的 GPU 集成到芯片组中,一般没有专用显存,通常是由 BIOS 从系统物理内存中分配一块空间给 GPU 作专用显存。一般而言,BIOS 会有个默认的分配规则,有的 BIOS 也会为用户留有接口,用户可以通过 BIOS 设置显存的大小。如对于具有 1GB 物理内存的系统来说,可以划分 256MB 内存给 GPU 用作显存。
但是这种静态的分配方式带来的问题之一就是如何平衡系统与显示占用的内存,究竟分配多少内存给 GPU 才能在系统常规使用和运行图形计算密集的应用(如 3D 应用)之间达到最优。如果分配给 GPU 的显存少了,那么在进行图形处理时性能必然会降低。而单纯提高分配给 GPU 的显存,也可能会造成系统的整体性能降低。而且,过多的分配内存给显存,那么当不运行 3D 应用时,就是一种内存浪费。毕竟,用户的使用模式不会是一成不变的,比如对于一个程序员来说,在编程之余也可能会玩一些游戏。但是我们显然不能期望用户根据具体运行应用的情况,每次都进入 BIOS 修改内存分配给显存的大小。
为了最优利用内存,一种方式就是不再从内存中为 GPU 分配固定的显存,而是当 GPU 需要时,直接从系统内存中分配,不使用时就归还给系统使用。但是 CPU 和 GPU 毕竟是两个完全独立的处理器,虽然现在 CPU 和 GPU 正在走融合之路,但是它们依然有自己的地址空间。显然,我们不能允许 CPU 和 GPU 彼此独立地去使用物理内存,这样必然会导致冲突,也正是因为这个原因,才有了我们前面提到的 BIOS 会从物理内存中划分一块区域给 GPU ,这样 CPU 和 GPU 才能井水不犯河水,分别使用属于自己的存储区域。
1、动态显存技术
为了解决这个矛盾,Intel 的开发者们开发了动态显存技术(Dynamic Video Memory Technology),相比于以前在内存中为 GPU 开辟专用显存,使用动态显存技术后,显存和系统可以按需动态共享整个主存。
动态显存中关键的是 GART(graphics address remapping table),也被称为 GTT(graphics translation table),它是 GPU 直接访问系统内存的关键。事实上,这是 CPU 和 GPU 的融合过程中的一个产物,最终,CPU 和 GPU 有可能完全实现统一的寻址。
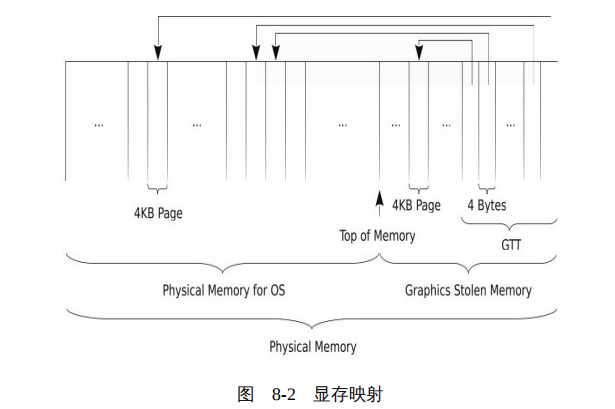
GTT 就是一个表格,或者说就是一个数组,表格中的每一个表项占用 4 字节,或者指向物理内存中的一个页面,或者设置为无效。整个 GTT 所能寻址的范围就代表了 GPU 的逻辑寻址空间,如 512KB 大小的 GTT 可以寻址 512MB 的显存空间(512K/4*4KB=512MB),如图 8-2 所示。
这是一种动态按需从内存中分配显存的方式,GTT 中的所有表项不必全部都映射到实际的物理内存,完全可以按需映射。而且当 GTT 中的某个表项指向的内存不再被 GPU 使用时,可以收回为系统所用。通过这种动态按需分配的方式,达到系统和 GPU 最优分享内存。内核中的 DRM 模块设计了特殊的互斥机制,保证 CPU 和 GPU 独立寻址物理内存时不会发生冲突。
我们注意到,GPU 是通过 GTT 访问内存的(内存中用作显存的部分),所以 GPU 首先要访问 GTT,但是,GTT 也是在内存中。显然,这又是一个先有鸡还是先有蛋的问题。因此,需要另外一个协调人出现,这个协调人就是 BIOS 。在 BIOS 中,仍然需要在物理内存中划分出一块对操作系统不可见、专用于显存的存储区域,这个区域通常也称为 Graphics Stolen Memory 。但是相比于以前动辄分配几百兆的专用显存给 GPU ,这个区域要小多了,一般几 MB 就足矣,如我们前面讨论的寻址 512MB 的显存,只需要一个 512KB 的 GTT 表。
BIOS 负责在 Graphics Stolen Memory 中建立 GTT 表格,初始化 GTT 表格的表项,更重要的是,BIOS 负责将 GTT 的相关信息,如 GTT 的基址,写入到 GPU 的 PCI 的配置寄存器(PCI Configuration Registers),这样,GPU 可以直接找到 GTT 了。
2、Buffer Object
与 CPU 相比,GPU 中包含大量的重复的计算单元,非常适合如像素、光影处理、3D 坐标变换等大量同类型数据的密集运算。因此,很多程序为了能够使用 GPU 的加速功能,都试图和 GPU 直接打交道。因此,系统中可能有多个组件或者程序同时使用 GPU ,如 Mesa 中的 3D 驱动、X 的 2D 驱动以及一些直接通过帧缓冲驱动直接操作帧缓冲的应用等。但是多个程序并发访问 GPU ,一旦逻辑控制不好,势必导致系统工作极不稳定,严重者甚至使 GPU 陷入一个混乱的状态。
而且,如果每个希望使用 GPU 加速的组件或程序都需要在自身的代码中加入操作 GPU 的代码,也使开发过程变得非常复杂。
于是,为了解决这一乱象,开发者们在内核中设计了 DRM 模块,所有访问 GPU 的操作都通过 DRM 统一进行,由 DRM 来统一协调对 GPU 的访问,如图 8-3 所示。
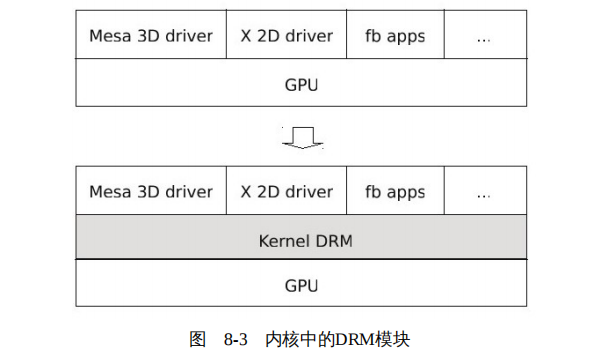
DRM 的核心是显存的管理,当前内核的 DRM 模块中包含两个显存管理机制:GEM 和 TTM。TTM 先于 GEM 开发,但是 Intel 的工程师认为 TTM 比较复杂,所以后来设计了 GEM 来替代 TTM 。目前内核中的 ATI 和 NVIDA 的 GPU 驱动仍然使用 TTM ,所以 GEM 和 TTM 还是共存的,但是 GEM 占据主导地位。
GEM 抽象了一个数据结构 Buffer Object ,顾名思义,就是一块缓冲区,但是比较特别,是 GPU 使用的一块缓冲区,也就是一块显存。比如一个颜色缓冲的像素阵列保存在一个 Buffer Object ,绘制命令以及绘制所需数据也分别保存在各自的 Buffer Object,等等。笔者实在找不到一个准确的中文词汇来代表 Buffer Object,所以只好使用这个英文名称。开发者习惯上也将 Buffer Object 简称为 BO,后续为了行文方便,我们有时也使用这个简称,其定义如下:
// linux-3.7.4/include/drm/drmP.h:struct drm_gem_object {...struct file *filp;...int name;...
