文章目录
- 前言
- 0、论文摘要
- 一、Introduction
- 二.相关工作
- 三.本文方法
- 四 实验效果
- 4.1数据集
- 4.2 对比模型
- 4.3实施细节
- 4.4评估指标
- 4.5 实验结果
- 标准抽象模型
- 微调抽象模型
- 微调抽象模型和 BRIO
- 微调抽象模型和 BRIO-Loop
- 五 总结
- 结论
- 局限
前言

Abstractive Text Summarization Using the BRIO Training Paradigm(2305)
code
paper
0、论文摘要
抽象摘要模型产生的摘要句子可能是连贯且全面的,但它们缺乏控制并且严重依赖参考摘要。 BRIO 训练范式假设非确定性分布,以减少模型对参考摘要的依赖,并提高推理过程中的模型性能。
本文提出了一种简单但有效的技术,通过微调预训练的语言模型并使用 BRIO 范式对其进行训练来改进抽象摘要。
我们构建了一个越南语文本摘要数据集,称为 VieSum。我们使用在 CNNDM 和 VieSum 数据集上使用 BRIO 范式训练的抽象摘要模型进行实验。
结果表明,在基本硬件上训练的模型优于所有现有的抽象摘要模型,尤其是越南语模型。
一、Introduction
文本摘要减少了原始文本的大小,同时保留了其主要内容。构建摘要的两种主要方法是提取和抽象。提取式摘要直接提取表达原始文档关键主题的句子或单词,并将它们连接起来。抽象摘要发现文档的主要内容并生成摘要。抽象摘要通常比提取摘要更自然、更连贯。大多数抽象摘要模型都遵循编码器-解码器框架。现有的抽象摘要模型是使用最大似然估计进行训练的,并依赖于参考摘要。刘等人。 (2022a) 提出了一种 BRIO 训练范例,通过假设系统生成的候选摘要的非确定性分布来解决对参考摘要的依赖。在本文中,我们使用 BRIO 训练范式用于为英语和越南语文档构建摘要的抽象摘要模型。
总之,我们的贡献如下:
• 我们使用基于BART 和基于T5 的模型作为骨干,采用BRIO 训练范式进行抽象概括。
• 我们提出了BRIO 范式的问题。
• 我们使用BARTpho-BRIO 和ViT5BRIO 研究抽象摘要模型以获得改进的结果。
• 我们公开发布VieSum 总结数据集用于研究目的。
二.相关工作
盛等人。 (2022) 的 Siamese Semantic Preserving Generative Adversarial Net (SSPGAN) 使用基于 Transformer 的生成器来生成摘要。基于 Siamese Transformer 的鉴别器捕获源文档和相应摘要之间的语义一致性。在对抗训练期间,鉴别器计算生成的每个单词的奖励。在 Gigaword 数据集上,SSPGAN 模型比许多现有的抽象文本摘要模型取得了更好的结果,例如深度循环生成解码器(Li et al., 2017)、强化学习的 actor-critic 方法(Li et al., 2018)和 Transformer (瓦斯瓦尼等人,2017)。
刘等人。 (2022b) 通过在编码器和解码器中结合局部性偏差,开发用于抽象摘要的 PageSum 模型。每个文档都被划分为不重叠的页面。 arXiv:2305.13696v1 [cs.CL] 202 年 5 月 23 日 编码器是一个抽象摘要器,对每个页面进行编码并进行本地预测。解码器基于局部预测的加权组合来预测输出。作者对 BART 模型(Lewis et al., 2020)进行了微调以进行抽象概括,并研究了几种局部性方法,例如空间局部性、话语局部性和文档局部性。 PageSum 优于抽象摘要模型,例如 longformer 编码器-解码器 (Beltagy et al., 2020)、具有头向位置跨步的编码器-解码器注意力 (Huang et al., 2021) 以及具有分层注意力变换器的 BART (Rohde et al., 2021) )。然而,PageSum 需要较长的训练时间,需要较大的内存大小,并且无法捕获长距离依赖关系。
