文章目录
- 说明
- 专家系统
- 机器学习
- 机器学习定义
- 工作流程
- 模型评估
- 机器学习分类
- 在这里插入图片描述
- 机器学习部分md内容
- 机器学习
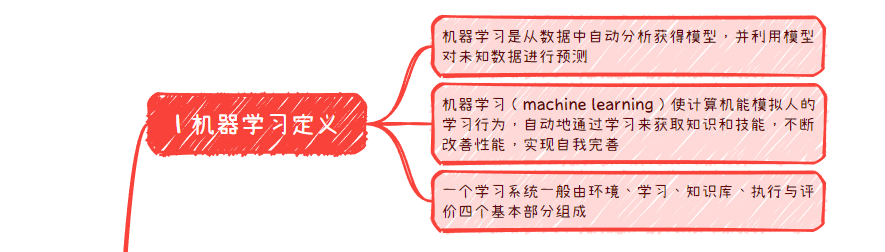
- 1 机器学习定义
- 机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测
- 机器学习(machine learning)使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善
- 一个学习系统一般由环境、学习、知识库、执行与评价四个基本部分组成
- 2 机器学习过程
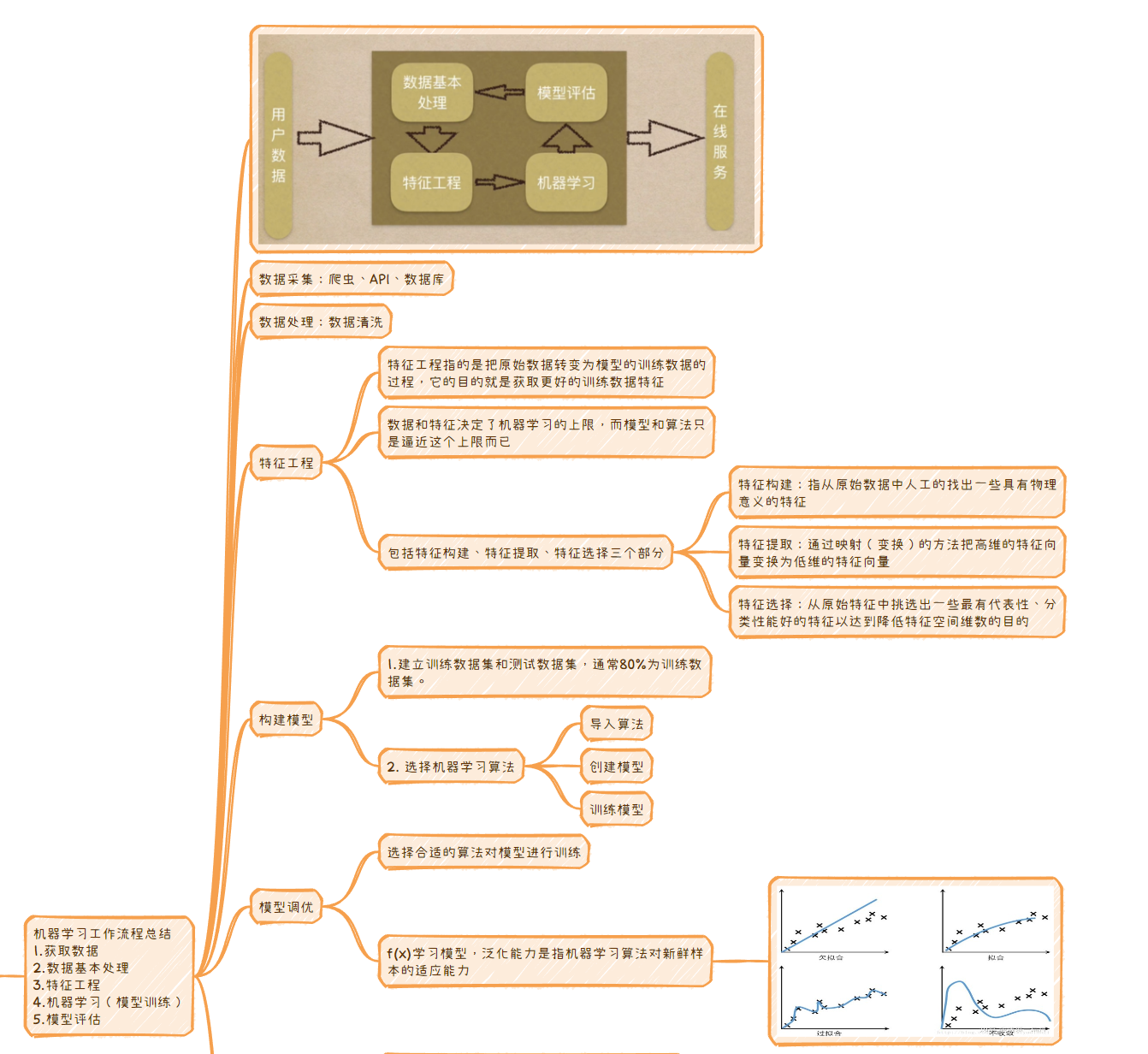
- 机器学习工作流程总结
- 3 机器学习分类
- 按照学习方式分
- 按照学习任务分
- 特征提取:将原始特征转换为一组具有明显物理意义或者统计意义或核的特征,特征提取会改变原来的特征空间。
说明
- 《人工智能导论》知识思维导图梳理【1~5章节
