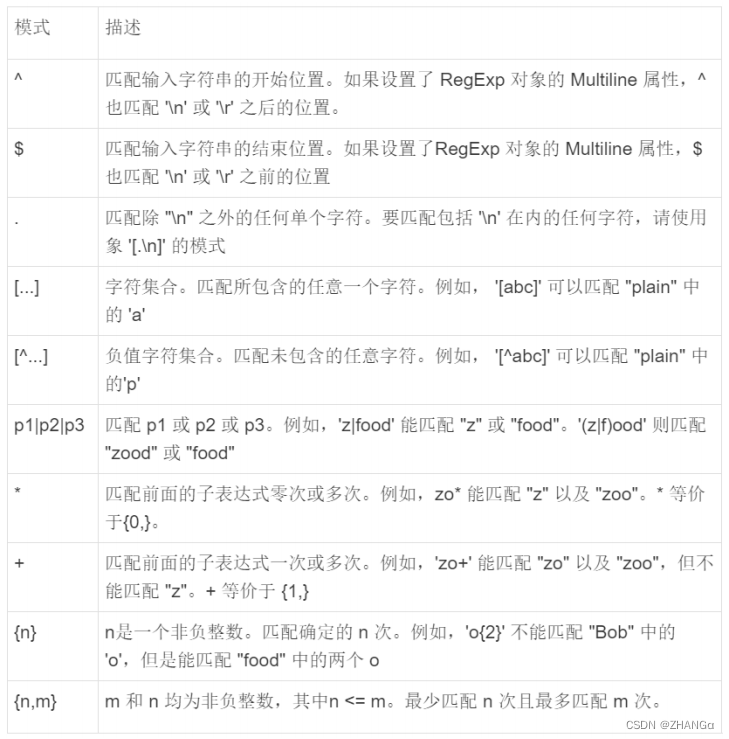
DQL:数据查询语言
查询全表
select * from 表名;
查询指定列
select 列名 1, 列名 2,… from 表名 ;
条件查询
select * from 表名 where 条件 ;
注意:
条件查询就是在查询时给出 WHERE 子句,在 WHERE 子句中可以使用如下运算符及关键
字:
= 、 != 、 <> 、 < 、 <= 、 > 、 >=
BETWEEN…AND ( 等价 <= 和 >=)
IN(set) ( 包含 )
IS NULL ( 非空 )
AND ( 逻辑与 )
OR ( 逻辑或 )
NOT ( 逻辑非 )
XOR ( 逻辑异或 )
示例
-- 查询成绩小于80的学员
select * from stu where score < 80;
-- 查询成绩等于100的学员
select * from stu where score = 100;
-- 查询成绩在85~100的学员
select * from stu where math between 80 and 100;
-- 查询姓名叫做“张三”或者“李四”的所有学生信息。
select * from stu where name beteween "张三" and "李四";
-- 查询成绩不小于80的学员
select * from stu where not score < 80;
-- 查询姓名不叫做“张三”或者“李四”的所有学生信息。
select * from stu where name not beteween "张三" and "李四";
-- 查询姓名叫做“张三”或者“李四”的所有学生信息。
select * from stu where name in ("张三","李四");
-- 查询成绩小于0或大于100的学员
select * from stu where score < 0 or score > 100;
-- 查询性别为空的学员
select * from stu where sex IS NULL;模糊查询
语法
当想查询姓名中包含 a 字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字
LIKE 。
_: 任意一个字母
%: 任意 0~n 个字母 ' 张 %'
示例
-- 查找姓名为3个字母的学生信息
select * from stu where name like '___';//注意是3个_,表示匹配3个字符
-- 查找以字母b开头的学生信息
select * from stu where name like 'b%'; 正则表达式
MySQL 同样也支持其他正则表达式的匹配, MySQL 中使用 REGEXP 操作符来进行正则
表达式匹配。
示例
-- 查找姓名以 l 开头且以 y 结尾的学生信息
select * from stu where name regexp '^l' and name regexp 'y$' ;
去重
关键字 :distinct
示例
-- 查询 stu 表中 age 字段,剔除重复行
select distinct age from stu;
计算列
对从数据表中查询的记录的列进行一定的运算之后显示出来
+,-,*,/,%
示例
-- 出生年份 = 当前年份 - 年龄
select stu_name, 2021 -stu_age from stus;
别名
如果在连接查询的多张表中存在相同名字的字段,我们可以使用 表名 . 字段名 来进行区
分,如果表名或字段名太长则不便于 SQL 语句的编写,我们可以使用数据表别名
示例
-- 字段起别名
select name AS 姓名 from stu;
-- 表名起别名
select s.name,s.sex from stu AS s;
-- AS可以省略
select name 姓名 from stu;
select s.name,s.sex from stu s;排序order by
将查询到的满足条件的记录按照指定的列的值升序 / 降序排列
语法:
select * from 表名 where 条件 order by 列名 asc|desc;
order by 列名 表示将查询结果按照指定的列排序
asc 按照指定的列升序(默认)
desc 按照指定的列降序
示例:
