一.Linux目录结构
Linux操作系统在定位文件或目录位置时,使用斜杠“ / ”进行分割(区别于Windows操作系统中的反斜杠“ \ ”)。整个树形目录结构中,使用独立的一个" / "表示根目录,根目录是Linux操作系统文件系统的起点,其所在的分区称为根分区。
在根目录下,Linux操作系统将默认建立一些特殊的子目录,分别具有不同的用途,下面介绍一下其中常见的子目录及其作用。
-
/boot : 此目录是系统内核存放的目录,同时也是系统启动时所需文件的存放目录,如vmlinuz和initrd.img。在安装Linux操作系统时,为boot目录创建一个分区,有利于对系统进行备份。
-
/bin : bin是binary的缩写,这一目录存放了所有用户都可执行的且经常使用的命令,如cp、ls等。
-
/dev : 此目录保存了接口设备文件,如/dev/hdal、/dev/cdrom等。
-
/etc :系统主要的配置文件几乎都放置到这个目录内,如:人员的账号密码文件、各种服务的起始文件等。
-
/home :存放所有普通系统用户的默认工作文件夹(称为:宿主目录、家目录),如用户账号“ teacher”对应的宿主目录位于“/home/teacher”。如果服务器需要提供大量的普通用户使用,建议将"/home"目录划分为独立的分区,以方便用户数据备份。
-
/root : 该目录是Linux操作系统管理员(称为:超级用户)root的宿主目录,默认情况下只有root用户的宿主目录在根目录下而不是在“ /home ”目录下。
-
/sbin : 存放Linux操作系统中最基本的管理命令,一般管理员用户才有权限执行。
-
/usr : 存放其他的用户应用程序,通常还被划分成很多子目录,用于存放不同类型的应用程序。
-
/var : 存放系统中经常需要变化的一些文件,如系统日志文件、用户邮箱目录等。在实际应用中,“/var”目录通常也被划分为独立的分区。
二.查看及检索文件命令
1.查看文件内容-cat
1.1 cat
格式: cat 要查看目录文件
只能看普通的文本文件 谁在前面先看谁
缺点:如果内容过多会显示不全
实例:

| 选项 | 效果 |
| -n | 显示行号包括空白行 |
| -A | 显示隐藏字符 |
| -b | 跳过空白行编号 |
| -s | 将所有的连续的多个空行替换为一个空行(压缩成一个空行) |




1.2 三个标准文件
标准输入:你输入的指令 键盘输入
标准输出:电脑反馈给你的信息
错误输出:电脑的一些报错信息
(默认在屏幕上显示)
1.3 重定向
重新定义标准输出方向

> 覆盖 >> 追加
1.4 >覆盖
hello 被覆盖成nihao

1.5 >>追加

1.6 paste 横向合并

cat 上下合并

小问题:
如何将两个文件合并
cat A B > C 上下合并
paste A B > C 左右合并
paste -d 指定分隔符

1.6 tac A 倒序看

1.7 rev 将同一行的内容逆向显示

1.8 管道符
命令1 | 命令2 | 命令3 | 命令4
| 管道符:将前面命令的结果当做后面命令的执行参数
管道符左边的命令 一定要有标准输出
管道符右边的命令 一定要可以接收标准输入
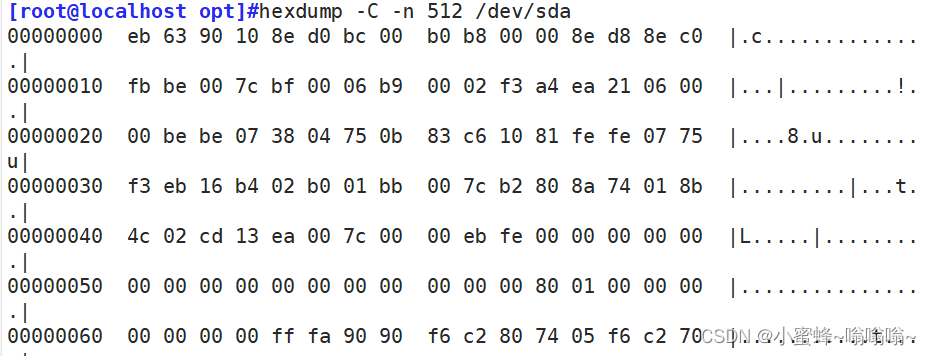
1.9 hexdump 查看非文本文件内容

2.分页查看内容-more less
使用cat命令可以非常简单的直接显示整个文件的内容,但是当文件的内容较多时,很有可能只能看到最后一部分信息,文件前面的大部分都来不及看到,而more和less命令通过采用全屏的方式分页显示文件,便于我们从头到尾仔细的阅读文件内容。
2.1 more
结束会直接退出
回车 一行
空格 一页
2.2 less
结束不会退出
/关键字 进行搜索,大小写敏感
n 向下查看
N 向上查看
q 退出
3.查看文件内容-head tail
3.1 head命令
用途:查看文件开头的一部分内容(默认为10行)
格式:head -n 数字 文件名 看文件的前数字行
实例:
看test 文件的前3行

head -c 取字符

依次取 中文一个字算三个字符
倒过来取字符

(用了正则表达式)
3.2 tail 命令
用途:查看文件结尾的少部分内容(默认为10行)
格式:tail -n 数字 文件名 看文件的后n行
实例:
看test 文件的后3行

tail -f 实时追踪查看文件
tail -f 文件名 tailf = tail -f
通常用于查看系统日志,(因为较新的日志记录总是添加到文件最后),以便于观察差网络访问,服务调试等相关信息,配合选项“ -f ”使用,还可以跟踪文件尾部内容的动态更新,便于实施监控文件内容变化。按ctrl + c 结束运行
三.统计文件内容-wc
格式: wc 【选项】 目标文件
| 选项 | 说明 |
| -l | 只统计行 |
| -w | 只统计单词 |
| -c | 只统计字符 |
seq 产生整数序列