};
其中两个关键的字段是 filp 和 name 。
对于一个 BO 来说,可能会有多个组件或者程序需要访问它。GEM 使用 Linux 的共享内存机制实现这一需求,字段 filp 指向的就是 BO 对应的共享内存,代码如下:
// linux-3.7.4/drivers/gpu/drm/drm_gem.c:int drm_gem_object_init(...) {...obj->filp = shmem_file_setup("drm mm object", size, ...);...
}
既然多个组件需要访问 BO,GEM 为每个 BO 都分配了一个名字。当然这个名字不是一个简单的字符,它是一个全局唯一的 ID,各个组件使用这个名字来访问 BO 。
BO 可以占用一个页面,也可以占用多个页面。但是,通常 BO 都是占用整数个页面,即 BO 的大小一般是 4KB 的整数倍。在 i915 的 BO 的结构体定义中,数据项 pages 指向的就是 BO 占用的页面的链表,这里并不是使用的简单的链表,结构体 sg_table 使用了散列技术。具体代码如下:
// linux-3.7.4/drivers/gpu/drm/i915/i915_drv.h:struct drm_i915_gem_object {...struct sg_table *pages;...
};
为了可以被 GPU 访问,BO 使用的内存页面还要映射到 GTT 。这个映射过程也比较直接,就是将 BO 所在的页面填入到 GTT 的表项中。
综上,我们看到,BO 本质上就是一块共享内存,对于 CPU 来说 BO 与其他内存没有任何差别,但是 BO 又是特别的,它被映射进了 GTT,所以它既可以被 CPU 寻址,也可以被 GPU 寻址,如图 8-4 所示。
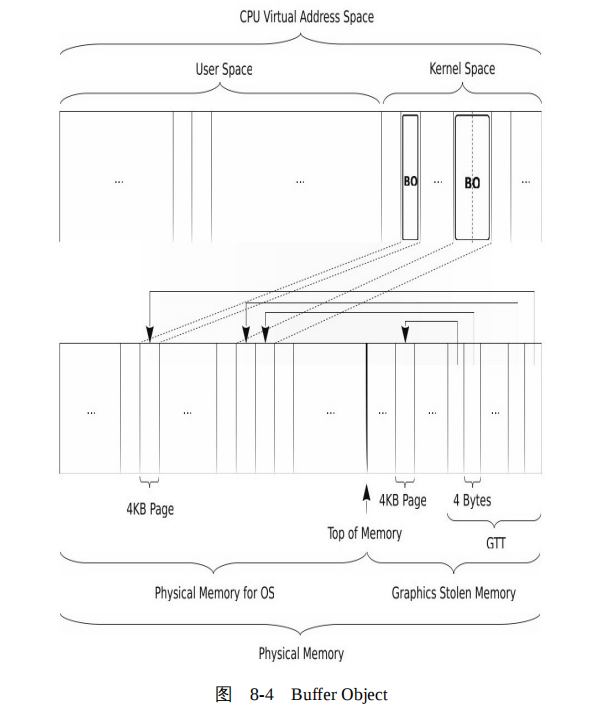
为了方便程序使用内核的 DRM 模块,开发者们开发了库 libdrm 。在库 libdrm 中 BO 的定义如下:
// libdrm-2.4.35/intel/intel_bufmgr.h:struct _drm_intel_bo {...unsigned long offset;...void *virtual;...
};
其中两个重要的数据项是 offset 和 virtual 。
事实上,BO 只是 DRM 抽象的在内核空间代表一块显存的一个数据结构。那么 GPU 是怎么找到 BO 的呢?如同 CPU 使用地址寻址一个内存单元一样,GPU 也使用地址寻址。GPU 根本不关心什么 BO ,它只认显存的地址。因此,每一个 BO 在显存的地址空间中,都有一个唯一的地址,GPU 通过这个地址寻址,这就是 offset 的意义。offset 是 BO 在显存地址空间中的虚拟地址,显存使用线性地址寻址,任何一个显存地址都是从起始地址的偏移,这就是 offset 命名的由来。offset 通过 GTT 即可映射到实际的物理地址。当我们向 GPU 发出命令访问某个 BO 时,就使用 BO 的成员 offset 。
有时需要将 BO 映射到用户空间,其中数据项 virtual 就是记录映射的基址。
前面,我们讨论了 BO 的本质。下面我们从使用的角度看一看 CPU 与 GPU 又是如何使用 BO 的。BO 是显存的基本单元,所以从保存像素阵列的帧缓冲,到 CPU 下达给 GPU 的指令和数据,全部使用 BO 承载。下面,我们分别从软件渲染和硬件渲染两个角度看看 BO 的使用。
(1)软件渲染
当 GPU 不支持某些绘制操作时,代表帧缓冲的 BO 将被映射到用户空间,用户程序直接在 BO 上使用 CPU 进行软件绘制。从这里我们也可以看出,DRM 巧妙的设计使得 BO 非常方便地在显存和系统内存之间进行角色切换。
(2)硬件渲染
当 GPU 支持绘制操作时,用户程序则将命令和数据等复制到保存命令和数据的 BO ,然后 GPU 从这些 BO 读取命令和数据,按照 BO 中的指令和数据进行渲染。
库 libdrm 中提供了函数 drm_intel_bo_subdata 和 drm_intel_bo_get_subdata ,在程序中一般使用这两个函数将用户空间的命令和数据复制到内核空间的 BO 读者也会见到 dri_bo_subdata 和 dri_bo_get_subdata 。对于 Intel 的驱动来说,后面两个函数分别是前面两个函数的别名而已。后面讨论具体渲染过程时,我们会经常看到这几个函数。
LIBDRM使用
Linux系统中少有的图形子系统分析
Linux DRM(一) – 硬件信号
Linux DRM(二) --Xorg/DRM
Linux DRM(三) – DRM KMS/ Debug
Linux DRM(四) – loongson driver
Linux DRM(五) – Libdrm 库
Linux DRM(六) – xrandr
Linux DRM(六) – EDID
三、2D渲染
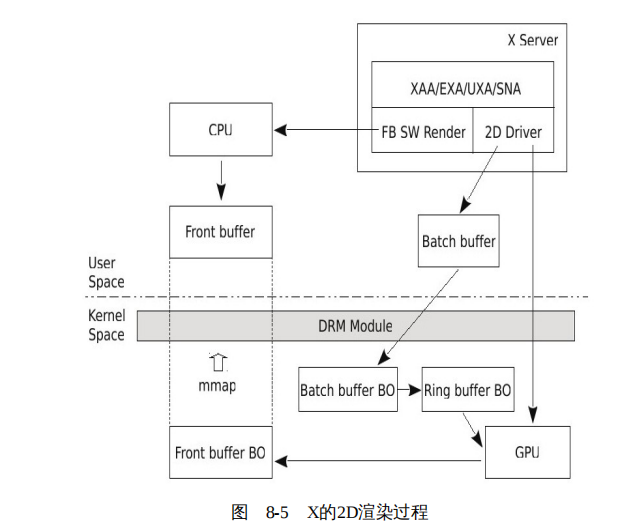
这一节,我们结合 X 窗口系统,讨论 2D 程序的渲染过程。我们可以形象地将 2D 渲染过程比喻为绘画,其中有两个关键的地方:一个是画布,另外一个是画笔。
X 服务器启动后,将加载 GPU 的 2D 驱动,2D 驱动将请求内核中的 DRM 模块创建帧缓冲,这个帧缓冲就相当于画布。然后 X 服务器按照绘画需要,从画笔盒子中挑选合适的画笔进行绘画。
X 的画笔保存在结构体 GCOps 中,其中包含了基本的绘制操作,如绘制矩形的 PolyRectangle ,绘制圆弧的 PolyArc ,绘制实心多边形的 FillPolygon ,等等。代码如下:
// xorg-server-1.12.2/include/gcstruct.h:typedef struct _GCOps {...void (*PolyRectangle) (DrawablePtr /*pDrawable */ , ...);void (*PolyArc) (DrawablePtr /*pDrawable */ , ...);void (*FillPolygon) (DrawablePtr /*pDrawable */ , ...);void (*PolyFillRect) (DrawablePtr /*pDrawable */ , ...);...
