更多资料获取
📚 个人网站:ipengtao.com
Apache Flink 是一个流式处理框架,支持复杂事件处理和大规模数据分析。在 Flink 中,合流(Join)是一种常见的操作,用于将两个或多个流中的数据按照指定条件进行关联。本文将深入探讨 PyFlink 中合流的基本操作,包括合流的类型、操作方法、常见应用场景以及实例代码,以帮助读者更好地理解和运用 PyFlink 中的合流操作。
1. 合流的类型
在 PyFlink 中,合流有两种基本类型:内连接和外连接。理解这两种类型是进行合流操作的关键。
1.1 内连接(Inner Join)
内连接是合流操作中最常见的一种。它仅保留两个流中满足指定条件的元素,过滤掉不满足条件的元素。
1.2 外连接(Outer Join)
外连接包括左外连接、右外连接和全外连接。外连接会保留满足条件的元素,并用空值填充未满足条件的元素。
- 左外连接(Left Outer Join):保留左边流中的所有元素,右边流中没有匹配的元素用空值填充。
- 右外连接(Right Outer Join):保留右边流中的所有元素,左边流中没有匹配的元素用空值填充。
- 全外连接(Full Outer Join):保留两个流中的所有元素,不匹配的元素用空值填充。
2. 合流操作方法
PyFlink 提供了丰富的 API 来执行合流操作,以下是常用的合流操作方法:
2.1 Connect 和 CoMap
Connect 操作用于将两个流连接在一起,然后通过 CoMap 操作对连接后的流进行转换。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import SimpleStringSchema
from pyflink.datastream.functions import KeyedProcessFunction
from pyflink.datastream.processfunction import CoProcessFunction
from pyflink.datastream.util import Collectorenv = StreamExecutionEnvironment.get_execution_environment()# 创建两个流
stream1 = env.from_elements((1, "Alice", 25))
stream2 = env.from_elements((1, "Alice", "Female"))# 使用Connect将两个流连接
connected_streams = stream1.connect(stream2)# 使用CoMap对连接后的流进行转换
result_stream = connected_streams.map(# 定义CoMap函数CoProcessFunction().on_timer(1) # 定义定时器.process_element(lambda value, ctx, out: out.collect(value),SimpleStringSchema())
)result_stream.print()env.execute("Connect and CoMap Example")
2.2 KeyedStream 的 Join
KeyedStream 的 Join 操作是常见的合流方法之一,它允许按照指定的键进行连接。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import SimpleStringSchema
from pyflink.datastream.functions import KeyedProcessFunction
from pyflink.datastream.processfunction import CoProcessFunction
from pyflink.datastream.util import Collectorenv = StreamExecutionEnvironment.get_execution_environment()# 创建两个KeyedStream
stream1 = env.from_elements((1, "Alice", 25)).key_by(0)
