- 1、MapReduce概述
- 1.1 MapReduce定义
- 1.2 MapReduce优点
- 1.3 MapReduce缺点
- 1.4 MapReduce核心思想
- 1.5 MapReduce进程
- 1.6 常用数据序列化类型
- 1.7 源码与MapReduce编程规范
- 2、WordCount案例实操
- 2.1 本地测试
- 2.2 提交到集群测试
1、MapReduce概述
1.1 MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
1.2 MapReduce优点
1)MapReduce易于编程
==它简单的实现一些接口,就可以完成一个分布式程序,===这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
1.3 MapReduce缺点
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.4 MapReduce核心思想
现在有一个需求:要统计一个文件当中每一个单词出现的总次数(并将查询结果a-p字母保存一个文件,q-z字母保存一个文件),则可以按照图示步骤
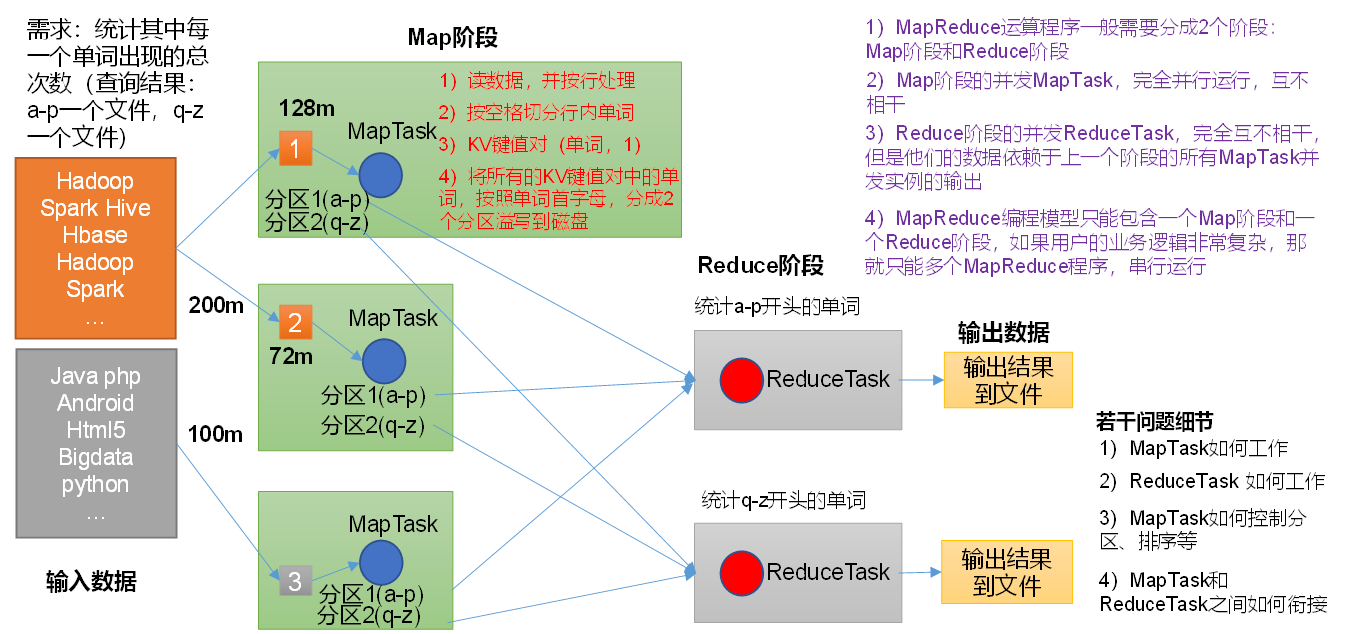
(1)分布式的运算程序往往需要分成至少2个阶段。map+reduce
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。统计次数,形成键值对,<H,1>、<S,1>、<H,1>,但是次数之间不相加。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。将统计的次数相加求和。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
1.5 MapReduce进程
mr、job、任务指的都是一个应用程序。例如:跑一个wordcount,可以说这是一个job或者任务。
未来在运行MapReduce程序的时候,会启动哪些进程呢?