} GCOps;
最初,这些绘制操作均由 CPU 负责完成,也就是我们通常所说的软件渲染。X 中的 fb 层就是软件渲染的实现,代码如下:
// xorg-server-1.12.2/fb/fbgc.c:const GCOps fbGCOps = {fbFillSpans,...fbPolySegment,fbPolyRectangle,fbPolyArc,miFillPolygon,...
};
但是随着 GPU 的不断发展,其计算能力越来越强。于是 X 的开发者们不断改进 X 的渲染部分,希望能充分利用 GPU 擅长的图形操作以大幅提高计算机的图形能力,而又可以解放 CPU,使其专心于控制逻辑。也就是说,X 的开发者们希望画笔盒子中的画笔更多地来自 GPU 。
当然,任何事物都不是一蹴而就的,GPU 的渲染能力也是螺旋演进的,对于 GPU 尚未实现的或者相比来说 CPU 更适合的渲染操作还是需要 CPU 来完成,因此,X 的渲染架构也随着 GPU 的演进不断地改进。在 XFree86 3.3 的时候,X 的开发者设计了 XAA(XFree86 Acceleration Architecture)架构;在 X.Org Server 6.9 版本,开发者用改进的 EXA 取代了 XAA;当 DRM 中使用了 GEM 后,Intel 的 GPU 驱动开发者们重新实现了 EXA ,并命名为 UXA(Unified Acceleration Architecture);随着 Intel 推出 Sandy Bridge 及 ivy Birdge 芯片组,Intel 又开发了 SNA(SandyBridge’s New Acceleration)。
后续,我们以成熟且稳定的 UXA 为例进行讨论。在 UXA 架构下,X 的画笔盒子如下:
// xf86-video-intel-2.19.0/uxa/uxa-accel.c:const GCOps uxa_ops = {uxa_fill_spans,...uxa_poly_lines,uxa_poly_segment,miPolyRectangle,uxa_check_poly_arc,miFillPolygon,...
};
我们看到 uxa_ops 包含在 Intel 的 GPU 驱动中,当然,这是非常合理的,因为只有 GPU 自己最清楚哪些渲染自己可以胜任,哪些还需要 CPU 来负责。在 uxa_ops 中,有一部分画笔来自 GPU ,另外一部分来自 CPU 。
对于每一个绘制操作,UXA 首先检查 GPU 是否支持这个绘制操作,或者说在某些条件下,对于这个绘制操作,GPU 渲染的比 CPU 更快。如果 GPU 支持这个绘制操作,UXA 首先将绘制的命令翻译为 GPU 可以识别的指令,并将这个指令、绘制所需的相关数据,以及保存像素阵列的 BO 在显存地址空间中的地址,一同保存在用户空间的批量缓冲(Batch Buffer),然后通过 DRM 将用户空间的批量缓冲复制到内核为批量缓冲创建的 BO ,之后通知 GPU 从 BO 中读取指令和数据进行绘制。实际上,DRM 按照 Intel GPU 的要求在批量缓冲和 GPU 之间还组织了一个环形缓冲区(Ring buffer),但是我们暂时忽略它,这对于理解 2D 渲染过程没有任何影响,后面在讨论 3D 渲染过程时,我们会简单的讨论这个环形缓冲区。
如果 GPU 不支持这个绘制操作,那么 UXA 将代表帧缓冲的 BO 映射到 X 服务器的用户空间,X 服务器借助 fb 层中的实现,使用 CPU 进行绘制。
也就是说,UXA 在 fb 和 GPU 加速的上面封装了一层,其根据具体绘制动作选择使用来自 GPU 的画笔或来自 CPU 的画笔。
综上,X 的 2D 渲染过程如图 8-5 所示。
不知读者是否注意到,无论是 fbGCOps,还是 uxa_ops,其中均有个别的绘制函数以 “mi” 开头。这些以 “mi” 开头的函数包含在 X 的 mi 层中。mi 是 Machine Independent 的缩写,顾名思义,是与机器无关的实现。笔者没有找到 X 中关于这个层的非常明确的解释,但是根据 mi 中的代码来看,其中的绘致函数根据不同的绘制条件,被拆分为调用其他 GCOps 中的绘制函数。
基本上,拆分的原因无外乎 GPU 支持的绘制原语有限,所以有些绘制操作需要分解为 GPU 可以支持的动作。或者出于绘制效率的考虑,将某些绘制操作拆分为效率更好的绘制原语。因此,X 将这些与具体绘制实现无关的代码剥离到
一个单独的模块 mi 中。从这个角度或许能解释 X 为什么将这个层命名为 Machine Independent。
1、创建前缓冲
在 X 环境下,在不开启复合(Composite)扩展的情况下,所有程序共享一个前缓冲。对于 2D 程序,所有的绘制动作生成的图像的像素阵列最终都输出到这个前缓冲上,窗口只不过是前缓冲中的一块区域而已。
但是一旦开启了复合扩展,那么每个窗口都将被分配一个离屏(offscreen)的缓冲,类似于 OpenGL 环境中的后缓冲。应用将生成的像素阵列输出到这个离屏的缓冲中,在绘制完成后,X 服务器将向复合管理器(Composite Manager)发送 Damage 事件,复合管理器收到这个事件后,将离屏缓冲区的内容合成到前缓冲。为了避免复合扩展干扰我们探讨图形渲染的本质,在讨论 2D、包括后面的 3D 渲染时,我们都不考虑复合扩展开启的情况。
