- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 一、我的环境
- 二、代码实现与执行结果
- 1.引入库
- 2.设置GPU(如果使用的是CPU可以忽略这步)
- 3.导入数据
- 4.查看数据
- 5.加载数据
- 6.再次检查数据
- 7.配置数据集
- 8.可视化数据
- 9.构建ResNet50模型
- 10.编译模型
- 11.训练模型
- 12.模型评估
- 三、知识点详解
- 1. CNN算法发展
- 2. 残差网络介绍
- 3 残差网络解决了什么
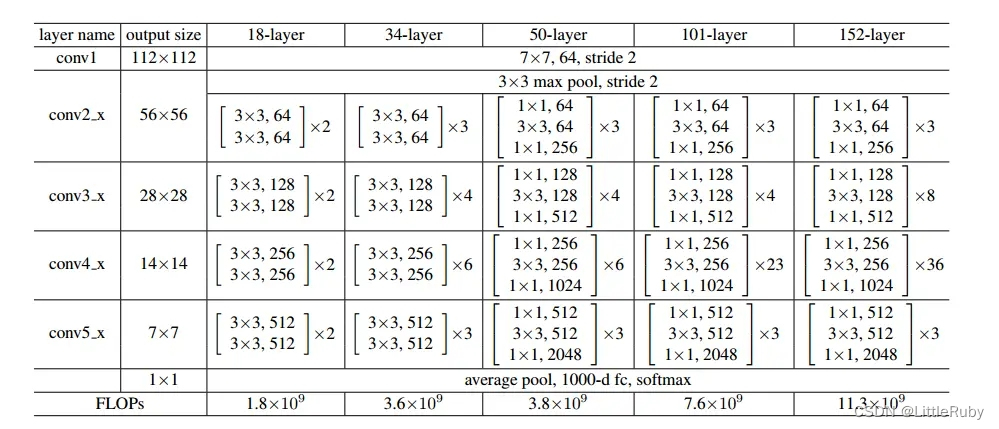
- 4 ResNet的各种网络结构图
- 5 resnet18&resnet50网络图
- 6 SoftMax以及它的实现原理
- 7 pytorch实现Resnet50算法
- 总结
前言
关键字:CNN算法发展,残差网络介绍,Resnet50, softmax及它的实现原理, pytorch实现Resnet50算法
一、我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:TensorFlow 2.10.1
- 显卡:NVIDIA GeForce RTX 4070
二、代码实现与执行结果
1.引入库
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import tensorflow as tf
from keras import layers, models, Input
from keras.layers import Input, Activation, BatchNormalization, Flatten
from keras.layers import Dense, Conv2D, MaxPooling2D, ZeroPadding2D, AveragePooling2D, Flatten, Dropout, BatchNormalization
from keras.models import Model
import matplotlib.pyplot as plt
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.设置GPU(如果使用的是CPU可以忽略这步)
'''前期工作-设置GPU(如果使用的是CPU可以忽略这步)'''
# 检查GPU是否可用
print(tf.test.is_built_with_cuda())
gpus = tf.config.list_physical_devices("GPU")
print(gpus)
if gpus:gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPUtf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存用量按需使用tf.config.set_visible_devices([gpu0], "GPU")
执行结果
True
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
3.导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)
4.查看数据
'''前期工作-查看数据'''
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
image_list = list(data_dir.glob('Bananaquit/*.jpg'))
image = Image.open(str(image_list[1]))
# 查看图像实例的属性
print(image.format, image.size, image.mode)
plt.imshow(image)
plt.axis("off")
plt.show()
执行结果:
图片总数为: 565
JPEG (224, 224) RGB

5.加载数据
'''数据预处理-加载数据'''
batch_size = 8
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
class_names = train_ds.class_names
print(class_names)
运行结果:
Found 565 files belonging to 4 classes.
Using 452 files for training.
Found 565 files belonging to 4 classes.
Using 113 files for validation.
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']6.再次检查数据
'''数据预处理-再次检查数据'''
# Image_batch是形状的张量(16, 336, 336, 3)。这是一批形状336x336x3的16张图片(最后一维指的是彩色通道RGB)。
# Label_batch是形状(16,)的张量,这些标签对应16张图片
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
运行结果
(8, 224, 224, 3)
(8,)
7.配置数据集
'''数据预处理-配置数据集'''
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)8.可视化数据
'''数据预处理-可视化数据'''
plt.figure(figsize=(10, 5))
for images, labels in train_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]], fontsize=10)plt.axis("off")
# 显示图片
plt.show()
9.构建ResNet50模型
"""构建ResNet50模型"""
def identity_block(input_tensor, kernel_size, filters, stage, block):filters1, filters2, filters3 = filtersname_base = str(stage) + block + '_identity_block_'x = Conv2D(filters1, (1, 1), name=name_base + 'conv1')(input_tensor)x = BatchNormalization(name=name_base + 'bn1')(x)x = Activation('relu', name=name_base + 'relu1')(x)x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)x = BatchNormalization(name=name_base + 'bn2')(x)x = Activation('relu', name=name_base + 'relu2')(x)x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)x = BatchNormalization(name=name_base + 'bn3')(x)x = layers.add([x, input_tensor], name=name_base + 'add')x = Activation('relu', name=name_base + 'relu4')(x)return xdef conv_block(input_tensor, kernel_size, filters, stage, block, strides=(2, 2)):filters1, filters2, filters3 = filtersres_name_base = str(stage) + block + '_conv_block_res_'name_base = str(stage) + block + '_conv_block_'x = Conv2D(filters1, (1, 1), strides=strides, name=name_base + 'conv1')(input_tensor)x = BatchNormalization(name=name_base + 'bn1')(x)x = Activation('relu', name=name_base + 'relu1')(x)x = Conv2D(filters2, kernel_size, padding='same', name=name_base + 'conv2')(x)x = BatchNormalization(name=name_base + 'bn2')(x)x = Activation('relu', name=name_base + 'relu2')(x)x = Conv2D(filters3, (1, 1), name=name_base + 'conv3')(x)x = BatchNormalization(name=name_base + 'bn3')(x)shortcut = Conv2D(filters3, (1, 1), strides=strides, name=res_name_base + 'conv')(input_tensor)shortcut = BatchNormalization(name=res_name_base + 'bn')(shortcut)x = layers.add([x, shortcut], name=name_base + 'add')x = Activation('relu', name=name_base + 'relu4')(x)return xdef ResNet50(input_shape=[224, 224, 3], classes=1000):img_input = Input(shape=input_shape)x = ZeroPadding2D((3, 3))(img_input)x = Conv2D(64, (7, 7), strides=(2, 2), name='conv1')(x)x = BatchNormalization(name='bn_conv1')(x)x = Activation('relu')(x)x = MaxPooling2D((3, 3), strides=(2, 2))(x)x = conv_block(x, 3, [64, 64, 256], stage=2, block='a', strides=(1, 1))x = identity_block(x, 3, [64, 64, 256], stage=2, block='b')x = identity_block(x, 3, [64, 64, 256], stage=2, block='c')x = conv_block(x, 3, [128, 128, 512], stage=3, block='a')x = identity_block(x, 3, [128, 128, 512], stage=3, block='b')x = identity_block(x, 3, [128, 128, 512], stage=3, block='c')x = identity_block(x, 3, [128, 128, 512], stage=3, block='d')x = conv_block(x, 3, [256, 256, 1024], stage=4, block='a')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='b')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='c')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='d')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='e')x = identity_block(x, 3, [256, 256, 1024], stage=4, block='f')x = conv_block(x, 3, [512, 512, 2048], stage=5, block='a')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='b')x = identity_block(x, 3, [512, 512, 2048], stage=5, block='c')x = AveragePooling2D((7, 7), name='avg_pooling')(x)x = Flatten()(x)x = Dense(classes, activation='softmax', name='fc1000')(x)model = Model(img_input, x, name='resnet50')# 加载预训练模型model.load_weights("resnet50_weights_tf_dim_ordering_tf_kernels.h5")return modelmodel = ResNet50()
model.summary()网络结构结果如下:
Model: "resnet50"
__________________________________________________________________________________________________Layer (type) Output Shape Param # Connected to
==================================================================================================input_1 (InputLayer) [(None, 224, 224, 3 0 [] )] zero_padding2d (ZeroPadding2D) (None, 230, 230, 3) 0 ['input_1[0][0]'] conv1 (Conv2D) (None, 112, 112, 64 9472 ['zero_padding2d[0][0]'] ) bn_conv1 (BatchNormalization) (None, 112, 112, 64 256 ['conv1[0][0]'] ) activation (Activation) (None, 112, 112, 64 0 ['bn_conv1[0][0]'] ) max_pooling2d (MaxPooling2D) (None, 55, 55, 64) 0 ['activation[0][0]'] 2a_conv_block_conv1 (Conv2D) (None, 55, 55, 64) 4160 ['max_pooling2d[0][0]'] 2a_conv_block_bn1 (BatchNormal (None, 55, 55, 64) 256 ['2a_conv_block_conv1[0][0]'] ization) 2a_conv_block_relu1 (Activatio (None, 55, 55, 64) 0 ['2a_conv_block_bn1[0][0]'] n) 2a_conv_block_conv2 (Conv2D) (None, 55, 55, 64) 36928 ['2a_conv_block_relu1[0][0]'] 2a_conv_block_bn2 (BatchNormal (None, 55, 55, 64) 256 ['2a_conv_block_conv2[0][0]'] ization) 2a_conv_block_relu2 (Activatio (None, 55, 55, 64) 0 ['2a_conv_block_bn2[0][0]'] n) 2a_conv_block_conv3 (Conv2D) (None, 55, 55, 256) 16640 ['2a_conv_block_relu2[0][0]'] 2a_conv_block_res_conv (Conv2D (None, 55, 55, 256) 16640 ['max_pooling2d[0][0]'] ) 2a_conv_block_bn3 (BatchNormal (None, 55, 55, 256) 1024 ['2a_conv_block_conv3[0][0]'] ization) 2a_conv_block_res_bn (BatchNor (None, 55, 55, 256) 1024 ['2a_conv_block_res_conv[0][0]'] malization) 2a_conv_block_add (Add) (None, 55, 55, 256) 0 ['2a_conv_block_bn3[0][0]', '2a_conv_block_res_bn[0][0]'] 2a_conv_block_relu4 (Activatio (None, 55, 55, 256) 0 ['2a_conv_block_add[0][0]'] n) 2b_identity_block_conv1 (Conv2 (None, 55, 55, 64) 16448 ['2a_conv_block_relu4[0][0]'] D) 2b_identity_block_bn1 (BatchNo (None, 55, 55, 64) 256 ['2b_identity_block_conv1[0][0]']rmalization) 2b_identity_block_relu1 (Activ (None, 55, 55, 64) 0 ['2b_identity_block_bn1[0][0]'] ation) 2b_identity_block_conv2 (Conv2 (None, 55, 55, 64) 36928 ['2b_identity_block_relu1[0][0]']D) 2b_identity_block_bn2 (BatchNo (None, 55, 55, 64) 256 ['2b_identity_block_conv2[0][0]']rmalization) 2b_identity_block_relu2 (Activ (None, 55, 55, 64) 0 ['2b_identity_block_bn2[0][0]'] ation) 2b_identity_block_conv3 (Conv2 (None, 55, 55, 256) 16640 ['2b_identity_block_relu2[0][0]']D) 2b_identity_block_bn3 (BatchNo (None, 55, 55, 256) 1024 ['2b_identity_block_conv3[0][0]']rmalization) 2b_identity_block_add (Add) (None, 55, 55, 256) 0 ['2b_identity_block_bn3[0][0]', '2a_conv_block_relu4[0][0]'] 2b_identity_block_relu4 (Activ (None, 55, 55, 256) 0 ['2b_identity_block_add[0][0]'] ation) 2c_identity_block_conv1 (Conv2 (None, 55, 55, 64) 16448 ['2b_identity_block_relu4[0][0]']D) 2c_identity_block_bn1 (BatchNo (None, 55, 55, 64) 256 ['2c_identity_block_conv1[0][0]']rmalization) 2c_identity_block_relu1 (Activ (None, 55, 55, 64) 0 ['2c_identity_block_bn1[0][0]'] ation) 2c_identity_block_conv2 (Conv2 (None, 55, 55, 64) 36928 ['2c_identity_block_relu1[0][0]']D) 2c_identity_block_bn2 (BatchNo (None, 55, 55, 64) 256 ['2c_identity_block_conv2[0][0]']rmalization) 2c_identity_block_relu2 (Activ (None, 55, 55, 64) 0 ['2c_identity_block_bn2[0][0]'] ation) 2c_identity_block_conv3 (Conv2 (None, 55, 55, 256) 16640 ['2c_identity_block_relu2[0][0]']D) 2c_identity_block_bn3 (BatchNo (None, 55, 55, 256) 1024 ['2c_identity_block_conv3[0][0]']rmalization) 2c_identity_block_add (Add) (None, 55, 55, 256) 0 ['2c_identity_block_bn3[0][0]', '2b_identity_block_relu4[0][0]']2c_identity_block_relu4 (Activ (None, 55, 55, 256) 0 ['2c_identity_block_add[0][0]'] ation) 3a_conv_block_conv1 (Conv2D) (None, 28, 28, 128) 32896 ['2c_identity_block_relu4[0][0]']3a_conv_block_bn1 (BatchNormal (None, 28, 28, 128) 512 ['3a_conv_block_conv1[0][0]'] ization) 