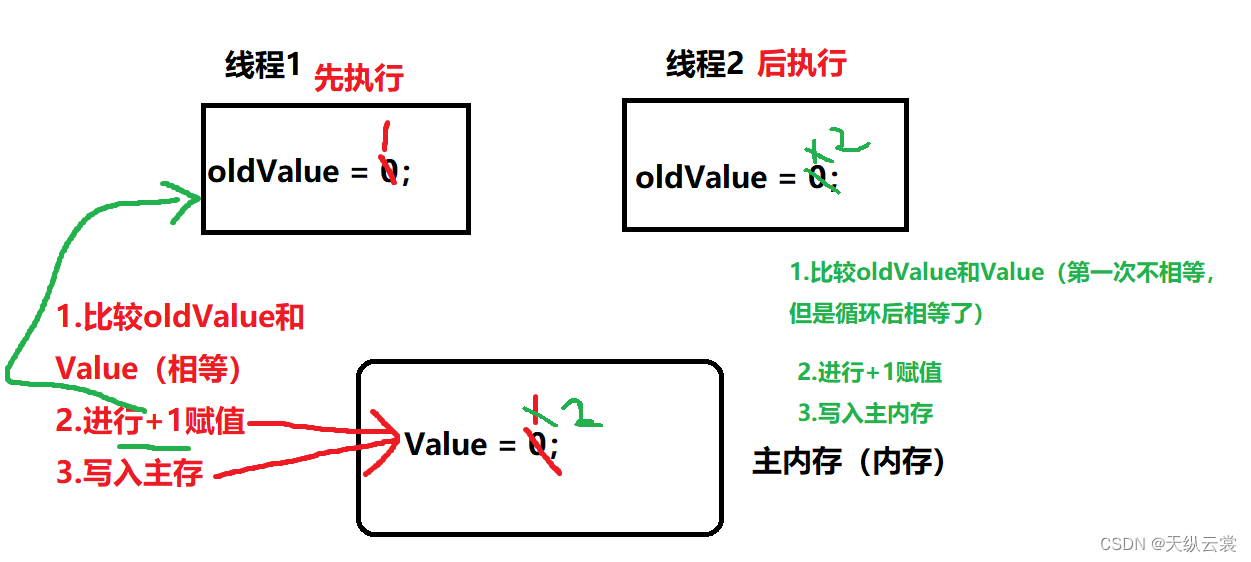
通过 HBase 的相关 JavaAPI,我们可以实现伴随 HBase 操作的 MapReduce 过程,比如使用 MapReduce 将数据从本地文件系统导入到 HBase 的表中,比如我们从 HBase 中读取一些原 始数据后使用 MapReduce 做数据分析。
1 官方 HBase-MapReduce
1.查看 HBase 的 MapReduce 任务的执行
./bin/hbase mapredcp
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hbase-1.3.1/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
/opt/module/hbase-1.3.1/lib/zookeeper-3.4.6.jar:/opt/module/hbase-1.3.1/lib/guava-12.0.1.jar:/opt/module/hbase-1.3.1/lib/metrics-core-2.2.0.jar:/opt/module/hbase-1.3.1/lib/protobuf-java-2.5.0.jar:/opt/module/hbase-1.3.1/lib/hbase-common-1.3.1.jar:/opt/module/hbase-1.3.1/lib/hbase-protocol-1.3.1.jar:/opt/module/hbase-1.3.1/lib/htrace-core-3.1.0-incubating.jar:/opt/module/hbase-1.3.1/lib/hbase-client-1.3.1.jar:/opt/module/hbase-1.3.1/lib/hbase-hadoop-compat-1.3.1.jar:/opt/module/hbase-1.3.1/lib/netty-all-4.0.23.Final.jar:/opt/module/hbase-1.3.1/lib/hbase-server-1.3.1.jar:/opt/module/hbase-1.3.1/lib/hbase-prefix-tree-1.3.1.jar2.环境变量的导入
(1)执行环境变量的导入(临时生效,在命令行执行下述操作)
$ export HBASE_HOME=/opt/module/hbase
$ export HADOOP_HOME=/opt/module/hadoop-2.7.2
$ export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`(2)永久生效:在/etc/profile 配置
export HBASE_HOME=/opt/module/hbase
export HADOOP_HOME=/opt/module/hadoop-2.7.2并在 hadoop-env.sh 中配置:(注意:在 for 循环之后配)
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase-1.3.1/lib/*3.运行官方的 MapReduce 任务 --
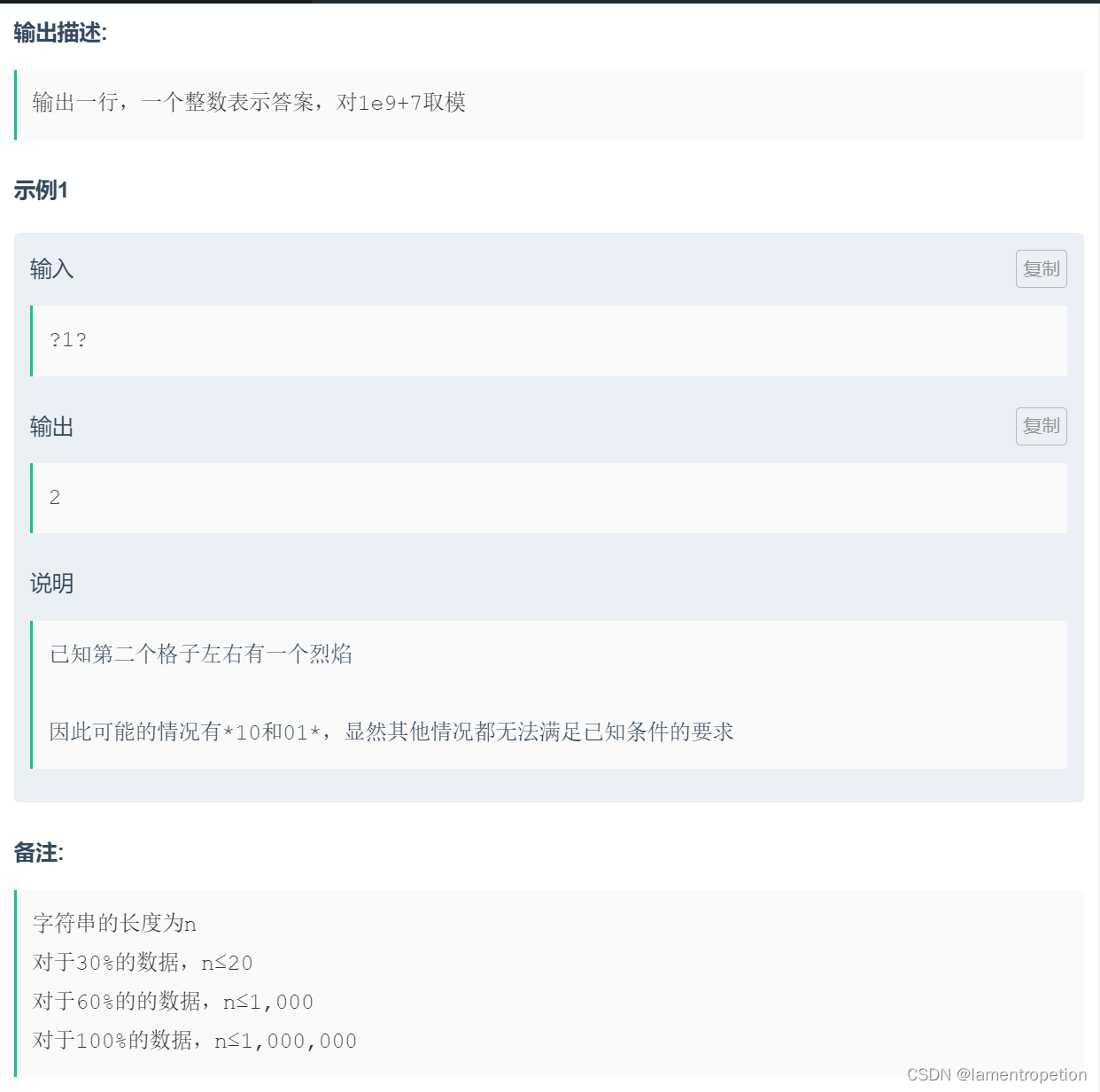
案例一:统计 Student 表中有多少行数据
/opt/module/hadoop-3.1.3/bin/yarn jar lib/hbase-server-1.3.1.jar rowcounter stu
案例二:使用 MapReduce 将本地数据导入到 HBase
1)在本地创建一个 tsv 格式的文件:fruit.tsv(注意这里的分隔符是TAB键)
1001 Apple Red
1002 Pear Yellow
1003 Pineapple Yellow3)上传到hadoop
hadoop fs -put fruit.tsv /4)执行 MapReduce 到 HBase 的 fruit 表中
/opt/module/hadoop-3.1.3/bin/yarn jar lib/hbase-server-1.3.1.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit hdfs://hadoop101:9000/input_fruit
2)创建 Hbase 表
Hbase(main):001:0> create 'fruit','info'5)使用 scan 命令查看导入后的结果
hbase(main):011:0> scan 'fruit'
ROW COLUMN+CELL 1001 column=info:color, timestamp=1642253156646, value=Red 1001 column=info:name, timestamp=1642253156646, value=Apple 1002 column=info:color, timestamp=1642253156646, value=Yellow 1002 column=info:name, timestamp=1642253156646, value=Pear 1003 column=info:color, timestamp=1642253156646, value=Yellow 1003 column=info:name, timestamp=1642253156646, value=Pineapple
