目录
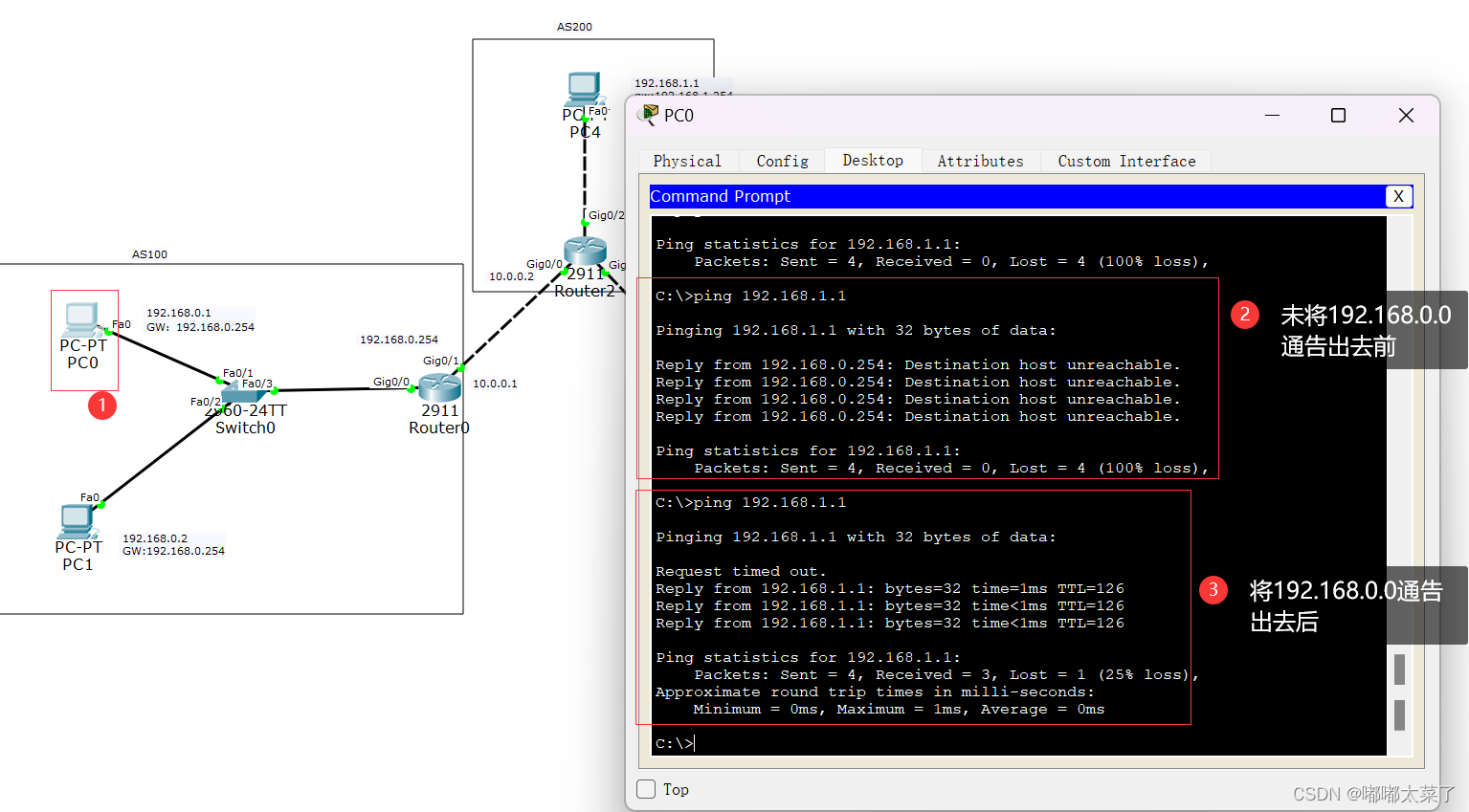
简介
特点
MPP数据库
PB和EB都是用来衡量数据存储量的单位。
秒级响应
Google Mesa
Apache Impala
支持标准sql且兼容mysql协议
ROLAP
OLAP(On-Line Analytical Processing,联机分析处理)
ROLAP(Relational On-Line Analytical Processing,关系型联机分析处理)
自动上卷
简单的部署模式
FE
BE
MGW
OLAP分析引擎对比
设计要点
range分区、hash分桶两级数据分布
Schema
多副本管理、副本自动均衡
两阶段提交
MVCC版本控制
MVCC(Multi-Version Concurrency Control)
Base Compaction
累积压缩(Cumulative Compaction)
读放大(Read Amplification)
写放大(Write Amplification)
空间放大(Space Amplification)
Doris使用LSM树
支持AggregateUniqDuplicate三种数据模型
什么是数据模型
3类数据模型
Doris导入基本原理
StreamLoad
SparkLoad
简介
特点
-
支持大数据量的分布式数据管理:MPP数据库
-
支持事务
-
对分析型查询友好
-
高吞吐
-
MPP数据库
分布式存储+分布式执行,提供大数据量的存储和计算能力
MPP(Massively Parallel Processing,大规模并行处理)数据库是一种分布式系统,它通过并行运行大量处理器或服务器来执行查询,从而实现高速、高吞吐量的数据处理。
在MPP数据库中,数据被分布在多个节点(服务器或处理器)上,每个节点都有自己的存储和计算资源。当执行查询时,查询会被分解成多个子查询,每个子查询在一个节点上并行执行。这样,大量的查询可以同时进行,大大提高了查询速度和系统吞吐量。
MPP数据库非常适合处理大数据,因为它可以轻松扩展到数百甚至数千个节点,处理PB级别的数据。此外,由于每个节点都有自己的存储和计算资源,因此MPP数据库具有很高的容错性。
PB和EB都是用来衡量数据存储量的单位。
- PB:PB是PetaByte的缩写,1PB等于1024TB(TeraBytes),也就是1,048,576GB(GigaBytes),或者说是1,125,899,906,842,624字节。
- EB:EB是ExaByte的缩写,1EB等于1024PB,也就是1,048,576TB,或者说是1,152,921,504,606,846,976字节。
这两个单位通常用于描述大数据存储和处理的规模。例如,一些大型互联网公司可能需要处理PB甚至EB级别的数据。
常见的MPP数据库有Greenplum、Redshift、Teradata、Vertica等。在开源领域,有ClickHouse、Doris等。
-
秒级响应
设计基于Google Mesa和Apache Impala,具有良好的查询性能
Google Mesa和Apache Impala都是大数据处理工具,但它们的设计目标和使用场景有所不同。
Google Mesa