一些研究使用预先训练的模型进行抽象文本摘要。法拉哈尼等人。 (2021) 使用 mT5 (Xue et al., 2021) 和序列到序列 ParsBERT (Rothe et al., 2020) 构建波斯语文本的抽象摘要。 T5 (Raffel et al., 2020) 和 BERT (Devlin et al., 2018) 也被用来构建抽象摘要 (Garg et al., 2021)。 Kievongngam 等人。 (2020) 使用 BERT 和 GPT-2 总结了 COVID-19 生物医学研究文章 (Radford et al., 2019)。提取文档特征并将其集成到抽象模型中以改进摘要生成。南比亚尔等人。 (2022)开发了一种使用注意力机制的编码器-解码器模型,其中将 POS 特征合并到词嵌入层中以增强词向量。在马拉雅拉姆语数据集上的实验表明,注意力模型和 POS 特征的集成优于 seq2seq 和注意力模型。 Barna 和 Heickal(2021)通过结合预训练的词嵌入层来调整指针生成器网络以进行抽象摘要,以传输语义相似性和主题特征,以实现更好的主题覆盖。通常抽象概括的一个缺点是省略了命名实体。为了改善这一情况,Berezin 和 Batura (2022) 训练了一个基于 ROBERTa 的命名实体识别模型来发现命名实体。然后,训练 BART 屏蔽命名实体语言模型以关注名称实体。最后,BART 针对文本摘要进行了微调。
大多数用越南语构建抽象摘要的研究都使用编码器-解码器框架或预训练模型。库克等人。 (2019) 整合句子位置和术语频率进入具有覆盖机制的指针生成器网络,以对越南文档进行抽象摘要。林等人。 (2022) 使用带有注意力的 RNN、带有副本生成器的 BiLSTM、标准 Transformer、BERT 以及使用自下而上方法的序列到序列抽象模型为在线报纸构建抽象摘要。潘等人。 (2022) 使用基于 Transformer 的编码器-解码器架构(例如 Transformer、PhoBERT(Tran 等人,2022)和 ViT5(Phan 等人,2022))进行实验来总结越南语文档。
三.本文方法
四 实验效果
4.1数据集
4.2 对比模型
4.3实施细节
我们在 Google Colaboratory 环境 NVIDIA Tesla T4 16GB 中进行实验。我们使用英语版的 CNNDM3 数据集,以及越南语版的 VieSum 数据集。由于硬件的限制,我们从VieSum中随机挑选了70,000份文档及其相应的参考摘要进行实验。每个数据集分为 3 部分,其中 75% 用于训练,8% 用于验证,17% 用于测试。在本文中,预训练的基于 BART512 长度和基于 T5512 长度的模型被用作生成抽象摘要的骨干。 BART (Lewis et al., 2020) 和 T5 (Raffel et al., 2020) 模型在 CNNDM 数据集上进行训练,而 BARTpho (Tran et al., 2022) 和 ViT5 (Phan et al., 2022) 模型则在 CNNDM 数据集上进行训练。在 VieSum 数据集上进行训练。所有型号均为基础型号。为了便于比较,我们使用原作者建议的相同参数。
4.4评估指标
4.5 实验结果
标准抽象模型
首先,我们使用标准 BART 基础和 T5 基础模型来实验和评估抽象概括方法。我们使用批量大小为 4、历元数为 5、学习率为 10−5、预热步骤为 20,000 和 Adam 优化器来训练模型。使用标准主干模型的抽象摘要系统的结果如表 1 所示。
