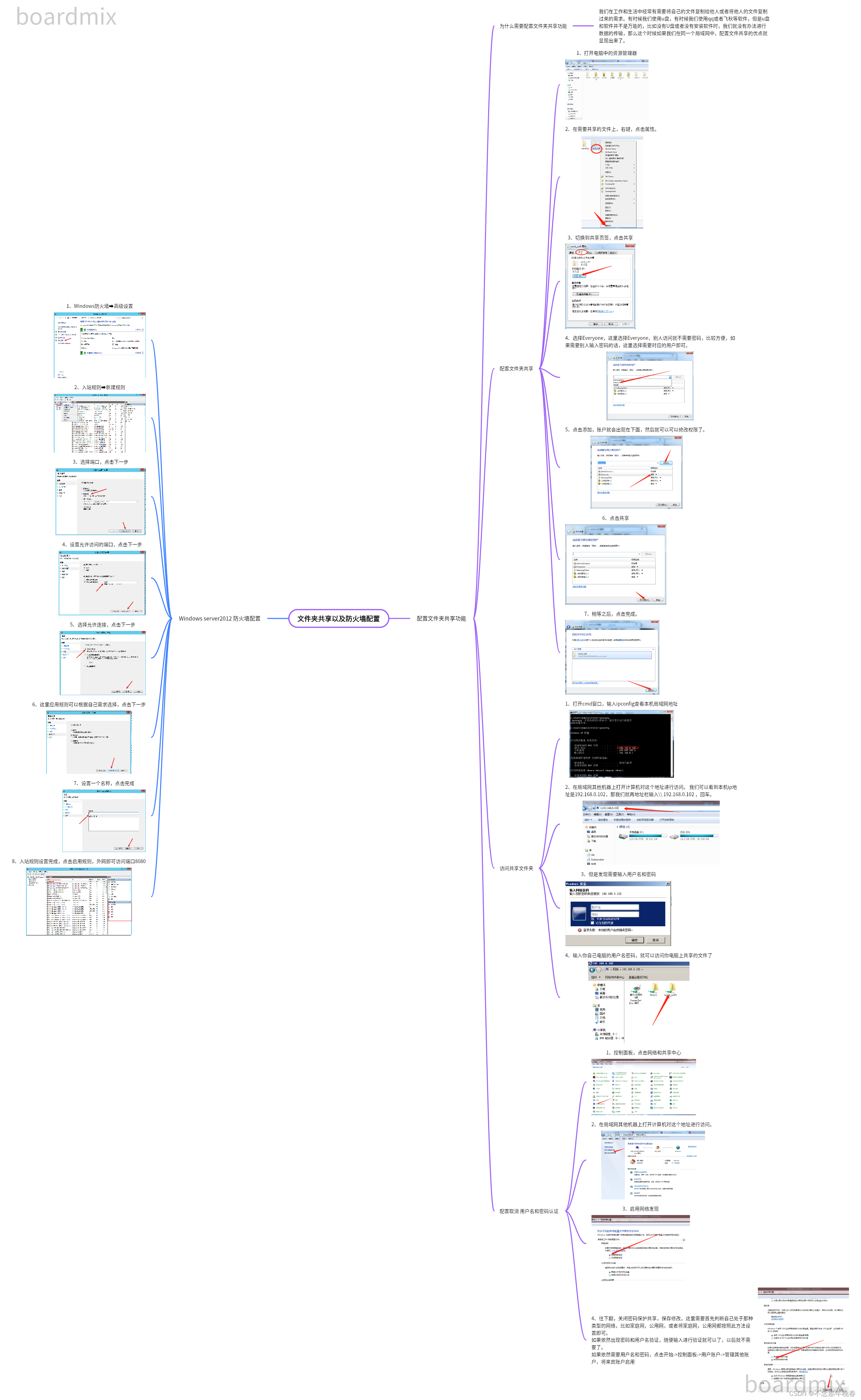
一、简介
一、简介
正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。
二、起源
正则表达式的“鼻祖”或许可一直追溯到科学家对人类神经系统工作原理的早期研究。美国新泽西州的Warren McCulloch和出生在美国底特律的Walter Pitts这两位神经生理方面的科学家,研究出了一种用数学方式来描述神经网络的新方法,他们创造性地将神经系统中的神经元描述成了小而简单的自动控制元,从而作出了一项伟大的工作革新。
在1951 年,一位名叫Stephen Kleene的数学科学家,他在Warren McCulloch和Walter Pitts早期工作的基础之上,发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。
之后一段时间,人们发现可以将这一工作成果应用于其他方面。1968年,Unix之父Ken Thompson就把这一成果应用于计算搜索算法的一些早期研究。Ken Thompson将此符号系统引入编辑器QED,然后是Unix上的编辑器ed,并最终引入grep。Jeffrey Friedl 在其著作《Mastering Regular Expressions (2nd edition)》(中文版译作:精通正则表达式,已出到第三版)中对此作了进一步阐述讲解。
自此以后,正则表达式被广泛地应用到各种UNIX或类似于UNIX的工具中,如大家熟知的Perl。Perl的正则表达式源自于Henry Spencer编写的regex,之后已演化成了pcre(Perl兼容正则表达式Perl Compatible Regular Expressions),pcre是一个由Philip Hazel开发的、为很多现代工具所使用的库。正则表达式的第一个实用应用程序即为Unix中的 qed 编辑器。
 三、引擎
三、引擎
正则引擎主要可以分为两大类:一种是确定型有穷自动机(Deterministic finite automaton, DFA),一种是非确定型有穷自动机(Non-deterministic finite automaton,NFA)。这两种引擎都有了很久的历史,当中也由这两种引擎产生了很多变体。于是POSIX的出台规避了不必要变体的继续产生。这样一来,主流的正则引擎又分为3类:一、DFA,二、传统型NFA,三、POSIX NFA。
- **DFA引擎**:
DFA引擎对每一个字符只进行一次判断。它比较快速且其性能不受正则表达式复杂度的影响,但它不支持某些高级匹配特性,例如捕获组和回溯引用。
DFA 引擎在线性时状态下执行,因为它们不要求回溯(并因此它们永远不测试相同的字符两次)。DFA 引擎还可以确保匹配最长的可能的字符串。但是,因为 DFA 引擎只包含有限的状态,所以它不能匹配具有反向引用的模式;并且因为它不构造显示扩展,所以它不可以捕获子表达式。
- **NFA引擎**:
NFA引擎可以进行回溯,支持更复杂的正则功能,如前述的捕获组、非贪婪量词以及前后断言等。大部分现代编程语言使用这种引擎。然而,当正则表达式特别复杂时,NFA引擎可能导致性能下降,因为它会尝试所有可能的路径来匹配一个字符串。
传统的 NFA 引擎运行所谓的“贪婪的”匹配回溯算法,以指定顺序测试正则表达式的所有可能的扩展并接受第一个匹配项。因为传统的 NFA 构造正则表达式的特定扩展以获得成功的匹配,所以它可以捕获子表达式匹配和匹配的反向引用。但是,因为传统的 NFA 回溯,所以它可以访问完全相同的状态多次(如果通过不同的路径到达该状态)。因此,在最坏情况下,它的执行速度可能非常慢。因为传统的 NFA 接受它找到的第一个匹配,所以它还可能会导致其他(可能更长)匹配未被发现。
POSIX NFA 引擎与传统的 NFA 引擎类似,不同的一点在于:在它们可以确保已找到了可能的最长的匹配之前,它们将继续回溯。因此,POSIX NFA 引擎的速度慢于传统的 NFA 引擎;并且在使用 POSIX NFA 时,您恐怕不会愿意在更改回溯搜索的顺序的情况下来支持较短的匹配搜索,而非较长的匹配搜索。
使用DFA引擎的程序主要有:awk,egrep,flex,lex,MySQL,Procmail等;
使用传统型NFA引擎的程序主要有:GNU Emacs,Java,ergp,less,more,.NET语言,PCRE library,Perl,PHP,Python,Ruby,sed,vi;
使用POSIX NFA引擎的程序主要有:mawk,Mortice Kern Systems’ utilities,GNU Emacs(使用时可以明确指定);
也有使用DFA/NFA混合的引擎:GNU awk,GNU grep/egrep,Tcl。
举例简单说明NFA与DFA工作的区别:
比如有字符串this is yansen’s blog,正则表达式为 /ya(msen|nsen|nsem)/ (不要在乎表达式怎么样,这里只是为了说明引擎间的工作区别)。 NFA工作方式如下,先在字符串中查找 y 然后匹配其后是否为 a ,如果是 a 则继续,查找其后是否为 m 如果不是则匹配其后是否为 n (此时淘汰msen选择支)。然后继续看其后是否依次为 s,e,接着测试是否为 n ,是 n 则匹配成功,不是则测试是否为 m 。为什么是 m ?因为 NFA 工作方式是以正则表达式为标准,反复测试字符串,这样同样一个字符串有可能被反复测试了很多次。
而DFA则不是如此,DFA会从 this 中 t 开始依次查找 y,定位到 y ,已知其后为a,则查看表达式是否有 a ,此处正好有a 。然后字符串a 后为n ,DFA依次测试表达式,此时 msen 不符合要求淘汰。nsen 和 nsem 符合要求,然后DFA依次检查字符串,检测到sen 中的 n 时只有nsen 分支符合,则匹配成功。
由此可以看出来,两种引擎的工作方式完全不同,一个(NFA)以表达式为主导,一个(DFA)以文本为主导。一般而论,DFA引擎则搜索更快一些。但是NFA以表达式为主导,反而更容易操纵,因此一般程序员更偏爱NFA引擎。 两种引擎各有所长,而真正的引用则取决与你的需要以及所使用的语言。