- 《人工智能导论》第七章知识思维导图梳理,本文整理相对重要的内容,助力快速复习和整体知识梳理。
- 这里由于是参考导论课程教材学习梳理,有关机器学习算法,并没有进行梳理
专家系统
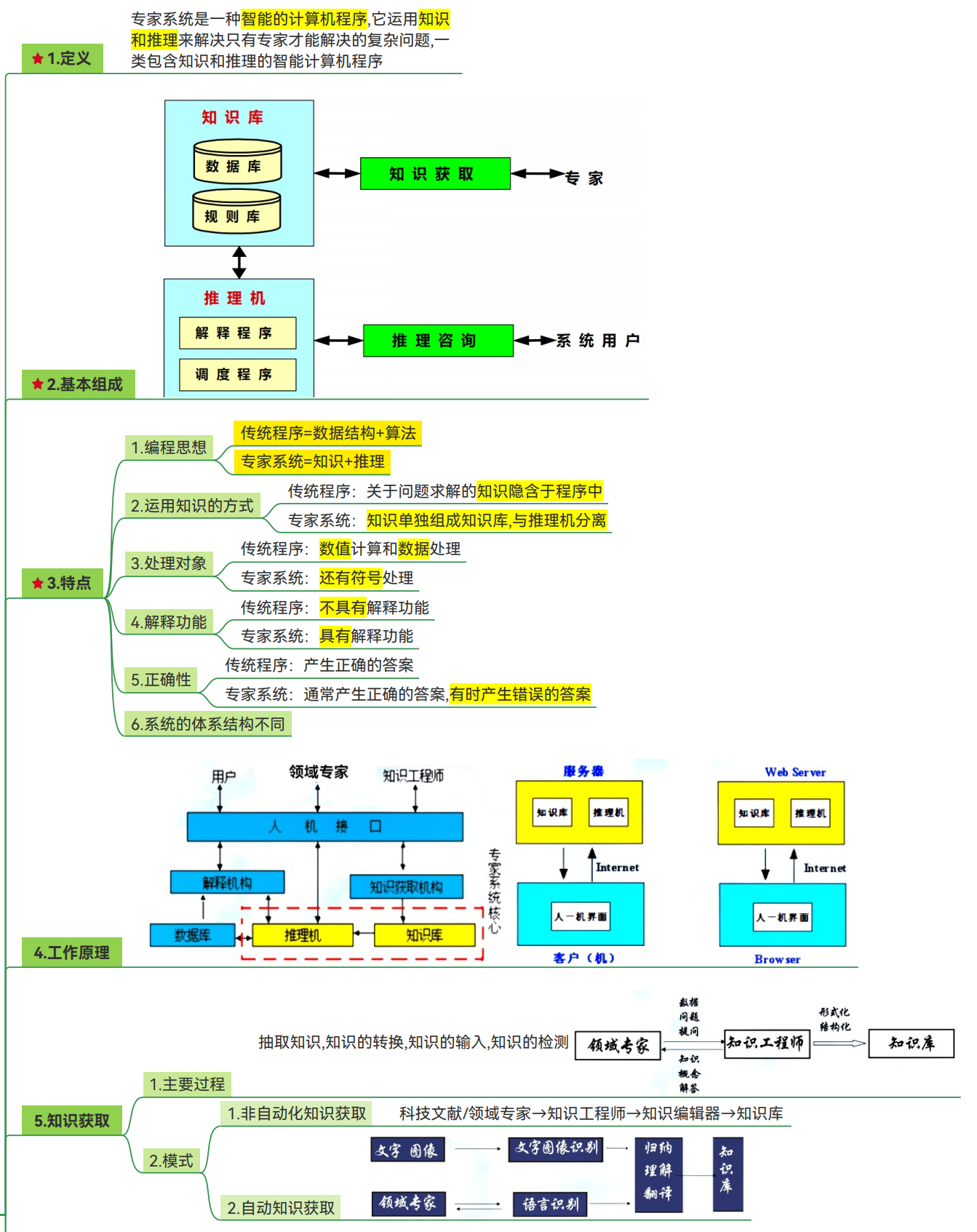
机器学习
机器学习定义
工作流程
模型评估
机器学习分类
机器学习部分md内容
- xmind的绘图使用以下的内容进行绘制,需要完善的同学可以直接拿去使用!
机器学习
1 机器学习定义
机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测
机器学习(machine learning)使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善
一个学习系统一般由环境、学习、知识库、执行与评价四个基本部分组成
2 机器学习过程
机器学习工作流程总结
1.获取数据
2.数据基本处理
3.特征工程
4.机器学习(模型训练)
5.模型评估
-
数据采集:爬虫、API、数据库
-
数据处理:数据清洗
-
特征工程
-
特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征
