一、前言
本文将介绍ChatGLM-6B的模型结构组件源码。
代练链接:https://huggingface.co/THUDM/chatglm-6b/blob/main/modeling_chatglm.py
二、激活函数
@torch.jit.script
def gelu_impl(x):"""OpenAI's gelu implementation."""return 0.5 * x * (1.0 + torch.tanh(0.7978845608028654 * x *(1.0 + 0.044715 * x * x)))def gelu(x):return gelu_impl(x)
三、位置编码
3.1、RoPE原理简介

3.2、ChatGLM-6B中RoPE代码实现
这里直接上代码阅读
class RotaryEmbedding(torch.nn.Module):def __init__(self, dim, base=10000, precision=torch.half, learnable=False):super().__init__()inv_freq = 1. / (base ** (torch.arange(0, dim, 2).float() / dim))inv_freq = inv_freq.half()self.learnable = learnableif learnable:self.inv_freq = torch.nn.Parameter(inv_freq)self.max_seq_len_cached = Noneelse:self.register_buffer('inv_freq', inv_freq)self.max_seq_len_cached = Noneself.cos_cached = Noneself.sin_cached = Noneself.precision = precisiondef _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys,error_msgs):passdef forward(self, x, seq_dim=1, seq_len=None):if seq_len is None:seq_len = x.shape[seq_dim]if self.max_seq_len_cached is None or (seq_len > self.max_seq_len_cached):self.max_seq_len_cached = None if self.learnable else seq_len# 在计算旋转嵌入之前,根据当前的嵌入维度和基数计算频率因子 inv_freq。将其转换为半精度数据类型(如果指定的 precision 为 bfloat16,则转换为单精度)。t = torch.arange(seq_len, device=x.device, dtype=self.inv_freq.dtype)# 使用 爱因斯坦求和函数 einsum 将 t 和 inv_freq 相乘,得到频率矩阵 freqs。freqs = torch.einsum('i,j->ij', t, self.inv_freq)# 通过在频率矩阵 freqs 中进行重复和拼接操作,生成旋转嵌入矩阵 emb,其维度为 [seq_len, 2 * dim]。emb = torch.cat((freqs, freqs), dim=-1).to(x.device)if self.precision == torch.bfloat16:emb = emb.float()# 将旋转嵌入矩阵 emb 分别进行余弦和正弦运算。cos_cached = emb.cos()[:, None, :]sin_cached = emb.sin()[:, None, :]if self.precision == torch.bfloat16:cos_cached = cos_cached.bfloat16()sin_cached = sin_cached.bfloat16()if self.learnable:return cos_cached, sin_cachedself.cos_cached, self.sin_cached = cos_cached, sin_cached# 按照序列长度截取return self.cos_cached[:seq_len, ...], self.sin_cached[:seq_len, ...]