四.检索和过滤文件内容-grep
4.1 grep
格式:grep [选项] 表达式 文件
实例:
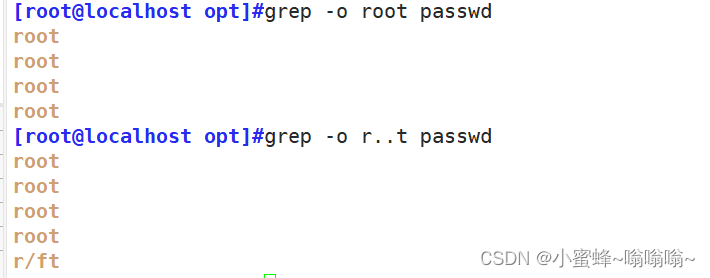
过滤/etc/passwd 文件中含有root关键字的行

| 选项 | 说明 |
| -i | 忽略大小写 |
| -v | 反向查找 |
| -o | 只显示匹配项 |
| -f | 对比两个文件的相同行 |
| -c | 只显示匹配的行数 |
-r 递归目录,但不处理软链接



4.2 正则表达式
. 任意字符
^ 一行的开头
$ 一行的结尾

实例:
grep “^root” passwd 只能匹配以root开头的
grep “root$” passwd 只能匹配以root结尾的
grep “^root$” passwd 这一行只有这四个字母,开头是他结尾是他
空行 grep “^$” passwd
非空行 grep -v “^$” passwd
小问题:
如何找出两个文件中相同的部分?
grep -f a文件 b文件
将a文件作为条件去匹配b文件,得出a文件和b文件相同的部分
在某一文件夹中,快速找到所有含有root字符的文件?
(如何快速过滤数据,找到含有特定字符的文件?)
grep -r 表达式 文件夹 (-r 递归目录,但不处理软链接)

4.3 split 分割文件
| 选项 | 说明 |
| -b | 按多少字节进行拆分 |
| -d | 使用数字作为后缀 |
| -a | 指定后缀长度(默认2) |
| -l | 值为每一输出档的行数大小 |
| -C | 每一输出档中,单行的最大字节数 |


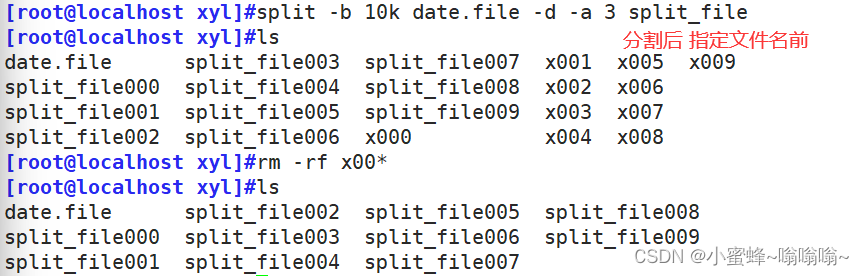
小问题:
有一个10G的文件,怎么分割成小的文件存储
split -b 100M 文件名
五.压缩和解压缩文件命令-
5.1 gzip命令
制作的压缩文件默认的扩展名为“ .gz ”,制作压缩文件时,使用“ -9 ”选项可以提高压缩的比率,但文件较大时会需要更多的时间。生成压缩文件后,原始文件将不再保留。
-d 解压缩
格式:
gzip 【-9】 文件名 :制作压缩文件
gzip -d .gz格式的压缩文件 :解开压缩文件
gunzip .gz格式的压缩文件 :解开压缩文件
选项“ -9 ”解释:
这里的选项可以为:1-9,它们的压缩比例不一样,从低往上压缩压缩比例越来越小。

5,2 bzip2
bzip2和bunzip2命令的用法与gzip、gunzip命令基本相同,使用bzip2制作的压缩文件默认的扩展名为“.bz2”,保留原文件。
格式:
bzip2 -9 文件名 :压缩文件
bzip2 -d .bz格式的压缩文件 :解压文件
bunzip2 .bz2格式的压缩文件 :解压文件

5.3 tar 命令
| 选项 | 说明 |
| -f | 代表使用tar归档 tar -f 只要出现tar一定要出现f |
| -c | 建立归档 |
| -x | 解开归档 |
| -j | 代表使用 bzip2压缩 |
| -z | 代表使用gzip压缩 |
| -C | 指定解压的目录 |
| -t | 不解开压缩包 查看压缩包中的内容 |
| -v | 显示压缩解压缩过程 |
| -p | 保留权限 |
| -P | 保留路径 |
选项顺序问题:
有 - f在最后一位
没有 - 都可以
5.3.1 制作归档备份压缩文件
格式:tar 【选项】 压缩后的名字 被压缩的文件名
(tar fzcv 压缩包的名字(*.tar.gz) 需要压缩的文件)
一定要加 f

5.3.2 从归档中恢复数据
格式: tar [选项] 要解压的文件名 [-C 目标目录]