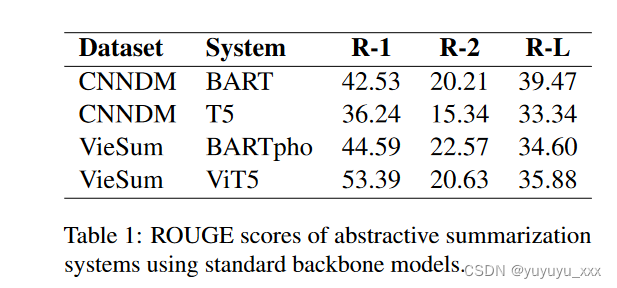
微调抽象模型
为了提高创建的摘要的质量,我们使用 Hugging Face4 提供的 Trainer 微调主干模型。我们不对 BART 模型进行微调,因为它已经在 CNN 数据集上进行了微调。表 2 显示了微调抽象模型的 ROUGE 分数。

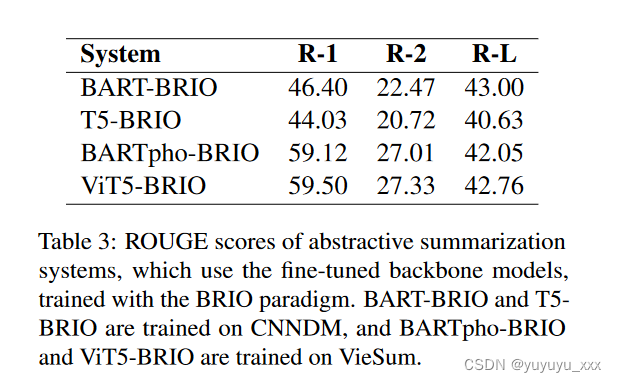
微调抽象模型和 BRIO
BRIO(Liu et al., 2022a)训练范式有助于抽象概括模型更准确地预测标记。刘等人。 (2022a) 使用 BART 作为骨干模型。 BRIO 使用对比学习根据输出摘要候选者的质量分配概率质量。抽象模型充当生成模型,以自回归方式生成抽象候选,以及评估模型,通过计算候选的概率分布来评估候选。生成器使用标准 MLE 损失进行训练,而评估器则使用对比损失进行训练(Hadsell 等人,2006)。
在 BRIO 中,主干模型用于为每个文档生成 N 个抽象摘要,即所谓的 candsum。通过获取其 ROUGE-1、ROUGE-2 和 ROUGE-L 值的平均分数,为每个 candsum 分配一个质量分数。特别是,刘等人。 (2022a) 使用 BART1024 长度模型为每个文档创建 16 个 Candsum。接下来,使用按质量分数降序排序的文档、参考摘要和相应的 Candsum 来训练使用 BRIO 范式的抽象摘要模型。我们注意到刘等人。 (2022a) 使用标准模型作为骨干,并使用 BRIO 范式对其进行训练。
在我们的工作中,上一节中介绍的微调主干抽象摘要模型用于使用不同的波束搜索(Vijayakumar 等人,2018)为每个文档生成 N=6 的candsum,其中 num beam groups=6,多样性罚分=1.0,光束数=4。抽象概括模型使用 10−3 的学习率和 Adafactor 优化器进行训练。刘等人。 (2022a) 声称 BRIO 训练有助于模型在 CNNDM 数据集上的一个时期内达到最佳性能。因此,我们使用一个 epoch 来训练带有 BRIO 范式的微调摘要模型。用 BRIO 训练的抽象摘要系统的结果如表 3 所示。
微调抽象模型和 BRIO-Loop
正如刘等人的建议。 (2022a),我们执行循环处理,使用由 BRIO 训练的抽象概括模型创建的 candsum 来训练模型。然而,经过几次循环迭代后,ROUGE 分数似乎变化很小。特别是,BARTpho 和 ViT5 几乎通过 2 次迭代就达到了最高的 ROUGE 分数。表 4 列出了循环两次后获得的 ROUGE 分数。
实验结果表明,BRIO 训练范式通过减少系统对参考摘要的依赖,显着帮助改进抽象摘要。然而,为了减少对参考摘要的依赖,有必要为candsum和参考摘要分配权重。不同的波束搜索有助于获得不同的坎德和,但可能会在波束搜索空间中造成干扰,因为模型可能不遵循参考摘要。此外,使用 ROUGE 度量来评估用 BRIO 范式训练的抽象摘要模型似乎不公平,因为这些模型可能生成独立于参考摘要的摘要。

五 总结
在不同硬件和不同数据集上训练的模型之间进行比较并不容易。我们尝试将我们的工作与类似数据集上已发表的论文进行比较。目前,BRIO 使用标准 BART1024 长度模型作为主干,生成 16 个 Candsum,在 CNNDM 数据集上取得了 SOTA 结果,ROUGE-1 为 47.78,ROUGE-L 为 32.58(Liu et al., 2022a)。
