引言:
大模型落地到当前这个阶段,核心关注点还是领域大模型,而领域大模型落地的前提在于两点:需求端,对当前应用的降本增效以及新应用的探索;供给端,训练技术已经有较高的成熟度。
专家介绍:

柏海峰
滴普科技 Deepexi产品线总裁
负责企业大模型产品的规划、技术架构设计和应用解决方案的全体系打造,承担公司基础产品核心竞争力及创新力的构建。拥有丰富的企业数字化转型咨询与实施和产品研发管理经验,曾任华为技术研发经理、微软中国顾问、IBM(GBS)咨询总监以及营销云SaaS产品创业经验,服务过中移动、华润、工商银行等多个世界500强企业。
降本增效方面,以机器学习团队的构成为例,滴普科技Deepexi产品线总裁柏海峰介绍道:“传统机器学习或者说小模型的技术落地,对人才的要求很高,但企业往往没有意识到这个问题。具体来说,一般需要构建一个综合性的团队即数据科学团队,团队中需要数据开发工程师、BI工程师、商业分析师、数据科学家、算法工程师等岗位,人力成本很高,除了互联网、金融行业的大型企业,传统企业或中小型企业很难组建这样的团队。”
人才要求高的原因在于,不同岗位的技能差异非常大,相关工具和技术栈也比较分散,比如在某个具体应用领域的AI模型也是采用不同的算法,数据处理层面的pipeline,很多时候自动化的实现也不够完善。总之,不同的钉子只能用不同的锤子,而每一把锤子都不便宜。
因此,尽管小模型对算力、数据要求没有那么高,但要调出好的效果,复杂度还是很高的。除了技术因素,在团队协作和业务适配方面,也还有很多难题。
“大模型带来的首要好处就是,它一下子把技术门槛拉低了,把整个技术栈从输入到输出的链条变得很短,原本需要很多人的数据科学团队,变成只需要一个人加多个Copilot就可以完成,这个人甚至可以是业务部门的,这是非常有想象力的。”
训练技术方面,大模型一般都是先进行self supervised learning,构建通用大模型,然后经过supervised fine-tuning训练,针对特定任务,构建领域大模型初版,最后通过RLHF训练,对齐人类价值,完成类似于人类学习成长的解题、实习、社会工作三步曲。

其中后两步是大模型微调并构建领域大模型的主要步骤,可以把训练前回答问题很散漫的通用大模型Llama 2 13B,训练成专业性很强的chatbot——Llama 2 13B-chat。
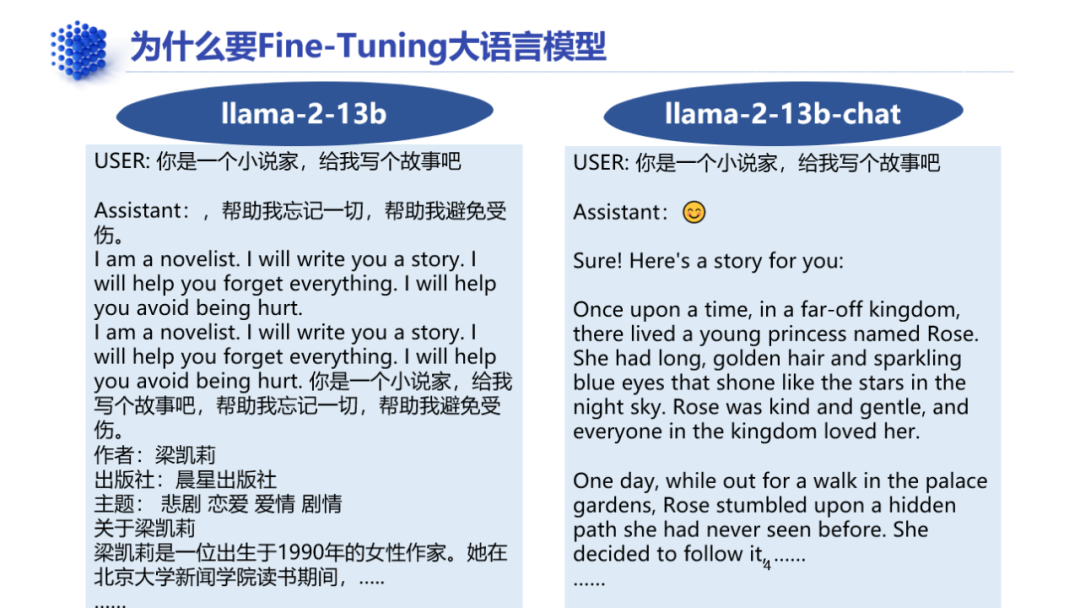
