文章目录
- 一、强化学习问题
- 1、交互的对象
- 2、强化学习的基本要素
- 3、策略(Policy)
- 4、马尔可夫决策过程
- 1. 基本元素
- 2. 交互过程的表示
- 3. 马尔可夫过程(Markov Process)
- 4. 马尔可夫决策过程(MDP)
- 5. 轨迹的概率计算
- 6. 给西瓜浇水问题的马尔可夫决策过程
一、强化学习问题
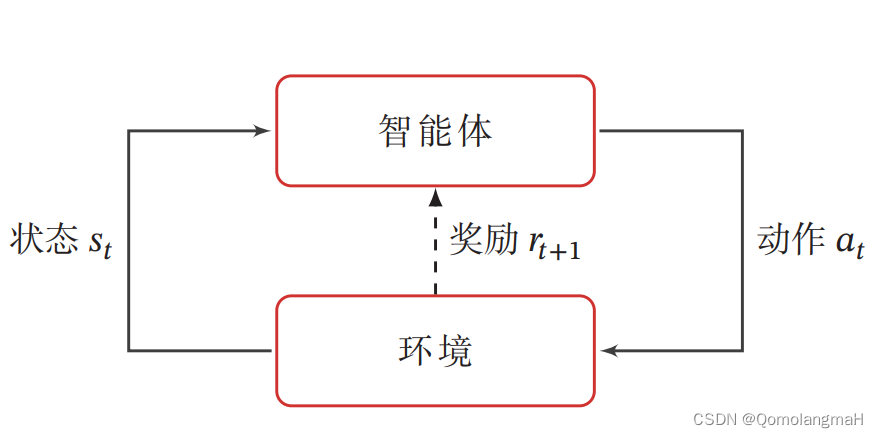
强化学习的基本任务是通过智能体与环境的交互学习一个策略,使得智能体能够在不同的状态下做出最优的动作,以最大化累积奖励。这种学习过程涉及到智能体根据当前状态选择动作,环境根据智能体的动作转移状态,并提供即时奖励的循环过程。
1、交互的对象
在强化学习中,有两个可以进行交互的对象:智能体和环境
-
智能体(Agent):能感知外部环境的状态(State)和获得的奖励(Reward),并做出决策(Action)。智能体的决策和学习功能使其能够根据状态选择不同的动作,学习通过获得的奖励来调整策略。
-
环境(Environment):是智能体外部的所有事物,对智能体的动作做出响应,改变状态,并反馈相应的奖励。
2、强化学习的基本要素
强化学习涉及到智能体与环境的交互,其基本要素包括状态、动作、策略、状态转移概率和即时奖励。
-
状态(State):对环境的描述,可能是离散或连续的。
-
动作(Action):智能体的行为,也可以是离散或连续的。
-
策略(Policy):智能体根据当前状态选择动作的概率分布。
-
状态转移概率(State Transition Probability):在给定状态和动作的情况下,环境转移到下一个状态的概率。
-
即时奖励(Immediate Reward):智能体在执行动作后,环境反馈的奖励。
3、策略(Policy)
策略(Policy)就是智能体如何根据环境状态 𝑠 来决定下一步的动作 𝑎(智能体在特定状态下选择动作的规则或分布)。
- 确定性策略(Deterministic Policy) 直接指定智能体应该采取的具体动作
- 随机性策略(Stochastic Policy) 则考虑了动作的概率分布,增加了对不同动作的探索。
上述概念可详细参照:【深度学习】强化学习(一)强化学习定义
4、马尔可夫决策过程
为了简化描述,将智能体与环境的交互看作离散的时间序列。智能体从感知到的初始环境 s 0 s_0 s0 开始,然后决定做一个相应的动作 a 0 a_0 a0,环境相应地发生改变到新的状态 s 1 s_1 s1,并反馈给智能体一个即时奖励 r 1 r_1 r1,然后智能体又根据状态 s 1 s_1 s1做一个动作 a 1 a_1 a1,环境相应改变为 s 2 s_2 s2,并反馈奖励 r 2 r_2 r2。这样的交互可以一直进行下去: s 0 , a 0 , s 1 , r 1 , a 1 , … , s t − 1 , r t − 1 , a t − 1 , s t , r t , … , s_0, a_0, s_1, r_1, a_1, \ldots, s_{t-1}, r_{t-1}, a_{t-1}, s_t, r_t, \ldots, s0,a0,s1,r1,a1,…,st−1,rt−1,at−1,st,rt,…,其中 r t = r ( s t − 1 , a t − 1 , s t ) r_t = r(s_{t-1}, a_{t-1}, s_t) rt=r(st−1,at−1,st) 是第 t t t 时刻的即时奖励。这个交互过程可以被视为一个马尔可夫决策过程(Markov Decision Process,MDP)。