3 row(s) in 0.2760 seconds2 自定义 HBase-MapReduce1
目标:将 fruit 表中的一部分数据,通过 MR 迁入到 fruit_mr 表中。
分步实现:
1.构建 ReadFruitMapper 类,用于读取 fruit 表中的数据
package com.atguigu.mr;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FruitMapper extends Mapper<LongWritable, Text,LongWritable,Text> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {context.write(key,value);}
}
2. 构建 WriteFruitMRReducer 类,用于将读取到的 fruit 表中的数据写入到 fruit_mr 表中
package com.atguigu.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FruitReducer extends TableReducer<LongWritable, Text, NullWritable> {
//可以进行动态传参String cf1;
@Overrideprotected void setup(Context context) throws IOException, InterruptedException {
Configuration configuration = context.getConfiguration();
cf1 = configuration.get("cf1");}
@Overrideprotected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//1.遍历valuesfor (Text value : values) {//获取每一行数据String[] fields = value.toString().split("\t");
//3.构建put对象Put put = new Put(Bytes.toBytes(fields[0]));
//4.给put对象赋值put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(fields[1]));put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("color"),Bytes.toBytes(fields[2]));
//5. 写出context.write(NullWritable.get(),put);}
}
}
3.构建 Fruit2FruitMRRunner extends Configured implements Tool 用于组装运行 Job任务
package com.atguigu.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/*** @author:左泽林* @date:日期:2022-01-16-时间:8:55* @message:*/
public class FruitDriver implements Tool {
//定义一个COnfigurationprivate Configuration configuration = null;
public int run(String[] args) throws Exception {
//1.获取Job对象Job job = Job.getInstance(configuration);
//2. 设置驱动类路径job.setJarByClass(FruitDriver.class);
//3. 设置mapper&mapper输出的KV类型job.setMapperClass(FruitMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);
//4. 设置Reducer类TableMapReduceUtil.initTableReducerJob(args[1] , FruitReducer.class , job);
//5. 设置输入输出的参数FileInputFormat.setInputPaths(job,new Path(args[0]));
//6. 提交任务boolean result = job.waitForCompletion(true);
return result ? 0 : 1;}
public void setConf(Configuration configuration) {this.configuration = configuration;}
public Configuration getConf() {return null;}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new FruitDriver(), args);
System.exit(run);}
}
4.主函数中调用运行该 Job 任务
5.打包运行任务

6. 上传jar包到虚拟机,在hbase中创建fruit1表,在运行创建的jar包
创建fruit表:
hbase(main):003:0* create 'fruit1','info'
0 row(s) in 1.8160 seconds=> Hbase::Table - fruit1运行jar包