在 X 中,Window 和 Pixmap 是两个绘制发生的地方,Window 代表屏幕上的窗口,Pixmap 则代表离屏的一个存储区域。所以自然而然的,X 使用数据结构 Pixmap 来表示前缓冲。因为这个前缓冲对应整个屏幕,而且不属于某一个应用,因此开发者也将代表前缓冲的这个 Pixmap 称为 Screen Pixmap 。后续为了行文方便,我们有时也使用 Screen Pixmap 这个词来代表前缓冲的这个 Pixmap 对象。显然,这个Screen Pixmap 也是显示器(Screen)的资源,所以X将其保存到了代表显示器的结构体_Screen中。
2、GPU渲染
GPU 渲染,也就是我们通常所说的硬件加速,从软件的层面所做的工作就是将数学模型按照 GPU 的规定,翻译为 GPU 可以识别的指令和数据,传递给 GPU,生成像素阵列等图像密集型计算则由 GPU 负责完成。可见,当使用 GPU 进行渲染时,在软件层面,实质上就是组织命令和数据而已。
Intel GPU 的 2D 驱动是如何将这些命令和数据传递给 GPU 的呢?读者一定想到了 BO 。在 Intel GPU 的 2D 驱动中,定义了使用了一种所谓的批量缓冲来保存这些命令和数据,这里所谓的批量就是将驱动准备命令和数据放到这个缓冲,然后批量地让 GPU 来读取,这就是批量缓冲的由来。
3、CPU渲染
根据上节讨论的函数 uxa_poly_fill_rect ,我们看到,GPU 并不是接收全部的绘制实心矩形的操作。对于不满足GPU条件的实心矩形,则将求助于 CPU 绘制,对应的函数是 uxa_check_poly_fill_rect 。

BO 是由 DRM 模块在内核空间分配的,因此运行在用户空间的 X( 2D驱动)要想访问这个内存,必须首先要将其映射到用户空间,这是由函数 uxa_prepare_access 来完成的。然后,X 使用 CPU 在映射到用户空间的 BO 上进行绘制。看到以 fb 开头的函数 fbPolyFillRect,读者一定猜到了,这就是 X 的 fb 层的函数,而 fb 层正是软件渲染的实现。
(1)映射 BO 到用户空间
函数 uxa_check_poly_fill_rect 调用 uxa_prepare_access 将 BO 映射到用户空间:
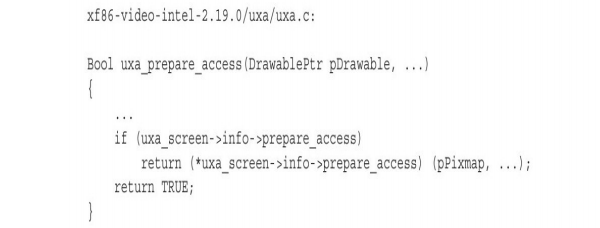
函数 intel_uxa_prepare_access 通过 libdrm 库中的函数 drm_intel_gem_bo_map_gtt 申请内核中的 DRM 模块将保存前缓冲的像素阵列的 BO 映射到用户空间:
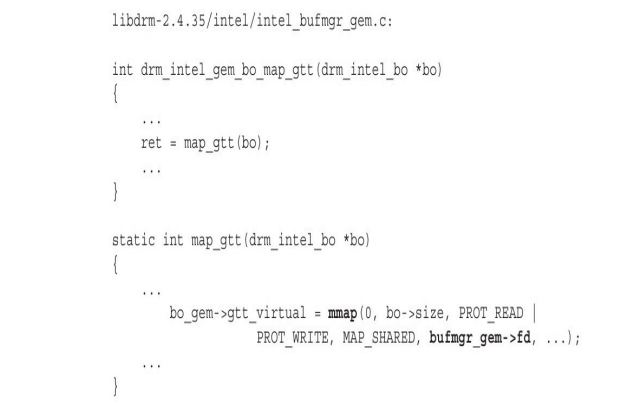
看到熟悉的函数 mmap ,读者应该一切都明白了。从 CPU 的角度看,BO 与普通内存并无区别,所以,映射 BO 与映射普通内存完全相同。其中 bufmgr_gem->fd 指向的就是代表 BO 的共享内存。
(2)使用 CPU 在映射到用户空间的 BO 上进行绘制
X 的软件渲染层(即 fb 这一层),或者借助库 pixman 中的 API,或者自己直接操作像素数组,完成图形的绘制。其原理非常简单,就是直接设置像素数组中的颜色值或索引。
经过对 2D 渲染的探讨,我们看到,所谓的软件渲染和硬件加速,本质上都是生成图像的像素阵列,只不过一个是由 CPU 来计算的,另外一个是由 GPU 来计算的。当然,对于硬件加速,CPU 要充当一个翻译,将数学模型按照 GPU 的要求翻译为其可以识别的指令和数据。
四、3D渲染
运行在 X 上的 2D 程序,都将绘制请求发给 X 服务器,由 X 服务器来完成绘制。但是对于 3D 图形的绘制,X 应用需要通过套接字向 X 服务器传递大量的数据,这种机制严重影响了图形的渲染效率。为了解决效率问题,X 的开发者们设计了 DRI 机制,即 X 应用不再将绘制图形的请求发送给 X 服务器了,而是由应用自行绘制。
在 Linux 平台上,OpenGL 的实现是 Mesa ,所以在本节中,我们结合 Mesa,探讨 3D 的渲染过程。我们可以认为 Mesa 分为两个关键部分:
◆ 一部分是一套兼容 OpenGL 标准的实现,为应用程序提供标准的 OpenGL API 。
◆ 另外一部分是 DRI 驱动,通常也被称为 3D 驱动,其中包括 Pipleline 的软件实现,也就是说,即使 GPU 没有任何 3D 计算能力,那么 Mesa 也完全可以使用 CPU 完成 3D 渲染功能。3D 驱动还负责将 3D 渲染命令翻译为 GPU 可以理解并能执行的指令。不同的 GPU 有各自的 “指令集” ,因此,在 Mesa 中不同的 GPU 都有各自的 3D 驱动。
Pipeline 最后将生成好的像素阵列输出到帧缓冲,但是这还不够,因为最后的输出需要显示到屏幕上。而屏幕的显示是由具体的窗口系统控制的,因此,帧缓冲还需要与具体的窗口系统相结合。但是 X 的核心协议并不包含 OpenGL 相关的协议,因此,开发者们开发了 GL 的扩展 GLX(GL Extension)。为了支持 DRI,开发者们又开发了 DRI 扩展。显然,GLX 以及 DRI 扩展在 X 和 Mesa 中均需要实现。