# 单字段排序
select * from stu where age>15 order by score desc;
# 多字段排序:先满足第一个排序规则,当第一个排序的列的值相同时再按照第二个列的
规则排序
select * from stus where age>15 order by score asc,age desc;聚合函数
聚合函数是用来做纵向运算的函数:
COUNT() :统计指定列不为 NULL 的记录行数;
MAX() :计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN() :计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
SUM() :计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为 0 ;
AVG() :计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为 0 ;
示例
-- 统计年龄大于20的学员人数
select count(*) as cnt from stu where age>20;
-- 统计学员的总年龄
select sum(age) from stu;
-- 统计学员的平均年龄以及总年龄
select sum(age),avg(age) from stu;
-- 统计学员的最低年龄以及最高年龄
select max(age),min(age) from stu;
-- 计算班级平均分
select avg(score) from stu;分组查询
分组:就是将数据表中的记录按指定的列进行分组
语法
select 分组字段/聚合函数
from 表名
[where 条件]
group by 分组列名 [having 条件]
[order by 排序字段] 注意
语句执行顺序:
1, 先根据 where 条件从数据库查询记录
2,group by 对查询记录进行分组
3, 执行 having 对分组后的数据进行筛选
4, 排序
示例
-- 先对查询的学生信息按性别进行分组(分成了男、女两组),然后再分别统计每组
学生的个数
select stu_gender,count(stu_num) from stus group by stu_gender;
-- 先对查询的学生信息按性别进行分组(分成了男、女两组),然后再计算每组的平
均年龄
select stu_gender,avg(stu_age) from stus group by stu_gender;
-- 先对学生按年龄进行分组,然后统计各组的学生数量,还可以对最终的结果排序
select stu_age,count(stu_num) from stus group by stu_age order by
stu_age;
-- 查询所有学生,按年龄进行分组,然后分别统计每组的人数,再筛选当前组人数>1
的组,再按年龄升序显示出来
select stu_age,count(stu_num)
from stus
group by stu_age
having count(stu_num)>1
order by stu_age;
-- 查询性别为'男'的学生,按年龄进行分组,然后分别统计每组的人数,再筛选当前组人
数>1的组,再按年龄升序显示出来
select stu_age,count(stu_num)
-> from stus
-> where stu_gender='男'
-> group by stu_age
-> having count(stu_num)>1
-> order by stu_age;
分页查询
语法
select 查询的字段
from 表名
where 条件
limit param1,param2;
注意 :
- param1 :表示获取查询语句的结果中的第一条数据的索引(索引从 0 开始)
- param2 :表示获取的查询记录的条数(如果剩下的数据条数 <param2 ,则返回剩下的
所有记录)
注意
-- 示例
-- 假如 : 对数据表中的学生信息进行分页显示,总共有 10 条数据,我们每页显示 3 条
-- 总记录数: `count 10`
-- 每页显示: `pageSize 3`
-- 总页数: `pageCount=count%pageSize==0?
