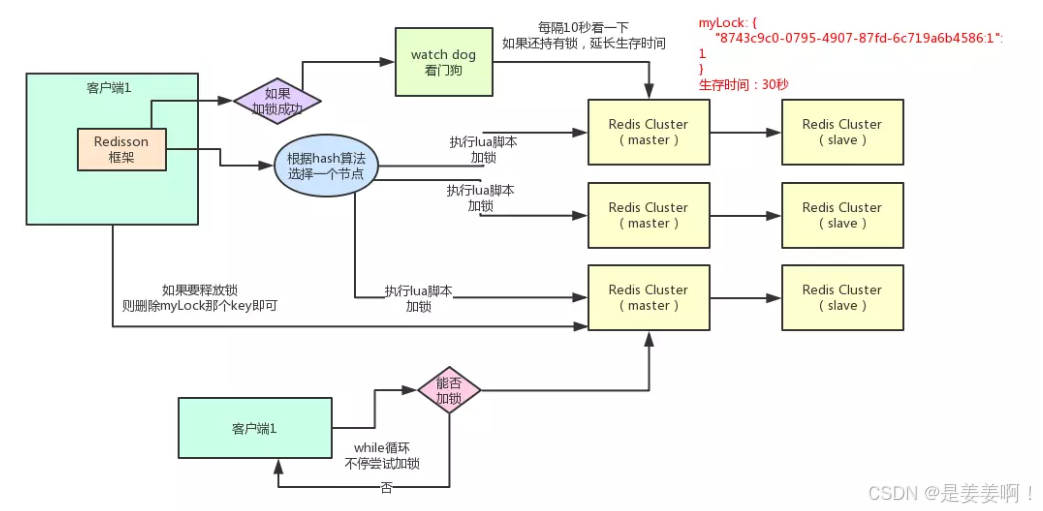
阶段性
阶段一:
单机时代
阶段二:
大数据时代-分布式处理
阶段三:
实时大数据时代
hadoop慢因为她的计算结果保存在磁盘 处理在spark中可解决属于内存
Hadoop特点:
高可靠性
高拓展性
高效性
高容错性
阶段一:
单机时代
阶段二:
大数据时代-分布式处理
阶段三:
实时大数据时代
hadoop慢因为她的计算结果保存在磁盘 处理在spark中可解决属于内存
高可靠性
高拓展性
高效性
高容错性
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/22309.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!