Mesa是Google开发的一种高度可扩展的数据仓库系统,用于存储和查询大规模的结构化数据。Mesa的主要特点是能够提供一致性保证和高可用性,这使得它非常适合用于处理Google的广告业务等关键任务。Mesa支持PB级别的数据存储,并且可以处理来自全球数百万台服务器的更新请求。然而,Mesa并未开源,我们只能通过Google发布的论文来了解它的设计和实现。
Apache Impala
Impala是Apache Software Foundation开源的一种大数据查询工具,它提供了对Apache Hadoop数据的高性能、低延迟的SQL查询功能。Impala支持在Hadoop集群上进行交互式的分析查询,而无需将数据转移到其他系统或使用其他特定的查询引擎。Impala的主要优点是查询速度快,支持标准的SQL语法,以及与Hadoop生态系统的良好集成。
总的来说,Google Mesa和Apache Impala都是大数据处理的重要工具,但Mesa更注重数据的一致性和可用性,而Impala更注重查询的性能和与Hadoop的集成。
-
支持标准sql且兼容mysql协议
学习成本低,方便易用
-
ROLAP
相对于纯预计算系统,建模更灵活,同时消耗更少存储成本,提供更加丰富灵活的查询能力(如两大表JOIN等)
OLAP(On-Line Analytical Processing,联机分析处理)
是一种快速获取多维数据库信息的方法。它能够提供一种用户视图,使用户能够以一种直观的方式查看企业的全局,并能够进行复杂的分析。OLAP的主要功能包括:多维分析、钻取、切片和旋转等。
ROLAP(Relational On-Line Analytical Processing,关系型联机分析处理)
是OLAP的一种实现方式。ROLAP使用传统的关系数据库来存储和管理数据,以及进行计算。ROLAP的优点是可以处理大量的数据,而且可以使用SQL进行查询,易于理解和使用。但是,由于ROLAP依赖于关系数据库,因此其性能和可扩展性可能会受到数据库性能的限制。
总的来说,OLAP是一种分析处理的方法,而ROLAP是实现OLAP的一种技术。
-
自动上卷
用一定空间换取性能提升
简单的部署模式

FE
元数据管理、查询计划生成和下发、数据副本管理
FE(Master)通常不执行查询
BE
副本存储、查询计划执行、数据写入
MGW
负载均衡,转发客户端请求到FE
OLAP分析引擎对比

设计要点
-
range分区、hash分桶两级数据分布
一个分区有多个schema
副本总数=分区数*schema数*副本倍数
不同副本在不同机器上,如果机器数不满足分区分桶要求,建分区分桶失败
Schema
在数据库中指的是数据库的结构和组织方式,它定义了数据库中表的组织、表之间的关系、每个表中字段的属性等。简单来说,Schema就是数据库的蓝图,它描述了数据在数据库中如何存储和组织。
Schema的数量取决于数据库的设计和需求。在一个数据库中,可以有一个或多个Schema。例如,如果一个公司的不同部门需要使用不同的数据集,那么可能会为每个部门创建一个单独的Schema。每个Schema都有自己的命名空间,可以包含表、视图、索引、序列等数据库对象。
在实际应用中,Schema的数量没有固定的标准,完全取决于具体的业务需求和数据库设计。
-
多副本管理、副本自动均衡
集群扩容或BE宕机可能造成副本不均衡
-
两阶段提交
prepare-commit-published
-
MVCC版本控制

MVCC(Multi-Version Concurrency Control)