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
1.6 常用数据序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
- 除了string,其他的都是在java类型的基础上加上writable
1.7 源码与MapReduce编程规范
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
源码如下:
package org.apache.hadoop.examples;import java.io.IOException;
import java.io.PrintStream;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static void main(String[] args)throws Exception{Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));System.exit(job.waitForCompletion(true) ? 0 : 1);}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException{int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}
}
- 上面一共有三个方法,分别是main方法,map方法和reduce方法。
- 定义一个类,继承mapper,之后重写里面的mapper方法,实现自己的业务逻辑。


MapReduce的编程规范如下:


2、WordCount案例实操
2.1 本地测试
1)需求
在给定的文本文件中统计输出每一个单词出现的总次数
(1)输入数据
(2)期望输出数据
wenxin 2
banzhang 1
cls 2
hadoop 1
jiao 1
ss 2
xue 1
- 可以发现上面的数据涉及首字母排序的问题。
2)需求分析
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver。

(1)创建maven工程,MapReduceDemo
(2)在pom.xml文件中添加如下依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>
</dependencies>
(2)在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(3)创建包名:com.wenxin.mapreduce.wordcount
Mapper的源码:
@Public
@Stable
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {public Mapper() {}protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {}protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {context.write(key, value);}protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {}public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {this.setup(context);try {while(context.nextKeyValue()) {this.map(context.getCurrentKey(), context.getCurrentValue(), context);}} finally {this.cleanup(context);}}public abstract class Context implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {public Context() {}}
}

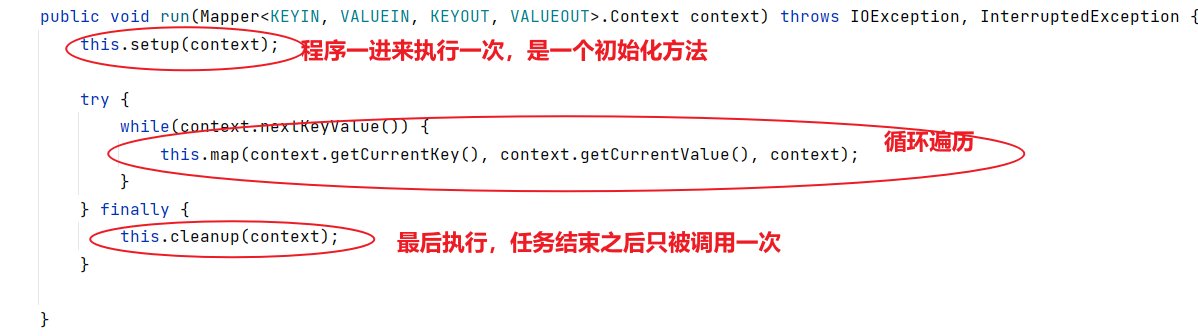
4)编写程序
(1)编写Mapper类
package com.wenxin.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;/*** @author Susie-Wen* @version 1.0* @description:* @date 2023/12/13 9:56*/
/*
KEYIN,map阶段输入的key的类型:LongWritable
VALUEINT,map阶段输入的value的类型:Text