1. 基本元素
-
状态( s t s_t st):
- 表示智能体与环境交互中的当前情况或环境状态。
- 在时间步𝑡时,智能体和环境的状态为 s t s_t st。
-
动作 ( a t a_t at):
- 表示智能体在给定状态 s t s_t st下采取的动作。
- 在时间步𝑡时,智能体选择执行动作 a t a_t at。
-
奖励 ( r t r_t rt):
- 表示在智能体采取动作 a t a_t at后,环境反馈给智能体的即时奖励。
- 在时间步𝑡时,智能体获得奖励 r t r_t rt。
2. 交互过程的表示
- 智能体与环境的交互过程可以用离散时间序列表示:
s 0 , a 0 , s 1 , r 1 , a 1 , … , s t − 1 , r t − 1 , a t − 1 , s t , r t , … , s_0, a_0, s_1, r_1, a_1, \ldots, s_{t-1}, r_{t-1}, a_{t-1}, s_t, r_t, \ldots, s0,a0,s1,r1,a1,…,st−1,rt−1,at−1,st,rt,…, - 在每个时间步,智能体根据当前状态选择一个动作,环境根据智能体的动作和当前状态发生转移,并反馈即时奖励。
- 这种时间序列描述强调了智能体和环境之间的交互,以及在时间步𝑡时智能体和环境的状态、动作和奖励。这符合马尔可夫决策过程的基本定义,其中马尔可夫性质要求当前状态包含了所有与未来预测相关的信息。
3. 马尔可夫过程(Markov Process)
-
定义: 马尔可夫过程是一组具有马尔可夫性质的随机变量序列 s 0 , s 1 , … , s t ∈ S s_0, s_1, \ldots, s_t \in \mathcal{S} s0,s1,…,st∈S,其中 S \mathcal{S} S 是状态空间。
-
马尔可夫性质: 当前状态 s t s_t st 对未来的预测只依赖于当前状态,而不依赖于过去的状态序列( s t − 1 , s t − 2 , … , s 0 s_{t-1}, s_{t-2}, \ldots, s_0 st−1,st−2,…,s0),即
p ( s t + 1 ∣ s t , … , s 0 ) = p ( s t + 1 ∣ s t ) p(s_{t+1} | s_t, \ldots, s_0) = p(s_{t+1} | s_t) p(st+1∣st,…,s0)=p(st+1∣st) -
状态转移概率 p ( s t + 1 ∣ s t ) p(s_{t+1} | s_t) p(st+1∣st): 表示在给定当前状态 s t s_t st 的条件下,下一个时刻的状态为 s t + 1 s_{t+1} st+1 的概率,满足 ∑ S t + 1 ∈ S p ( s t + 1 ∣ s t ) = 1 \sum_{S_{t+1} \in \mathcal{S}}p(s_{t+1} | s_t) = 1 ∑St+1∈Sp(st+1∣st)=1
4. 马尔可夫决策过程(MDP)
-
加入动作: MDP 在马尔可夫过程的基础上引入了动作变量 a t a_t at,表示智能体在状态 s t s_t st 时选择的动作。
-
状态转移概率的扩展: 在MDP中,下一个时刻的状态 s t + 1 s_{t+1} st+1 不仅依赖于当前状态 s t s_t st,还依赖于智能体选择的动作 a t a_t at:
