为什么大多数介绍大语言模型 RLHF 的文章,一讲到 PPO 算法的细节就戛然而止了呢?要么直接略过,要么就只扔出一个 PPO 的链接。然而 LLM x PPO 跟传统的 PPO 还是有些不同的呀。
其实在 ChatGPT 推出后的相当一段时间内,我一直在等一篇能给我讲得明明白白的文章,但是一直未能如愿。我想大概是能写的人都没时间写吧。
前几个月,自己在工作中遇到要用到 PPO 的场景了。我心想,干脆自己啃算了。
于是我找到了 InstructGPT 引用的 OpenAI 自家的大语言模型 RLHF 论文《fine-tuning language models from human preferences》和《learning to summarize from human feedback》的源码,逐行阅读。然后用近似但不完全相同的风格复现了一遍。后来又和同事一起把自己的实现和微软的 DeepSpeed-Chat 的实现相互印证,才算是理解了。
既然已经有了一些经验,为何不将它分享出来呢?就当是抛砖引玉吧。万一写的不对,也欢迎大家一起交流讨论。
由于本文以大语言模型 RLHF 的 PPO 算法为主,所以希望你在阅读前先弄明白大语言模型 RLHF 的前两步,即 SFT Model 和 Reward Model 的训练过程。另外因为本文不是纯讲强化学习的文章,所以我在叙述的时候不会假设你已经非常了解强化学习了。只是如果完全没有了解过,你可能会觉得有些操作看上去没有那么显然。但只要你非常了解语言模型和深度学习,应该不会影响你把整个流程给捋顺。
接下来,我会把大语言模型 RLHF 中的 PPO 分成三部分逐一介绍。这三部分分别是采样、反馈和学习。
技术交流
建了技术交流群!想要进交流群、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
资料1

资料2
在开始之前,我先用一段伪代码把三部分的关系简要说明一下(先建立一个印象,看不懂也没关系,后面自然会看懂):
policy_model = load_model()for k in range(20000):# 采样(生成答案)prompts = sample_prompt()data = respond(policy_model, prompts)# 反馈(计算奖励)rewards = reward_func(reward_model, data)# 学习(更新参数)for epoch in range(4):policy_model = train(policy_model, prompts, data, rewards)对于其中的每部分我都会用计算图来辅助描述,然后还会根据我的描述更新这段伪代码。
好了,让我们开始这趟旅程吧~

大语言模型的 RLHF,实际上是模型先试错再学习的过程。
我们扮演着老师的角色,给出有趣的问题,而模型则会像小学生一样,不断尝试给出答案。模型会对着黑板写下它的答案,有时候是正确的,有时候会有错误。我们会仔细检查每一个答案,如果它表现得好,就会给予它高声赞扬;如果它表现不佳,我们则会给予它耐心的指导和反馈,帮助它不断改进,直到达到令人满意的水平。
采样
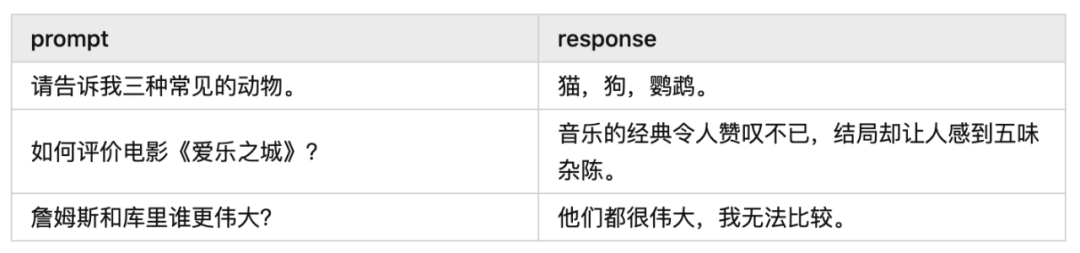
采样就是学生回答问题的过程,是模型根据提示(prompt)输出回答(response)的过程,或者说是模型自行生产训练数据的过程。
例如:
PPO 在这一部分做了什么呢?