count/pageSize:count/pageSize+1`
-- 查询第一页:
select * from stus [ where ...] limit 0 , 3 ; ( 1 - 1 )* 3
-- 查询第二页:
select * from stus [ where ...] limit 3 , 3 ; ( 2 - 1 )* 3
-- 查询第三页:
select * from stus [ where ...] limit 6 , 3 ; ( 3 - 1 )* 3
-- 查询第四页:
select * from stus [ where ...] limit 9 , 3 ; ( 4 - 1 )* 3
-- 如果在一张数据表中:
-- pageNum 表示查询的页码
-- pageSize 表示每页显示的条数
-- 通用分页语句如下:
select * from stus [ where ...] limit (pageNum- 1 )*pageSize,pageSize;
约束
概念
在创建数据表的时候,指定的对数据表的列的数据限制性的要求(对表的列中的数据进行
限制)
作用
- 保证数据的有效性
- 保证数据的完整性
- 保证数据的正确性
分类
- 非空约束( not null ):限制此列的值必须提供,不能为 null
- 唯一约束( unique ):在表中的多条数据,此列的值不能重复
- 主键约束( primary key ):非空 + 唯一,能够唯一标识数据表中的一条数据
- 自增长约束 (auto_increment): 每次 +1, 从 1 起
- 检查约束( check ):保证列中的值满足某一条件
- 默认约束( default ):保存数据时 , 未指定值则采用默认值
- 外键约束( foreign key ):建立不同表之间的关联关系
非空约束
含义 : 限制数据表中此列的值必须提供
例子 : 创建图书表 , 设置书名 (book_name) 的不能为空
create table books(
book_isbn integer ,
book_isbn char ( 4 ),
book_name varchar ( 10 ) not null ,
book_author varchar ( 6 )
);
唯一约束
含义 : 在表中的多条数据,此列的值不能重复
例子 : 创建图书表 , 设置国籍标准书号 (book_isbn) 的不能重复
create table books(
book_id integer ,
book_isbn char ( 4 ) unique ,
book_name varchar ( 10 ) not null ,
book_author varchar ( 6 )
);
检查约束
含义 : 保证列中的值满足某一条件
例子 : 创建用户表时 , 检查年龄在 0~200 岁
方式 1: 创建表时
create table users(
u_id integer ,
u_name varchar ( 30 ),
u_sex char ( 10 ),
u_age int ,
check (u_age >= 0 and u_age <= 200 )
);
注意 :CHECK 子句会被分析,但是会被忽略。
原因 :CREATE TABLE 语法:接受这些子句但又忽略子句的原因是为了提高兼容性,以便更
容易地从其它 SQL 服务器中导入代码,并运行应用程序,创建带参考数据的表。
解决方案 : 枚举或触发器
默认约束
含义 : 保存数据时 , 未指定值则采用默认值
例子 : 创建图书表 , 设置封面地址默认为 xxx
create table books(
book_id integer ,
book_isbn char ( 4 ) unique ,
book_name varchar ( 10 ) not null ,
book_author varchar ( 6 ),
book_img varchar ( 100 ) default 'xxx'
);
主键约束
概念
就是数据表中记录的唯一标识,在一张表中只能有一个主键(主键可以是一个列,也可以
是多个列的组合)
含义 :
当一个字段声明为主键之后,添加数据时:
此字段数据不能为 null
此字段数据不能重复
例子 : 创建图书表 , 设置书籍 id(book_id)
create table books(
book_id integer primary key ,
book_isbn char ( 4 ) unique ,
book_name varchar ( 10 ) not null ,
book_author varchar ( 6 )
);
或
create table books(
book_id integer ,
book_isbn char ( 4 ) unique ,
book_name varchar ( 10 ) not null ,
book_author varchar ( 6 ),
primary key (book_id)
);
删除数据表主键约束
# 语法 :alter table 表名 drop primary key;
# 如 :
alter table books drop primary key ;
创建表之后添加主键约束
# 语法 :alter table 表名 modify 字段名 数据类型 primary key;
# 如 :
alter table books modify book_id integer primary key ;
自增长
在我们创建一张数据表时,如果数据表中有列可以作为主键(例如:学生表的学号、图书