微调可以减少大模型的幻觉,增加模型输出的一致性、专业性,并且只需要通用模型训练的千分之一或者万分之一的数据量。

需求端和供给端条件具备,商业模式就有了雏形,那么,企业要发挥的作用就是,效能建设。
▼01.效能建设:数据为道、模型为术
效能建设的核心变量,在于数据治理。但这个“数据”,和大数据时代的“数据”,内涵又有很大不同。
传统的数据治理,针对数据分析场景,主要面向结构化数据,包括主动元数据、AI增强治理等技术,已成比较成熟的体系。
而数据治理的新内涵,面向大模型训练常见的非结构化数据。
非结构化数据治理的首要难题是,高质量的领域数据获取的成本。
大模型微调的典型方法是instruction fine tuning,也就是指令微调,ChatGPT和Llama 2都是指令微调的产物。指令微调采用的数据,就是prompt加上response的问答对,要么由更强大的大模型比如GPT-4生成,要么由人工生成。
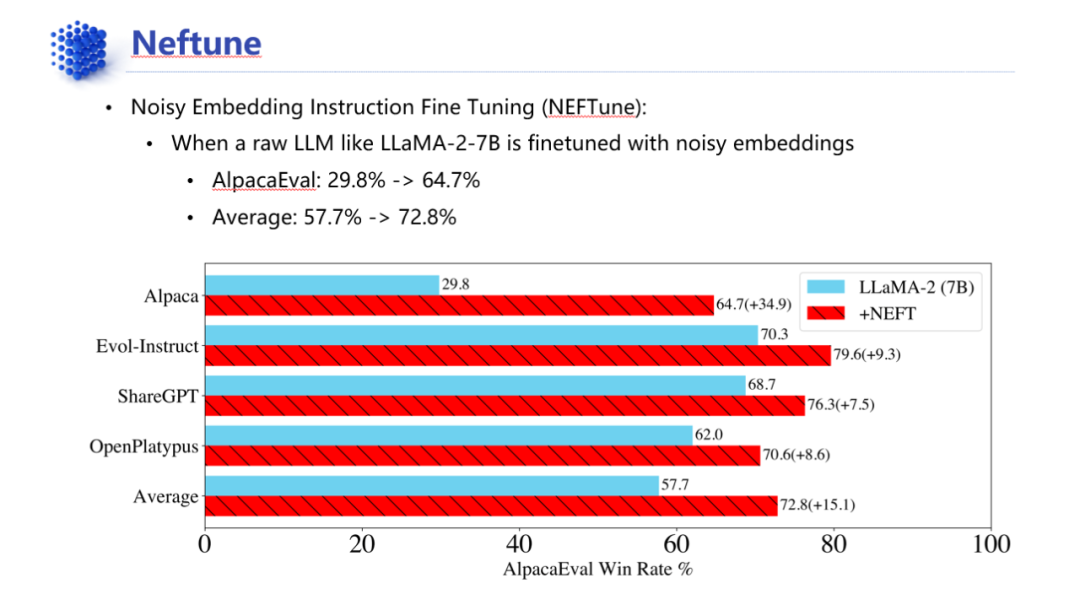
进一步的微调强化还可以采用Explanation Tuning——解释微调,这是一种数据增强技术,主要是通过成熟的大模型将对prompt的回答进行step by step的拆解,从而获得更容易理解的数据。这主要是基于这样的经验,即提示大模型一步一步拆解问题并解答,可以显著提高准确率。此外,还存在像Neftune这种通过将数据经过模型添加噪声之后再进行训练,就能显著增加推理准确率的魔法一般的数据增强技术。
除了增强,AI模型也可以反过来帮助将杂乱的非结构化数据进行压缩提炼,提取知识。一般来说,可以在公网中使用Claude2、GPT-4、GPT-3.5(ChatGPT),以prompt的形式将数据进行信息提取,就可以把大量的文档数据变成结构化的知识。如果企业考虑到数据安全的问题,就可以在本地部署Llama 2 13B、ChatGLM2 6B等本地大模型,来处理这些文档。
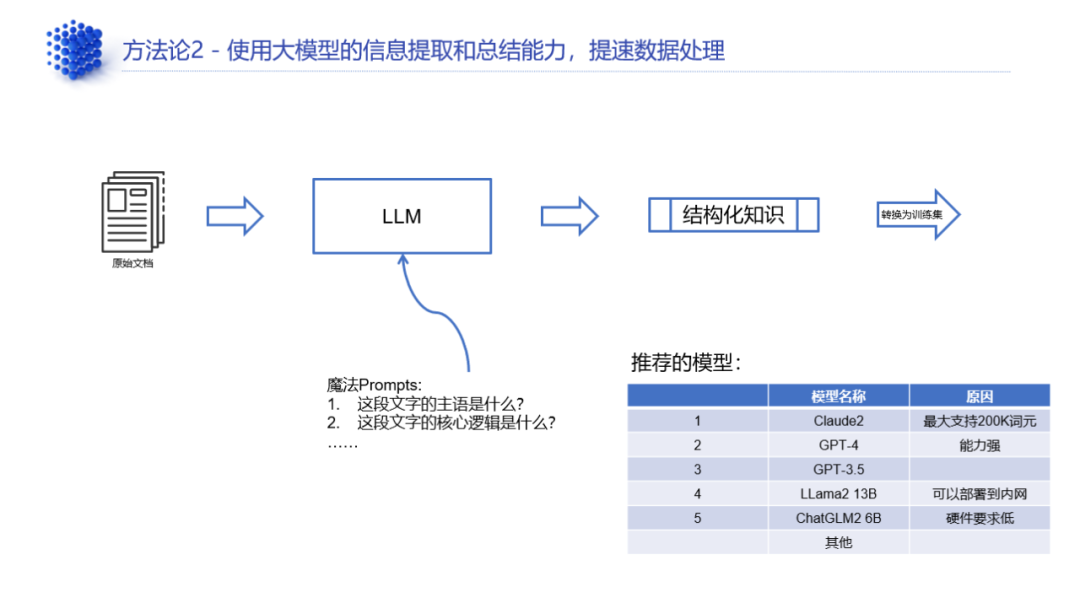
也就是说,非结构化数据其实在很大程度上正在借助已有的成熟模型来处理,其中包括了小模型和大模型。
“比如说在石化行业的数据有很大部分都是多模态的,包括勘探钻井时收集的图像数据、地震探测中收集的地理数据、安全监控视频的数据、物联网IoT数据等等,非常复杂。这些数据要得到利用,就要通过小模型、大模型的技术从里面提取出显性的、隐性的知识,从而能够让被训练的大模型也能够看懂,这就是非结构化数据的治理方法。”