-
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
-
包括特征构建、特征提取、特征选择三个部分
-
特征构建:指从原始数据中人工的找出一些具有物理意义的特征
-
特征提取:通过映射(变换)的方法把高维的特征向量变换为低维的特征向量
-
特征选择:从原始特征中挑选出一些最有代表性、分类性能好的特征以达到降低特征空间维数的目的
-
-
-
构建模型
-
1.建立训练数据集和测试数据集,通常80%为训练数据集。
-
- 选择机器学习算法
-
导入算法
-
创建模型
-
训练模型
-
-
模型调优
-
选择合适的算法对模型进行训练
-
f(x)学习模型,泛化能力是指机器学习算法对新鲜样本的适应能力
-
-
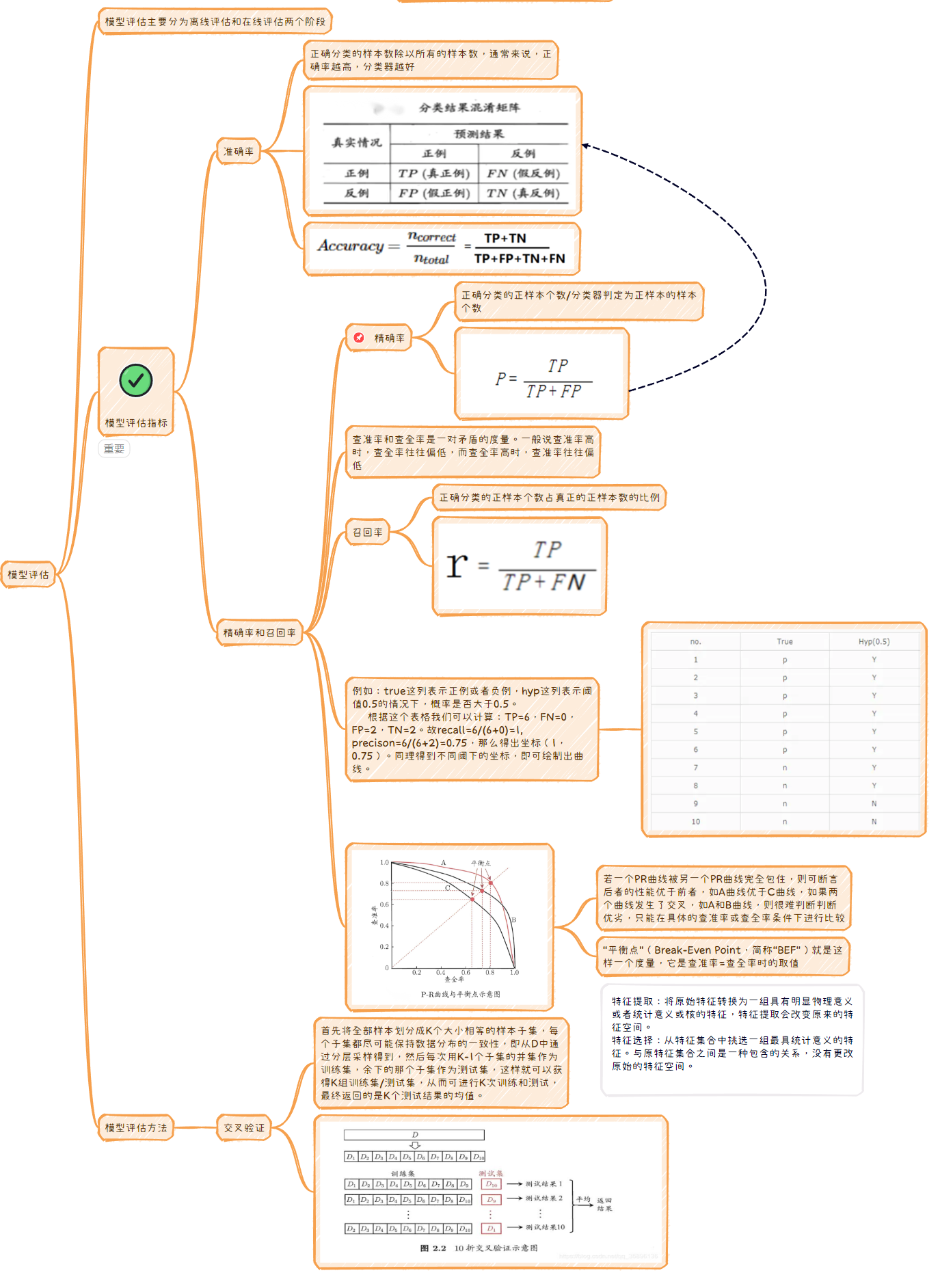
模型评估
-
模型评估主要分为离线评估和在线评估两个阶段
-
模型评估指标
-
准确率
- 正确分类的样本数除以所有的样本数,通常来说,正确率越高,分类器越好
-
精确率和召回率
-
精确率