表的 isbn )我们可以直接这是这个列为主键;
当有些数据表中没有合适的列作为主键时,我们可以额外定义一个与记录本身无关的列
( ID )作为主键,此列数据无具体的含义主要用于标识一条记录,在 mysql 中我们可以将此
列定义为 int ,同时设置为 自动增长 ,当我们向数据表中新增一条记录时,无需提供 ID 列的
值,它会自动生成
定义 int 类型字段自动增长: auto_increment
例子
create table types(
type_id int primary key auto_increment ,
type_name varchar ( 20 ) not null ,
type_remark varchar ( 100 )
);
注意:自动增长从 1 开始,每添加一条记录,自动的增长的列会自定 +1 ,当我们把某条记录
删除之后再添加数据,自动增长的数据也不会重复生成(自动增长只保证唯一性、不保证
连续性)
多表查询
语法: select 列名 1, 列名 2,.. from 表 1, 表 2,.. where 判断语句 ;
示例
-- 查看 stu 和 grade 表中的学生学号、姓名、班级、成绩信息
select s.*,g.* from stu s,grade g where s .id = g .stu_id ;
注意
没有条件会出现笛卡尔积
视图:虚拟表
概念
视图,就是由数据库中一张表或者多张表根据特定的条件查询出得数据构造成得虚拟表
优点
安全性:
如果我们直接将数据表授权给用户操作,那么用户可以CRUD 数据表中所有数据,加
入我们想要对数据表中的部分数据进行保护,可以将公开的数据生成视图,授权用户访
问视图;用户通过查询视图可以获取数据表中公开的数据,从而达到将数据表中的部分
数据对用户隐藏。
简单性:
如果我们需要查询的数据来源于多张数据表,可以使用多表连接查询来实现;我们
通过视图将这些连表查询的结果对用户开放,用户则可以直接通过查询视图获取多表数
据,操作更便捷。
数据独立:
一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没
有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。
创建视图
CREATE VIEW 视图名称 AS <SELECT语句>
示例
create view view_test1
AS
select * from students
查询视图结构
语法
DESC 视图名称;
示例:
desc view_test1;
修改视图
语法
create OR REPLACE view 视图名称
AS 查询语句
# 或
alter view 视图名称
AS 查询语句
示例
# 方式1
create OR REPLACE view view_test1
AS
select * from students where stu_gender='女';
# 方式2
alter view view_test1
AS
select * from students where stu_gender='男';特性
视图是虚拟表,查询视图的数据是来源于数据表的。当对视图进行操作时,对原数据表中的数据是否由影响呢?
查询操作 :如果在数据表中添加了新的数据,而且这个数据满足创建视图时查询语句的条件,通过查询视图也可以查询出新增的数据;当删除原表中满足查询条件的数据时,也会从视图中删除。
新增数据: 如果在视图中添加数据,数据会被添加到原数据表
删除数据: 如果从视图删除数据,数据也将从原表中删除
修改操作: 如果通过修改数据,则也将修改原数据表中的数据
视图的使用建议 : 对复杂查询简化操作,并且不会对数据进行修改的情况下可以使用视图。
触发器
概念
触发器是数据库的回调函数,它会在指定的数据库事件发生时自动执行调用
1、只有每当执行 delete , insert 或 update 操作时,才会触发,并执行指定的一条或多条SQL 语句。
例如:
可以设置触发器,当删除persons表中 lucy 的信息时,自动删除 grade 表中与lucy相关的信息
2、触发器常用于保证数据一致,以及每当更新或删除表时,将记录写入日志表
创建触发器
语法:
-- 语法 :
-- 修改 sql 语句结束符为 ||
delimiter ||
-- 创建触发器
create trigger 触发器名 [after|before] [ delete |update|insert] on 表名
for each row
begin
语句 ;
end ||
delimiter ;
old: 老数据
new: 新数据
示例
-- 删除 stu 表中的数据 , 同时删除 grade 表中 stu_id 相同的数据
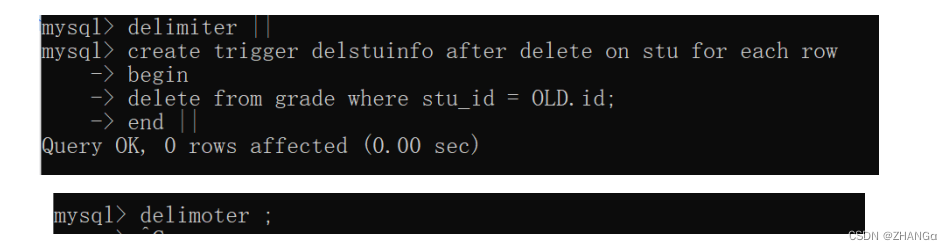
查看触发器
语法:
show triggers;
删除触发器
drop trigger 触发器名;
c语言操作MySQL
API
注意
1, 需要安装 mysql 相关库 , 安装命令如下
Ubuntu16/18: sudo apt-get install libmysqld-dev
Ubuntu20: sudo apt-get install libmysqlclient-dev
2, 编译时需要加 mysqlclient
gcc 源文件名 .c -l mysqlclient
初始化
所需头文件
#include <mysql/mysql.h>
函数 :
MYSQL *mysql_init(MYSQL *mysql)