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
建了技术交流群&星球!想要资料、进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司,即可。然后就可以拉你进群了。
方式①、添加微信号:mlc2060,备注:大模型资料 or 技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:大模型资料 or 技术交流


四、注意力层
4.1、2D位置编码
ChatGLM-6B代码中这一层采用的位置编码是GLM的中提出的2D位置编码,详细原理见原文:GLM: General Language Model Pretraining with Autoregressive Blank Infilling,其原理图如下图:

输入的序列是,片段和片段、被随机MASK,原始的输入序列则变为,如上图(a)和(b)所示。将三个片段拼接得到模型的输入,模型的输出则是被遮蔽掉的片段,如上图©所示。这里使用了2种位置编码:第一种编码为整个输入嵌入位置信息,能够表示MASK片段在原始输入中的位置;第二种位置编码则是为MASK片段内的tokens输入位置信息。
4.2、注意力机制
ChatGLM-6B相比标准的自注意力机制在Q和K中注入了RoPE位置信息。
- 标准自注意力机制attention_fn:
def attention_fn(self,query_layer,key_layer,value_layer,attention_mask,hidden_size_per_partition,layer_id,layer_past=None,scaling_attention_score=True,use_cache=False,
):# 考虑过去的信息if layer_past is not None:past_key, past_value = layer_pastkey_layer = torch.cat((past_key, key_layer), dim=0)value_layer = torch.cat((past_value, value_layer), dim=0)# seqlen, batch, num_attention_heads, hidden_size_per_attention_headseq_len, b, nh, hidden_size = key_layer.shapeif use_cache:present = (key_layer, value_layer)else:present = None# 对查询层进行缩放操作,即将其除以(隐藏层大小的平方根乘以查询层的缩放系数)。这是为了控制注意力得分的尺度。query_key_layer_scaling_coeff = float(layer_id + 1)if scaling_attention_score:query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)# ===================================# Raw attention scores. [b, np, s, s]# ===================================# # 注意力分数的输出形状: [batch_size, num_heads, seq_length, seq_length]output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))# 形状重塑:[seq_length, batch_size, num_heads, head_dim] -> [seq_length, batch_size*num_heads, head_dim]# [sq, b, np, hn] -> [sq, b * np, hn]query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)# [sk, b, np, hn] -> [sk, b * np, hn]key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)matmul_result = torch.empty(output_size[0] * output_size[1],output_size[2],output_size[3],dtype=query_layer.dtype,device=query_layer.device,)# 计算原始的注意力得分,通过转置和重塑操作,将查询、键和值的张量形状调整为合适的形状。matmul_result = torch.baddbmm(matmul_result,query_layer.transpose(0, 1), # [b * np, sq, hn]key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]beta=0.0,alpha=1.0,)# 重塑形状为:[batch_size,num_head,seq_length,seq_length]attention_scores = matmul_result.view(*output_size)# 如果指定了缩放的掩码 softmax(scale_mask_softmax),则将注意力得分传递给缩放的掩码 softmax 函数进行处理,以获得归一化的注意力概率。# 否则,将应用 softmax 操作,并根据需要填充一个较大的负数值(-10000.0)来屏蔽无效位置。if self.scale_mask_softmax:self.scale_mask_softmax.scale = query_key_layer_scaling_coeffattention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())else:# 对注意力分数进行maskif not (attention_mask == 0).all():# if auto-regressive, skipattention_scores.masked_fill_(attention_mask, -10000.0)dtype = attention_scores.type()attention_scores = attention_scores.float()attention_scores = attention_scores * query_key_layer_scaling_coeffattention_probs = F.softmax(attention_scores, dim=-1)attention_probs = attention_probs.type(dtype)# =========================# Context layer. [sq, b, hp]# =========================# value_layer -> context layer.