p ( s t + 1 ∣ s t , a t , … , s 0 , a 0 ) = p ( s t + 1 ∣ s t , a t ) p(s_{t+1} | s_t,a_t, \ldots, s_0, a_0) =p(s_{t+1} | s_t, a_t) p(st+1∣st,at,…,s0,a0)=p(st+1∣st,at) -
马尔可夫决策过程的特点: 在MDP中,智能体的决策不仅受当前状态的影响,还受到智能体选择的动作的影响,从而更加适应需要制定决策的场景。
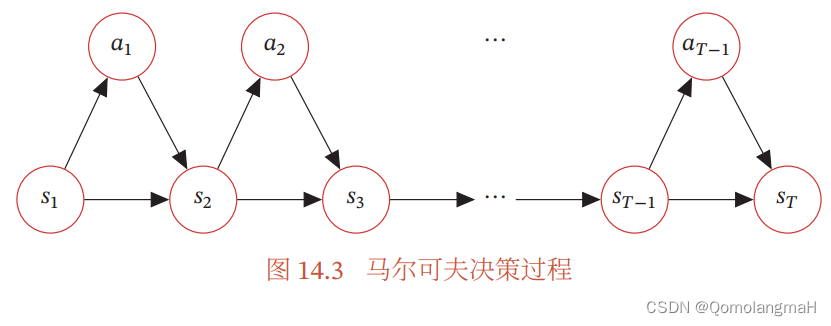
5. 轨迹的概率计算
-
轨迹表示: 给定策略 π ( a ∣ s ) \pi(a|s) π(a∣s),MDP的一个轨迹 τ \tau τ 表示智能体与环境交互的一系列状态、动作和奖励的序列:
τ = s 0 , a 0 , s 1 , r 1 , a 1 , … , s T − 1 , r T − 1 , a T − 1 , s T , r T , … , \tau=s_0, a_0, s_1, r_1, a_1, \ldots, s_{T-1}, r_{T-1}, a_{T-1}, s_T, r_T, \ldots, τ=s0,a0,s1,r1,a1,…,sT−1,rT−1,aT−1,sT,rT,…, -
概率计算公式:
p ( τ ) = p ( s 0 , a 0 , s 1 , r 1 , … ) p(\tau) = p(s_0, a_0, s_1, r_1, \ldots) p(τ)=p(s0,a0,s1,r1,…) p ( τ ) = p ( s 0 ) ∏ t = 0 T − 1 π ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p(\tau) = p(s_0) \prod_{t=0}^{T-1} \pi(a_t|s_t) p(s_{t+1}|s_t, a_t) p(τ)=p(s0)t=0∏T−1π(at∣st)p(st+1∣st,at)- p ( s 0 ) p(s_0) p(s0) 是初始状态的概率。
- π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st) 是策略:在状态 s t s_t st 下选择动作 a t a_t at 的概率。
- p ( s t + 1 ∣ s t , a t ) p(s_{t+1}|s_t, a_t) p(st+1∣st,at) 是在给定当前状态 s t s_t st 和动作 a t a_t at 的条件下,下一个时刻的状态为 s t + 1 s_{t+1} st+1 的概率(状态转移概率
)。
-
轨迹的联合概率:
- 通过对轨迹中每个时刻的概率连乘,得到整个轨迹的联合概率。
6. 给西瓜浇水问题的马尔可夫决策过程

在给西瓜浇水的马尔可夫决策过程中,只有四个状态(健康、缺水、溢水、凋亡)和两个动作(浇水、不浇水),在每一
步转移后,若状态是保持瓜苗健康则获得奖赏1 ,瓜苗缺水或溢水奖赏为- 1 , 这时通过浇水或不浇水可以恢复健康状态,当瓜苗凋亡时奖赏是最小值-100 且无法恢复。图中箭头表示状态转移,箭头旁的 a , p , r a,p,r a,p,r分别表示导致状态转移的动作、转移概率以及返回的奖赏.容易看出,最优策略在“健康”状态选择动作 “浇水”、在 “溢水”状态选择动作“不浇水”、在 “缺水”状态选择动作 “浇水”、在 “凋亡”状态可选择任意动作。