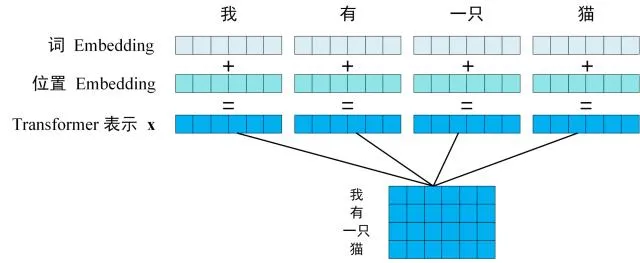
在 ChatGPT 引爆社会与学术界的热点后,“大模型”与“多模态”也成为了搜索量攀升的热门词汇。这些体现了大众对人工智能的广泛关注。
事实上,人工智能的进步离不开深度学习方法在各个具体任务上的进展。其中,尤其是预训练任务的方法,对人工智能的进步有着重要推进作用。而在各类预训练任务中,模型性能受预训练数据集质量的影响显著。
其中,为了获取通用的多模态知识,视觉-语言预训练任务主要使用带有弱标签的视觉-语言对进行模型训练。图像-文本任务主要为图像及标题、内容描述和人物的动作描述等。
本文根据《视觉语言多模态预训练综述》[1]一文,提供了一系列常用预训练数据集及其在OpenDataLab上的下载链接。
SBU数据集
SBU(Ordonez等,2011)数据集:
SBU是较为早期的大规模图像描述数据集。收集数据时,先使用对象、属性、动作、物品和场景查询词对图片分享网站Flickr进行查询,得到大量携带相关文本的照片,然后根据描述相关性和视觉描述性进行过滤,并保留包含至少两个拟定术语作为描述。
下载地址:
https://opendatalab.org.cn/SBU_Captions_Dataset/download
COCO数据集
COCO(Lin等,2014)数据集:
COCO是一个大型、丰富的物体检测、分割和描述数据集。数据集以场景理解为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的分割进行位置标定,含91个常见对象类别,其中82类有超过5000个标签实例,共含32.8万幅图像和250万个标签实例。COCO Captions(Chen等,2015)在COCO图片数据的基础上由人工标注图片描述得到。
下载地址:
https://opendatalab.org.cn/COCO_2014/download
Conceptual Captions数据集
Conceptual Captions为从互联网获取的图文数据集。首先按格式、大小、内容和条件筛选图像和文本,根据文字内容能否较好地匹配图像内容过滤图文对,对文本中使用外部信息源的部分利用谷歌知识图谱进行转换处理,最后进行人工抽样检验和清理,获得最终数据集。Changpinyo等人(2021)基于Conceptual Captions将数据集的规模从330万增加到了1200万,提出了Conceptual12M。
下载地址:
https://opendatalab.org.cn/Conceptual_Captions/download
HowTo100M数据集
HowTo100M的内容为面向复杂任务的教学视频,其大多数叙述能够描述所观察到的视觉内容,并且把主要动词限制在与真实世界有互动的视觉任务上。字幕主要由ASR生成,以每一行字幕作为描述,并将其与该行对应的时间间隔中的视频剪辑配对。How To100M比此前的视频预训练数据集大几个数量级,包含视频总时长15年,平均时长6.5min,平均一段视频产生110对剪辑-标题,其中剪辑平均时长4s,标题平均长4个单词。
下载地址:
https://opendatalab.org.cn/HowTo100M/download
YT-Temporal-180M数据集
YT-Temporal-180M覆盖的视频类型丰富,包括来自HowTo100M(Miech等,2019)的教学视频,来自VLOG(Fouhey等,2018)的日常生活记录短视频,以及Youtube上自动生成的热门话题推荐视频,如“科学”、“家装”等。对共计2700万候选数据按如下条件删除视频:
1)不含英文ASR文字描述内容;
2)时长超过20min;
3)视觉上内容类别无法找到根据,如视频游戏评论等;
4)利用图像分类器检测视频缩略图剔除不太可能包含目标对象的视频。最后,还会应用序列到序列的模型为ASR生成的文本添加标点符号。
下载地址:
https://opendatalab.com/YT-Temporal-180M
WebVid-2M数据集
由于ASR生成的句子通常不完整,且没有标点符号,更重要的是不一定与图像内容完全对齐,所以Bain等人(2021)针对这一问题对抓取的网络视频进行人工标注,使得描述文本词汇丰富、格式良好且与视频视觉内容对齐,提出了WebVid-2M(Bain等,2021)数据集。
下载地址:
https://opendatalab.com/WebVid-2M
VQA,VQAv2.0,GQA数据集
一些研究(Tan和Bansal,2019;Cho等,2021;Zhang等,2021a)从VQA,VQAv2.0,GQA这类问答数据集获取预训练数据。使用时不包含测试数据,一般将问题描述与答案句子作为文本输入,与图像构成图文对,从而进行模态间的预训练。
下载地址:
https://opendatalab.com/VQA
https://opendatalab.org.cn/VQA-v2.0/download
https://opendatalab.org.cn/GQA/download
引用
[1] 张浩宇,王天保,李孟择,赵洲,浦世亮,吴飞.视觉语言多模态预训练综述[J].中国图象图形学报,2022,27(09):2652-2682.
-END-
更多数据集,欢迎访问OpenDataLab官网:https://opendatalab.org.cn/
没有想要的数据集,怎么办?
如果在平台没有找到您想要的数据集资源,欢迎扫描下方二维码,记录您的需求,我们会努力为您提供相关支持。