stream2 = env.from_elements((1, "Alice", "Female")).key_by(0)# 使用KeyedStream的Join进行连接
result_stream = stream1.join(stream2).where(0).equal_to(0).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).apply(lambda value1, value2: value1,SimpleStringSchema()
)result_stream.print()env.execute("KeyedStream Join Example")
3. 应用场景
合流在实际应用中有着广泛的应用场景,以下是一些常见的应用场景:
3.1 数据关联
在流式数据处理中,不同流的数据可能需要进行关联,以便获取更丰富的信息。合流操作可以用于将这些相关的数据进行连接,形成更有价值的结果。
3.2 实时计算
合流操作也常用于实时计算任务,例如将两个实时流中的数据按照某种条件进行关联,生成实时计算的结果。
3.3 异常检测
通过合流操作,可以将正常数据流与异常数据流进行连接,从而实现异常检测。例如,通过左外连接找出未匹配的数据,即为异常数据。
4. 示例代码
下面是一个综合示例,演示了如何使用 PyFlink 进行合流操作。这个例子中,我们模拟了两个用户信息流,一个包含用户的基本信息,另一个包含用户的额外信息。我们通过用户ID进行内连接,获取完整的用户信息。
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.connectors import SimpleStringSchema
from pyflink.datastream.functions import CoProcessFunction
from pyflink.datastream.util import Collectorenv = StreamExecutionEnvironment.get_execution_environment()# 模拟用户基本信息流
basic_info_stream = env.from_elements((1, "Alice", 25), (2, "Bob", 30)).key_by(0)
# 模拟用户额外信息流
extra_info_stream = env.from_elements((1, "Alice", "Female"), (2, "Bob", "Male")).key_by(0)# 内连接操作,获取完整的用户信息
result_stream = basic_info_stream.connect(extra_info_stream).key_by(0, 0).process(CoProcessFunction().on_timer(1) # 定义定时器.process_element(lambda value, ctx, out: out.collect(value),SimpleStringSchema())
)result_stream.print()env.execute("Join Example")
总结
本文深入介绍了 PyFlink 中合流的基本操作,包括合流的类型、操作方法、常见应用场景以及详细的示例代码。合流作为流式处理的重要操作之一,广泛应用于实时计算、数据关联和异常检测等领域。通过深入理解合流的原理和使用方法,可以更好地应用 PyFlink 进行流式数据处理。希望本文能为大家在 PyFlink 中的合流操作提供实用的指导。
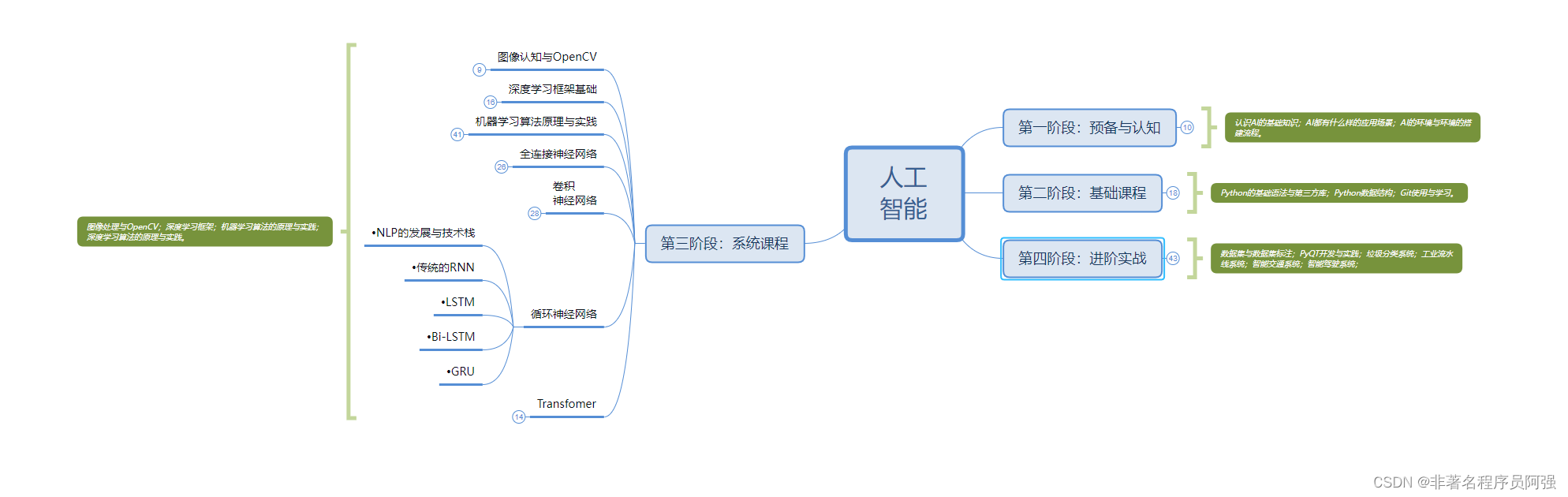
Python学习路线

更多资料获取
📚 个人网站:ipengtao.com
如果还想要领取更多更丰富的资料,可以点击文章下方名片,回复【优质资料】,即可获取 全方位学习资料包。

点击文章下方链接卡片,回复【优质资料】,可直接领取资料大礼包。








![[德人合科技]——设计公司 \ 设计院图纸文件数据 | 资料透明加密防泄密软件](https://img-blog.csdnimg.cn/direct/6f3a5fd395b345839019cd82fe904d3a.gif)