yarn jar hbase-1.0-SNAPSHOT.jar com.atguigu.mr.FruitDriver /input/fruit.tsv fruit1查看fruit1表中的结果:
hbase(main):004:0> scan 'fruit1'
ROW COLUMN+CELL 1001 column=info:color, timestamp=1642298137576, value=Red 1001 column=info:name, timestamp=1642298137576, value=Apple 1002 column=info:color, timestamp=1642298137576, value=Yellow 1002 column=info:name, timestamp=1642298137576, value=Pear 1003 column=info:color, timestamp=1642298137576, value=Yellow 1003 column=info:name, timestamp=1642298137576, value=Pineapple
3 row(s) in 0.4790 seconds3 自定义 Hbase-MapReduce2
目标:实现将 HDFS 中的数据写入到 Hbase 表中。
分步实现:
1.构建 ReadFruitFromHDFSMapper 于读取 HDFS 中的文件数据
package com.atguigu.mr2;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;public class Fruit2Mapper extends TableMapper<ImmutableBytesWritable , Put> {
@Overrideprotected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//构建Put对象Put put = new Put(key.get());
//1.获取数据for (Cell cell : value.rawCells()) {
//2.判断当前的cell是否为”name“列if ("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){
//3.给Put对象赋值put.add(cell);
}}
//4.写出context.write(key,put);}
}2.构建 WriteFruitMRFromTxtReducer 类
package com.atguigu.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class Fruit2Reducer extends TableReducer<ImmutableBytesWritable , Put , NullWritable> {
@Overrideprotected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
//1。遍历写出for (Put value : values) {
context.write(NullWritable.get(),value);
}
}
}
3.创建 Txt2FruitRunner 组装 Job
package com.atguigu.mr2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class Fruit2Driver implements Tool {
//定义配置信息private Configuration configuration = null;
public int run(String[] args) throws Exception {
//1.获取Job对象Job job = Job.getInstance(configuration);
//2. 设置主类路径job.setJarByClass(Fruit2Driver.class);
//3.设置Mapper&输出KV类型TableMapReduceUtil.initTableMapperJob("fruit",new Scan(),Fruit2Mapper.class,ImmutableBytesWritable.class,Put.class,job);
//4.设置Reducer&输出的表TableMapReduceUtil.initTableReducerJob("fruit12",Fruit2Reducer.class,job);
//5.提交任务boolean result = job.waitForCompletion(true);
return result ? 0 : 1;}
public void setConf(Configuration configuration) {this.configuration = configuration;}
public Configuration getConf() {return configuration;}
public static void main(String[] args) throws Exception {
Configuration configuration = HBaseConfiguration.create();
ToolRunner.run(configuration, new Fruit2Driver() , args);
}
}