此外,经过2次迭代,BART1024-lengthBRIO的ROUGE-1和ROUGE-L分别达到48.01和44.67;这些都比我们的 BART512-length-BRIO 更好,BART512-length-BRIO 在 2 次迭代后为每个文档创建 6 个 Candsum:ROUGE-1 为 46.55,ROUGE-L 为 43.00。陶莫等人。 (2022) 微调 T5 抽象概括模型并在 CNNDM 数据集上进行评估。他们的 T5 模型的 ROUGE-1 和 ROUGE-L 分数分别为 40.79 和 34.80,低于我们微调的 T5 模型的分数,并且显着低于我们最好的模型 T5-BRIO-Loop 模型的分数:ROUGE-1 为 45.24,ROUGE-L 为 41.80。
对于越南语抽象概括,Quoc 等人。 (2019) 在从 Baomoi6 收集的越南数据集上使用具有句子位置和术语频率特征的 LSTM (LSTM+SP+TF)。他们的模型的最佳 ROUGE-1 和 ROUGE-L 分数分别为 31.89 和 29.97,明显低于我们的 BRIO-BART 模型的分数。使用 BRIO 范式训练的 BARTpho 和 ViT5 模型均优于 Lam 等人提出的所有模型。 (2022) 在 CTUNLPSum 数据集上,该数据集与 VieSum 数据集非常相似,包括序列到序列模型、复制生成器网络、重写器方法的序列到序列和自下而上的方法。特兰等人。 (2022) 在 VNDS (Nguyen et al., 2019) 数据集上应用多种模型进行抽象总结。他们在 8 个 A100 GPU(每个 40GB)上进行实验。他们的模型在大约 6 天内训练了 15 个时期。他们的最佳模型 BARTpho 的 ROUGE-1 为 61.14,略高于 BARTpho-BRIOLoop,ROUGE-L 为 40.15,低于 BARTpho-BRIO-Loop。
此外,BARTpho-BRIO-Loop 使用基本硬件在大约 32 小时内完成一个 epoch 的训练。潘等人。 (2022) 引入了一种用于越南语抽象摘要的预训练文本到文本转换器,称为 ViT5。作者声称 ViT5 模型是越南语抽象概括的 SOTA。他们的 ViT5 抽象摘要模型在 VNDS 数据集上分别实现了 61.85 和 41.70 的 ROUGE-1 和 ROUGE-L(Nguyen 等人,2019)。我们在 VNDS 上进行了实验,发现了与 ViT5 模型相关的有趣结果。使用通用范例训练的 ViT5 模型的 ROUGE 分数与 Phan 等人提供的 ROUGE 分数基本相同。 (2022)。然而,使用 BRIO 范式训练的 ViT5 模型的分数分别降至 59.37 和 41.6。在 VieSum 数据集上,标准 ViT5base 的 ROUGE-1 为 53.39,ROUGEL 为 35.88;而 ViT5-BRIO-Loop 的得分更高:ROUGE-1 为 60.90,ROUGE-L 为44.36。我们将这些不稳定的结果留给未来的工作进一步探索和评估。
结论
我们研究了用 BRIO 范式训练的抽象摘要模型。实验表明,我们可以在使用 BRIO 训练主干之前通过微调主干来改进抽象摘要模型。特别是,用 BRIO 训练的摘要模型优于越南语中的其他摘要模型。我们还讨论了 BRIO 范式的问题以进行进一步的探索。此外,我们还构建了 VieSum 数据集用于越南语摘要。对于未来的工作,我们将要求志愿者对 VieSum 数据集的一小部分进行评估并提供反馈。
局限
虽然许多研究表明深度学习模型的架构对结果有显着影响,但由于硬件限制,我们使用几种基本架构进行了实验。此外,越南还没有规模大且质量高的基准汇总数据集。现有的摘要数据集来自在线杂志,其中通常包含拼写错误和语法错误。此外,参考文献摘要可能无法传达相应文章的主要内容。因此,为越南语选择和开发有效的摘要模型仍然面临着许多挑战。