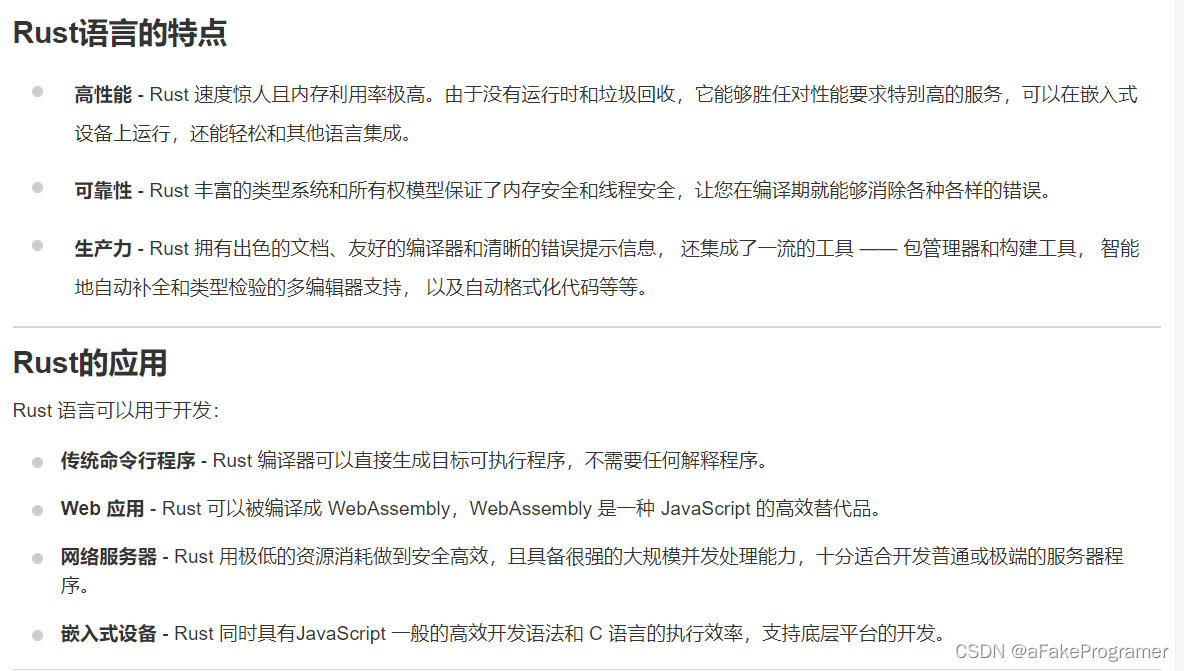
前面提到过:Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等;每种join算法都有对应的优化方案。
Map Join
在优化阶段,如果能将Common Join优化为Map Join算法,那就会优化成Map Join,但是在编译阶段如果所需的表大小是未知的(例如对子查询进行join操作),那么Hive会在编译阶段生成一个条件任务,计划列表中包含转换后的Map Join任务以及原有的Common Join任务。Common Join作后备计划。大致思路如下图所示:
Map join自动转换的具体判断逻辑如下图所示:
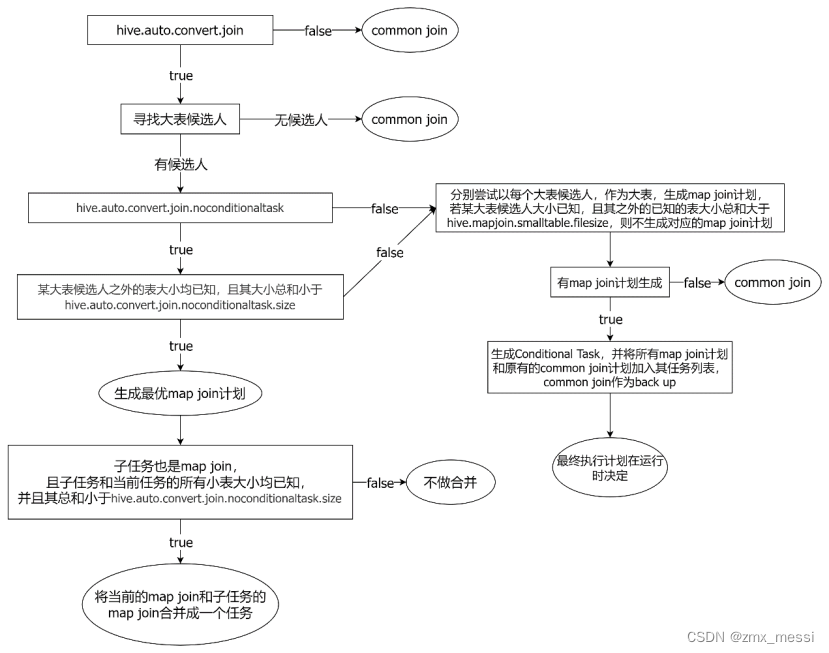
首先是查看hive.auto .convert.join参数是否开启,然后根据sql语句寻找大表候选人,再检测条件任务是否开启,一般开启条件任务即可(走右边),hive会自动判断,系统分别为每个大表候选人生成map join计划,如果已知其他表的大小超过hive.mapjoin.smalltable.filesize参数,则排除该计划。如果判断有map join计划生成,则会将所有生成的map join 计划和common join 计划一同加入任务列表,最终执行哪个运行时决定;
再来看左边,若大表之外的小表均已知,且大小总和小于noconditionaltask.size,则生成最优的mapjoin计划(最大的表生成大表,最小的表作为小表),如果不是,继续走右边。
如果子任务也是map join 计划,且他们的小表都小于noconditionaltask.size,那就会合并mapjoin计划。比如有a,b,c三张表:他们的关联字段不一样,因此需要两个maptask去执行,在join a和b的时候,b是小表,走mapjoin ;在join 中间结果和c的时候,c是小表,走mapjoin;那么如果b+c小于noconditionaltask.size,就会将b,c缓存在内存中,去遍历a的记录先去join b的hashtable中的字段,再去c的hashtable中寻找关联字段进行join。这相当于一个中终极mapjoin计划。
上面几个参数如下:
--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的已知大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;