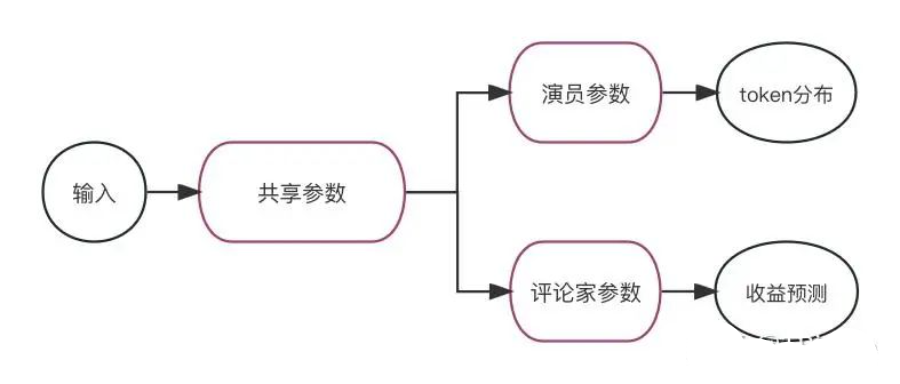
先明确一个概念——策略(policy),它就是 RLHF 中的“学生”。policy 由两个模型组成,一个叫做演员模型(Actor),另一个叫做评论家模型(Critic)。它们就像是学生大脑中的两种意识,一个负责决策,一个负责总结得失。
其中演员就是我们想要训练出来的大模型。在用 PPO 训练它之前,它就是 RLHF 的第一步训练出来的 SFT (Supervised Fine-Tuning) model。输入一段上下文,它将输出下一个 token 的概率分布 context 。评论家是强化学习的辅助模型,输入一段上下文,它将输出下一个 token 的“收益"。
什么是“收益”呢?简单来说就是从下一个 token 开始,模型能够获得的总奖励(浮点数标量)。这里说的奖励包括 Reward Model 给出的奖励。奖励是怎么给的,以及收益有什么用,这些内容我们后面会详细介绍。
▲ policy模型结构
从实现上说,评论家就是将演员模型的倒数第二层连接到一个新的全连接层上。除了这个全连接层之外,演员和评论家的参数都是共享的(如上图)。
上面提到的模型结构是较早期的版本,后续不共享参数的实现方式也有很多。
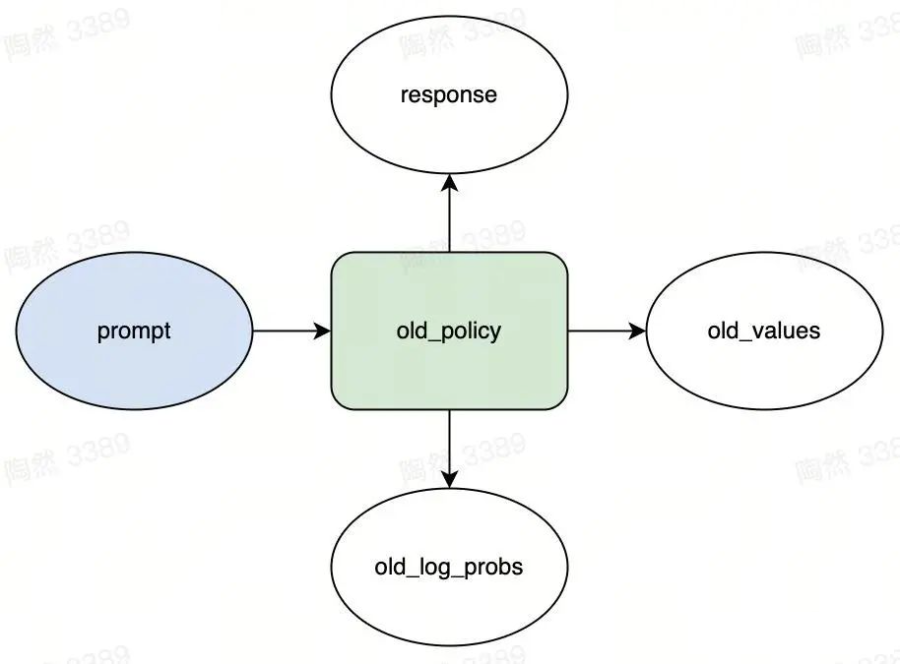
现在我们来看看 PPO 的采样过程中有哪些模型和变量。如下图,矩形表示模型,椭圆表示变量。
▲ 采样流程(转载须引用)
图中的“old_policy”矩形就是刚刚说的 policy(为啥有个“old”前缀呢?后面我会详细解释)。
采样指的是 old_policy 从 prompt 池中抽出 M 个 prompt 后,对每个 prompt 进行语言模型的 token 采样:
-
计算 response 的第 1 个 token 的概率分布,然后从概率分布中采样出第 1 个 token
-
根据第 1 个 token,计算 response 的第 2 个 token 的概率分布,然后从概率分布中采样出第 2 个 token
-
……
-
根据前 N-1 个 token,计算 response 的第 N 个 token 的概率分布,然后从概率分布中采样出第 N 个 token

▲ 语言模型的token采样
然后就得到了三个输出。假设对每个 prompt,policy 生成的 token 的个数为 N,那么这三个输出分别是:
-