基本上,运行在 X 窗口系统上的 OpenGL 程序的渲染过程,可以划分为三个阶段,如图 8-6 所示。
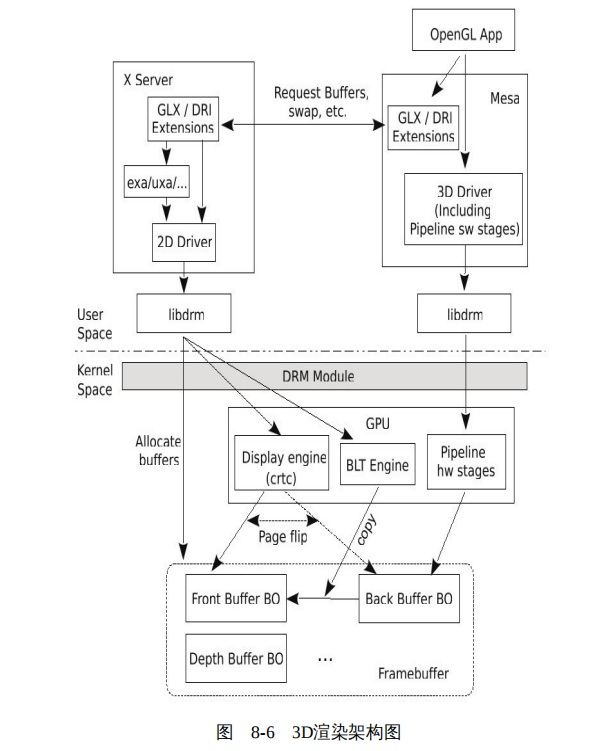
1)应用创建 OpenGL 的上下文,包括向 X 服务器申请创建帧缓冲。应用为什么不自己直接向内核的 DRM 模块请求创建帧缓冲呢?从技术上讲,应用自己请求 DRM 创建请求创建帧缓冲没有任何问题,但是为了将帧缓冲与具体的窗口系统绑定,应用只能委屈一下,放低姿态请求 X 服务器为其创建帧缓冲。这样,X 服务器就掌握了应用的帧缓冲的一手材料,在需要时,将帧缓冲显示到屏幕。帧缓冲是应用程序的 “画板” ,因此创建完成后,X 服务器需要将帧缓冲的 BO 的信息返回给应用。
2)应用程序建立数学模型,并通过 OpenGL 的 API 将数学模型的数据写入顶点缓冲(vertex buffer);更新 GPU 的状态,如指定后缓冲,用来存储 Pipeline 输出的像素阵列;然后启动 Pipeline 进行渲染。
3)渲染完成后,应用程序向 X 服务器发出交换(swap)请求。这里的交换有两种方式,一种是复制(copy),所谓复制就是将后缓冲中的内容复制到前缓冲,这是由 GPU 中 BLT 引擎负责的。但是复制的效率相对较低,所以,开发者们又设计了一种称为页翻转(page flip)的模式,在这种模式下,不需要复制动作,而是通过 GPU 的显示引擎控制显示控制器扫描哪个帧缓冲,这个被扫描的缓冲此时扮演前缓冲,而另外一个不被扫描的帧缓冲则作为应用的 “画板” ,也就是所说的后缓冲。
接下来我们就围绕这三个阶段,讨论 3D 程序的渲染过程。
1、创建帧缓冲
在 2D 渲染中,渲染过程都由 X 服务器完成,所以毫无争议,前缓冲由而且只能由 X 服务器创建。但是对于 DRI 程序来说,其渲染是在应用中完成,应用当然需要知道帧缓冲,但是 X 服务器控制着窗口的显示,所以 X 服务器也需要知道帧缓冲。所以,帧缓冲或者由 X 服务器创建,然后告知应用;或者由应用创建,然后再告知 X 服务器。X 采用的是前者。
虽然 OpenGL 中的帧缓冲的概念与 2D 相比有些不同,但本质上并无差别,帧缓冲中的每个缓冲都对应着一个 BO 。为了管理方便,Mesa 为帧缓冲以及其中的各个缓冲分别抽象了相应的数据结构,代码如下:
// Mesa-8.0.3/src/mesa/main/mtypes.hstruct gl_framebuffer {...struct gl_renderbuffer_attachment Attachment[BUFFER_COUNT];...
};
其中,结构体 gl_framebuffer 是帧缓冲的抽象。结构体 gl_renderbuffer 是颜色缓冲、深度缓冲等的抽象。gl_framebuffer 中的数组 Attachment 中保存的就是颜色缓冲、深度缓冲等。
在具体的 3D 驱动中,通常会以 gl_renderbuffer 作为基类,派生出自己的类。如对于 Intel GPU 的 3D 驱动,派生的数据结构为 intel_renderbuffer :
// Mesa-8.0.3/src/mesa/drivers/dri/intel/intel_fbo.hstruct intel_renderbuffer {struct swrast_renderbuffer Base;struct intel_mipmap_tree *mt; /** < The renderbuffer storage. */
};
其中指针 mt 间接指向缓冲区对应的 BO 。
如同在 Intel GPU 的 2D 驱动中,使用结构体 intel_pixmap 封装了 BO 一样,Intel GPU的 3D 驱动也在 BO 之上包装了一层 intel_region 。intel_region 中除了包括 BO 外,还包括缓冲区的一些信息,如缓冲区的宽度、高度等:
// Mesa-8.0.3/src/mesa/drivers/dri/intel/intel_regions.h:struct intel_region {drm_intel_bo *bo; /**< buffer manager's buffer */GLuint refcount; /**< Reference count for region */GLuint cpp; /**< bytes per pixel */GLuint width; /**< in pixels */...
};
当 OpenGL 应用调用 glXMakeCurrent 时,就开启了创建帧缓冲的过程,这个过程可分为三个阶段:
1)OpenGL 应用向 X 服务器请求为指定窗口创建帧缓冲对应的 BO 。帧缓冲中包含多个缓冲,所以当然是创建多个 BO 了。
2)X 服务器收到应用的请求后,为各个缓冲创建 BO 。在创建完成后,将 BO 的名字等相关信息发送给应用。
3)应用收到 BO 信息后,将更新 GPU 的状态。比如告诉 GPU 画板在哪里。
2、渲染Pipleline
与 2D 渲染相比,3D 渲染要复杂得多。就如同有些复杂的绘画过程,要分成几个阶段一样,OpenGL 标准也将 3D 的渲染过程划分为一些阶段,并将由这些阶段组成的这一过程形象地称为 Pipleline 。