3a_conv_block_relu1 (Activatio (None, 28, 28, 128) 0 ['3a_conv_block_bn1[0][0]'] n) 3a_conv_block_conv2 (Conv2D) (None, 28, 28, 128) 147584 ['3a_conv_block_relu1[0][0]'] 3a_conv_block_bn2 (BatchNormal (None, 28, 28, 128) 512 ['3a_conv_block_conv2[0][0]'] ization) 3a_conv_block_relu2 (Activatio (None, 28, 28, 128) 0 ['3a_conv_block_bn2[0][0]'] n) 3a_conv_block_conv3 (Conv2D) (None, 28, 28, 512) 66048 ['3a_conv_block_relu2[0][0]'] 3a_conv_block_res_conv (Conv2D (None, 28, 28, 512) 131584 ['2c_identity_block_relu4[0][0]']) 3a_conv_block_bn3 (BatchNormal (None, 28, 28, 512) 2048 ['3a_conv_block_conv3[0][0]'] ization) 3a_conv_block_res_bn (BatchNor (None, 28, 28, 512) 2048 ['3a_conv_block_res_conv[0][0]'] malization) 3a_conv_block_add (Add) (None, 28, 28, 512) 0 ['3a_conv_block_bn3[0][0]', '3a_conv_block_res_bn[0][0]'] 3a_conv_block_relu4 (Activatio (None, 28, 28, 512) 0 ['3a_conv_block_add[0][0]'] n) 3b_identity_block_conv1 (Conv2 (None, 28, 28, 128) 65664 ['3a_conv_block_relu4[0][0]'] D) 3b_identity_block_bn1 (BatchNo (None, 28, 28, 128) 512 ['3b_identity_block_conv1[0][0]']rmalization) 3b_identity_block_relu1 (Activ (None, 28, 28, 128) 0 ['3b_identity_block_bn1[0][0]'] ation) 3b_identity_block_conv2 (Conv2 (None, 28, 28, 128) 147584 ['3b_identity_block_relu1[0][0]']D) 3b_identity_block_bn2 (BatchNo (None, 28, 28, 128) 512 ['3b_identity_block_conv2[0][0]']rmalization) 3b_identity_block_relu2 (Activ (None, 28, 28, 128) 0 ['3b_identity_block_bn2[0][0]'] ation) 3b_identity_block_conv3 (Conv2 (None, 28, 28, 512) 66048 ['3b_identity_block_relu2[0][0]']D) 3b_identity_block_bn3 (BatchNo (None, 28, 28, 512) 2048 ['3b_identity_block_conv3[0][0]']rmalization) 3b_identity_block_add (Add) (None, 28, 28, 512) 0 ['3b_identity_block_bn3[0][0]', '3a_conv_block_relu4[0][0]'] 3b_identity_block_relu4 (Activ (None, 28, 28, 512) 0 ['3b_identity_block_add[0][0]'] ation) 3c_identity_block_conv1 (Conv2 (None, 28, 28, 128) 65664 ['3b_identity_block_relu4[0][0]']D) 3c_identity_block_bn1 (BatchNo (None, 28, 28, 128) 512 ['3c_identity_block_conv1[0][0]']rmalization) 3c_identity_block_relu1 (Activ (None, 28, 28, 128) 0 ['3c_identity_block_bn1[0][0]'] ation) 3c_identity_block_conv2 (Conv2 (None, 28, 28, 128) 147584 ['3c_identity_block_relu1[0][0]']D) 3c_identity_block_bn2 (BatchNo (None, 28, 28, 128) 512 ['3c_identity_block_conv2[0][0]']rmalization) 3c_identity_block_relu2 (Activ (None, 28, 28, 128) 0 ['3c_identity_block_bn2[0][0]'] ation) 3c_identity_block_conv3 (Conv2 (None, 28, 28, 512) 66048 ['3c_identity_block_relu2[0][0]']D) 3c_identity_block_bn3 (BatchNo (None, 28, 28, 512) 2048 ['3c_identity_block_conv3[0][0]']rmalization) 3c_identity_block_add (Add) (None, 28, 28, 512) 0 ['3c_identity_block_bn3[0][0]', '3b_identity_block_relu4[0][0]']3c_identity_block_relu4 (Activ (None, 28, 28, 512) 0 ['3c_identity_block_add[0][0]'] ation) 3d_identity_block_conv1 (Conv2 (None, 28, 28, 128) 65664 ['3c_identity_block_relu4[0][0]']D) 3d_identity_block_bn1 (BatchNo (None, 28, 28, 128) 512 ['3d_identity_block_conv1[0][0]']rmalization) 3d_identity_block_relu1 (Activ (None, 28, 28, 128) 0 ['3d_identity_block_bn1[0][0]'] ation) 3d_identity_block_conv2 (Conv2 (None, 28, 28, 128) 147584 ['3d_identity_block_relu1[0][0]']D) 3d_identity_block_bn2 (BatchNo (None, 28, 28, 128) 512 ['3d_identity_block_conv2[0][0]']rmalization) 3d_identity_block_relu2 (Activ (None, 28, 28, 128) 0 ['3d_identity_block_bn2[0][0]'] ation) 3d_identity_block_conv3 (Conv2 (None, 28, 28, 512) 66048 ['3d_identity_block_relu2[0][0]']D) 3d_identity_block_bn3 (BatchNo (None, 28, 28, 512) 2048 ['3d_identity_block_conv3[0][0]']rmalization) 3d_identity_block_add (Add) (None, 28, 28, 512) 0 ['3d_identity_block_bn3[0][0]', '3c_identity_block_relu4[0][0]']3d_identity_block_relu4 (Activ (None, 28, 28, 512) 0 ['3d_identity_block_add[0][0]'] ation) 4a_conv_block_conv1 (Conv2D) (None, 14, 14, 256) 131328 ['3d_identity_block_relu4[0][0]']4a_conv_block_bn1 (BatchNormal (None, 14, 14, 256) 1024 ['4a_conv_block_conv1[0][0]'] ization) 4a_conv_block_relu1 (Activatio (None, 14, 14, 256) 0 ['4a_conv_block_bn1[0][0]'] n) 4a_conv_block_conv2 (Conv2D) (None, 14, 14, 256) 590080 ['4a_conv_block_relu1[0][0]'] 4a_conv_block_bn2 (BatchNormal (None, 14, 14, 256) 1024 ['4a_conv_block_conv2[0][0]'] ization) 4a_conv_block_relu2 (Activatio (None, 14, 14, 256) 0 ['4a_conv_block_bn2[0][0]'] n) 4a_conv_block_conv3 (Conv2D) (None, 14, 14, 1024 263168 ['4a_conv_block_relu2[0][0]'] ) 4a_conv_block_res_conv (Conv2D (None, 14, 14, 1024 525312 ['3d_identity_block_relu4[0][0]']) ) 4a_conv_block_bn3 (BatchNormal (None, 14, 14, 1024 4096 ['4a_conv_block_conv3[0][0]'] ization) ) 4a_conv_block_res_bn (BatchNor (None, 14, 14, 1024 4096 ['4a_conv_block_res_conv[0][0]'] malization) ) 4a_conv_block_add (Add) (None, 14, 14, 1024 0 ['4a_conv_block_bn3[0][0]', ) '4a_conv_block_res_bn[0][0]'] 4a_conv_block_relu4 (Activatio (None, 14, 14, 1024 0 ['4a_conv_block_add[0][0]'] n) ) 4b_identity_block_conv1 (Conv2 (None, 14, 14, 256) 262400 ['4a_conv_block_relu4[0][0]'] D) 4b_identity_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4b_identity_block_conv1[0][0]']rmalization) 4b_identity_block_relu1 (Activ (None, 14, 14, 256) 0 ['4b_identity_block_bn1[0][0]'] ation) 4b_identity_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4b_identity_block_relu1[0][0]']D) 4b_identity_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4b_identity_block_conv2[0][0]']rmalization) 4b_identity_block_relu2 (Activ (None, 14, 14, 256) 0 ['4b_identity_block_bn2[0][0]'] ation) 4b_identity_block_conv3 (Conv2 (None, 14, 14, 1024 263168 ['4b_identity_block_relu2[0][0]']D) ) 4b_identity_block_bn3 (BatchNo (None, 14, 14, 1024 4096 ['4b_identity_block_conv3[0][0]']rmalization) ) 4b_identity_block_add (Add) (None, 14, 14, 1024 0 ['4b_identity_block_bn3[0][0]', ) '4a_conv_block_relu4[0][0]'] 4b_identity_block_relu4 (Activ (None, 14, 14, 1024 0 ['4b_identity_block_add[0][0]'] ation) ) 4c_identity_block_conv1 (Conv2 (None, 14, 14, 256) 262400 ['4b_identity_block_relu4[0][0]']D) 4c_identity_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4c_identity_block_conv1[0][0]']rmalization) 4c_identity_block_relu1 (Activ (None, 14, 14, 256) 0 ['4c_identity_block_bn1[0][0]'] ation) 4c_identity_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4c_identity_block_relu1[0][0]']D) 4c_identity_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4c_identity_block_conv2[0][0]']rmalization) 4c_identity_block_relu2 (Activ (None, 14, 14, 256) 0 ['4c_identity_block_bn2[0][0]'] ation) 4c_identity_block_conv3 (Conv2 (None, 14, 14, 1024 263168 ['4c_identity_block_relu2[0][0]']D) ) 4c_identity_block_bn3 (BatchNo (None, 14, 14, 1024 4096 ['4c_identity_block_conv3[0][0]']rmalization) ) 4c_identity_block_add (Add) (None, 14, 14, 1024 0 ['4c_identity_block_bn3[0][0]', ) '4b_identity_block_relu4[0][0]']4c_identity_block_relu4 (Activ (None, 14, 14, 1024 0 ['4c_identity_block_add[0][0]'] ation) ) 4d_identity_block_conv1 (Conv2 (None, 14, 14, 256) 262400 ['4c_identity_block_relu4[0][0]']D) 4d_identity_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4d_identity_block_conv1[0][0]']rmalization) 4d_identity_block_relu1 (Activ (None, 14, 14, 256) 0 ['4d_identity_block_bn1[0][0]'] ation) 4d_identity_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4d_identity_block_relu1[0][0]']D) 4d_identity_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4d_identity_block_conv2[0][0]']rmalization) 4d_identity_block_relu2 (Activ (None, 14, 14, 256) 0 ['4d_identity_block_bn2[0][0]'] ation) 4d_identity_block_conv3 (Conv2 (None, 14, 14, 1024 263168 ['4d_identity_block_relu2[0][0]']D) ) 4d_identity_block_bn3 (BatchNo (None, 14, 14, 1024 4096 ['4d_identity_block_conv3[0][0]']rmalization) ) 4d_identity_block_add (Add) (None, 14, 14, 1024 0 ['4d_identity_block_bn3[0][0]', ) '4c_identity_block_relu4[0][0]']4d_identity_block_relu4 (Activ (None, 14, 14, 1024 0 ['4d_identity_block_add[0][0]'] ation) ) 4e_identity_block_conv1 (Conv2 (None, 14, 14, 256) 262400 ['4d_identity_block_relu4[0][0]']D) 4e_identity_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4e_identity_block_conv1[0][0]']rmalization) 4e_identity_block_relu1 (Activ (None, 14, 14, 256) 0 ['4e_identity_block_bn1[0][0]'] ation) 4e_identity_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4e_identity_block_relu1[0][0]']D) 4e_identity_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4e_identity_block_conv2[0][0]']rmalization) 4e_identity_block_relu2 (Activ (None, 14, 14, 256) 0 ['4e_identity_block_bn2[0][0]'] ation) 4e_identity_block_conv3 (Conv2 (None, 14, 14, 1024 263168 ['4e_identity_block_relu2[0][0]']D) ) 4e_identity_block_bn3 (BatchNo (None, 14, 14, 1024 4096 ['4e_identity_block_conv3[0][0]']rmalization) ) 4e_identity_block_add (Add) (None, 14, 14, 1024 0 ['4e_identity_block_bn3[0][0]', ) '4d_identity_block_relu4[0][0]']4e_identity_block_relu4 (Activ (None, 14, 14, 1024 0 ['4e_identity_block_add[0][0]'] ation) ) 4f_identity_block_conv1 (Conv2 (None, 14, 14, 256) 262400 ['4e_identity_block_relu4[0][0]']D) 4f_identity_block_bn1 (BatchNo (None, 14, 14, 256) 1024 ['4f_identity_block_conv1[0][0]']rmalization) 4f_identity_block_relu1 (Activ (None, 14, 14, 256) 0 ['4f_identity_block_bn1[0][0]'] ation) 4f_identity_block_conv2 (Conv2 (None, 14, 14, 256) 590080 ['4f_identity_block_relu1[0][0]']D) 4f_identity_block_bn2 (BatchNo (None, 14, 14, 256) 1024 ['4f_identity_block_conv2[0][0]']rmalization) 4f_identity_block_relu2 (Activ (None, 14, 14, 256) 0 ['4f_identity_block_bn2[0][0]'] ation) 4f_identity_block_conv3 (Conv2 (None, 14, 14, 1024 263168 ['4f_identity_block_relu2[0][0]']D) ) 4f_identity_block_bn3 (BatchNo (None, 14, 14, 1024 4096 ['4f_identity_block_conv3[0][0]']rmalization) ) 