response:M 个字符串,每个字符串包含 N 个 token
-
old_log_probs:演员输出的 M × N 的张量,包含了 response 中 token 的对数概率 log(p(token|context))
-
old_values:评论家输出的 M × N 的张量,包含了每次生成 token 时评论家预估的收益
得到这三个输出后,采样阶段就就结束了。这三个输出都是后续阶段重要的输入数据。
我们先将采样部分的伪代码更新一下:
# 采样
prompts = sample_prompt()
responses, old_log_probs, old_values = respond(policy_model, prompts)
就像是一场考试,学生已经完成了答题环节,他们在黑板上留下了答案。但这只是整个学习过程的一个环节,接下来是关键的反馈步骤。
反馈
反馈就是老师检查答案的过程,是奖励模型(Reward Model)给 response 打分的过程,或者说是奖励模型给训练数据 X 标上 Y 值的过程。
打出的分数衡量了 response 的正确性,它也可以被视为 prompt 和 response 的匹配程度。
例如:
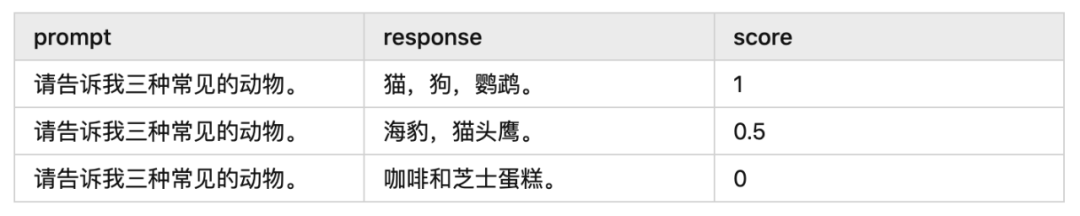
Reward Model 可以被比作班级里成绩最好的学生,他能够辅助老师批改作业。就像老师先教会这个学生如何批改作业,之后这个学生就能独立完成作业批改一样,Reward Model 通过学习和训练,也能够独立地完成任务并给出正确的答案。
网上有很多资料介绍 Reward Model 的训练过程,这也不是本文的重点,我就不再赘述了。
PPO 拿训练好的 Reward Mode 做了什么呢?我们接着看图说话:
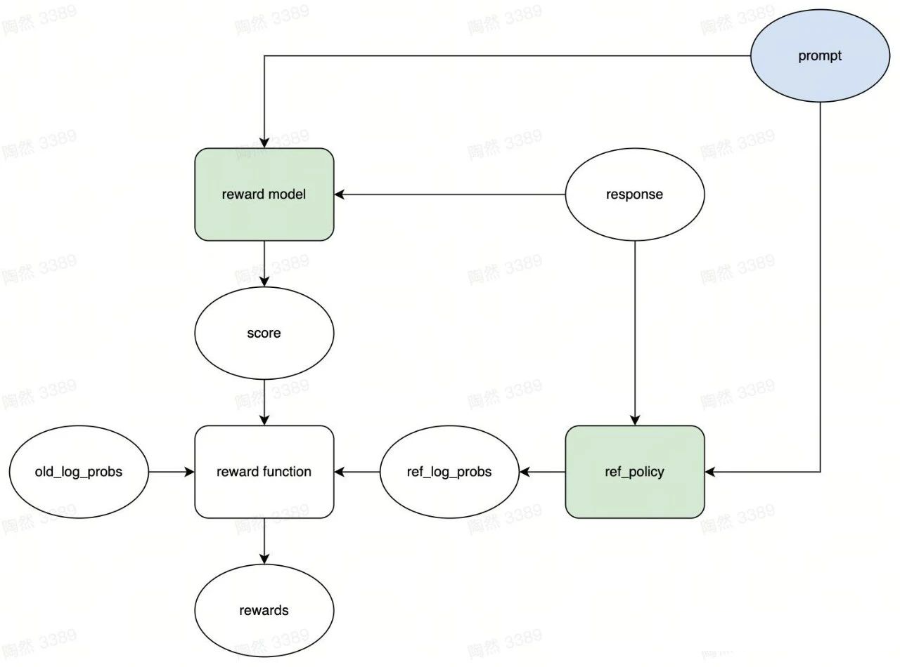
▲ 奖励流程(转载须引用)
从图中我们可以看出,左上角的绿色矩形 reward model 拿到 prompt 和 response,然后输出了分数 score。实际上发生的事情是,prompt 和 response 被拼接成一个字符串,接着被送入到 reward model 中,最后 reward model 计算出了匹配分数。
你也许发现了,在图中,score 并不是最终的奖励。它和最终的奖励 rewards 之间还隔着一个 reward function 函数。