采用大模型、小模型来代替人力从非结构化数据中提取高质量数据,可以极大降低人力处理的成本。
业内对大模型一直有着这样的质疑声音,认为现在的大模型就是把小模型做过的事情重做一遍,“但实际上,大模型和小模型形成了层次更丰富的模型栈,各自发挥所长,才能把效率最大化。”
不同规模、不同能力的AI模型,仿佛构成了一个内部生态。在训练时,它们之间使用数据进行交流,增强终端大模型的能力。在推理时,大模型又成了决策枢纽,通过prompt的交流来规划任务。
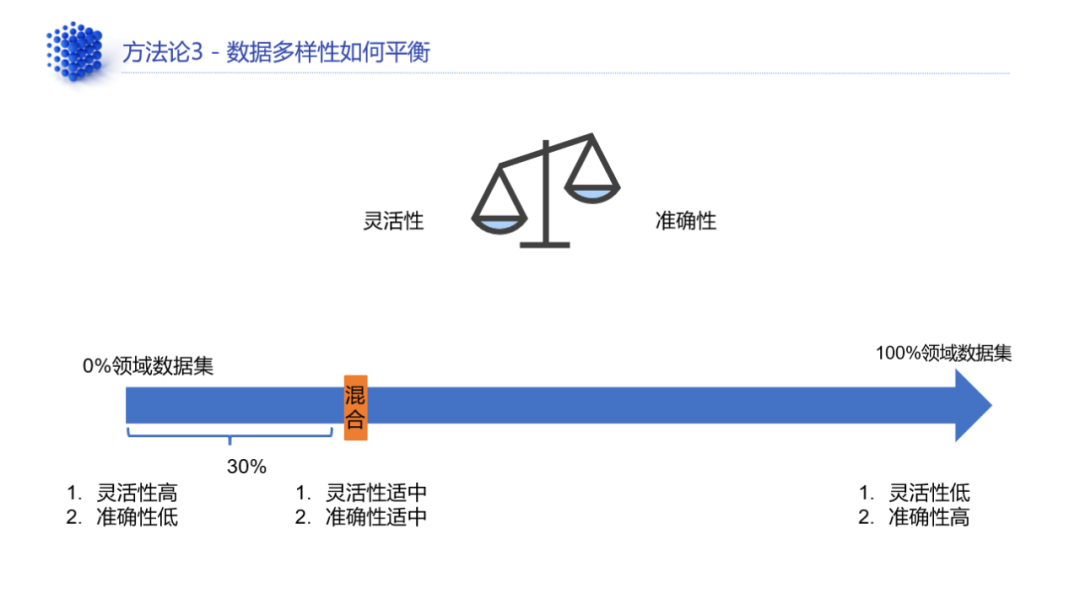
▼02.数据集的平衡:准确率 vs 多样性
数据集质量的评估是多维度的,需要平衡几项因素:灵活性、多样性和准确率。
其中,灵活性、多样性是指模型面对变化多样的prompt也能给出一致的回答,这在通用大模型应用中很常见。而领域数据之所以对质量要求高,也是因为对准确率要求很高。
“比如Text to SQL这样的场景,行业属性很强,对准确率要求也很高。目前行业相关应用的准确率普遍不高,ChatGPT也不到80%。而准确率不超过80%,在生产环境是不能应用的。“
此外,考虑到通用大模型的训练数据在灵活性、多样性上最高,准确率最低,小模型则相反,领域大模型其实处于两者之间,因此必须对这几项因素进行平衡。
滴普科技在实践中发现,在训练数据集中如果领域数据集占30%,通用数据集占70%,训练出来的领域大模型更能够兼顾灵活性、多样性和准确性。这个平衡又进一步降低了数据的总体获取成本。
▼03.数据类型:另一个维度
数据类型的划分,除了质量,还可以从知识表示的形式进行划分,不同形式对应不同的训练方法。
数据或任务通常包含两大类型,第一种属于重表示型,比如把对Java线程的解释进行重新表述,第二种属于知识问答型,比如如果不知道授信额度的准确定义,就无法回答一些相关知识问答。

相比之下,第二种任务对模型的要求更高,因为有知识增量,需要对模型参数进行较大的调整。
针对第一种任务,模型微调常采用高效微调的方式,比如LoRA、QLoRA、P-tuning等,保留大模型原有参数,在模型前方或后方添加新的神经网络层以改善推理,成本更低;针对第二种任务,则采用全参微调的方式,对硬件要求高,主要在于内存量,比如Llama 2 13B的全参微调至少需要一块80G内存的A800,Llama 2 7B则至少需要一块24G内存的RTX4090,才能完成训练,并且为防止过拟合,对数据集的要求也更高。