四、实现正则表达式的库:
正则表达式的具体实现通常指具体编程语言或工具所使用的库或模块。例如:
- **PCRE (Perl Compatible Regular Expressions)**:广泛用于各种语言和工具中,提供了类似Perl语言正则表达式功能的实现。
- **std::regex**:C++的正则表达式库,可以在C++程序中使用。
- **re**:这是Python语言中的一个标准库,用于提供正则表达式的支持。
- **java.util.regex**:Java语言中用于处理正则表达式的类库。
- **RegExp**:JavaScript中内建的正则表达式支持。
五、正则表达式的语法
正则表达式的语法可以非常复杂,但以下是一些基本的组成元素:
1. **字面量** (Literals):
任何非特殊字符都会匹配它自己。
2. **元字符** (Metacharacters):
在正则表达式中有特殊含义的字符,
如:
- . 表示任何单个字符(除了换行符)。
- ^ 表示行的开始。
- $ 表示行的结束。
- * 表示前一个字符的0次或多次匹配。
- + 表示前一个字符的1次或多次匹配。
- ? 表示前一个字符的0次或1次匹配。
- {n,m} 表示前一个字符至少n次,不超过m次的匹配。
3. **字符集** (Character classes):
定义一个字符集合,匹配该集合中的任意字符。
- [abc] 将匹配 "a"、"b" 或 "c"。
- [^abc] 将匹配 "a"、"b" 和 "c" 之外的任何字符。
- [a-z] 匹配任何小写字母。
- [A-Z] 匹配任何大写字母。
- [0-9] 匹配任何数字。
4. **转义字符** (Escape character):
\ 被用来转义特殊字符。
- \t 表示制表符。
- \n 表示换行符。
- \\ 表示字面量的反斜杠。
- \. 表示字面量的点(不再是元字符了)。
5. **锚点** (Anchors):
\b 和 \B 表示单词的边界和非边界。
- \b 匹配一个单词边界,即字与空格间的位置。
- \B 匹配非单词边界。
6. **分组** (Grouping) 和 **捕获** (Capturing):
- 使用小括号`()`可以将多个字符组成一个单元,这个单元可以用`*、+`等元字符来整体匹配。
- (abc) 表示匹配字面字符串 "abc"。
- (a|b) 表示匹配 "a" 或 "b"。
7. **非捕获分组** (Non-capturing groups):
使用`(?: ... )`可以进行分组但不捕获匹配的子字符串。
8. **前向和后向断言** (Lookahead and Lookbehind assertions):
- 前向肯定断言 (?=...) 匹配一个后面跟着特定模式的位置。
- 前向否定断言 (?!...) 匹配一个后面不跟着特定模式的位置。
- 后向肯定断言 (?<=...) 匹配一个前面是特定模式的位置。
- 后向否定断言 (?<!...) 匹配一个前面不是特定模式的位置。