这是因为 score 只能衡量结果的对错,不能衡量过程的合理性。怎么衡量过程的合理性呢?一种简单粗暴的方法是:循规蹈矩,即为合理。

当年爱因斯坦的相对论理论首次发表时,遭遇了许多质疑。后来,该理论被证明并得到了应有的认可。大家的目光可能都聚焦于爱因斯坦是如何坚定不移地坚持自己的理念并获得成功的。
然而,你有没有想过,那些反对和质疑其实也是必要的。
在相对论理论出现之前,已经有一个相对完整的物理系统。当时,一个年轻人突然出现挑战这个系统。在不知道他的路数的情况下,有必要基于现有的经验给予适当的质疑。因为并非每个人都是伟人啊。如果他的理论真的得到验证,那么就是给予肯定和荣誉的时候了。
语言模型也是一样,在我们给予最终奖励之前,最好也对它的“标新立异”给予少量的惩罚(即刚刚说的质疑)。
怎么做呢?我们给它立一个规矩,只要它按照这个规矩来,就能获得少量奖励。而这个规矩就是我们在 SFT 阶段已经训练好的语言模型 ref_policy(图中右下角的绿色矩形),或者说是完全还没经过强化学习训练的语言模型。
过程合理性奖励的计算方式是这样的。ref_policy 拿到 prompt,然后给 old_policy 生成的 response 的每个 token 计算对数概率,得到一个张量 ref_log_prob。现在假设 old_policy 的演员模型生成了第 i 个 token,此时它应该获得的奖励为:
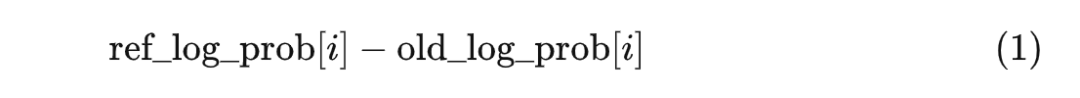
来理解一下这个式子:
-
ref_log_prob[i] 越高,ref_policy 越认可 old_policy 的输出,说明 old_policy 更守规矩,因此应该获得更高的奖励;
-
old_log_prob[i] 越高,old_policy 获得的奖励反而更低。old_log_prob[i] 作为正则项,可以保证概率分布的多样性。
有了这两个直觉上的解释,我们说式 (1) 是比较合理的。顺便说一句,熟悉信息论的人也许注意到了,式 (1) 是 KL 散度的简化版本。实际上式 (1) 完全可以改成计算两个 token 的概率分布的 KL 散度。这是另一个话题,就不延伸了。
最终,我们将过程合理性奖励和结果正确性奖励合并起来,就得到了最终奖励的计算方式。
注意,我们只在最后一个 token 上应用结果正确性奖励(reward_model 的输出)。也就是说,第 i 个 token 的奖励的计算方式为:
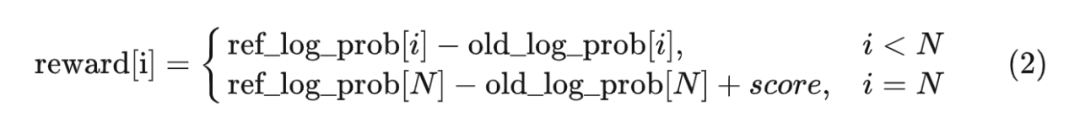
