【IC前端虚拟项目】数据搬运指令处理模块前端实现虚拟项目说明-CSDN博客
mvu这个模块是干嘛用的呢?从这个名字就可以看出来move_unit,应该是做数据搬运的。很多指令级中都会有数据搬运的指令,这类指令的作用一般是在片内片外缓存以及通用专用寄存器之间搬运数据,比如典型的riscv里的load/store指令。
而mvu这个模块处理的指令就是move指令,指令的作用是在ram和ddr之间搬运数据。比如需要做三维卷积,那么可能需要把特征和权重先从ddr读到ram里进行计算,计算完成后再把卷积结果从ram读回到ddr上,这种场景就是mvu要做的事情了。
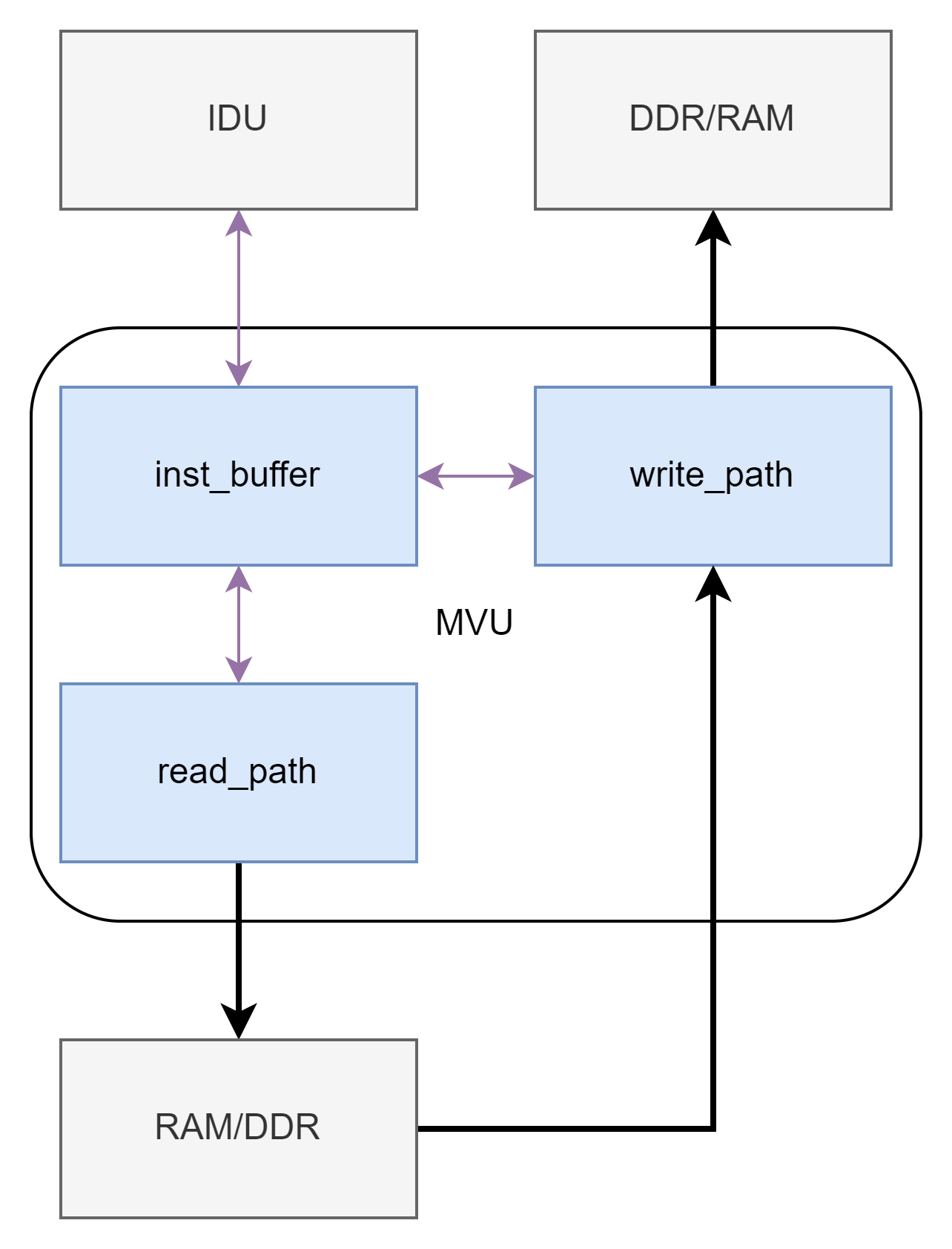
mvu上游的模块是idu,顾名思义就是inst_decode_unit,指令解码模块。众所周知,处理器的处理流程包括取指、译码、执行、写回、提交等,idu负责的就是译码。 idu接收到指令后对指令进行分析,发现这是一条move指令之后,将指令发送给mvu有mvu负责处理。mvu根据指令进行数据的搬运,将所有的数据搬运完成后向idu进行指令提交。
简单点来说mvu就实现5个功能:
1.接收idu下发的move指令;
2.根据指令读ddr/ram;
3.将读回的数据摆放在合理的位置;
4.根据指令把摆好的数据写回ddr/ram;
5.提交指令;
功能并不复杂,不过corner的点其实不算少。因为axi读写地址是根据数据位宽对齐的,而指令中的读写地址是按Byte对齐的,因此把读回来的数据偏移、拼接形成写数据的过程,时序上还是比较复杂的,尤其当总线位宽比较大时。
对于这个项目,基本的设计要求有如下几个:
1.缓存指令最多为数量8个,避免资源浪费;
2.单指令内通路没有反压场景下,ar/aw/w通路不应该有空拍;
3.指令间ar/aw/w允许有空拍,也可以尝试设计指令间无空拍的结构;
4.inst对应的aw/w除第一笔和最后一笔外,其他strb不允许出现0;
在此基础上,可以进一步的优化面积时序以及功能:
1.AXI相关为参数化设计,尝试对128/256/512/1024四种不同位宽在400M/800M两种时钟频率下收时序;
2.降低复位寄存器比例,提高clk_gating比例;
我自己完成的代码在90nm工艺下跑1G时钟,最大时序违规是-260ps,这个数字还是挺大的,应该说优化空间很大。在实际的项目中我们一般要求时序违规在-100ps以下即可满足要求,不过虚拟项目里,还是尽量把违规时序收到0吧。
此外,mvu模块中还引入了寄存器单元,通过寄存器进行相关的配置和模块状态的反馈。通过这部分练习,能够系统的掌握寄存器单元的设计、实现与仿真。