- 正确分类的正样本个数/分类器判定为正样本的样本个数
-
查准率和查全率是一对矛盾的度量。一般说查准率高时,查全率往往偏低,而查全率高时,查准率往往偏低
-
召回率
- 正确分类的正样本个数占真正的正样本数的比例
-
例如:true这列表示正例或者负例,hyp这列表示阈值0.5的情况下,概率是否大于0.5。
根据这个表格我们可以计算:TP=6,FN=0,FP=2,TN=2。故recall=6/(6+0)=1,
precison=6/(6+2)=0.75,那么得出坐标(1,0.75)。同理得到不同阈下的坐标,即可绘制出曲线。-
若一个PR曲线被另一个PR曲线完全包住,则可断言后者的性能优于前者,如A曲线优于C曲线,如果两个曲线发生了交叉,如A和B曲线,则很难判断判断优劣,只能在具体的查准率或查全率条件下进行比较
-
“平衡点”(Break-Even Point,简称“BEF”)就是这样一个度量,它是查准率=查全率时的取值
-
-
-
-
模型评估方法
-
交叉验证
- 首先将全部样本划分成K个大小相等的样本子集,每个子集都尽可能保持数据分布的一致性,即从D中通过分层采样得到,然后每次用K-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得K组训练集/测试集,从而可进行K次训练和测试,最终返回的是K个测试结果的均值。