领域大模型偏重知识型任务,一般而言全参微调是必不可少的。但任务本身也分层次,底层是统计分析型,顶层是预测型。统计分析型任务更基础,对准确性要求高,比如文本分类、意图识别、实体关系提取等,预测型相比之下对准确性要求更低一些。
这在Text to SQL任务中也有体现,“统计分析是what happen,预测分析是why happen,后者的准确率一般没法达到100%。”
当然,要求是一方面,收益是另一方面,如果在高级任务中能获得更强的能力,也将成为领域大模型的技术壁垒,为此,在滴普科技的5维模型基础能力评估模型中,把理解偶一、句法分析能力等高级能力维度放到了更高的权重。

▼04.产品体系:效率、性能与体验兼顾
所以,效率是一方面,性能是另一方面。企业做产品,除了提升效率来保证落地,也要在保证效率前提下提升性能,才能最大程度上保证用户体验。
比如,Text to SQL产生的SQL语句是让大模型来执行还是让传统工具来执行,也是个问题,”现在常见的大模型演示中,人们都是上传一个数据集,让大模型去分析,但这其实跟真实场景差距太远了。真实场景面对的数据集不是一个5-30M的Excel或CSV文件,而是一个包含几万张表、几十亿条记录的数据湖,在做统计的时候,也会涉及到join这种复杂的表关联计算。真的让大模型面对这样的场景,可能直接挂机。但大模型迟早要面对这个问题,不然仍然是一个实验室的玩具。“
为解决这个问题,首先需要将大模型从GPT-4转向本地大模型,这时准确率可能急剧降低,“40%-50%都算高的。”为了克服底层逻辑的复杂性,滴普科技开发了一个分析引擎MQL(metric query language),其可以统一连接多样的数据库引擎比如MySQL、Hive、ClickHouse等等,“MQL通过灵活的选维度,生成中间的MQL代码,从而高性能地完成加速查询并毫秒级返回。所以,我们的解题思路不是Text to SQL,而是Text to MQL,因为MQL已经把不同数仓的差异性进行了统一。在这个架构下,只要对模型做一定的微调,Text to SQL的准确率是可以达到100%的,而不仅仅是保证生产环境可行。”
这些方法论最终体现在滴普科技的大模型产品规划上。