# [sk, b, np, hn] --> [b, np, sq, hn]# context layer shape: [b, np, sq, hn]output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))# change view [sk, b * np, hn]value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)# 对注意力分数进行mask# change view [b * np, sq, sk]attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)# matmul: [b * np, sq, hn]context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))# change view [b, np, sq, hn]context_layer = context_layer.view(*output_size)# [b, np, sq, hn] --> [sq, b, np, hn]context_layer = context_layer.permute(2, 0, 1, 3).contiguous()# [sq, b, np, hn] --> [sq, b, hp]new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)# 重塑上下文层context_layer = context_layer.view(*new_context_layer_shape)outputs = (context_layer, present, attention_probs)return outputs-
SelfAttention的目的是为了捕捉序列中的位置信息,应用RoPE将位置信息注入Q和K。
class SelfAttention(torch.nn.Module):def __init__(self, hidden_size, num_attention_heads,layer_id, hidden_size_per_attention_head=None, bias=True,params_dtype=torch.float, position_encoding_2d=True):super(SelfAttention, self).__init__()self.layer_id = layer_idself.hidden_size = hidden_sizeself.hidden_size_per_partition = hidden_sizeself.num_attention_heads = num_attention_headsself.num_attention_heads_per_partition = num_attention_headsself.position_encoding_2d = position_encoding_2dself.rotary_emb = RotaryEmbedding(self.hidden_size // (self.num_attention_heads * 2)if position_encoding_2delse self.hidden_size // self.num_attention_heads,base=10000,precision=torch.half,learnable=False,)self.scale_mask_softmax = Noneif hidden_size_per_attention_head is None:self.hidden_size_per_attention_head = hidden_size // num_attention_headselse:self.hidden_size_per_attention_head = hidden_size_per_attention_headself.inner_hidden_size = num_attention_heads * self.hidden_size_per_attention_head# Strided linear layer.self.query_key_value = skip_init(torch.nn.Linear,hidden_size,3 * self.inner_hidden_size,bias=bias,dtype=params_dtype,)self.dense = skip_init(torch.nn.Linear,self.inner_hidden_size,hidden_size,bias=bias,dtype=params_dtype,)@staticmethoddef attention_mask_func(attention_scores, attention_mask):attention_scores.masked_fill_(attention_mask, -10000.0)return attention_scoresdef split_tensor_along_last_dim(self, tensor, num_partitions,contiguous_split_chunks=False):"""Split a tensor along its last dimension.Arguments:tensor: input tensor.num_partitions: number of partitions to split the tensorcontiguous_split_chunks: If True, make each chunk contiguousin memory."""# Get the size and dimension.last_dim = tensor.dim() - 1last_dim_size = tensor.size()[last_dim] // num_partitions# Split.tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)# Note: torch.split does not create contiguous tensors by default.if contiguous_split_chunks:return tuple(chunk.contiguous() for chunk in tensor_list)return tensor_listdef forward(self,hidden_states: torch.Tensor,position_ids,attention_mask: torch.Tensor,layer_id,layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache: bool = False,output_attentions: bool = False,):"""hidden_states: [seq_len, batch, hidden_size]attention_mask: [(1, 1), seq_len, seq_len]"""# [seq_len, batch, 3 * hidden_size]mixed_raw_layer = self.query_key_value(hidden_states)# [seq_len, batch, 3 * hidden_size] --> [seq_len, batch, num_attention_heads, 3 * hidden_size_per_attention_head]new_tensor_shape = mixed_raw_layer.size()[:-1] + (self.num_attention_heads_per_partition,3 * self.hidden_size_per_attention_head,)mixed_raw_layer = mixed_raw_layer.view(*new_tensor_shape)# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head](query_layer, key_layer, value_layer) = self.split_tensor_along_last_dim(mixed_raw_layer, 3)# 根据是否使用二维位置编码,对查询和键应用旋转嵌入,并根据位置信息进行索引操作。