多版本并发控制,是一种常用的并发控制技术。它的主要目标是在保证数据一致性的同时,尽可能地提高数据库的并发性能。
在MVCC的设计中,每一条记录在数据库中不只有一份实例,同时存在多个版本,每个版本都有自己的版本号。当读取数据时,数据库会返回版本号最新且事务已经提交的数据,这样就避免了读操作等待写操作的情况,提高了并发性能。
当进行写操作(更新或删除)时,数据库并不直接覆盖原有记录,而是创建一个新的版本,同时保留旧的版本。这样,即使有新的写操作,读操作也可以继续读取旧的版本数据,避免了读写冲突。
MVCC的优点是提高了并发性能,减少了锁的竞争。但是,由于需要保存多个版本的数据,所以会占用更多的存储空间。
Base Compaction
是Doris数据库中的一种压缩策略,主要用于处理大量的小文件问题。在Doris中,数据被分成多个版本,每个版本都对应一个delta文件。当这些delta文件数量过多时,就会影响查询性能。
Base Compaction的工作原理是将多个小的delta文件合并成一个大的base文件,从而减少文件的数量。这个过程会对数据进行排序和重组,以提高查询效率。它是一个后台的、低优先级的任务,不会影响到正常的查询和写入操作。当系统空闲时,Base Compaction会自动运行,从而提高系统的整体性能。
Doris在进行Base Compaction后,原来的delta文件会被删除。这是因为Base Compaction的过程实际上是将多个小的delta文件合并成一个大的base文件,合并后的base文件已经包含了原来delta文件的所有数据,因此原来的delta文件就没有必要保留了,会被系统自动删除,以节省存储空间。
累积压缩(Cumulative Compaction)
是一种常见的压缩策略,主要用于LSM(Log-Structured Merge-tree)类型的数据库,如RocksDB和LevelDB等。这种策略的主要目标是减少存储空间的使用和写放大,但它可能会导致读放大。
在累积压缩中,数据被分成多个层级,每个层级都包含一些SSTable文件。当一个层级的数据量达到一定阈值时,就会将这个层级的数据和下一个层级的数据合并,形成新的SSTable文件。这个过程被称为Compaction。
Compaction可以有效地减少存储空间的使用,但是它可能会导致读放大。这是因为在读取数据时,可能需要在多个层级中查找数据,甚至可能需要读取多个SSTable文件。此外,由于Compaction过程中可能会产生新的SSTable文件,这也可能导致数据的物理位置发生变化,从而增加了数据读取的难度。
为了降低读放大,可以通过调整Compaction策略、优化数据布局、使用Bloom Filter等方法进行优化。
读放大(Read Amplification)
是一个描述在存储系统中,为了读取一定量的数据,实际需要读取的数据量的指标。这个概念通常用于描述基于LSM(Log-Structured Merge-tree)的数据库系统,如RocksDB和LevelDB等。
在LSM树型数据库中,数据被存储在多个层级(Level)的SSTable文件中。当进行数据读取时,可能需要在多个层级中查找数据,甚至可能需要读取多个SSTable文件,这就导致了读放大。
读放大会影响系统的读取性能和效率。为了降低读放大,可以通过调整Compaction策略、优化数据布局、使用Bloom Filter等方法进行优化。