为兼顾效率、性能和体验,滴普科技规划了完善的产品体系,“我们从多个维度规划了大模型产品体系。第一个维度是算力基础,大模型的预训练、微调的算力开销很大,但客户普遍算力资源不足,同时不知道如何在硬件上部署什么样的大模型,以及如何部署。为此,我们提供的Fast5000E训推一体机,从硬件到模型完全整合到一起提供给客户,客户只需要考虑场景适配和应用就可以了。虽然算力规模不大,远低于互联网大公司的算力,但对于大部分企业而言已经足够。”
然后,在算力基础之上,为了在应用层面提升效率,降低开发门槛,滴普科技开发了FastAGI智能体平台,“可以理解成是一个Agent或智能体开发平台,该平台用于快速构建大模型工具链。我们提供了易于使用的开发工具,可以快速构建智能体能力。目前我们已经有了可以做高级数据分析的Data Agent,有处理非结构化数据的Doc Agent,还有一些用于扩展企业内部应用的Plugin Agent等等。除了这两个核心产品,滴普科技也会基于具体的业务场景帮助客户定制解决方案,比如在Data Agent之上做数据分析的Copilot、供应链智能助手等。“
这些成果体现了滴普科技顺应大模型落地趋势的认知,也反映了滴普科技在延展数据治理内涵上的努力。
数据治理的新趋势,是治理手段的技术化、工具化、一体化,“一方面,对于规模相对较小的客户,传统的自顶向下的数据治理方法,周期长、见效慢。一般来说,都需要先规划,请咨询公司帮忙把相关标准、规范、流程、制度确立,然后再进行内部运营。这种做法在大公司里没问题,但并不适合小公司。另外,大模型的数据治理还涉及非结构化数据的处理,非结构化数据和知识之间有很大的gap,专业门槛也很高。”
因此,滴普科技提倡数据治理要从传统数据治理走向敏捷数据治理。在与Gartner联合发布的《企业级数据治理体系建设指南》白皮书中,滴普科技明确提出,要将数据开发与治理一体化,在开发环节将治理动作执行到位,从根源上保证数据质量,同时在大模型时代将数据治理内涵进一步延伸至非结构化数据,持续提高数据的治理质量、广度和效率。
▼05.领域大模型的成本经济学
滴普科技在大模型落地实践中,将数据治理方法论进一步拓展,对数据质量、特性的评估建立了准确率、多样性、统计型、预测型等维度,进而用于指导领域大模型的高效低成本训练,同时追求性能和用户体验的极致,规划了系统性的产品体系。这不仅是领域大模型的成本经济学,也将成为滴普科技未来持续推进大模型落地应用的重要原则。
- End -
访谈人:柏海峰滴普科技 Deepexi 产品线总裁
与谈人:刘晓坤 DataFun
编辑:刘晓坤 DataFun