式 (2) 就是图中“reward function”的计算内容。
通俗来说,整个 reward function 的计算逻辑是典型的霸总逻辑:除非你能拿到好的结果,否则你就得给我守规矩。

注意,我们只对 response 计算奖励。另外在整个反馈阶段,reward_model 和 ref_policy 是不更新参数的。
一旦给出 reward,就完成了反馈阶段。现在我们将反馈部分的伪代码更新一下:
# 采样
prompts = sample_prompt()
responses, old_log_probs, old_values = respond(policy_model, prompts)# policy_model的副本,不更新参数
ref_policy_model = policy_model.copy()# 反馈
scores = reward_model(prompts, responses)
ref_log_probs = analyze_responses(ref_policy_model, prompts, responses)
rewards = reward_func(reward_model, scores, old_log_probs, ref_log_probs)这就像是老师在检查学生的答案并给出评价后,学生们就可以了解他们的表现如何,并从中学习和进步。然而,获得反馈并不是结束,而是新的开始。正如学生需要用这些反馈来进行复习和改进一样,模型也需要通过学习阶段来优化其性能和预测能力。
学习
“学习”就是学生根据反馈总结得失并自我改进的过程,或者说是强化优势动作的过程。
如果说前两步分别是在收集数据 X,以及给数据打上标签 Y。那么这一步就是在利用数据 (X, Y) 训练模型。
"强化优势动作"是 PPO 学习阶段的焦点。在深入探讨之前,我们首先要明确一个关键概念——优势。
此处,我们将优势定义为“实际获得的收益超出预期的程度”。
为了解释这个概念,请允许我举一个例子。假设一个高中生小明,他在高一时数学考试的平均分为 100 分,在此之后,大家对他的数学成绩的预期就是 100 分了。到了高二,他的数学平均分提升到了 130 分。在这个学期,小明的数学成绩显然是超出大家的预期的。
表现是可用分数量化的,故表现超出预期的程度也是可以用分数差来量化的。我们可以认为,在高二阶段,小明超出预期的程度为 30 分(130 - 100)。根据优势的定义我们可以说,在高二阶段,小明相对于预期获得了 30 分的优势。