KEYOUT,map阶段输出的Key的类型:Text
VALUEOUT,map阶段输出的value类型:IntWritable*/
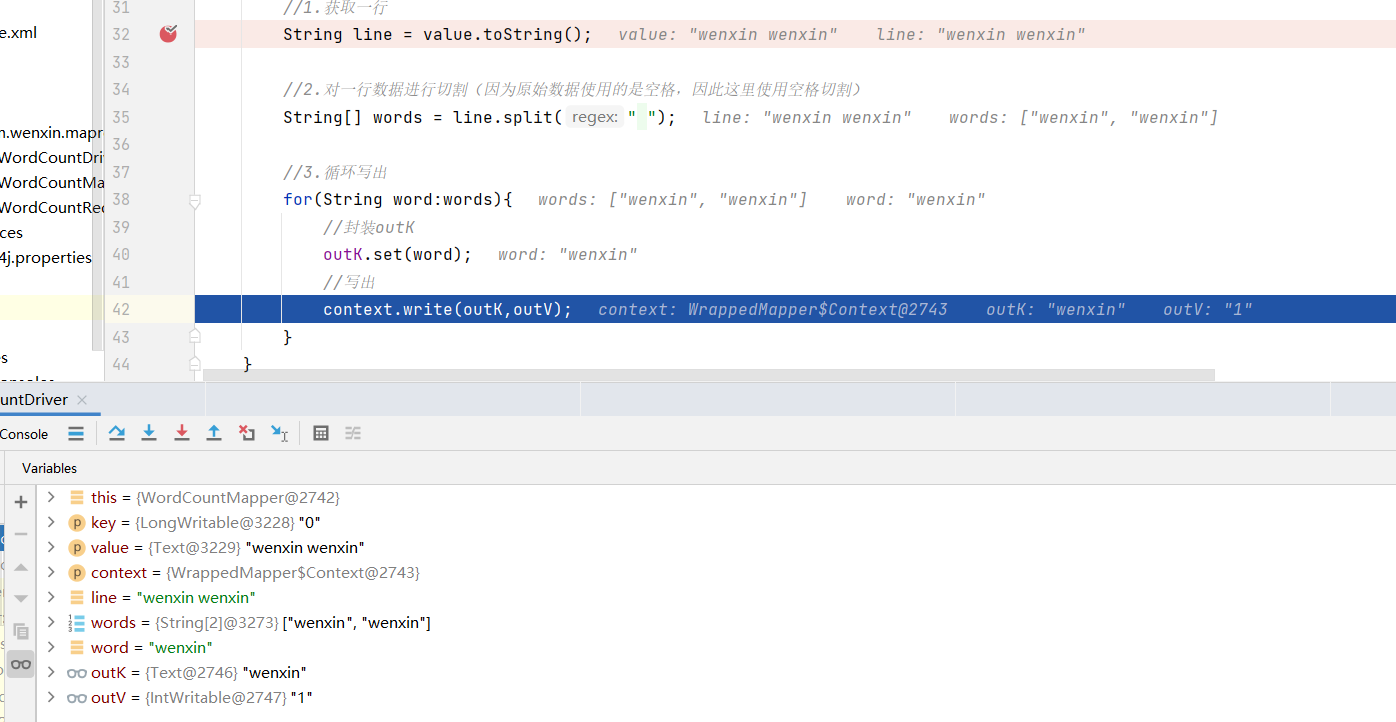
public class WordCountMapper<map> extends Mapper<LongWritable, Text,Text, IntWritable> {//private Text outK=new Text();private IntWritable outV=new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {/*LongWritable key,输入的key,偏移量Text value,输入的valueContext context,对应的上下文*///1.获取一行String line = value.toString();//2.对一行数据进行切割(因为原始数据使用的是空格,因此这里使用空格切割)String[] words = line.split(" ");//3.循环写出for(String word:words){//封装outKoutK.set(word);//写出context.write(outK,outV);}}
}



(2)编写Reducer类
package com.wenxin.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/*** @author Susie-Wen* @version 1.0* @description:* @date 2023/12/13 9:56*/