应用程序建立基本的模型包括在对象坐标中的顶点数据、顶点的各种属性(比如颜色),以及如何连接这些顶点(如是连接成直线还是连接为三角形),等等,统一存储在顶点缓冲中,然后作为 Pipeline 的输入,这些输入就像原材料一样,经过 Pipeline 这台机器的加工,最终生成像素阵列,输出到后缓冲的 BO 中。
OpenGL 的标准规定了一个参考的 Pipeline,但是各家 GPU 的实现与这个参考还是有很多差别的,有的 GPU 将相应的阶段合并,有的 GPU 将个别阶段又拆分了,有的可能增加了一些阶段,有的又砍了一些阶段。但是,大体上整个过程如图 8-7 所示。
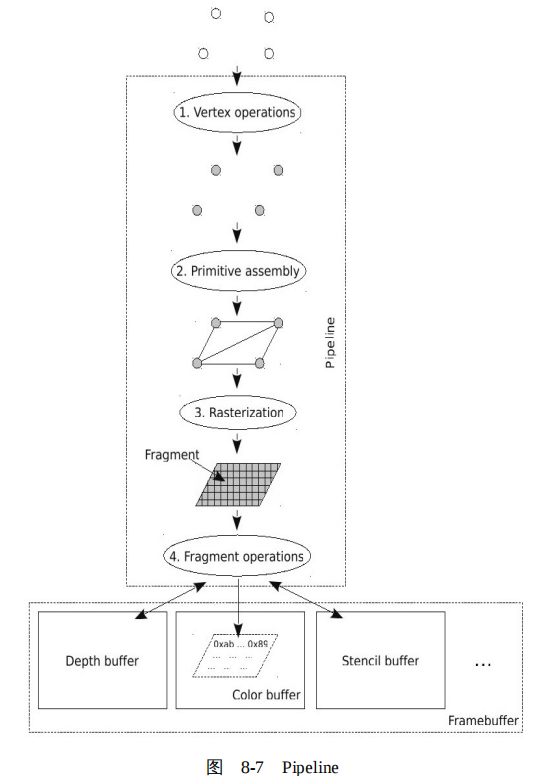
(1)顶点处理
OpenGL 使用顶点的集合来定义或逼近对象,应用程序建模实际上就是组织这些顶点,当然也包括顶点的属性。Pipeline 的第一个阶段就是顶点处理(vertex operations),顶点处理单元将几何对象的顶点从对象坐标系变换到视点坐标系,也就是将三维空间的坐标投影到二维坐标,并为每个顶点赋颜色值,并进行光照处理等。
(2)图元装配
显然,很多操作处理是不能以顶点单独进行处理的,比如裁减、光栅化等,需要将顶点组装成几何图形。Pipeline 将处理过的顶点连接成为一些最基本的图元,包括点、线和三角形等。这个过程成为图元装配( primitive assembly )。
任何一个曲面都是多个平面无限逼近的,而最基本的是三点表示一个平面。所以,理论上,GPU 将曲面都划分为若干个三角形,也就是使用三角形进行装配。但是也不排除现代 GPU 的设计者们使用其他的更有效的图元,比如梯形,进行装配。
(3)光栅化
我们前文提到,图形是使用像素阵列来表示的。所以,图元最终要转化为像素阵列,这个过程称为光栅化(rasterization),我们可以把光栅理解为像素的阵列。经过光栅化之后,图元被分解为一些片断(fragment),每个片段对应一个像素,其中有位置值(像素位置)、颜色、纹理坐标和深度等属性。
(4)片段处理
在 Pipeline 更新帧缓冲之前,Pipeline 执行最后一系列的针对每个片段的操作。对于每一个片断,首先进行相关的测试,比如深度测试、模板测试。以深度测试为例,只有当片段的深度值小于深度缓存中与片段相对应的像素的深度值时,颜色缓冲、深度缓冲中的与片段相对应的像素的值才会被这个片段中对应的信息更新。
Pipeline 可全部由软件实现(CPU),也可全部由硬件实现(GPU),或者二者混合,这完全取决于 GPU 的能力。对于 GPU 没有 3D 计算能力的,则 Pipeline 完全由软件实现。比如,Mesa 中的 _tnl_default_pipeline,即是一个纯软件的 Pipeline,Pipeline 中的每一个阶段均由 CPU 负责渲染:
对于 3D 计算能力比较强的 GPU,如 ATI 的 GPU,Pipeline 完全由 GPU 实现。
而有些 GPU 能力不那么强大,那么 CPU 就要参与图形渲染了,因此,Pipeline 一部分由 CPU 实现,一部分由 GPU 实现。
以 Intel GPU 为例,Pipeline 的渲染过程大致如图 8-8 所示。
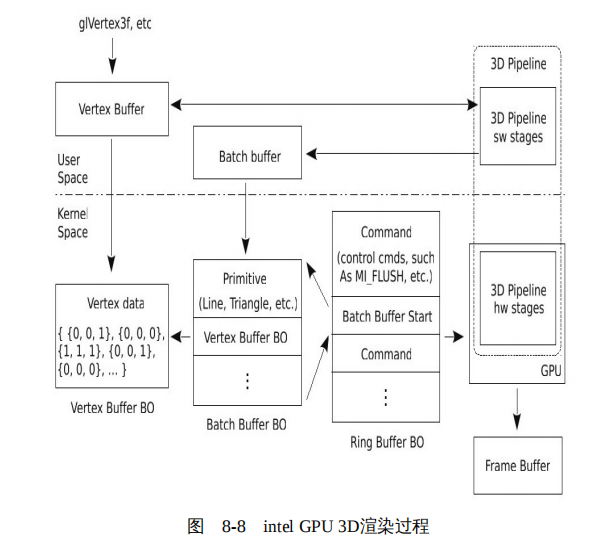
1)首先,应用程序通过 glVertex 等 OpenGL API 将数据写入用户空间的顶点缓冲。
2)当程序显示调用 glFlush,或者,当顶点缓冲满时,其将自动激活 glFlush,glFlush 将启动 Pipeline。以 intel_pipeline 为例,Pipeline 的前几个阶段是 CPU 负责的,因此,所有的输入来自用户空间的顶点缓冲,计算结果也输出到用户空间的顶点缓冲;在最后的 _intel_render_stage 阶段,按照 intel GPU 的要求,从公共的顶点缓冲中读取数据,使用 intel GPU 的 3D 驱动中提供的函数,重新组织一个符合 intel GPU 规范的顶点缓冲。
3)glFlush 调用 3D 驱动中的函数 intel_glFlush 。intel_glFlush 首先将顶点缓冲和批量缓冲复制到内核空间对应的 BO,实际上就是相当于复制到了 GPU 的显存空间,这样 GPU 就可以访问了。然后,内核的 DRM 模块将按照 Intel GPU 的要求建立一个环形缓冲区(ring buffer)。
4)准备好环形缓冲区后,内核中的 DRM 模块将环形缓冲区的信息,如缓冲区的头和尾的地址分别写入 GPU 的寄存器 Head Offset 和 Tail Offset 等。当 DRM 向寄存器 Tail Offset 写入数据时,将触发 GPU 读取并执行环形缓冲区中的命令,启动 GPU 中的 Pipeline 进行渲染。最后,GPU 的 Pipepline 将生成的像素阵列输入到帧缓冲。
-
建立数学模型
-
启动 Pipeline
在建模后,应用将顶点数据存入了顶点缓冲,加工需要的原材料已经准备好了,接下来就需要开动 Pipeline 这台加工机器了。那么,这个机器什么时候运转起来呢?通常是在程序中显示调用函数 glFlush 时。当然,一旦顶点缓冲已经充满了,也会自动调用 glFlush。读者可能有个疑问:我们编写程序时,有时并没有显示调用 glFlush 啊?没错,那是通常情况下,我们使用的都是启用了双缓冲的 OpenGL ,即前缓冲和后缓冲。对于启用双缓冲的 OpenGL 程序,OpenGL 规定,当程序在后缓冲渲染完成后,请求交换到前后缓冲时,使用 OpenGL 的 API glXSwapBuffers,而实际上,函数 glXSwapBuffers 已经替我们调用了 glFlush。 -