在这个例子中,实际已经给出了 PPO 计算优势的方法:优势 = 实际收益 - 预期收益。
对于语言模型而言,生成第 i 个 token 的实际收益就是:从生成第 i 个 token 开始到生成第 N 个 token 为止,所能获得的所有奖励的总和。我们用 return 来表示实际收益,它的计算方式如下:
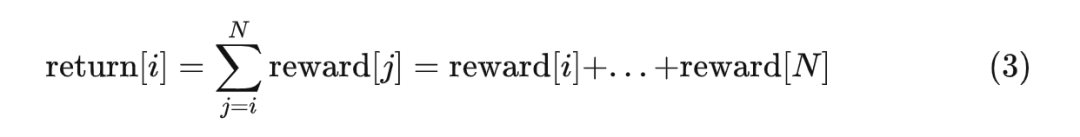
* 写给熟悉 RL 的人:简单起见,在这里我们既不考虑贴现也不计算广义优势估计 GAE
预期收益又该如何计算呢? 记得我们在“采样”阶段提到过,policy 包含演员模型和评论家模型,其中后者是用来预估收益的。其实,当时说的收益 old_values 就是现在我们想要计算的预期收益。评论家会为 response 中的每个 token 计算一个预期收益,第 个预期收益记为 values[i] (它预估的是刚才提到的 )。
现在,我们可以这样计算生成第 i 个 token 的优势 a(这里我们使用采样阶段计算出来的 old_values):
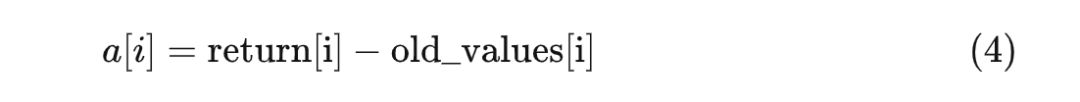
好的,我们已经理解了优势的含义了。现在终于可以揭开这个关键主题的面纱——在 PPO 学习阶段,究竟什么是"强化优势动作"。
所谓“强化优势动作”,即强化那些展现出显著优势的动作。
在上面的小明的例子中,这意味着在高三阶段,小明应该持续使用高二的学习方法,因为在高二阶段,他的学习策略展示出了显著的优势。
在语言模型中,根据上下文生成一个 token 就是所谓的“动作”。"强化优势动作"表示:如果在上下文(context)中生成了某个 token,并且这个动作的优势很高,那么我们应该增加生成该 token 的概率,即增加 p(token|context) 的值。
由于 policy 中的演员模型建模了 p(token|context),所以我们可以给演员模型设计一个损失函数,通过优化损失函数来实现“强化优势动作”:
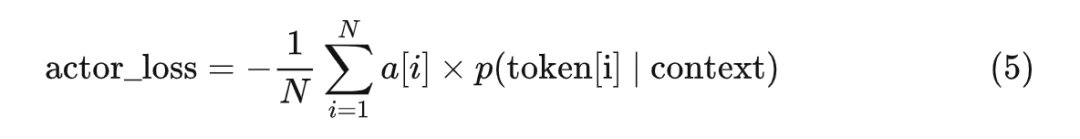
其中:
-
当优势大于 0 时,概率越大,loss 越小;因此优化器会通过增大概率(即强化优势动作)来减小 loss
-
当优势小于 0 时,概率越小,loss 越小;因此优化器会通过减小概率(即弱化劣势动作)来减小 loss
这很像巴浦洛夫的狗不是吗?