正则表达式在各种编程语言中都有广泛的支持,包括Python、Java、JavaScript、C#、PHP等。在不同的编程语言中,正则表达式的工作方式和性能上可能有所差异,但基本的语法规则是一致的。在实际使用中,由于正则表达式的复杂性,通常推荐先通过文档加深理解,并在在线测试工具上练习,以便熟练掌握其强大的功能。
六、正则表达式用例
1. **验证电子邮件地址**:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ - ^ 匹配输入字符串的开始位置。
- [a-zA-Z0-9._%+-]+ 匹配前面的字符集合一次或多次(邮件用户名部分)。
- @ 字面量字符 "@"。
- [a-zA-Z0-9.-]+ 匹配邮件服务提供商名(域名前部)。
- \. 字面量点,用来分隔域名的各部分。
- [a-zA-Z]{2,} 匹配域名后缀(如.com、.org等),至少两个字符。
- $ 匹配输入字符串的结束位置。
2. **匹配手机号码(以中国为例)**:
^1[3-9]\d{9}$ - ^ 匹配输入字符串的开始位置。
- 1 字面量数字 "1"。
- [3-9] 匹配3到9之间的任一数字。(这假定手机号码第二位为3-9之间的数字)
- \d{9} 匹配任意数字,连续9次。
- $ 匹配输入字符串的结束位置。
3. **查找HTML标签**:
<([a-z]+)([^<]+)*(?:>(.*)<\/\1>| *\/>) - < 开始的字面小于号。
- ([a-z]+) 匹配并捕获一次或多次的小写字母(即标签名)。
- ([^<]+)* 匹配除了小于号之外的任意字符,零次或多次。
- (?: ... ) 是一个非捕获分组。
- > 字面量大于号,结束标签的开始部分。
- (.*) 匹配并捕获任意字符,零次或多次,直到闭标签前。
- </\1> 中 \1 引用第一个捕获组,匹配相同的标签名。
- | 表示或操作符,匹配前面或后面的表达式。
- *\/> 匹配自闭合标签的结尾。
4. **匹配IPv4地址**:
^(\d{1,3}\.){3}\d{1,3}$ - ^ 匹配输入字符串的开始位置。
- (\d{1,3}\.){3} 单个数字字符重复1到3次,跟着点,这个模式重复3次(对应前三个数字及点)。
- \d{1,3} 匹配1至3位数的数字字符。
- $ 匹配输入字符串的结束位置。
5. **简单密码强度校验**:
^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$ - ^ 匹配输入字符串的开始位置。
- (?=.*[A-Za-z]) 前向断言,确保至少存在一个字母。
- (?=.*\d) 前向断言,确保至少存在一个数字。
- [A-Za-z\d]{8,} 匹配8个或更多的字母或数字。
- $ 匹配输入字符串的结束位置。
每个用例都是根据具体需求制定的,可能会因应用的上下文和要求不同而有所变化。在使用这些正则表达式时,需谨慎考虑边界情况和特定语言实现的细微差别,并应在实际环境中进行充分测试。
相关链接:
正则表达式_百度百科 (baidu.com)