if self.position_encoding_2d:q1, q2 = query_layer.chunk(2, dim=(query_layer.ndim - 1))k1, k2 = key_layer.chunk(2, dim=(key_layer.ndim - 1))cos, sin = self.rotary_emb(q1, seq_len=position_ids.max() + 1)position_ids, block_position_ids = position_ids[:, 0, :].transpose(0, 1).contiguous(), \position_ids[:, 1, :].transpose(0, 1).contiguous()q1, k1 = apply_rotary_pos_emb_index(q1, k1, cos, sin, position_ids)q2, k2 = apply_rotary_pos_emb_index(q2, k2, cos, sin, block_position_ids)# 拼接嵌入不同位置信息的query和key,这样query和key中包含了两种位置信息query_layer = torch.concat([q1, q2], dim=(q1.ndim - 1))key_layer = torch.concat([k1, k2], dim=(k1.ndim - 1))else:# RoPEposition_ids = position_ids.transpose(0, 1)cos, sin = self.rotary_emb(value_layer, seq_len=position_ids.max() + 1)# [seq_len, batch, num_attention_heads, hidden_size_per_attention_head]query_layer, key_layer = apply_rotary_pos_emb_index(query_layer, key_layer, cos, sin, position_ids)# 调用 attention_fn 方法计算注意力得分和上下文层,其中使用了注意力函数的代码块# [seq_len, batch, hidden_size]context_layer, present, attention_probs = attention_fn(self=self,query_layer=query_layer,key_layer=key_layer,value_layer=value_layer,attention_mask=attention_mask,hidden_size_per_partition=self.hidden_size_per_partition,layer_id=layer_id,layer_past=layer_past,use_cache=use_cache)output = self.dense(context_layer)outputs = (output, present)if output_attentions:outputs += (attention_probs,)return outputs # output, present, attention_probs五、GLU层
根据代码,GLU形式化表示为:
class GEGLU(torch.nn.Module):def __init__(self):super().__init__()self.activation_fn = F.geludef forward(self, x):# dim=-1 breaks in jit for pt<1.10x1, x2 = x.chunk(2, dim=(x.ndim - 1))return x1 * self.activation_fn(x2)class GLU(torch.nn.Module):def __init__(self, hidden_size, inner_hidden_size=None,layer_id=None, bias=True, activation_func=gelu, params_dtype=torch.float):super(GLU, self).__init__()self.layer_id = layer_idself.activation_func = activation_func# Project to 4h.self.hidden_size = hidden_sizeif inner_hidden_size is None:inner_hidden_size = 4 * hidden_sizeself.inner_hidden_size = inner_hidden_sizeself.dense_h_to_4h = skip_init(torch.nn.Linear,self.hidden_size,self.inner_hidden_size,bias=bias,dtype=params_dtype,)# Project back to h.self.dense_4h_to_h = skip_init(torch.nn.Linear,self.inner_hidden_size,self.hidden_size,bias=bias,dtype=params_dtype,)def forward(self, hidden_states):"""hidden_states: [seq_len, batch, hidden_size]"""# [seq_len, batch, inner_hidden_size]intermediate_parallel = self.dense_h_to_4h(hidden_states)intermediate_parallel = self.activation_func(intermediate_parallel)output = self.dense_4h_to_h(intermediate_parallel)return output六、GLMBlock
根据代码,GLMBlock由Layer Norm、Self Attention、Layer Norm和GLU模块构成。
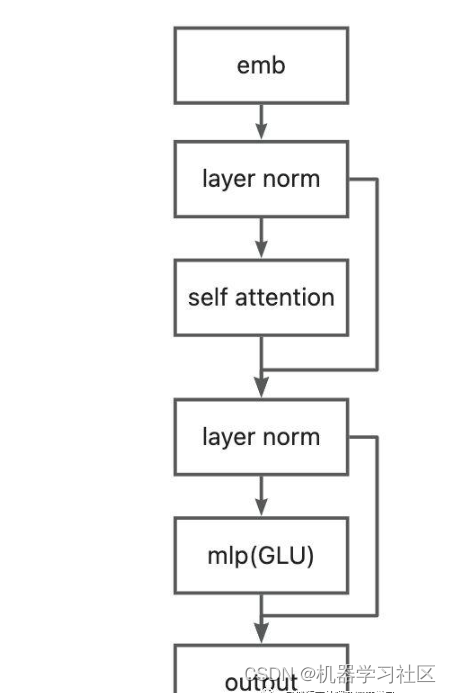