Pipeline 中的软件计算阶段
所谓的软件计算阶段,是指计算过程是由 CPU 来负责的。CPU 从上下文中获取上个阶段的状态信息,进行计算,然后将计算结果保存到上下文中,作为下一个阶段的输入。上下文的数据抽象为结构体 TNLcontext,其中非常重要的一个成员是结构体 vertex_buffer 。 -
Pipeline 中 GPU 相关的阶段
很难要求所有厂家的 GPU 都按照一个标准设计,所以在启动 GPU 中的硬件阶段之前,需要将 OpenGL 标准规定的标准格式的顶点缓冲中的数据按照具体的 GPU 的要求组织一下,然后再传递给 GPU 。 -
复制顶点数据和批量数据到内核空间
在 Pipeline 的软件阶段,所有阶段的计算结果都保存在用户空间,为了启动 Pipeline 的硬件阶段,显然需要将这些数据复制到内核空间的 BO,这样 GPU 才可以访问。_mesa_flush 最后将调用 3D 驱动中的函数 _intel_batchbuffer_flush 进行复制。 -
启动 GPU 中的 Pipeline
将数据复制到内核空间的BO后,接下来就需要通知GPU来读取这些数据,并执行GPU中的Pipeline。以Intel GPU为例,其规定需要将批量数据组织到一个环形缓冲区中,然后GPU从环形缓冲区中读取并执行命令,如图8-9所示。
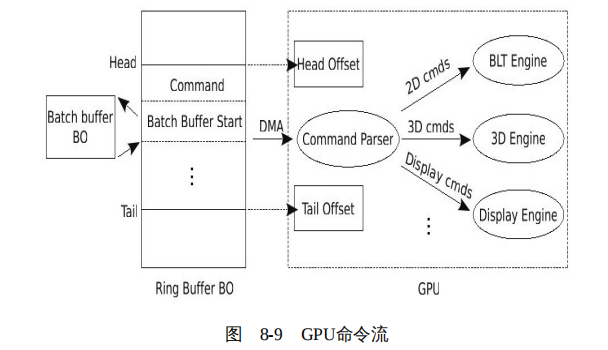
环形缓冲区也只是从内存中分配的一块用于显存的普通存储区,所以,当内核中的DRM模块组织好其中的数据后,GPU并不会自动到环形缓冲区中读取数据,而是需要通知GPU来读取。
那么内核如何通知GPU呢?熟悉驱动开发的读者应该比较容易猜到,方法之一就是直接写GPU的寄存器。Intel GPU为环形缓冲区设计了专门的寄存器,典型的包括Head Offset、Tail Offset等。其中寄存器Head Offset中记录环形缓存区中有效数据的起始位置,寄存器Tail Offset中记录的则是环形缓存区中有效数据的结束位置。
一旦内核中的DRM模块向寄存器Tail Offset中写入数据,GPU就将对比寄存器Head Offset和Tail Offset中的值。如果这两个寄存器中的值不相等,那么就说明环形缓冲区中已经存在有效的命令了,GPU中的命令解析单元(Command Parser)通过DMA的方式直接从环形缓冲区中读取命令,并根据命令的类型,定向给不同的处理引擎。如果是3D命令,则转发给GPU中的3D引擎;如果是2D命令,则转发给GPU中的BLT引擎;如果是控制显示的,则转发给Display引擎;等等。
3、交换前缓冲和后缓冲
应用程序绘制完成后,需要将后缓冲交换(swap)到前缓冲,其中有三个问题需要考虑。
(1)谁来负责交换
如果应用自己负责将后缓冲更新到前缓冲,那么当有多个应用同时更新前缓冲时如何协调?显然将交换动作交给更擅长窗口管理的X服务器统一协调更为合理。
如果X服务器开启了复合扩展,更需要知道应用已经更新前缓冲了,因为X服务器需要通知复合管理器重新合成前缓冲。
综上,应该由X服务器来负责交换前后缓冲。
对于GPU支持交换的情况,X服务器通过2D驱动请求GPU进行交换。否则X服务器只能将前缓冲和后缓冲的BO映射到用户空间,使用CPU逐位复制。
(2)交换的时机
与2D应用不同,3D程序通常涉及复杂的动画和图像,如果显示控制器正在扫描前缓冲的同时,X服务器更新了前缓冲,那么可能会导致屏幕出现撕裂(tearing)现象。所谓的撕裂就是指本应该分为两桢显示在屏幕上的图像同时显示在屏幕上,上半部分是一帧的上半部分,而下半部分是另外一帧的下半部分,情况严重的将导致屏幕出现闪烁(flicker)。
以一个刷新率为60Hz的显示器为例,显示控制器每隔1/60秒从前缓冲读取数据传给显示器。每开始新的一帧扫描时,显示控制器都从前缓冲的最左上角的点,即第一行的第一个点开始,逐行进行扫描,直到扫描到图像右下角的点,即最后一行的最后一个点。经过这样一个过程之后,就完成了一帧图像的扫描。然后显示控制器回溯(retrace)到第一行的第一个点的位置,等待下一帧扫描开始,如图8-10所示。
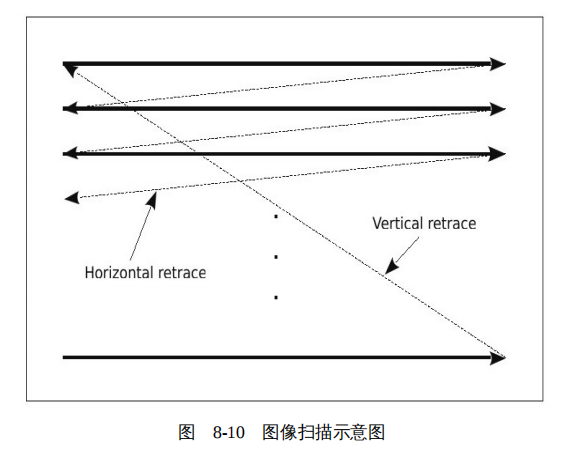
更新一帧图像远不需要1/60秒,从更新完最后一行的最右侧一个点,到开始扫描下一帧之间的间隙被称为垂直空闲(vertical blank),简称为"vblank"。显然,如果在vblank这段时间更新前缓冲,就不会导致上述撕裂和闪烁现象的出现了。
(3)交换的方法
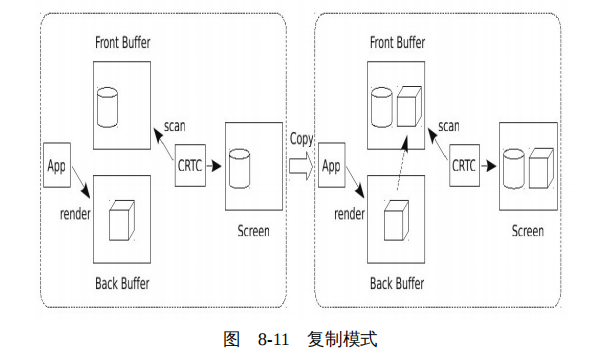
交换后缓冲和前缓冲通常有两种方法:第一是复制,在绘制完成后,X服务器将后缓冲中的数据复制到前缓冲,如图8-11所示。