/*
KEYIN,reduce阶段输入的key的类型:Text
VALUEINT,reduce阶段输入的value的类型:IntWritable
KEYOUT,reduce阶段输出的Key的类型:Text
VALUEOUT,reduce阶段输出的value类型:IntWritable*/
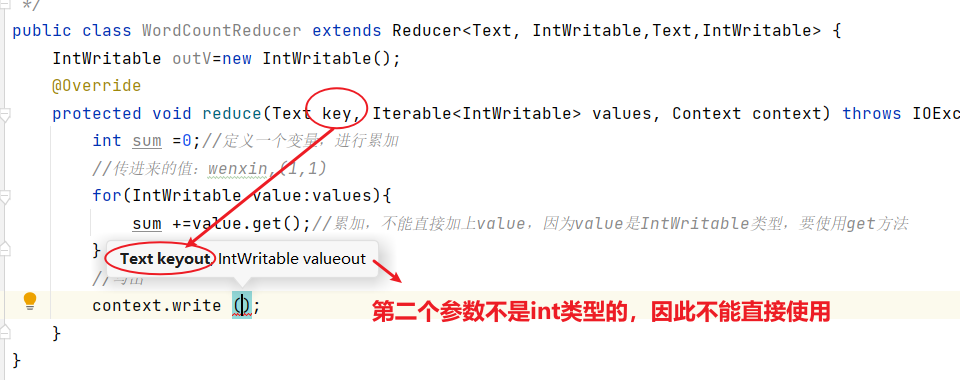
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {IntWritable outV=new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum =0;//定义一个变量,进行累加//传进来的值:wenxin,(1,1)for(IntWritable value:values){sum +=value.get();//累加,不能直接加上value,因为value是IntWritable类型,要使用get方法}outV.set(sum);//写出context.write(key,outV);}
}
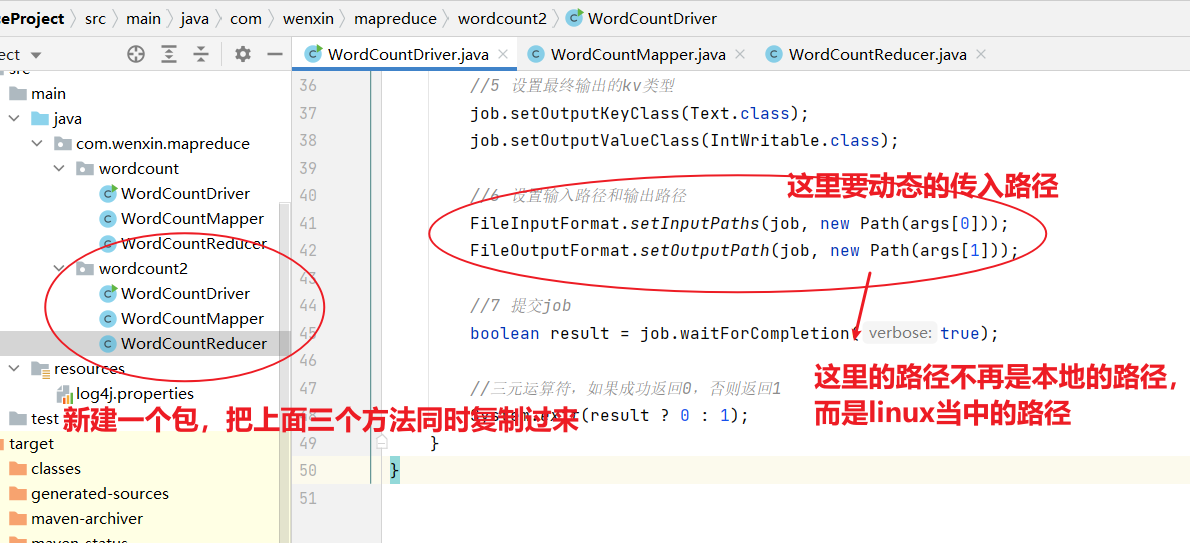
(3)编写Driver驱动类
- driver当中有7步,都是固定的;其次需要注意不要导错包了!
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