-
-
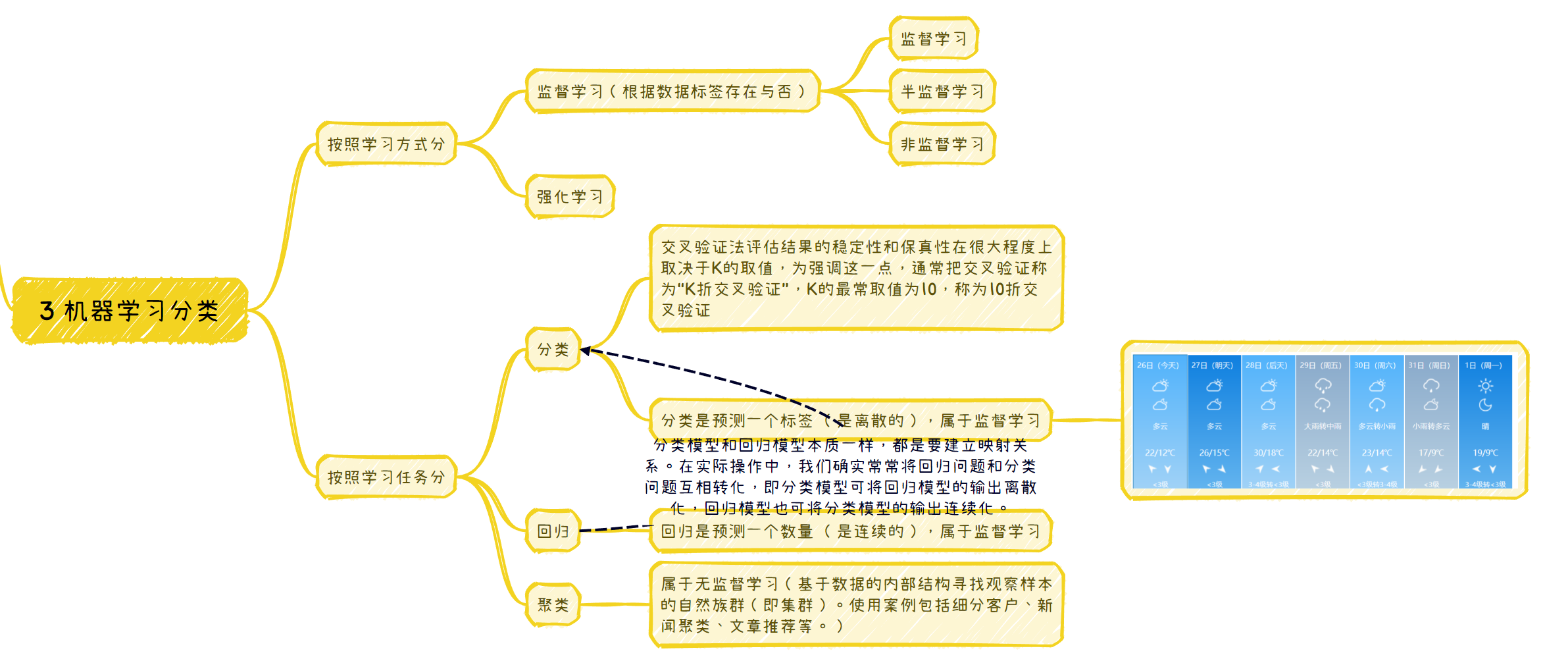
3 机器学习分类
按照学习方式分
-
监督学习(根据数据标签存在与否)
-
监督学习
-
半监督学习
-
非监督学习
-
-
强化学习
按照学习任务分
-
分类
-
交叉验证法评估结果的稳定性和保真性在很大程度上取决于K的取值,为强调这一点,通常把交叉验证称为“K折交叉验证”,K的最常取值为10,称为10折交叉验证
-
分类是预测一个标签 (是离散的),属于监督学习
-
-
回归
- 回归是预测一个数量 (是连续的),属于监督学习
-
聚类
- 属于无监督学习(基于数据的内部结构寻找观察样本的自然族群(即集群)。使用案例包括细分客户、新闻聚类、文章推荐等。)
特征提取:将原始特征转换为一组具有明显物理意义或者统计意义或核的特征,特征提取会改变原来的特征空间。
特征选择:从特征集合中挑选一组最具统计意义的特征。与原特征集合之间是一种包含的关系,没有更改原始的特征空间。