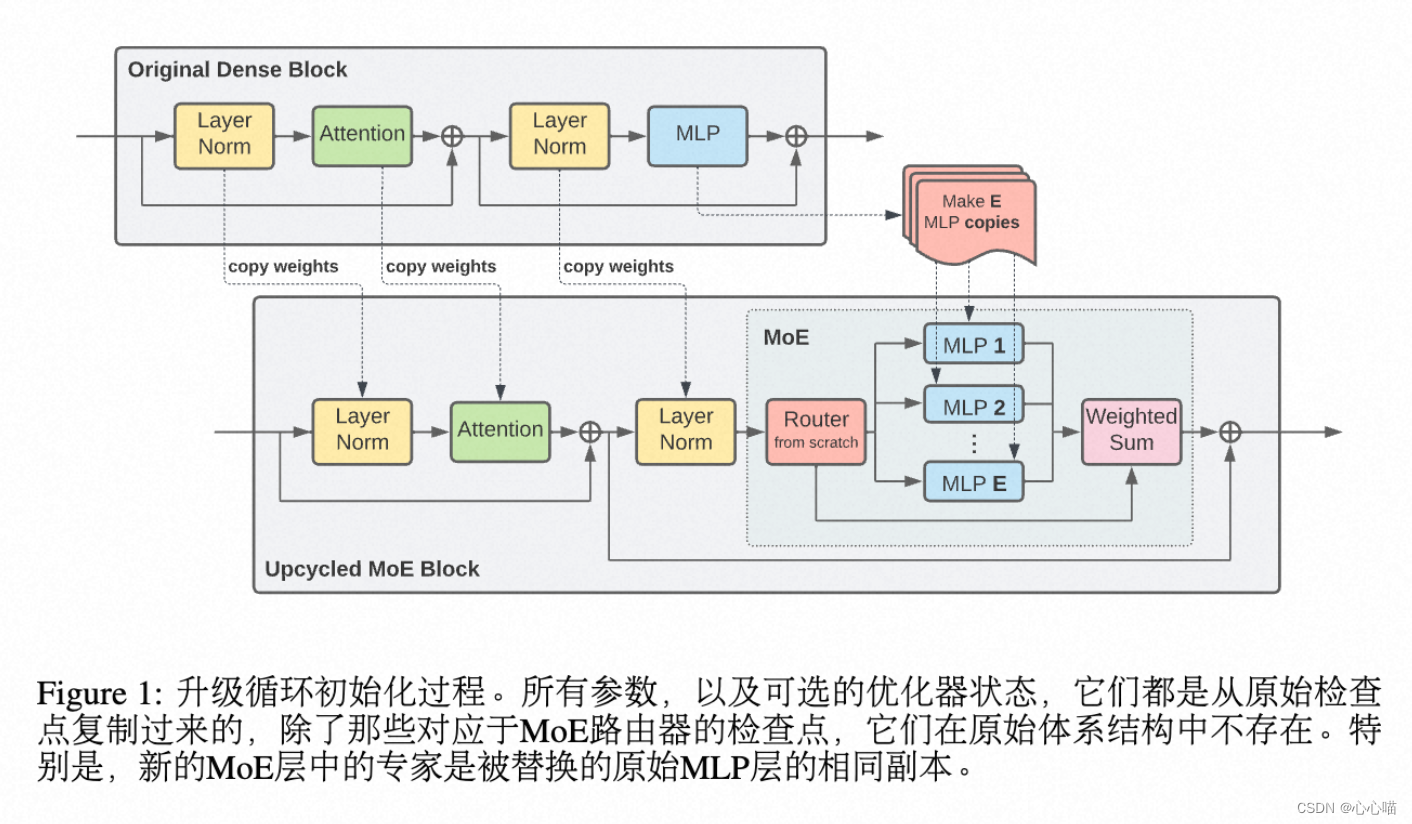
SparseMOE: 稀疏激活的MOE
Swtich MOE,所有token要在K个专家网络中,选择一个专家网络。
显存增加。

Experts Choice:路由MOE:
由专家选择token。这样不同的专家都选择到某个token,也可以不选择该token。
由于FFN层的时间复杂度和attention层不同,FFN层的时间复杂度在O(N*d),N是输入长度,d是隐层纬度。attention层的时间复杂度在O(N^2*d)。
所以这样操作没能减小计算量。参数量也是多了几个Expert的参数量。
论文里的效果比SparseMOE更好。显存增加。
Tokens Choice:路由MOE:
由token选择专家。每个token只能进到一个专家里。没有t





![[Kubernetes]3. k8s集群Service详解](https://img-blog.csdnimg.cn/direct/0f90740aef3c4283b109aa8ba52519fe.png)