描述:
分配或初始化与 mysql_real_connect() 相适应的 MYSQL 对象
参数:
mysql:MYSQL* 句柄
返回值:
初始化的 MYSQL* 句柄。如果无足够内存以分配新的对象,返回 NULL 。
设置编码
函数 :
int mysql_set_character_set(MYSQL *mysql, const char *csname);
参数 :
mysql:MYSQL* 句柄
csname: 编码格式
如 :
mysql_set_character_set(&mysql,"utf8");
获取连接
所需头文件
#include <mysql/mysql.h>
函数 :
MYSQL *mysql_real_connect(MYSQL *mysql,
const char *host,
const char *user,
const char *passwd,
const char *db,
unsigned int port,
const char *unix_socket,
unsigned long client_flag);
描述 :
mysql_real_connect()尝试与运行在主机上的 MySQL 数据库引擎建立连接。
参数 :
mysql:MySQL句柄
host:“host”的值必须是主机名或 IP 地址 . 如果 “host” 是 NULL 或字符串"localhost" 、 ”127.0.0.1” ,连接将被视为与本地主机的连接 .
user:MySQL登录的用户名
passwd: MySQL登录的密码
db:数据库名称
port:MySQL服务器监听客户端连接到来的端口号(默认: 3306 )
unix_socket:如果 unix_socket 不是 NULL ,该字符串描述了应使用的套接字或命名管道(默认为NULL)
client_flag: 通常为 0 ,可以更改其值,以允许特定功能(详情见手册)
返回值:
如果连接成功,返回MYSQL* 连接句柄。返回值与第 1 个参数的值相同。
如果连接失败,返回NULL 。
执行SQL语句
无操作结果 : 如建库 , 建表 , 增加 , 删除 , 修改等语句
所需头文件 :
#include <mysql/mysql.h>
函数 :
int mysql_real_query(MYSQL *mysql,const char * query,unsigned long length)
描述 :
执行由“query” 指向的 SQL 查询 , 它应是字符串长度字节 “long”. 正常情况下 , 字符串必须包含1 条 SQL 语句 , 而且不应为语句添加终结分号( ‘;’ )或 “\g”. 如果允许多语句执行, 字符串可包含由分号隔开的多条语句 .
参数 :
mysql:MySQL句柄
query:需要执行的 MySQL 语句
length:需要执行的 MySQL 语句的长度
返回值 :
如果查询成功,返回0 。
如果查询失败,返回非0 值
有操作结果 : 如查询语句
所需头文件 :
#include <mysql/mysql.h>
函数 :
MYSQL_RES *mysql_store_result(MYSQL *mysql)
描述:
对于成功检索了数据的每个查询(SELECT 、 SHOW 、 DESCRIBE 、 EXPLAIN 、 CHECK
TABLE 等),必须调 用 mysql_store_result() 或 mysql_use_result() 。 对于其他查询,不需要调用mysql_store_result() 或 mysql_use_result() ,但是如果在任何情况下均调用 mysql_store_result() ,它也不会导致任何伤害或性能降低。通过检查mysql_store_result() 是否返回 0 ,可检测查询 是否没有结果集(以后会更多)
参数 :
Mysql:MySQL句柄
返回值 :
成功 返回具有多个结果的MYSQL_RES 结果集合。
失败 返回NULL
查询结果集
获取结果集中的列数
所需头文件 :
#include <mysql/mysql.h>
函数 :
unsigned int mysql_num_fields(MYSQL_RES *result)
描述 :
返回结果集中的列数
参数 :
result:MYSQL_RES结果集句柄
返回值 :
表示结果集中行数的无符号整数
获取结果集中的行数
所需头文件 :
#include <mysql/mysql.h>
函数 :
my_ulonglong mysql_num_rows(MYSQL_RES *result)
描述 :
返回结果集中的行数
参数 :
result:MYSQL_RES结果集句柄
返回值 :
结果集中的行数
获取结果集中的列名称
所需头文件 :
#include <mysql/mysql.h>
函数 :
MYSQL_FIELD * mysql_fetch_field(MYSQL_RES *result)
描述 :
返回采用MYSQL_FIELD 结构的结果集的列。重复调用该函数,以检索关于结果集中所有列的信息。未剩余字段时,mysql_fetch_field() 返回 NULL 。
参数 :
result:MYSQL_RES结果集句柄
返回值 :
当前列的MYSQL_FIELD 结构。如果未剩余任何列,返回 NULL
获取结果集中的每行的数据(重要)
所需头文件 :
#include <mysql/mysql.h>
函数 :
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result)