4f_identity_block_add (Add) (None, 14, 14, 1024 0 ['4f_identity_block_bn3[0][0]', ) '4e_identity_block_relu4[0][0]']4f_identity_block_relu4 (Activ (None, 14, 14, 1024 0 ['4f_identity_block_add[0][0]'] ation) ) 5a_conv_block_conv1 (Conv2D) (None, 7, 7, 512) 524800 ['4f_identity_block_relu4[0][0]']5a_conv_block_bn1 (BatchNormal (None, 7, 7, 512) 2048 ['5a_conv_block_conv1[0][0]'] ization) 5a_conv_block_relu1 (Activatio (None, 7, 7, 512) 0 ['5a_conv_block_bn1[0][0]'] n) 5a_conv_block_conv2 (Conv2D) (None, 7, 7, 512) 2359808 ['5a_conv_block_relu1[0][0]'] 5a_conv_block_bn2 (BatchNormal (None, 7, 7, 512) 2048 ['5a_conv_block_conv2[0][0]'] ization) 5a_conv_block_relu2 (Activatio (None, 7, 7, 512) 0 ['5a_conv_block_bn2[0][0]'] n) 5a_conv_block_conv3 (Conv2D) (None, 7, 7, 2048) 1050624 ['5a_conv_block_relu2[0][0]'] 5a_conv_block_res_conv (Conv2D (None, 7, 7, 2048) 2099200 ['4f_identity_block_relu4[0][0]']) 5a_conv_block_bn3 (BatchNormal (None, 7, 7, 2048) 8192 ['5a_conv_block_conv3[0][0]'] ization) 5a_conv_block_res_bn (BatchNor (None, 7, 7, 2048) 8192 ['5a_conv_block_res_conv[0][0]'] malization) 5a_conv_block_add (Add) (None, 7, 7, 2048) 0 ['5a_conv_block_bn3[0][0]', '5a_conv_block_res_bn[0][0]'] 5a_conv_block_relu4 (Activatio (None, 7, 7, 2048) 0 ['5a_conv_block_add[0][0]'] n) 5b_identity_block_conv1 (Conv2 (None, 7, 7, 512) 1049088 ['5a_conv_block_relu4[0][0]'] D) 5b_identity_block_bn1 (BatchNo (None, 7, 7, 512) 2048 ['5b_identity_block_conv1[0][0]']rmalization) 5b_identity_block_relu1 (Activ (None, 7, 7, 512) 0 ['5b_identity_block_bn1[0][0]'] ation) 5b_identity_block_conv2 (Conv2 (None, 7, 7, 512) 2359808 ['5b_identity_block_relu1[0][0]']D) 5b_identity_block_bn2 (BatchNo (None, 7, 7, 512) 2048 ['5b_identity_block_conv2[0][0]']rmalization) 5b_identity_block_relu2 (Activ (None, 7, 7, 512) 0 ['5b_identity_block_bn2[0][0]'] ation) 5b_identity_block_conv3 (Conv2 (None, 7, 7, 2048) 1050624 ['5b_identity_block_relu2[0][0]']D) 5b_identity_block_bn3 (BatchNo (None, 7, 7, 2048) 8192 ['5b_identity_block_conv3[0][0]']rmalization) 5b_identity_block_add (Add) (None, 7, 7, 2048) 0 ['5b_identity_block_bn3[0][0]', '5a_conv_block_relu4[0][0]'] 5b_identity_block_relu4 (Activ (None, 7, 7, 2048) 0 ['5b_identity_block_add[0][0]'] ation) 5c_identity_block_conv1 (Conv2 (None, 7, 7, 512) 1049088 ['5b_identity_block_relu4[0][0]']D) 5c_identity_block_bn1 (BatchNo (None, 7, 7, 512) 2048 ['5c_identity_block_conv1[0][0]']rmalization) 5c_identity_block_relu1 (Activ (None, 7, 7, 512) 0 ['5c_identity_block_bn1[0][0]'] ation) 5c_identity_block_conv2 (Conv2 (None, 7, 7, 512) 2359808 ['5c_identity_block_relu1[0][0]']D) 5c_identity_block_bn2 (BatchNo (None, 7, 7, 512) 2048 ['5c_identity_block_conv2[0][0]']rmalization) 5c_identity_block_relu2 (Activ (None, 7, 7, 512) 0 ['5c_identity_block_bn2[0][0]'] ation) 5c_identity_block_conv3 (Conv2 (None, 7, 7, 2048) 1050624 ['5c_identity_block_relu2[0][0]']D) 5c_identity_block_bn3 (BatchNo (None, 7, 7, 2048) 8192 ['5c_identity_block_conv3[0][0]']rmalization) 5c_identity_block_add (Add) (None, 7, 7, 2048) 0 ['5c_identity_block_bn3[0][0]', '5b_identity_block_relu4[0][0]']5c_identity_block_relu4 (Activ (None, 7, 7, 2048) 0 ['5c_identity_block_add[0][0]'] ation) avg_pooling (AveragePooling2D) (None, 1, 1, 2048) 0 ['5c_identity_block_relu4[0][0]']flatten (Flatten) (None, 2048) 0 ['avg_pooling[0][0]'] fc1000 (Dense) (None, 1000) 2049000 ['flatten[0][0]'] ==================================================================================================
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
__________________________________________________________________________________________________
10.编译模型
#设置初始学习率
initial_learning_rate = 1e-3
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate)
model.compile(optimizer=opt,loss='sparse_categorical_crossentropy',metrics=['accuracy'])11.训练模型
'''训练模型'''
epochs = 10
history = model.fit(train_ds,validation_data=val_ds,epochs=epochs
)
训练记录如下:
Epoch 1/10
57/57 [==============================] - 8s 54ms/step - loss: 1.3797 - accuracy: 0.7212 - val_loss: 4021.5437 - val_accuracy: 0.2301
Epoch 2/10
57/57 [==============================] - 2s 40ms/step - loss: 0.4452 - accuracy: 0.8695 - val_loss: 22.2432 - val_accuracy: 0.3274
Epoch 3/10
57/57 [==============================] - 2s 40ms/step - loss: 0.3566 - accuracy: 0.8761 - val_loss: 21.0750 - val_accuracy: 0.2743
Epoch 4/10
57/57 [==============================] - 2s 40ms/step - loss: 0.1800 - accuracy: 0.9469 - val_loss: 4.8014 - val_accuracy: 0.3894
Epoch 5/10
57/57 [==============================] - 2s 40ms/step - loss: 0.0815 - accuracy: 0.9646 - val_loss: 0.2824 - val_accuracy: 0.9204
Epoch 6/10
57/57 [==============================] - 2s 40ms/step - loss: 0.0380 - accuracy: 0.9867 - val_loss: 1.8555 - val_accuracy: 0.8053
Epoch 7/10