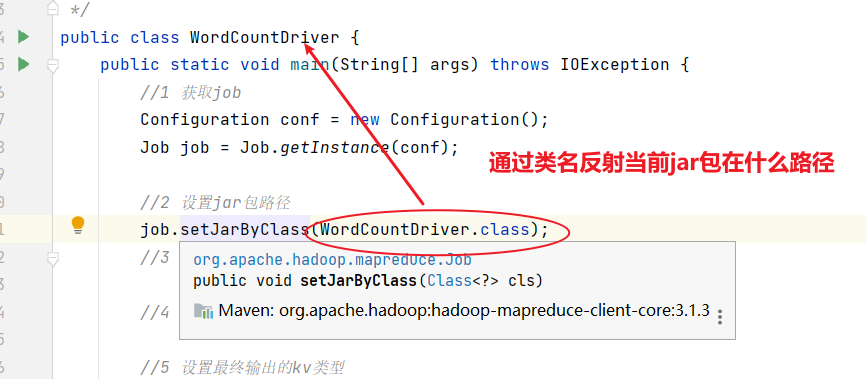
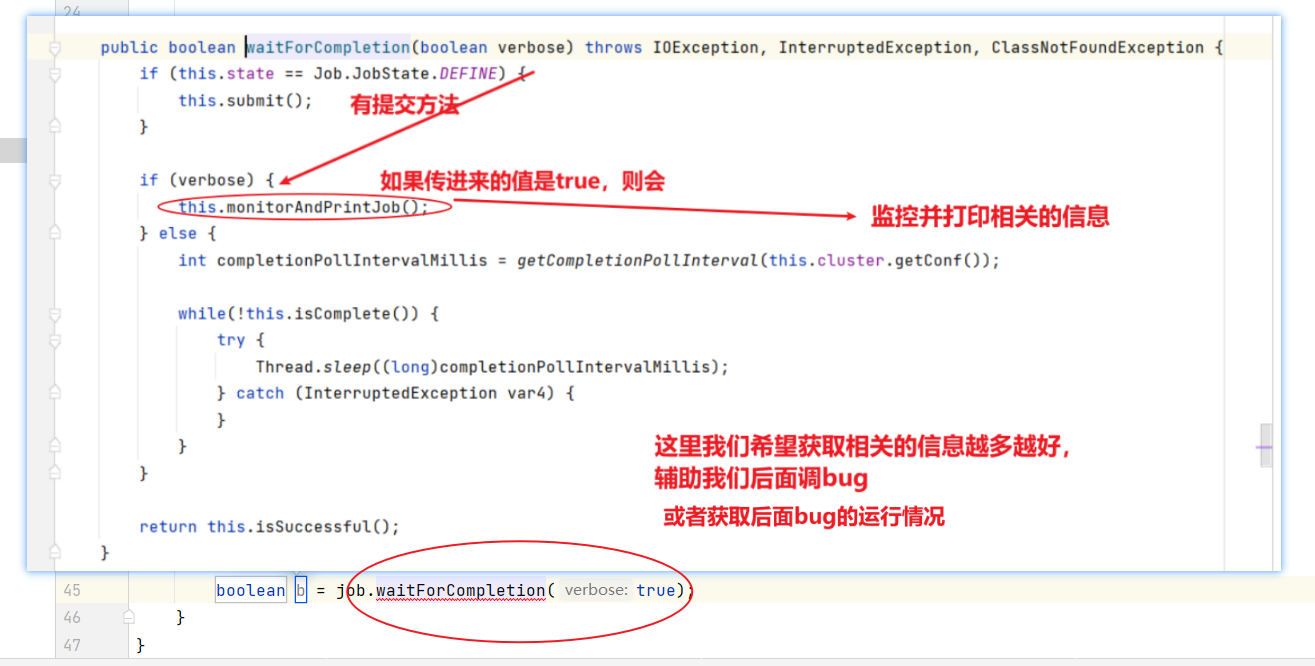
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取配置信息以及获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 关联本Driver程序的jarjob.setJarByClass(WordCountDriver.class);// 3 关联Mapper和Reducer的jarjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置Mapper输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
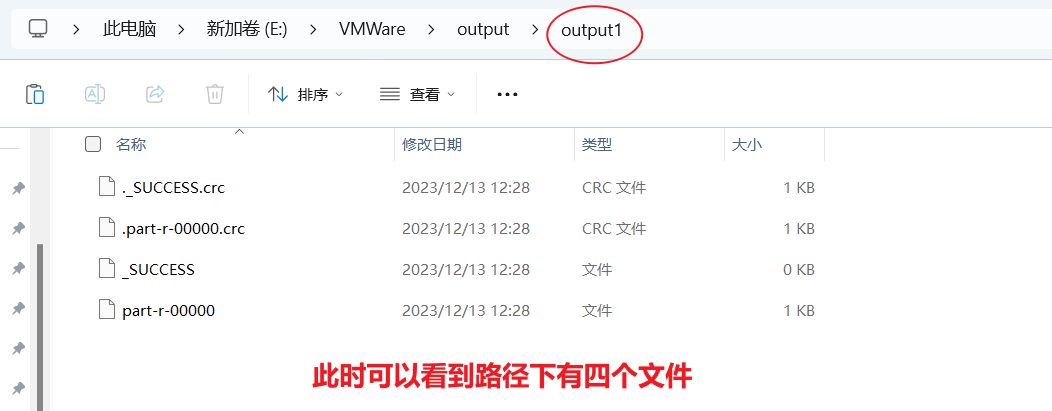
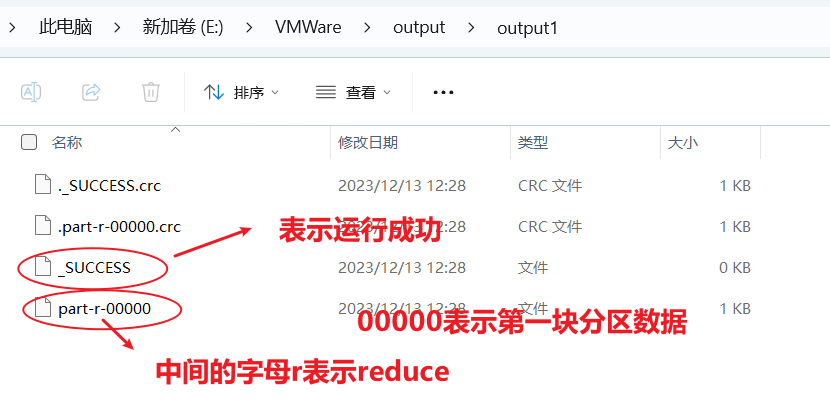

- 可以看到hadoop默认会对数据进行排序
- 如果此时再次点击运行的话,会报错,显示输出路径存在;因此对于mapreduce程序,如果输出路径存在了,就会报错。
5)本地测试
(1)需要首先配置好HADOOP_HOME变量以及Windows运行依赖
(2)在IDEA/Eclipse上运行程序
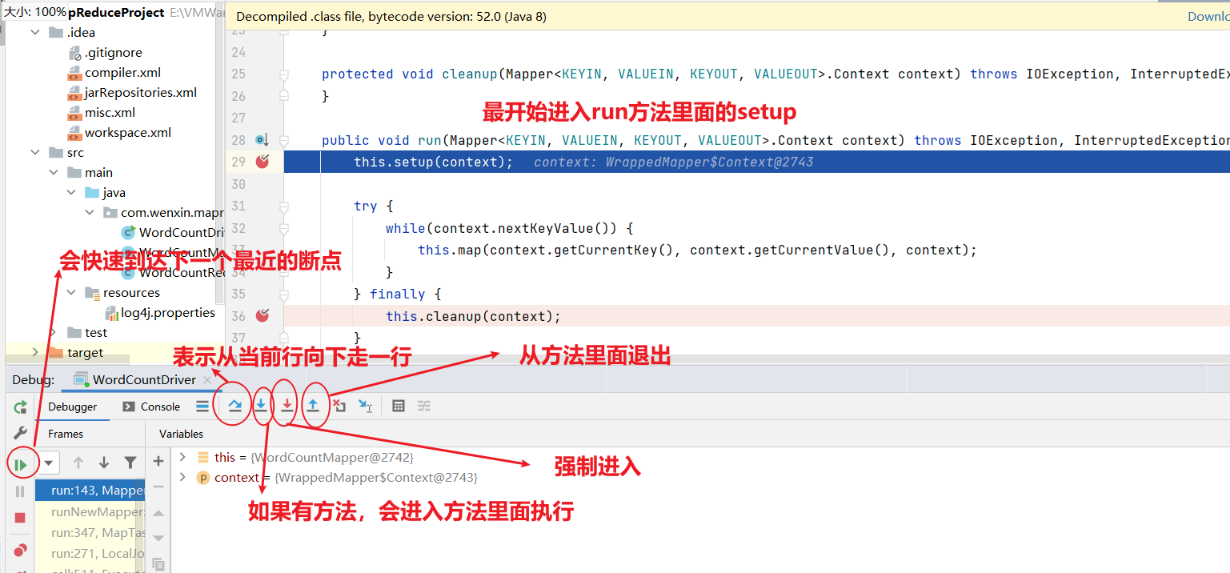
2.2 提交到集群测试
集群上测试
(1)用maven打jar包,需要添加的打包插件依赖