class GLMBlock(torch.nn.Module):def __init__(self,hidden_size,num_attention_heads,layernorm_epsilon,layer_id,inner_hidden_size=None,hidden_size_per_attention_head=None,layernorm=LayerNorm,use_bias=True,params_dtype=torch.float,num_layers=28,position_encoding_2d=True):super(GLMBlock, self).__init__()# Set output layer initialization if not provided.self.layer_id = layer_id# LayerNorm层self.input_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)# 是否使用2维位置编码self.position_encoding_2d = position_encoding_2d# 自注意力层self.attention = SelfAttention(hidden_size,num_attention_heads,layer_id,hidden_size_per_attention_head=hidden_size_per_attention_head,bias=use_bias,params_dtype=params_dtype,position_encoding_2d=self.position_encoding_2d)# LayerNorm层self.post_attention_layernorm = layernorm(hidden_size, eps=layernorm_epsilon)self.num_layers = num_layers# GLU层self.mlp = GLU(hidden_size,inner_hidden_size=inner_hidden_size,bias=use_bias,layer_id=layer_id,params_dtype=params_dtype,)def forward(self,hidden_states: torch.Tensor,position_ids,attention_mask: torch.Tensor,layer_id,layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,use_cache: bool = False,output_attentions: bool = False,):"""hidden_states: [seq_len, batch, hidden_size]attention_mask: [(1, 1), seq_len, seq_len]"""# 输入进行Layer Norm# [seq_len, batch, hidden_size]attention_input = self.input_layernorm(hidden_states)# 自注意力attention_outputs = self.attention(attention_input,position_ids,attention_mask=attention_mask,layer_id=layer_id,layer_past=layer_past,use_cache=use_cache,output_attentions=output_attentions)attention_output = attention_outputs[0]outputs = attention_outputs[1:]# Residual connection.alpha = (2 * self.num_layers) ** 0.5# 执行注意力残差连接hidden_states = attention_input * alpha + attention_output# 对注意力残差连接后的输出进行层归一化mlp_input = self.post_attention_layernorm(hidden_states)# 使用GLU层对归一化后的输出进行非线性变换mlp_output = self.mlp(mlp_input)# 执行GLU残差连接output = mlp_input * alpha + mlp_outputif use_cache:outputs = (output,) + outputselse:outputs = (output,) + outputs[1:]return outputs # hidden_states, present, attentions七、ChatGLMPreTrainedModel
这一块主要看看其中的MASK和Position_ids
7.1、ChatGLM-6B的Mask
ChatGLM-6B采用prefix-LM的Mask,其对于输入的前缀使用双向注意力,对于后续的生成部分则是Causal Mask。
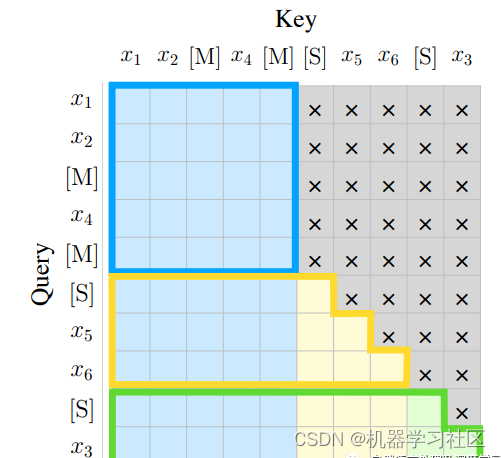
def get_masks(self, input_ids, device):batch_size, seq_length = input_ids.shape# context_lengths记录了batch中每个样本的真实长度context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]# 生成causal mask,即下三角以及对角线为1,上三角为0attention_mask = torch.ones((batch_size, seq_length, seq_length), device=device)attention_mask.tril_()# 将前缀部分的注意力改为双向注意力for i, context_length in enumerate(context_lengths):attention_mask[i, :, :context_length] = 1attention_mask.unsqueeze_(1)attention_mask = (attention_mask < 0.5).bool()return attention_mask7.2、ChatGLM-6B的Position_ids
def get_position_ids(self, input_ids, mask_positions, device, use_gmasks=None):"""input_ids: [batch_size, seq_length]mask_positions: [batch_size],由于GLM系列中会使用[Mask]或[gMask]标志,mask_positions就是指这些标注的具体位置"""batch_size, seq_length = input_ids.shapeif use_gmasks is None:use_gmasks = [False] * batch_size# context_lengths:未被padding前,batch中各个样本的长度context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]# 2维位置编码if self.position_encoding_2d:# [0,1,2,...,seq_length-1]position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)# 将原始输入后所有位置的postion id都设置为[Mask]或者[gMask]的位置idfor i, context_length in enumerate(context_lengths):position_ids[i, context_length:] = mask_positions[i]# 原始输入的位置编码全部设置为0,待生成的位置添加顺序的位置id# 例如:[0,0,0,0,1,2,3,4,5]block_position_ids = [torch.cat((torch.zeros(context_length, dtype=torch.long, device=device),torch.arange(seq_length - context_length, dtype=torch.long, device=device) + 1)) for context_length in context_lengths]block_position_ids = torch.stack(block_position_ids, dim=0)# 将postion_ids和block_position_ids堆叠在一起,用于后续的参数传入;# 在注意力层中,还有将这个position_ids拆分为两部分position_ids = torch.stack((position_ids, block_position_ids), dim=1)else:position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)for i, context_length in enumerate(context_lengths):if not use_gmasks[i]:position_ids[i, context_length:] = mask_positions[i]return position_ids八、ChatGLMModel