描述 :
检索结果集的下一行。在mysql_store_result() 之后使用时,如果没有要检索的行,mysql_fetch_row() 返回 NULL
参数 :
MYSQL_RES结果集句柄
返回值 :
下一行的MYSQL_ROW 结构。如果没有更多要检索的行或出现了错误,返回 NULL
释放资源
释放结果集
所需头文件 :
#include <mysql/mysql.h>
函数 :
void mysql_free_result(MYSQL_RES *result)
描述 :
释放由mysql_store_result() 、 mysql_use_result() 、 mysql_list_dbs() 等为结果集分配的内存。完成对结果集的操作后,必须调用mysql_free_result() 释放结果集使用的内存
参数 :
MYSQL_RES结果集句柄
返回值 :
无
释放MySQL句柄
所需头文件 :
#include <mysql/mysql.h>
函数 :
void mysql_close(MYSQL *mysql)
描述 :
关闭前面打开的连接。如果句柄是由mysql_init() 或 mysql_connect() 自动分配的,mysql_close() 还将解除分配由 mysql 指向的连接句柄
参数 :
MySQL连接句柄
返回值 :
无
示例DML
示例DML
#include <stdio.h>
#include <mysql/mysql.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char const *argv[])
{MYSQL mysql;mysql_init(&mysql);mysql_set_character_set(&mysql,"UTF8");MYSQL *tag = mysql_real_connect(&mysql,"10.12.152.71","root","027027","mtdata",3306,NULL,0);if(tag == NULL){printf("连接失败\n");return 0;}else{printf("连接成功\n");}//执行sql语句
char *sql_str = "select *from user";
mysql_query(&mysql,sql_str);
MYSQL_RES *res = mysql_store_result(&mysql);
if(res == NULL)
{printf("为空\n");return 0;
}
int column = mysql_num_fields(res);
int row = mysql_num_rows(res);
for(int i = 0;i < row;i++)
{MYSQL_ROW row_data= mysql_fetch_row(res);for(int j=0;j < column;j++){printf("%s\t",row_data[j]);}printf("\n");
}
mysql_free_result(res);return 0;
}示例DQL
#include <stdio.h>
#include <mysql/mysql.h>
int main(int argc, char const *argv[])
{/*总结步骤:执行dql的步骤1,定义MYSQL结构体变量2,初始化MYSQL结构体变量 mysql_init3,设置编码格式:mysql_set_character_set4,打开mysql连接:mysql_real_connect5,执行sql语句:mysql_query6,获取查找的结果集7,通过步骤5的返回值,获取查询到的数据mysql_num_rows:获取结果集中的行数mysql_num_fields:获取结果集中的列数mysql_fetch_field:获取列名mysql_fetch_row:获取每一行的数据8,关闭结果集:mysql_free_result9,关闭连接:mysql_close*/MYSQL mysql;mysql_init(&mysql);mysql_set_character_set(&mysql,"utf8");MYSQL *tag = mysql_real_connect(&mysql,"10.12.152.71","root","027027","mtdata",3306,NULL,0);if(tag == NULL){printf("连接失败\n");}elseprintf("连接成功\n");char sql[] = "select * from user";mysql_query(&mysql,sql);MYSQL_RES *res = mysql_store_result(&mysql);int row = mysql_num_rows(res);printf("row = %d\n",row);int lie = mysql_num_fields(res);printf("lie = %d\n",lie);for (int i = 0; i < row; i++){//获取一行的数据MYSQL_ROW r = mysql_fetch_row(res);for (int j = 0; j < lie; j++){char * str = r[j];printf("%s\t",str);}printf("\n");}mysql_free_result(res);mysql_close(&mysql);return 0;
}