57/57 [==============================] - 2s 40ms/step - loss: 0.0421 - accuracy: 0.9889 - val_loss: 1.5017 - val_accuracy: 0.7080
Epoch 8/10
57/57 [==============================] - 2s 41ms/step - loss: 0.0060 - accuracy: 0.9978 - val_loss: 0.7932 - val_accuracy: 0.8407
Epoch 9/10
57/57 [==============================] - 2s 41ms/step - loss: 0.0026 - accuracy: 1.0000 - val_loss: 0.1006 - val_accuracy: 0.9469
Epoch 10/10
57/57 [==============================] - 2s 41ms/step - loss: 6.7589e-04 - accuracy: 1.0000 - val_loss: 0.0842 - val_accuracy: 0.9735
......12.模型评估
'''模型评估'''
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()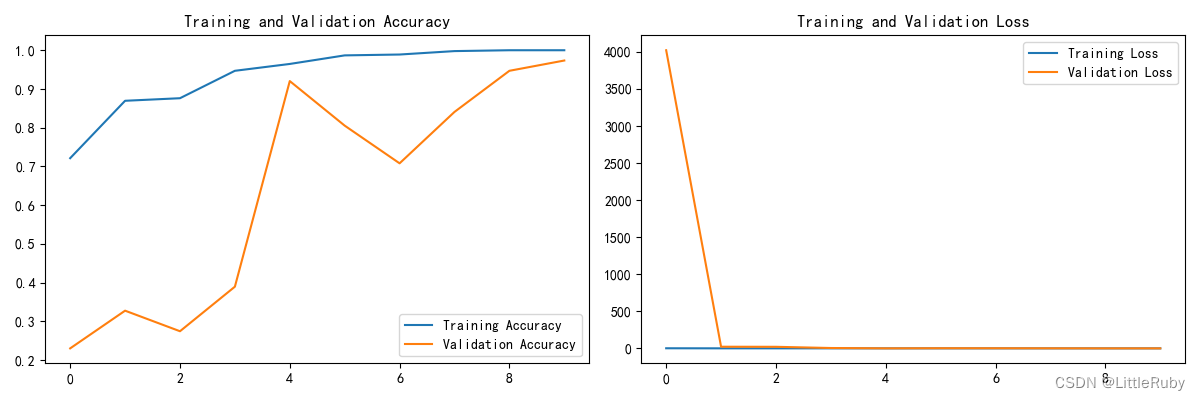
13.图像预测
'''指定图片进行预测'''
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示", fontsize=10)
for images, labels in val_ds.take(1):for i in range(8):ax = plt.subplot(2, 4, i + 1)# 显示图片plt.imshow(images[i].numpy().astype("uint8"))# 需要给图片增加一个维度img_array = tf.expand_dims(images[i], 0)# 使用模型预测图片中的人物predictions = model.predict(img_array)plt.title(class_names[np.argmax(predictions)],fontsize=10)plt.axis("off")
plt.show()

三、知识点详解
1. CNN算法发展
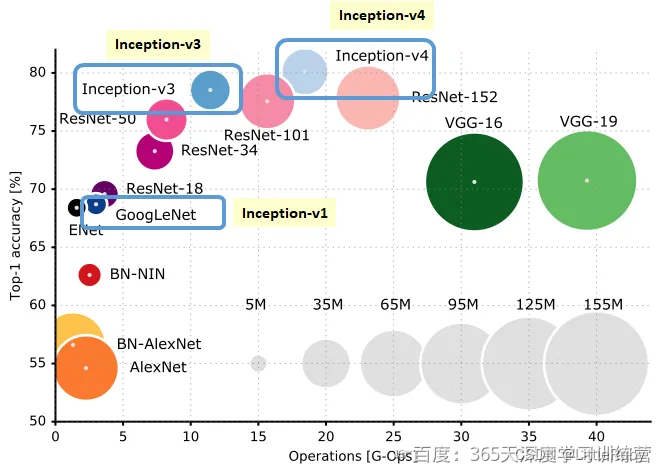
首先借用一下来自于网络的插图,在这张图上列出了一些有里程碑意义的、经典卷积神经网络。评估网络的性能,一个维度是识别精度,另一个维度则是网络的复杂度(计算量)。从这张图里,我们能看到:
(1)2012年,AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年ImageNet图像分类竞赛中提出的一种经典的卷积神经网络。AlexNet是首个深层卷积神经网络,同时也引入了ReLU激活函数、局部归一化、数据增强和Dropout 处理。
(2)VGG-16和VGG-19,这是依靠多层卷积+池化层堆叠而成的一个网络,其性能在当时也还不错,但是计算量巨大。VGG-16的网络结构在前面已经总结过,是将深层网络结构分为几个组,每组堆叠数量不等的Conv-ReLU层,并在最后一层使用MaxPool缩减特征图尺寸。 (3)GoogLeNet(也就是Inception V1),这是一个提出了使用并联卷积结构、且在每个通路中使用不同卷积核的网络,并且随后衍生出V2、V3、V4等一系列网络结构,构成一个家族。
(4)ResNet,有V1、V2、NeXt等不同的版本,这是一个提出恒等映射概念、具有短路直接路径、模块化的网络结构,可以很方便地扩展为18~1001层(ResNet-18、ResNet-34、ResNet-50、ResNet-101中的数字都是表示网络层数)。
(5)DenseNet,这是一种具有前级特征重用、层间直连、结构递归扩展等特点的卷积网络。
下图是另一篇文章总结的cnn发展史

2. 残差网络介绍
深度残差网络ResNet(deep residual network)在2015年由何凯明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成。
ResNet主要解决深度卷积网络在深度加深时候的”退化“问题。在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失或梯度爆炸,这个问题Szegedy提出的BN层后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过大或过小的情况。但是作者发现加了BN层后再加大深度仍然不容易收敛,其提到了第二个问题–准确率下降问题:层级大到一定程度时准确率就会饱和,然后迅速下降,这种下降既不是梯度消失引起的,也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的准确率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的优化器,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
作者在文中证明了只要有合适的网络结构,更深的网络肯定会比较浅的网络效果好。证明过程也很简单:假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。
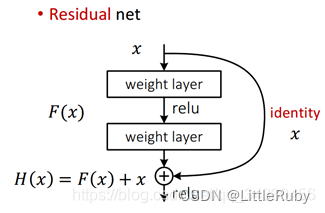
图1 残差模块
何凯明提出了一种残差结构来实现上述恒等映射(如上图所示):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出,用公式表达就是H(x)=F(x)+x,其中x是输入,F(x)是卷积分支的输出,H(x)是整个结构的输出。可以证明如果F(x)分支中所有参数都是0,H(x)=x,即H(x)与x为恒等映射。残差结构是人为的制造了恒等映射,能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数值就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则。
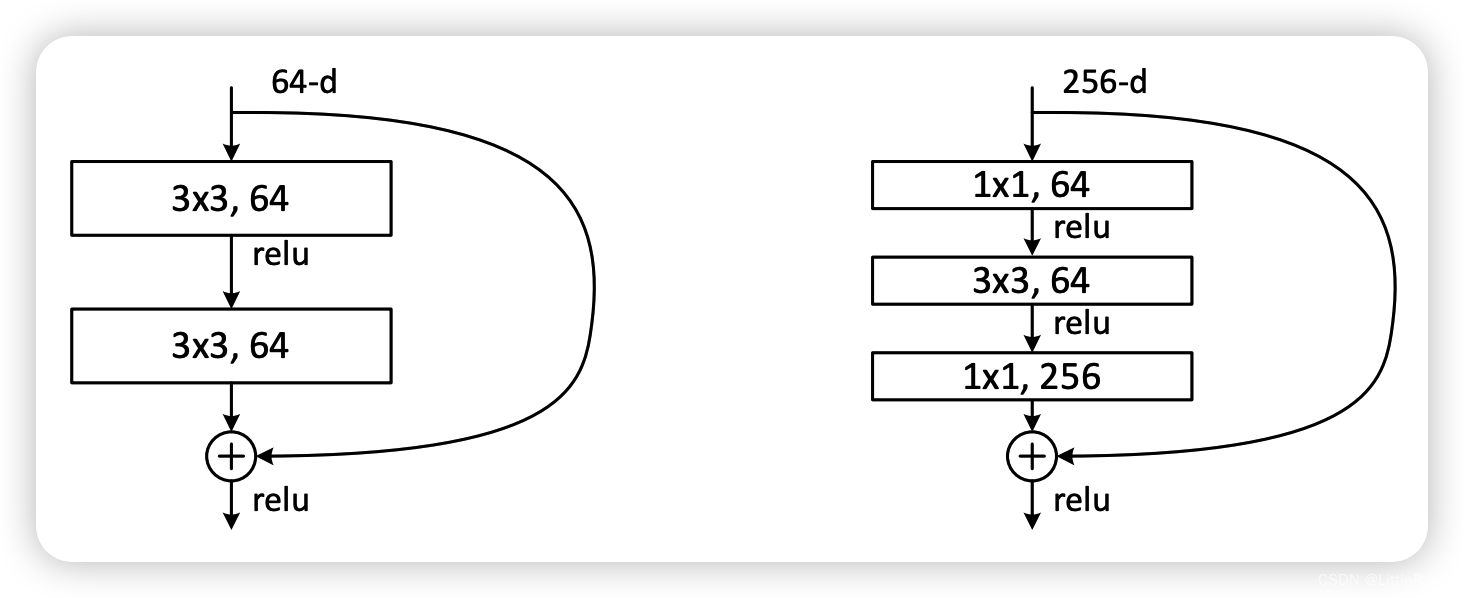
图2 两种残差模块
图2 左边的单元为ResNet两层的残差单元,两层的残差单元包含两个相同输出通道数的33卷积,只是用于较浅的ResNet网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为bottleneck结构,先用一个11卷积进行降维,最后用1*1升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层。三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型。通过残差单元的组合有经典的ResNet-50,ResNet-101等网络结构。
何恺明的这篇文章:Deep Residual Learning for Image Recognition.pdf
BP算法基于梯度下降策略,以目标的负梯度方向对参数进行调整,参数的更新为 w←w+Δw,给定 学习速率 α,得出 Δw = −α * ∂Loss / ∂w
根据 链式求导法则,更新梯度信息,∂fn / ∂fm 其实就是 对激活函数进行求导
当层数增加,∂fn / ∂fm < 1 → 梯度消失
当层数增加,∂fn / ∂fm > 1 → 梯度爆炸
在统计学中,残差的初始定义为:实际观测值 与 估计值 (拟合值) 的差值
在神经网络中,残差为恒等映射 H(X) 与 跨层连接 X 的差值
残差元结构图,两部分组成:恒等映射 H(X) + 跨层连接 X,使得前向传播过程为线性,而非连乘残差网络的基本思路:在原神经网络结构基础上,添加跨层跳转连接,形成残差元 (identity block),即 H(X) = F(X) + X,包含了大量浅层网络的可能性
数学原理:在反向传播的过程中,链式求导会从连乘变成连加,即:(∂fn / ∂fm) * (1 + (∂fm / ∂fo)),可以有效解决 梯度消失 & 梯度爆炸 问题
参考链接:【CV】04_残差网络【梯度消失 & 梯度爆炸】
3 残差网络解决了什么
残差网络是为了解决神经网络隐藏层过多时,而引起的网络退化问题。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。
拓展:深度神经网络的"两朵乌云"
梯度弥散/爆炸
简单来讲就是网络太深了,会导致模型训练难以收敛。这个问题可以被标准初始化和中间层正规化的方法有效控制。网络退化
随着网络深度增加,网络的表现先是逐渐增加至饱和,然后迅速下降,这个退化不是由过拟合引起的。
4 ResNet的各种网络结构图
5 resnet18&resnet50网络图
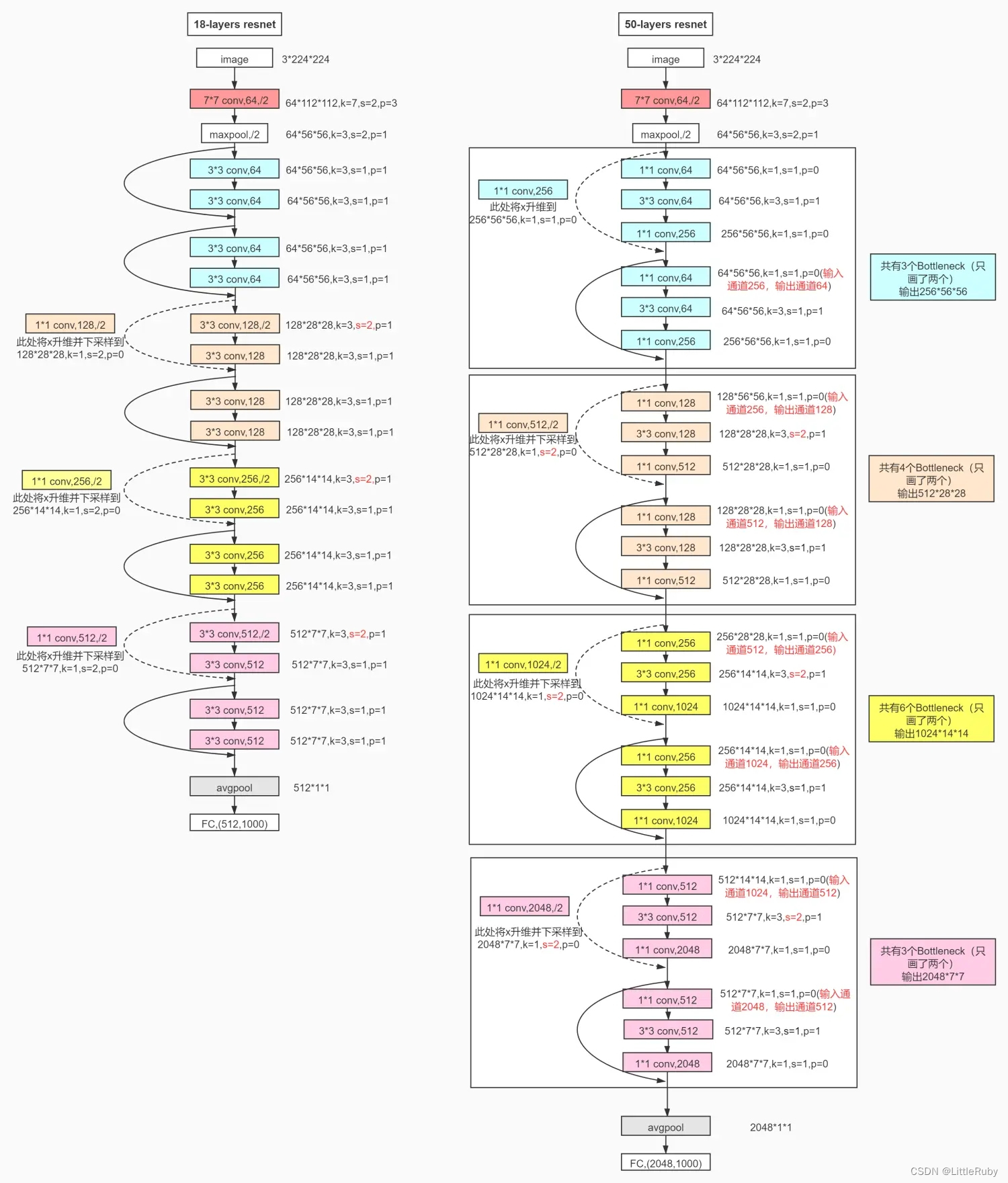
参考链接:resnet18 50网络结构以及pytorch实现代码
ResNet-50有两个基本的块,分别名为Conv Block和Identity Block
首先说说Conv Block,也就是第一个实线方框中虚线连接的三层:
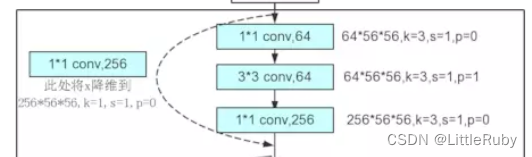
可以看到,总体的思路是先通过1×1的卷积对特征图像进行降维,做一次3×3的卷积操作,最后再通过1×1卷积恢复维度,后面跟着BN和ReLU层;虚线处用256个1×1的卷积网络,将maxpool的输出降维到255×56×56。
再说Identity Block,
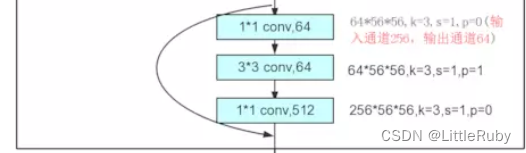
也就是实线连接所示,不经过卷积网络降维,直接将输入加到最后的1×1卷积输出上。
经过后面的Block,经过平均池化和全连接,用softmax实现回归。
参考链接:ResNet-50网络理解
Resnet50简化画法如下: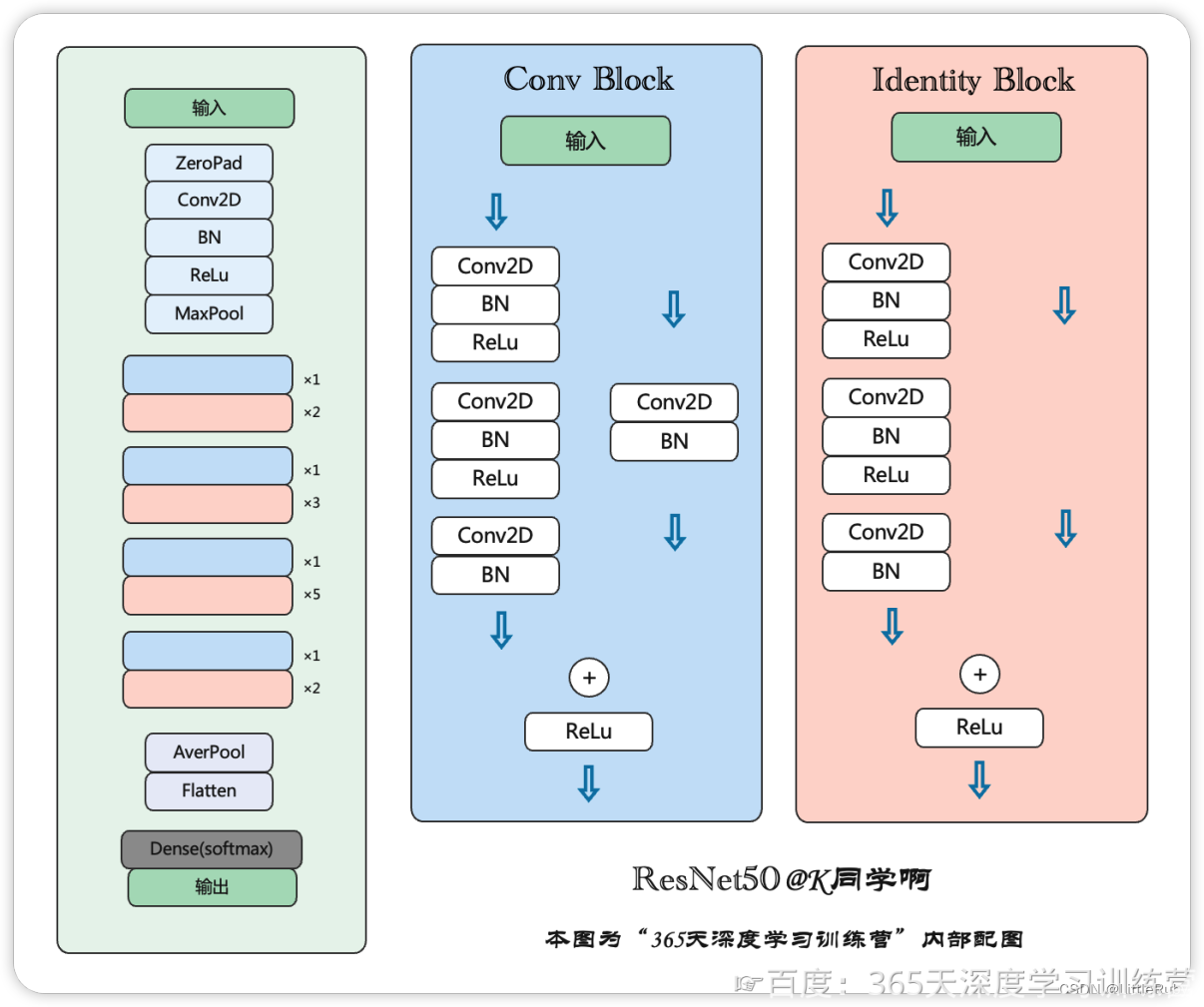
6 SoftMax以及它的实现原理
SoftMax要处理多个类别分类的问题。并且,需要把每个分类的得分值换算成概率,同时解决两个分类得分值接近的问题。
先从公式上看,SoftMmax是怎么做到的。
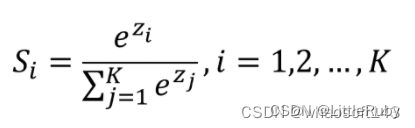
公式中,每个 z 就对应了多个分类的得分值。SoftMax对得分值进行了如下处理:
以e为底数进行了指数运算,算出每个分类的 eZi,作为公式的分子
分母为各分类得分指数运算的加和。
根据公式很自然可以想到,各个分类的SoftMax值加在一起是1,也就是100%。
所以,每个分类的SoftMax的值,就是将得分转化为了概率,所有分类的概率加在一起是100%。
这个公式很自然的就解决了从得分映射到概率的问题。那,它又是怎么解决两个得分相近的问题的呢?