这一块主要是模型的各部件的组合结构,直接看源码:
class ChatGLMModel(ChatGLMPreTrainedModel):def __init__(self, config: ChatGLMConfig, empty_init=True):super().__init__(config)if empty_init:init_method = skip_initelse:init_method = default_init# recording parametersself.max_sequence_length = config.max_sequence_lengthself.hidden_size = config.hidden_sizeself.params_dtype = torch.halfself.num_attention_heads = config.num_attention_headsself.vocab_size = config.vocab_sizeself.num_layers = config.num_layersself.layernorm_epsilon = config.layernorm_epsilonself.inner_hidden_size = config.inner_hidden_sizeself.hidden_size_per_attention_head = self.hidden_size // self.num_attention_headsself.position_encoding_2d = config.position_encoding_2dself.pre_seq_len = config.pre_seq_lenself.prefix_projection = config.prefix_projectionself.word_embeddings = init_method(torch.nn.Embedding,num_embeddings=self.vocab_size, embedding_dim=self.hidden_size,dtype=self.params_dtype)self.gradient_checkpointing = Falsedef get_layer(layer_id):return GLMBlock(self.hidden_size,self.num_attention_heads,self.layernorm_epsilon,layer_id,inner_hidden_size=self.inner_hidden_size,hidden_size_per_attention_head=self.hidden_size_per_attention_head,layernorm=LayerNorm,use_bias=True,params_dtype=self.params_dtype,position_encoding_2d=self.position_encoding_2d,empty_init=empty_init)self.layers = torch.nn.ModuleList([get_layer(layer_id) for layer_id in range(self.num_layers)])# Final layer norm before output.self.final_layernorm = LayerNorm(self.hidden_size, eps=self.layernorm_epsilon)"""pre_seq_len 为prompt部分长度,这部分仅编码,无反向传播"""if self.pre_seq_len is not None:for param in self.parameters():param.requires_grad = Falseself.prefix_tokens = torch.arange(self.pre_seq_len).long()self.prefix_encoder = PrefixEncoder(config)self.dropout = torch.nn.Dropout(0.1)def get_prompt(self, batch_size, device, dtype=torch.half):"""prompt 编码"""prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device)past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)past_key_values = past_key_values.view(batch_size,self.pre_seq_len,self.num_layers * 2,self.num_attention_heads,self.hidden_size // self.num_attention_heads)# seq_len, b, nh, hidden_sizepast_key_values = self.dropout(past_key_values)past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)# past_key_values = [(v[0], v[1]) for v in past_key_values]return past_key_valuesdef forward(self,input_ids: Optional[torch.LongTensor] = None,position_ids: Optional[torch.LongTensor] = None,attention_mask: Optional[torch.Tensor] = None,past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,inputs_embeds: Optional[torch.LongTensor] = None,use_cache: Optional[bool] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPast]:....."""past_key_values机制是重要的机制,其可以防止模型在文本生成任务中重新计算上一次迭代中已经计算好的上下文的值,大大提高了模型在文本生成任务中的计算效率。但要特别注意的是,在第一次迭代时由于不存在上一次迭代返回的past_key_values值,因此第一次迭代时past_key_values值为None。