但是这种方法效率相对较低,所以开发者们设计了页翻转模式(page flip)。页翻转模式不进行数据复制,而是将显示控制器指向后缓冲。后缓冲与前缓冲的角色进行互换,后缓冲摇身一变成为前缓冲,显示控制器将扫描后缓冲的数据到屏幕,而原来的前缓冲则变成了后缓冲,应用程序在前缓冲上进行绘制,如图8-12所示。
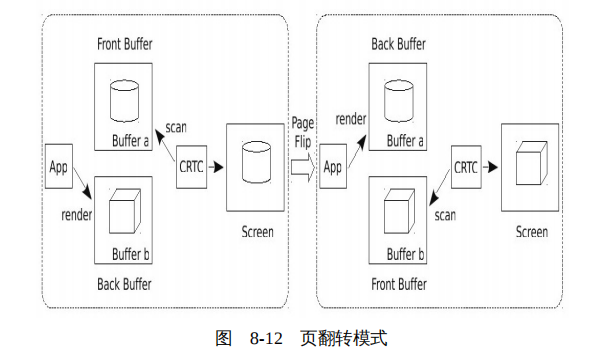
页翻转模式虽然效率高,但也不是所有的情况都适用。典型的,当一个应用处于全屏模式时,可以采用页翻转模式互换前缓冲和后缓冲。但是这对于使用复合管理器的图形系统来说,其实已经大大的提升效率了,因为复合管理器控制着整个屏幕的显示,所以复合管理器可以使用页翻转模式交换前缓冲和后缓冲。
- 应用发送交换请求
- X服务器处理交换请求
五、Wayland
将所有图形全部交由 X 服务器绘制的这种设计,在以2D应用为主的时代,一切还相安无事。但是随着基于3D的应用越来越多,效率问题逐渐凸显出来。与2D程序不同,3D程序的数据量要大得多,所以应用与X服务器之间需要传递大量的数据。设想一下几个人过独木桥和万人争过独木桥的场景,显然,X曾经引以为傲的设计——通过网络通信的客户/服务器架构,成为性能的瓶颈。
为了解决这个问题,X的开发者们设计了DRI机制,即应用程序不再将绘制图形的请求发送给X服务器,而是由应用程序自行绘制。这种设计与X最初的设计原则虽然有些格格不入,但是从某种程度上确实缓解了3D应用的效率问题。
但是,好景不长,人们逐渐不再满足于看上去比较“呆板”的图形用户界面,人们追求具有更华丽的3D特效的图形用户界面,比如窗口弹出和关闭时的放大/缩小动画、窗口之间的透明等。于是开发者们为 X 设计了复合( Composite ) 扩展,并仿效窗口管理器设计了一个所谓的复合管理器(Composite Manager)来实现这些效果。
我们以2D绘制过程为例来简要地看一下什么是复合扩展以及复合管理器,如图8-13所示。
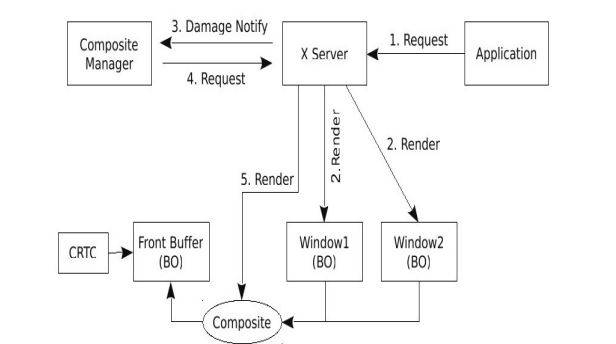
开启复合扩展后,最大的一个区别是所有的窗口都不再共享一个前缓冲,而是有了各自的离屏区域。X服务器在各个窗口的离屏区域上进行绘制。在绘制好后,X服务器向另外一个特殊的应用复合管理器(Composite Manager)发出Damage通知。然后由复合管理器请求X服务器对这些离屏的窗口的缓冲区进行合成,最后请求X服务器显示到前缓冲。
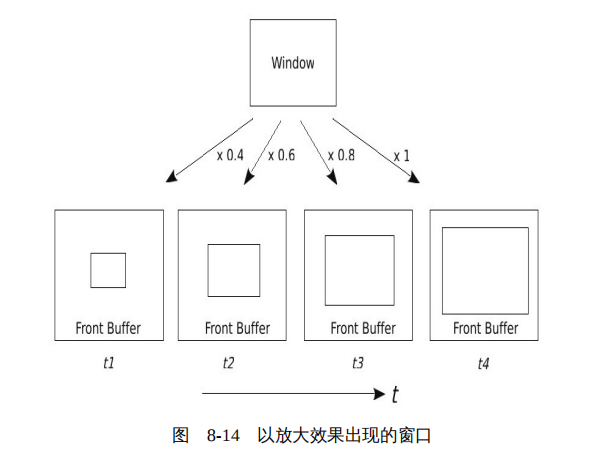
在这个复合过程中,就是制造那些绚丽效果的地方。比如在合成的过程中,我们使用如图8-14的方法,就可以使窗口看起来是以放大效果出现的。
使用复合管理后,绚丽的效果有了,但是仔细观察图8-13会发现,X被人诟病的基于网络通信的客户/服务器模式的问题又变得严重了。除了X服务器和应用之间的通信外,为了进行合成,X服务器和复合管理器之间又多了一层通信关系。
事实上,在DRI的演进过程中,X不断被拆分和瘦身,开发者从X中移除了大量与渲染有关的功能到内核和各种程序库中。慢慢的,人们发现,X所做的事情已经大为减少,替代X已经不是一项不可能的任务。于是一部分开发者开始尝试为Linux开发替代X的窗口系统,Kristian Høgsberg提出了Wayland。事实上,这一个过程迟早要发生的,即使不是Wayland,也会涌现出如Yayland、Zayland等。
Wayland并不是一个全新的事物,它是站在X这个巨人的肩膀上,在X的不断演进中进化而来的。虽然从名字上看,Wayland与X没有丝毫相干,但是实际上两者的联系可谓千丝万缕。Wayland的开发者Kristian Høgsberg曾经是X的DRI
的主要开发者之一。套用一句奔驰的广告语,“经典是对经典的继承,经典是对经典的背叛”,Wayland去掉了X的客户/服务器架构,但是继承了X为提高绘制效率不懈努力的成果:DRI。除了逻辑上设计上不同外,Wayland基本的渲染原理与我们前面讨论的2D和3D的渲染原理完全相同。基本上,基于Wayland的图形架构如图8-15所示。
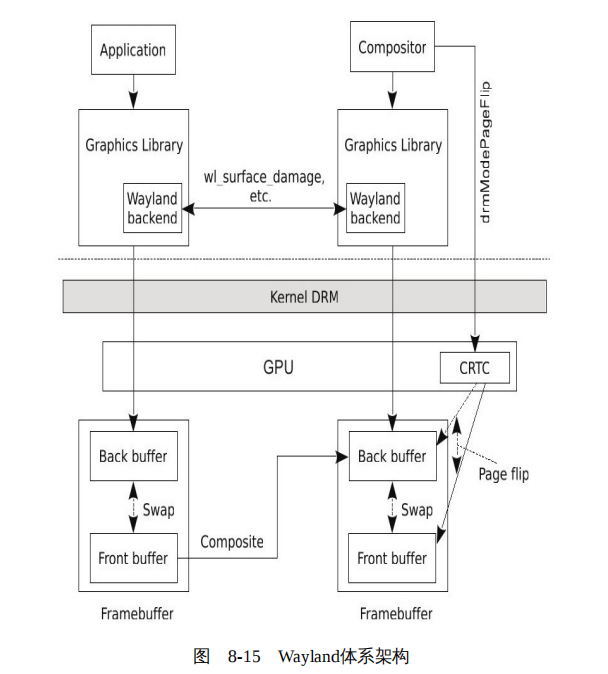
Wayland本身是一个协议,其具体的实现包括一个合成器(Compositor)以及一套协议实现库。当然,图形库为了与合成器进行通信,在图形库中需要加入Wayland协议的相关模块,也就是图8-15中的Wayland backend部分,当然这些都可以基于Wayland提供的库,而不必从头再将wayland协议实现一遍。
在Wayland下,所有的图形绘制完全由应用自己负责。其绘制过程与我们前面讨论的2D和3D的绘制过程完全相同,只不过2D的绘制部分也搬到图形库中了,绘制动作与合成器没有丝毫关系。而在绘制后,应用将前缓冲和后缓冲进行对调,并向合成器发送Damage通知,当然颜色缓冲不一定是前后两个,在具体实现中,有的图形系统可能使用3个、4个甚至更多。在收到Damage通知后,合成器将应用的前缓冲合成到自己的后缓冲中。而合成器的这个合成过程,与普通应用的绘制过程并无本质区别,也是通过图形库完成。
在合成完成后,合成器对调后缓冲与前缓冲,并设置显示控制器指向新的前缓冲,即原来的后缓冲。此前的前缓冲作为新的后缓冲,并作为合成器下一次合成的现场;而原来的后缓冲则变成现在的前缓冲,用于显示控制器的扫描输出。
光盘下载地址:http://pan.baidu.com/s/1o6p43O2