其实也很简单,重点在选择的指数操作上。我们知道指数的曲线是下面的样子。

指数曲线,恒大于零,并且在正半轴,离零越远,增长越快(指数增长)
指数增长的特性就是,横轴变化很小的量,纵轴就会有很大的变化。所以,从1.9变化到2.1,经过指数的运算,两者的差距立马被的拉大了。whaosoft aiot http://143ai.com
从而,我们可以更加明确的知道,图片的分类应该属于最大的那个。下面是将猫、狗、人三个分类经过SoftMax计算之后得到的概率。
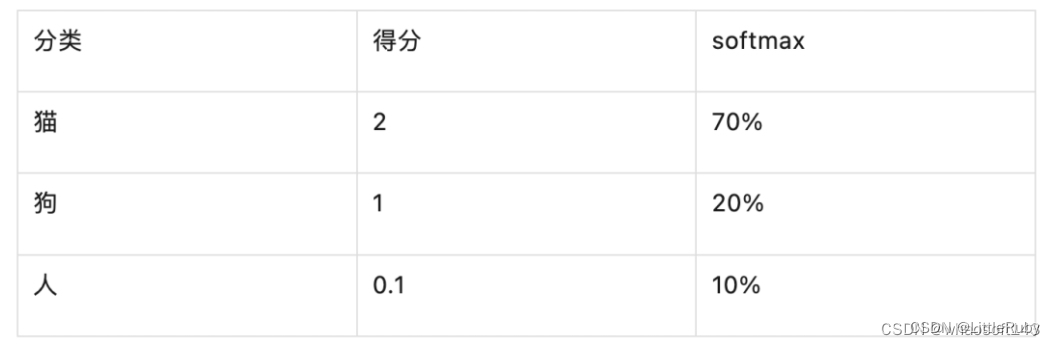
可以看到,分类是猫的概率遥遥领先。所以,神经网络在经过softmax层之后,会以70%的概率,认为这张图片是一张猫。
这就是SoftMax的底层原理。
指数让得分大的分类最终的概率更大,得分小的分类最终的概率更小,而得分为负数的分类,几乎可以忽略。
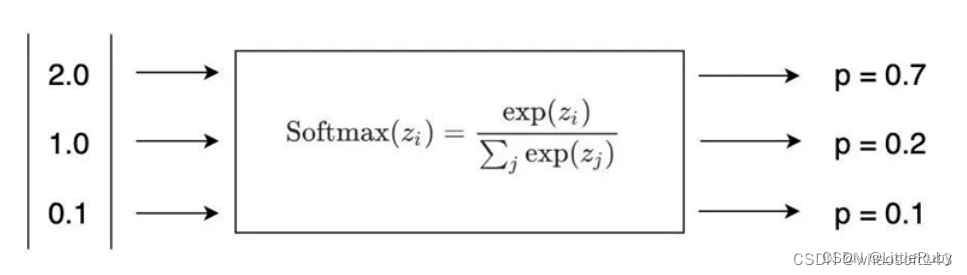
参考链接:Resnet50算法原理
7 pytorch实现Resnet50算法
# -*- coding: utf-8 -*-
# @Author : Ruby
# @File : pytorch_weather.pyimport torch
import torch.nn as nn
import time
import copy
from torchvision import transforms, datasets
import os
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as F
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印def autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, act=True): # ch_in, ch_out, kernel, stride, paddingsuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=1, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.ReLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))class ConvBlock(nn.Module):def __init__(self, c1, c2, c3, s0=1): #ch_in, ch_out1, ch_out2,s0super().__init__()self.cv1 = Conv(c1, c2, k=1, s=1, p=0)self.cv2 = Conv(c2, c2, k=3, s=s0, p=1)self.cv3 = Conv(c2, c3, k=1, s=1, p=0, act=False)self.cv4 = Conv(c1, c3, k=1, s=s0, p=0, act=False)self.act = nn.ReLU()def forward(self, x):return self.act(self.cv4(x) + self.cv3(self.cv2(self.cv1(x))))class IdentityBlock(nn.Module):def __init__(self, c1, c2, c3): # ch_in, ch_out1, ch_out2super().__init__()self.cv1 = Conv(c1, c2, 1, 1, 0)self.cv2 = Conv(c2, c2, 3, 1, 1)self.cv3 = Conv(c2, c3, 1, 1, 0, act=False)self.act = nn.ReLU()def forward(self, x):return self.act(x + self.cv3(self.cv2(self.cv1(x))))class Resnet50(nn.Module):def __init__(self):super(Resnet50, self).__init__()# 卷积块1self.Conv_1 = Conv(3, 64, 7, 2, 3)self.Conv_2 = nn.Sequential(nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2)), # in:256 out:64ConvBlock(64, 64, 256), # out:64->64->256IdentityBlock(256, 64, 256), # out:256->64->256IdentityBlock(256, 64, 256), # out:256->64->256)self.Conv_3 = nn.Sequential(ConvBlock(256, 128, 512, 2), # out:128->128->512IdentityBlock(512, 128, 512), # out:128->128->512IdentityBlock(512, 128, 512), # out:128->128->512IdentityBlock(512, 128, 512) # out:128->128->512)self.Conv_4 = nn.Sequential(ConvBlock(512, 256, 1024, 2), # out:256->256->1024IdentityBlock(1024, 256, 1024), # out:256->256->1024IdentityBlock(1024, 256, 1024), # out:256->256->1024IdentityBlock(1024, 256, 1024), # out:256->256->1024IdentityBlock(1024, 256, 1024), # out:256->256->1024IdentityBlock(1024, 256, 1024) # out:256->256->1024)self.Conv_5 = nn.Sequential(ConvBlock(1024, 512, 2048, 2), # out:512->512->2048IdentityBlock(2048, 512, 2048), # out:512->512->2048IdentityBlock(2048, 512, 2048), # out:512->512->2048)self.avgpool = nn.AvgPool2d(7, stride=2)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=2048, out_features=1000),nn.Softmax(dim=1))def forward(self, x):x = self.Conv_1(x)x = self.Conv_2(x)x = self.Conv_3(x)x = self.Conv_4(x)x = self.Conv_5(x)x = self.avgpool(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return x"""训练模型--编写训练函数"""
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)X, y = X.to(device), y.to(device) # 用于将数据存到显卡# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item() # 统计预测正确的个数test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossdef predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.axis("off")plt.imshow(test_img) # 展示预测的图片plt.show()test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')if __name__ == '__main__':"""前期准备-设置GPU"""# 如果设备上支持GPU就使用GPU,否则使用CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("Using {} device".format(device))'''前期工作-导入数据'''data_dir = r"D:\DeepLearning\data\bird\bird_photos"data_dir = Path(data_dir)data_paths = list(data_dir.glob('*'))classeNames = [str(path).split("\\")[-1] for path in data_paths]print(classeNames)'''前期工作-可视化数据'''subfolder = Path(data_dir)/"Cockatoo"image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])plt.figure(figsize=(10, 6))for i in range(len(image_files[:12])):image_file = image_files[i]ax = plt.subplot(3, 4, i + 1)img = Image.open(str(image_file))plt.imshow(img)plt.axis("off")# 显示图片plt.tight_layout()plt.show()'''前期工作-图像数据变换'''# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸# transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。])total_data = datasets.ImageFolder(str(data_dir), transform=train_transforms)print(total_data)print(total_data.class_to_idx)'''前期工作-划分数据集'''train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))print("train_size={}\ntest_size={}".format(train_size, test_size))'''前期工作-加载数据'''batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)'''前期工作-查看数据'''for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break"""搭建包含Backbone模块的模型"""model = Resnet50().to(device)print(model)print(summary.summary(model, (3, 224, 224)))#查看模型的参数量以及相关指标# exit()"""训练模型--设置超参数"""loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数learn_rate = 1e-4 # 学习率optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)optimizer3 = torch.optim.Adam(model.parameters(), lr=learn_rate, weight_decay=1e-4) #增加权重衰减,即L2正则化lr_opt = optimizer2model_opt = optimizer2# 调用官方动态学习率接口时使用2lambda1 = lambda epoch : 0.92 ** (epoch // 4)scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) # 选定调整方法"""训练模型--正式训练"""epochs = 30train_loss = []train_acc = []test_loss = []test_acc = []best_test_acc=0for epoch in range(epochs):milliseconds_t1 = int(time.time() * 1000)# 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(lr_opt, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = lr_opt.state_dict()['param_groups'][0]['lr']milliseconds_t2 = int(time.time() * 1000)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')if best_test_acc < epoch_test_acc:best_test_acc = epoch_test_acc#备份最好的模型best_model = copy.deepcopy(model)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')print(template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))# 保存最佳模型到文件中PATH = './best_model.pth' # 保存的参数文件名torch.save(model.state_dict(), PATH)print('Done')"""训练模型--结果可视化"""epochs_range = range(epochs)plt.figure(figsize=(12, 3))plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')plt.plot(epochs_range, test_acc, label='Test Accuracy')plt.legend(loc='lower right')plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)plt.plot(epochs_range, train_loss, label='Training Loss')plt.plot(epochs_range, test_loss, label='Test Loss')plt.legend(loc='upper right')plt.title('Training and Validation Loss')plt.show()"""保存并加载模型"""# 模型保存# PATH = './model.pth' # 保存的参数文件名# torch.save(model.state_dict(), PATH)# 将参数加载到model当中model.load_state_dict(torch.load(PATH, map_location=device))"""指定图片进行预测"""classes = list(total_data.class_to_idx)# 预测训练集中的某张照片predict_one_image(image_path=str(Path(data_dir)/"Cockatoo/001.jpg"),model=model,transform=train_transforms,classes=classes)"""模型评估"""best_model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)# 查看是否与我们记录的最高准确率一致print(epoch_test_acc, epoch_test_loss)训练过程如下:
Epoch: 1, duration:4065ms, Train_acc:25.7%, Train_loss:6.817, Test_acc:15.0%,Test_loss:6.771, Lr:1.00E-04,Update the best model
Epoch: 2, duration:3783ms, Train_acc:43.8%, Train_loss:6.485, Test_acc:27.4%,Test_loss:6.613, Lr:1.00E-04,Update the best model
Epoch: 3, duration:3829ms, Train_acc:63.5%, Train_loss:6.285, Test_acc:54.0%,Test_loss:6.369, Lr:1.00E-04,Update the best model
Epoch: 4, duration:3772ms, Train_acc:73.7%, Train_loss:6.194, Test_acc:44.2%,Test_loss:6.462, Lr:1.00E-04
Epoch: 5, duration:3814ms, Train_acc:68.8%, Train_loss:6.214, Test_acc:40.7%,Test_loss:6.500, Lr:1.00E-04
Epoch: 6, duration:3810ms, Train_acc:75.7%, Train_loss:6.160, Test_acc:70.8%,Test_loss:6.208, Lr:1.00E-04,Update the best model
Epoch: 7, duration:3825ms, Train_acc:83.0%, Train_loss:6.081, Test_acc:77.9%,Test_loss:6.132, Lr:1.00E-04,Update the best model
Epoch: 8, duration:3840ms, Train_acc:81.4%, Train_loss:6.134, Test_acc:65.5%,Test_loss:6.248, Lr:1.00E-04
Epoch: 9, duration:3929ms, Train_acc:84.7%, Train_loss:6.110, Test_acc:77.0%,Test_loss:6.125, Lr:1.00E-04
Epoch:10, duration:3843ms, Train_acc:86.9%, Train_loss:6.046, Test_acc:85.0%,Test_loss:6.083, Lr:1.00E-04,Update the best model
Epoch:11, duration:4012ms, Train_acc:89.2%, Train_loss:6.032, Test_acc:91.2%,Test_loss:5.991, Lr:1.00E-04,Update the best model
Epoch:12, duration:3817ms, Train_acc:91.8%, Train_loss:6.013, Test_acc:66.4%,Test_loss:6.210, Lr:1.00E-04
Epoch:13, duration:4025ms, Train_acc:91.6%, Train_loss:6.029, Test_acc:78.8%,Test_loss:6.137, Lr:1.00E-04
Epoch:14, duration:4011ms, Train_acc:83.6%, Train_loss:6.084, Test_acc:69.0%,Test_loss:6.237, Lr:1.00E-04
Epoch:15, duration:3924ms, Train_acc:85.8%, Train_loss:6.042, Test_acc:59.3%,Test_loss:6.314, Lr:1.00E-04
Epoch:16, duration:3958ms, Train_acc:86.5%, Train_loss:6.045, Test_acc:86.7%,Test_loss:6.032, Lr:1.00E-04
Epoch:17, duration:4038ms, Train_acc:88.7%, Train_loss:6.044, Test_acc:77.0%,Test_loss:6.166, Lr:1.00E-04
Epoch:18, duration:3850ms, Train_acc:87.8%, Train_loss:6.049, Test_acc:54.0%,Test_loss:6.333, Lr:1.00E-04
Epoch:19, duration:3861ms, Train_acc:86.3%, Train_loss:6.066, Test_acc:72.6%,Test_loss:6.197, Lr:1.00E-04
Epoch:20, duration:3839ms, Train_acc:84.3%, Train_loss:6.085, Test_acc:73.5%,Test_loss:6.153, Lr:1.00E-04
Epoch:21, duration:3892ms, Train_acc:87.4%, Train_loss:6.029, Test_acc:83.2%,Test_loss:6.084, Lr:1.00E-04
Epoch:22, duration:3848ms, Train_acc:90.9%, Train_loss:6.010, Test_acc:90.3%,Test_loss:6.018, Lr:1.00E-04
Epoch:23, duration:3826ms, Train_acc:86.7%, Train_loss:6.054, Test_acc:83.2%,Test_loss:6.079, Lr:1.00E-04
Epoch:24, duration:3937ms, Train_acc:91.6%, Train_loss:6.005, Test_acc:73.5%,Test_loss:6.168, Lr:1.00E-04
Epoch:25, duration:3862ms, Train_acc:86.7%, Train_loss:6.038, Test_acc:80.5%,Test_loss:6.109, Lr:1.00E-04
Epoch:26, duration:3928ms, Train_acc:88.5%, Train_loss:6.036, Test_acc:85.0%,Test_loss:6.051, Lr:1.00E-04
Epoch:27, duration:3869ms, Train_acc:90.0%, Train_loss:6.010, Test_acc:83.2%,Test_loss:6.094, Lr:1.00E-04
Epoch:28, duration:3851ms, Train_acc:92.5%, Train_loss:5.999, Test_acc:95.6%,Test_loss:5.960, Lr:1.00E-04,Update the best model
Epoch:29, duration:3831ms, Train_acc:93.4%, Train_loss:5.977, Test_acc:89.4%,Test_loss:6.019, Lr:1.00E-04
Epoch:30, duration:3839ms, Train_acc:96.2%, Train_loss:5.960, Test_acc:92.9%,Test_loss:5.992, Lr:1.00E-04
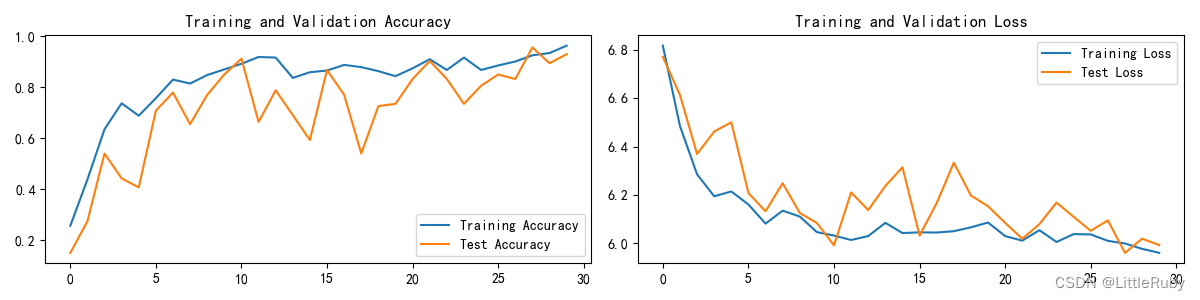
评估结果
0.9557522123893806 5.960119128227234
总结
通过本次的学习,了解了cnn的发展史,了解了残差网络可以解决梯度消失、爆炸及网络退化的问题,并了解了softmax的实现原理与作用,并学会了使用pytorch实现ResNet50,当把模型优化器改为SGD时,训练精度与测试进度均为0,但改为Adam后效果就不错。
![[C/C++]数据结构: 链式二叉树的构建及遍历](https://img-blog.csdnimg.cn/direct/e21f791949d242d3a5551a5aff5e3638.png)
![【C++11特性篇】模板的新一力将:可变参数模板 [全解析]](https://img-blog.csdnimg.cn/direct/8359486756ba4a4681cfcfd90e81be20.png)