past_key_values 中每个元素的dim :num_layers * seq_len * batch_size * nh * hidden_size_per_head"""if past_key_values is None:if self.pre_seq_len is not None:past_key_values = self.get_prompt(batch_size=input_ids.shape[0], device=input_ids.device,dtype=inputs_embeds.dtype)else:past_key_values = tuple([None] * len(self.layers))if attention_mask is None:attention_mask = self.get_masks(input_ids,device=input_ids.device)if position_ids is None:"""如果只有MASK无gMASK,则mask_positions 为第一个MASK的起始位置,如果有gMASK, 则mask_positions 为第一个gMASK的起始位置e.g.gMASK = 130001MASK = 130000seqs = [[11,22,MASK,33,MASK]]--> mask_positions:[2] use_gmask = [False]gMASK = 130001MASK = 130000seqs = seqs = [[11,22,MASK,33,MASK, gMASK, 55, 66, gMASK, 77]]--> mask_positions:[5] use_gmask = [True]把位置id结合mask位置信息由get_position_ids计算(为父类ChatGLMPreTrainedModel的方法)在使用2d position coding 时,position_ids dim = batch_size * 2 * seq_length 第二维包含 position_id 和 block_position_id """MASK, gMASK = self.config.mask_token_id, self.config.gmask_token_idseqs = input_ids.tolist()mask_positions, use_gmasks = [], []for seq in seqs:mask_token = gMASK if gMASK in seq else MASKuse_gmask = mask_token == gMASKmask_positions.append(seq.index(mask_token))use_gmasks.append(use_gmask)position_ids = self.get_position_ids(input_ids,mask_positions=mask_positions,device=input_ids.device,use_gmasks=use_gmasks)if self.pre_seq_len is not None and attention_mask is not None:prefix_attention_mask = torch.ones(batch_size, 1, input_ids.size(-1), self.pre_seq_len).to(attention_mask.device)prefix_attention_mask = (prefix_attention_mask < 0.5).bool()attention_mask = torch.cat((prefix_attention_mask, attention_mask), dim=3)"""输入的embedding在这里进行了转置 batch_size * seq_len * hidden_size -> seq_len * batch_size * hidden_size"""# [seq_len, batch, hidden_size]hidden_states = inputs_embeds.transpose(0, 1)presents = () if use_cache else Noneall_self_attentions = () if output_attentions else Noneall_hidden_states = () if output_hidden_states else Noneif attention_mask is None:attention_mask = torch.zeros(1, 1, device=input_ids.device).bool()else:attention_mask = attention_mask.to(hidden_states.device)for i, layer in enumerate(self.layers):if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)layer_past = past_key_values[i]if self.gradient_checkpointing and self.training:layer_ret = torch.utils.checkpoint.checkpoint(layer,hidden_states,position_ids,attention_mask,torch.tensor(i),layer_past,use_cache,output_attentions)else:layer_ret = layer(hidden_states,position_ids=position_ids,attention_mask=attention_mask,layer_id=torch.tensor(i),layer_past=layer_past,use_cache=use_cache,output_attentions=output_attentions)hidden_states = layer_ret[0]if use_cache:presents = presents + (layer_ret[1],)if output_attentions:all_self_attentions = all_self_attentions + (layer_ret[2 if use_cache else 1],)# Final layer norm.hidden_states = self.final_layernorm(hidden_states)if output_hidden_states:all_hidden_states = all_hidden_states + (hidden_states,)if not return_dict:return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)"""经过多个glm block堆叠,最后通过一个layernorm
"""return BaseModelOutputWithPast(last_hidden_state=hidden_states,past_key_values=presents,hidden_states=all_hidden_states,attentions=all_self_attentions,)如有不详细之处,还望一起交流学习。
参考文献
-
GLM: General Language Model Pretraining with Autoregressive Blank Infilling)
-
modeling_chatglm.py · THUDM/chatglm-6b at main (huggingface.co)
-
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces (kexue.fm)