写放大(Write Amplification)
写放大这是一个描述数据实际写入硬盘的量与应用程序写入的数据量之比的指标。在LSM树型数据库中,由于Compaction过程,同一份数据可能会被多次写入硬盘,从而导致写放大。写放大会影响硬盘的寿命和系统的写入性能。
空间放大(Space Amplification)
空间放大是一个描述硬盘上实际使用的空间与应用程序数据量之比的指标。在LSM树型数据库中,由于数据版本和删除标记的存在,硬盘上的实际数据量可能会大于应用程序的数据量,从而导致空间放大。空间放大会影响硬盘的使用效率和系统的存储成本。
为了降低写放大和空间放大,可以通过调整Compaction策略、优化数据布局、使用压缩技术等方法进行优化。
Doris使用LSM树
LSM(Log-Structured Merge Tree)是一种用于磁盘存储的数据结构,主要用于解决随机写入性能问题。LSM树最初是由Google的Bigtable使用的,现在已经被广泛应用于许多其他的存储系统,如LevelDB,RocksDB,Cassandra,HBase等。
LSM树的主要思想是将随机的写入操作转化为顺序的写入,从而大大提高了写入性能。在LSM树中,所有的写入操作首先会被存储在内存中的一个结构(通常是跳表或者红黑树)中,当这个结构的大小达到一定阈值时,就会将这个结构的数据写入到磁盘中。这样,大部分的写入操作都是在内存中进行的,只有少部分的写入操作会涉及到磁盘,从而大大提高了写入性能。
另外,LSM树还有一个合并(Compaction)的过程,这个过程会定期地在后台运行,将磁盘中的旧数据和新数据进行合并,删除无用的数据,从而保持磁盘的空间使用率。总的来说,LSM树是一种非常高效的磁盘存储结构,特别适合于写入操作比较频繁的场景。
在Doris中,LSM树被用于存储表的数据。当数据被插入到Doris中时,首先会被写入到内存中的MemTable中。当MemTable的大小达到一定阈值时,就会将MemTable的数据刷写到磁盘中,形成一个新的Segment。这些Segment会被组织成一个LSM树,以支持高效的数据查询和更新。同时,Doris还会定期地进行Compaction操作,将磁盘中的多个Segment合并成一个大的Segment,以提高查询性能和节省磁盘空间。
-
支持AggregateUniqDuplicate三种数据模型
什么是数据模型
数据模型定义了Doris副本在单个版本中的组织形式和多个版本在compaction和查询时的聚合方式。
数据主要包含维度(Key)和指标(Value)两种列,Key在前,Value在后。单个版本中,数据按Key排序放置,前36字节会构建前缀索引,查询条件落在前缀时,可极大加快查询速度。
3类数据模型
Aggregate模型:根据预定义的聚合函数,将含有相同key的数据聚合成一条数据。
Uniq模型:特殊的Aggregate模型,数据合并时,如遇到相同key的value,会使用高版本数据替换低版本数据。
Duplicate模型:也称之明细模型,数据按key排序,不作聚合,相同key的数据会全部保留下来。
Doris导入基本原理
StreamLoad
Kafka2Doris以及Hive2Doris的默认导入方式
SparkLoad
减小Doris压力,适用于大数据量的Hive2Doris