▲ 巴浦洛夫的狗
另外还有两个点值得注意:
-
优势的绝对值越大,loss 的绝对值也就越大
-
优势是不接收梯度回传的
实际上,式 5 只是一个雏形。PPO 真正使用的演员的损失函数是这样的:
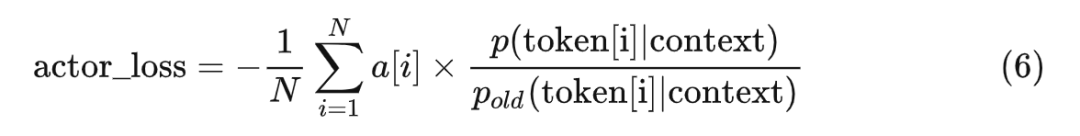
* 写给熟悉 RL 的人:简单起见,在这里我们既不考虑损失的截断,也不考虑优势的白化。
式子 6 相比式 5 子多了一个分母 。在式子 6 里, 表示 的一个较老的版本。因为它不接收梯度回传,所以我们可以将 当作常量,或者说,把它当成 的学习率的一部分。我们来分析一下它的作用。以优势大于 0 的情况为例,对任意 ,当 有较大的值的时候, 的参数的学习率更小。
直观来说,当生成某个 token 的概率已经很大了的时候,即便这个动作的优势很大,也不要再使劲增大概率了。或者更通俗地说,就是步子不要迈得太大。
现在的问题就是,我们应该使用 p 的哪个老版本。还记得我们在本文开头时给出的伪代码吗(后来在介绍“采样”和“反馈”阶段时又各更新了一次),我们对着代码来解释:
policy_model = load_model()
ref_policy_model = policy_model.copy()for k in range(20000):# 采样(已更新)prompts = sample_prompt()responses, old_log_probs, old_values = respond(policy_model, prompts)# 反馈(已更新)scores = reward_model(prompts, responses)ref_log_probs = analyze_responses(ref_policy_model, prompts, responses)rewards = reward_func(reward_model, scores, old_log_probs, ref_log_probs)# 学习for epoch in range(4):policy_model = train(policy_model, prompts, responses, old_log_probs, old_values, rewards)
简单来说,这段代码做的事情是:迭代 2 万次。在每次迭代中,通过采样和反馈得到一份数据,然后在学习阶段使用数据微调语言模型。每份数据我们都拿来训练 4 个 epoch。
那 使用 2 万次迭代开始之前的演员模型的参数可以吗?不行,那个版本过于老了(实际上就是 SFT,我们已经在奖励阶段中的 ref_policy 中用过了)。不妨使用同一次迭代的还未进入学习阶段的演员模型吧。如果是这样的话,仔细一看, 不就是采样阶段得到的 old_log_probs 吗?只是少了一个对数而已。
这就是为什么我们在采样阶段,对所有的模型和参数都使用“old”前缀,就是为了区分模型和变量的版本。
(补充:前面提到的 old_policy 指的是上面伪代码中采样出 old_log_probs 的那个时刻的 policy_model)
而对于 我们可以使用实时的演员模型的参数计算出来,然后用 log_prob 来表示它。于是,我们可以将式子 6 改写成以下形式:
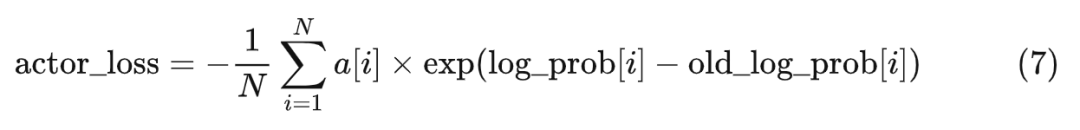
至此,我们完整地描述了 PPO 的学习阶段中“强化优势动作”的方法。就像下面的计算图展示的那样(policy 与前面的图中的 old_policy 不一样,是实时版本的模型)。