<build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
注意:如果工程上显示红叉。在项目上右键->maven->Reimport刷新即可。
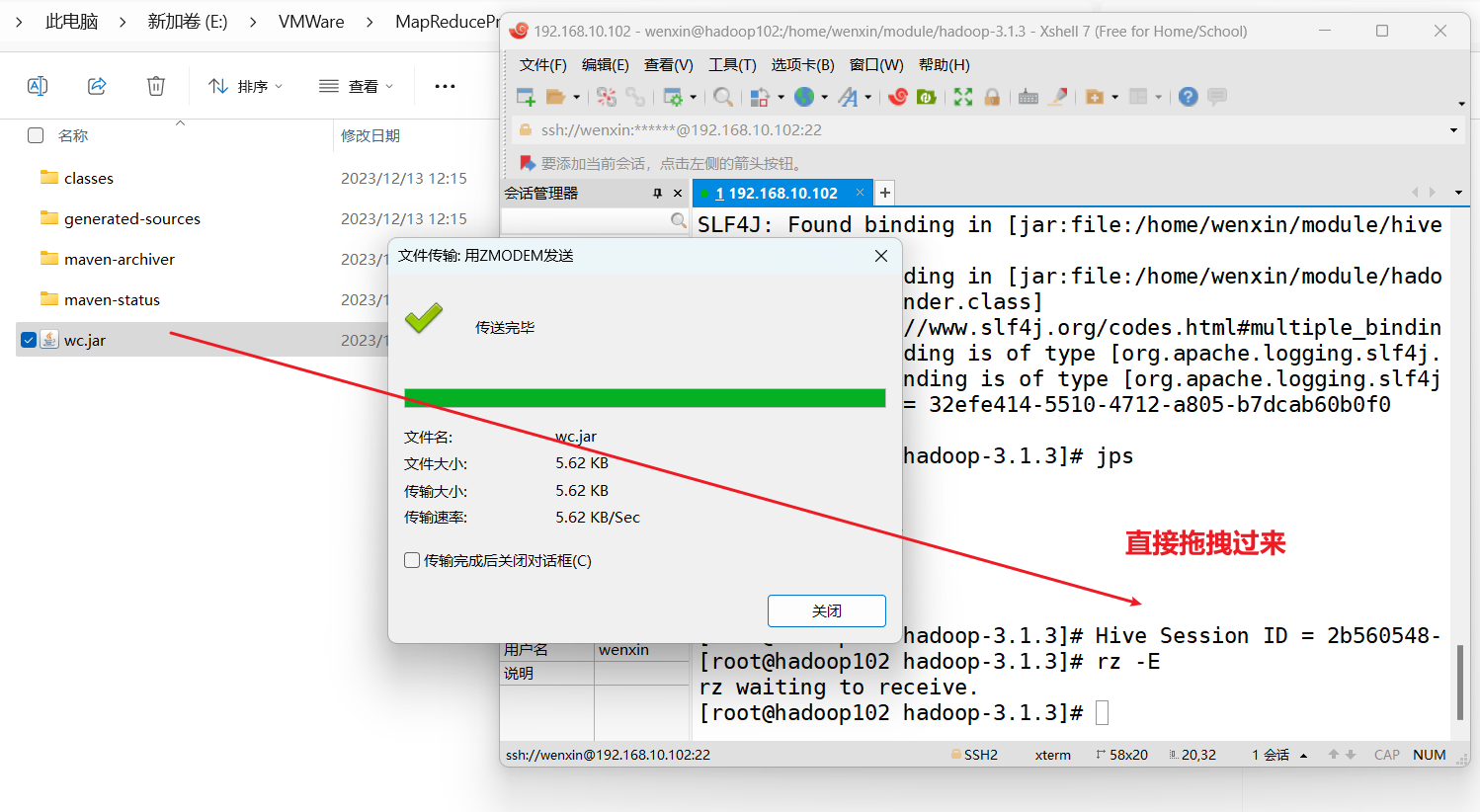
(2)将程序打成jar包


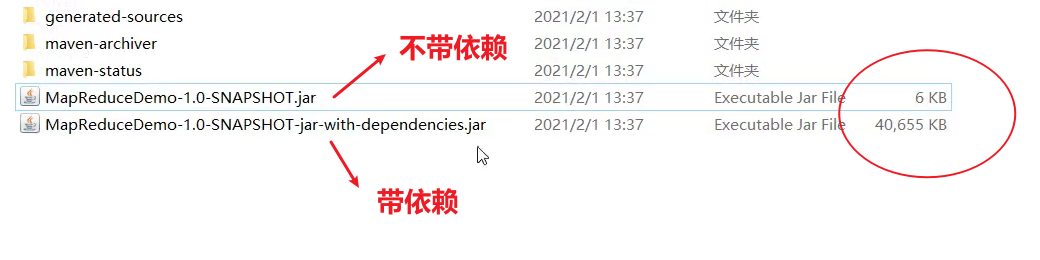
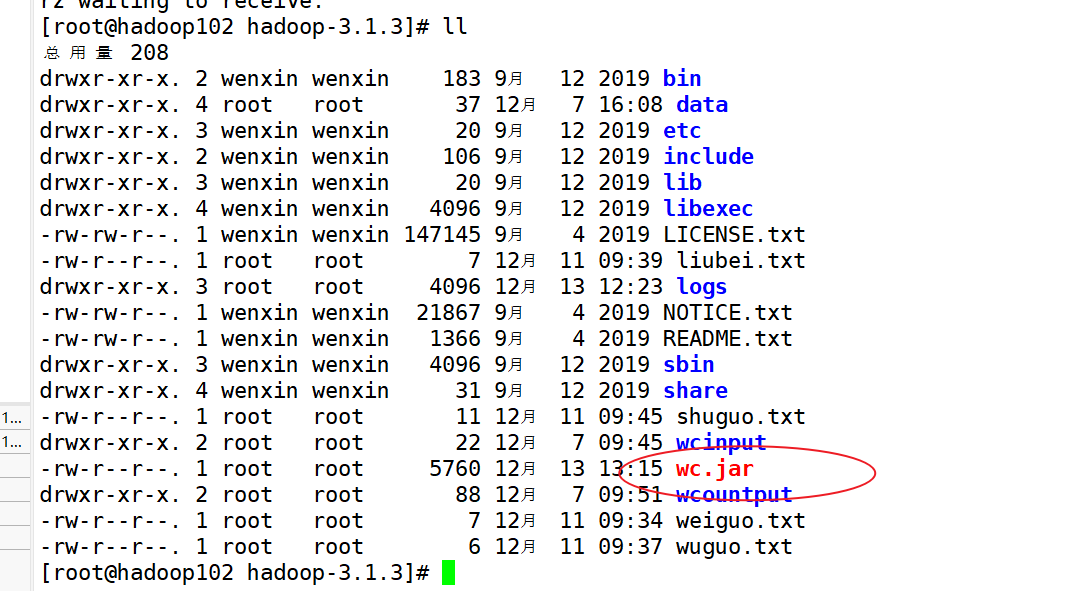
(3)修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的/home/wenxin/module/hadoop-3.1.3路径。
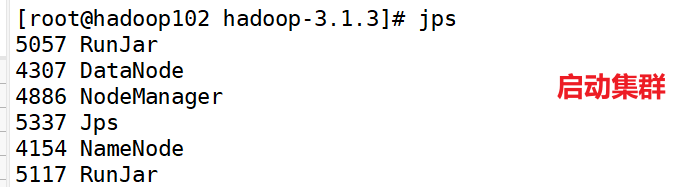
(4)启动Hadoop集群
[root@hadoop102 hadoop-3.1.3]sbin/start-dfs.sh
[root@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(5)执行WordCount程序
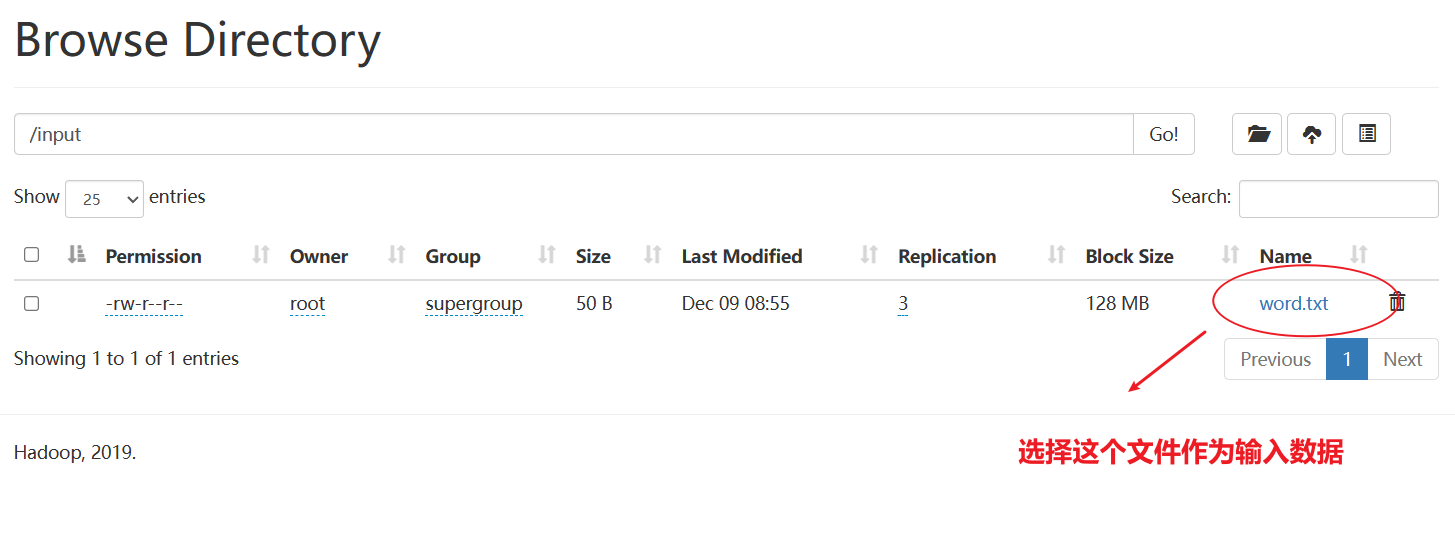
[root@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jarcom.wenxin.mapreduce.wordcount.WordCountDriver /user/wenxin/input /user/wenxin/output