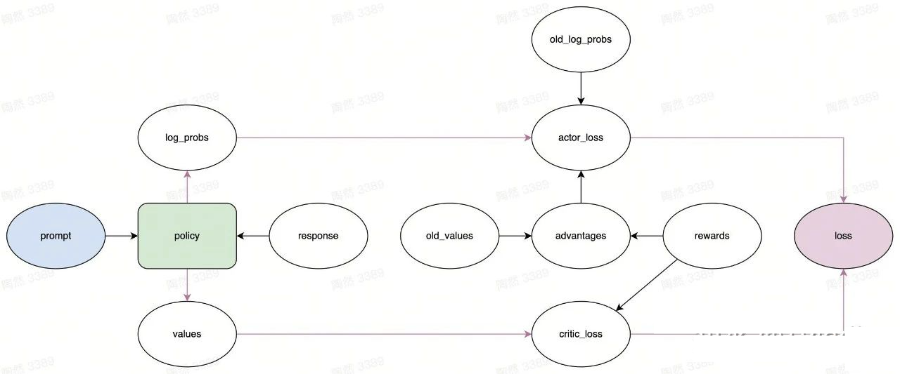
▲ 学习流程(转载须引用)
等等,似乎还没完。图中还有一个叫 critic_loss 的没提到过的东西。
当然了,负责决策的演员需要学习,难道总结得失的评论家就不需要学习了?评论家也是需要与时俱进的嘛,否则画评家难道不怕再次错过梵高那样的天才?
前面我们提到过,评论家会为 response 中的每个 token 计算一个预期收益,第 个预期收益记为 values[i],它预估的是 。
既然如此,就设计一个损失函数来衡量评论家预期收益和真实收益之间的差距。
PPO 用的是均方差损失(MSE):
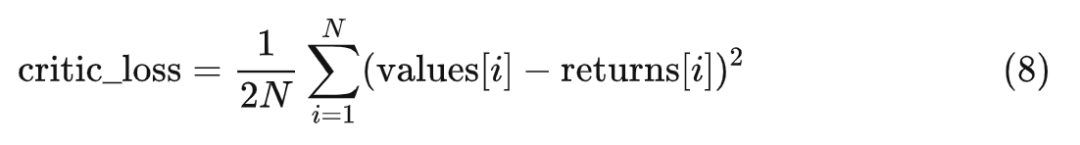
* 写给熟悉 RL 的人:由于我们不考虑 GAE,所以 returns 的计算也做了相应的简化。
最终优化 policy 时用的 loss 是演员和评论家的 loss 的加权和:

这才算是真正完事儿了。现在我们将整个 PPO 的伪代码都更新一下:
policy_model = load_model()
ref_policy_model = policy_model.copy()for k in range(20000):# 采样prompts = sample_prompt()responses, old_log_probs, old_values = respond(policy_model, prompts)# 反馈scores = reward_model(prompts, responses)ref_log_probs, _ = analyze_responses(ref_policy_model, prompts, responses)rewards = reward_func(reward_model, scores, old_log_probs, ref_log_probs)# 学习for epoch in range(4):log_probs, values = analyze_responses(policy_model, prompts, responses)advantages = advantage_func(rewards, old_values)actor_loss = actor_loss_func(advantages, old_log_probs, log_probs)critic_loss = critic_loss_func(rewards, values)loss = actor_loss + 0.1 * critic_losstrain(loss, policy_model.parameters())
总结
到这里,大语言模型 RLHF 中 PPO 算法的完整细节就算介绍完了。掌握这些细节之后,我们可以做的有趣的事情就变多了。例如:
-
你可以照着伪代码从头到尾自己实现一遍,以加深理解。相信我,这是非常有趣且快乐的过程
-
你可以以此为契机,把强化学习知识系统性地学一遍。你会发现很多强化学习的概念一下变得具象化了
-
你可以在你的产品或者研究方向中思考 PPO 是否可以落地
-
你也许会发现 PPO 算法的不合理之处,那么就深入研究下去,直到做出自己的改进
-
你可以跟周围不熟悉 PPO 的小伙伴吹牛,顺便嘲讽对方**(大误)**
总之,希望我们都因为掌握了知识变得更加充实和快乐~