前言
之前为了准备面试,收集整理了一些面试题。
本篇文章更新时间2023年12月27日。
最新的内容可以看我的原文:https://www.yuque.com/wfzx/ninzck/cbf0cxkrr6s1kniv
并发
进程与线程的区别
- 线程属于进程,进程可以拥有多个线程。
- 进程独享内存,线程之间共享进程的内存。
- 进程是资源分配调度的最小单位,线程是CPU调度的最小单位。
- 进程的创建、销毁(如分配、销毁内存、I/O设备等)以及上下文切换的开销更大。
- 同一进程中,多线程之间的通信可以通过相同的空间地址,方便的通信。
- 进程编程调试简单可靠,但是创建销毁开销大;线程开销小,但是编程调试相对复杂。
- 进程间不会相互影响;线程挂掉可导致进程挂掉。
- 进程适应于多核多机分布;线程适合用于多核。
单核 CPU 上运行多个线程效率一定会高吗?
取决于任务类型:IO密集型还是CPU密集型。
说说线程的生命周期和状态?
初始New、就绪Ready、运行Runnable、等待Waiting、有限等待Timed_Waiting、阻塞Blocked、终止Terminated。
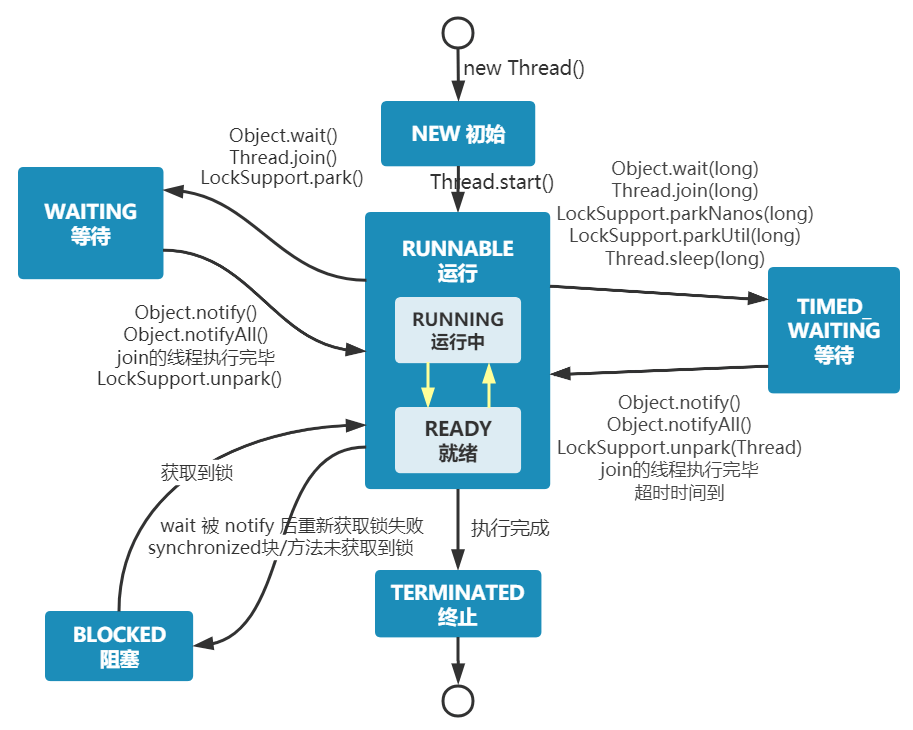
为什么JVM不区分Runnable、Ready两种状态?
JVM层面,只看到Runnable状态。这是因为:
多任务操作系统通常用“时间分片”方式进行抢占式轮转调用。
时间片通常很小,线程用完时间片之后马上放回调度队列末尾, 由于时间片小、线程切换得快,所以区分这两种状态没有意义。
什么是上下文?
线程是CPU资源调度的基本单位,CPU的执行需要线程的状态数据,比如寄存器信息、程序计数器等,这些信息称为上下文信息。
程序计数器:存储了指令的内存地址。
指令寄存器(寄存器的一种):存储了将要执行的指令(指令来自程序计数器中内存地址指向的值),CPU会对指令进行分析,交由对应的目标(逻辑运算单元或控制单元)去执行;
什么是上下文切换?
CPU在处理新任务前,将上下文信息存储到系统内核,并加载新任务的上下文到寄存器和程序计数器。
上下文切换的原因?
● 进程结束;
● 时间片耗尽;
● 进程所需资源没有得到满足时被挂起;
● 让优先级更高的进程先执行时,被挂起;
● 硬件中断程序。
为什么频繁的上下文切换会影响性能?
上下文的保存、恢复由CPU处理,相对于CPU的处理速度来说,上下文切换操作是比较耗时的。
创建线程的方式
- 继承 Thread 类;
- 实现 Runnable 接口;
- 实现 Callbale 接口。
Java 中用到的线程调度算法是什么?
分时调度模型和抢占式调度模型。
请你说一说synchronized和volatile的原理与区别
volatile原理
原理是依靠计算机的基本屏障指令来实现。
synchronized原理
通过获取屏障、释放屏障包装线程安全。
区别
volatile常被称为轻量级锁,跟synchronized相比,volate只能保证变量单个操作的原子性,不具备排他性,也不会引起上下文切换。
什么是死锁?
产生死锁要满足四个必要条件:请求保持、互斥性、不可剥夺、循环等待。
如何避免死锁?
破坏除互斥性之外的死锁条件。
- 请求保持:可以一次性申请所有资源;
- 不可剥夺:当申请不够资源时,可以主动释放占有的资源;
- 循环等待:设置合理的顺序预防。
sleep() 方法和 wait() 方法对比
都可以暂停线程。
区别:sleep不释放锁;wait需要通过notify唤醒线程;sleep是Thread的静态方法、wait是Object的方法。
什么是JMM?
是java语言规范的一部分,定义了final、volate、synchronized关键字的行为,确保做了同步的java代码正确运行在不同架构的处理器上。
对于开发人员来说,它为我们解答了三个问题:
- 原子性问题:规定了除long、double以外的基本数据类型、引用类型的读、写操作具有原子性;规定被volate修饰的long、double共享变量具有原子性。
- 可见性、有序性方面:它通过happens-before来解答。
什么是happens-before规则?
JMM定义了一些动作,如锁的申请、释放,变量读、写,Thread.join等,如果动作A和动作B具有 happens-before 关系,称 A happens-before B,JMM会保证A的结果对B可见,并且是有序的。
其中一条关于volate变量的规则:对volatile变量的写操作 happens-before 后续的针对该变量的读操作。注意的是,要有时间上的先后顺序。
volate如何保证变量的可见性?
禁用CPU高速缓存,线程对此共享变量的操作是在主存进行,而不是在线程私有的数据副本。
volate如何 保证变量的有序性/禁止重排序?
基于内存屏障保证。
一般来说,处理器支持那种内存重排序,就会提供相应的禁止重排序的指令,比如说LoadLoad
sleep(0)的意义
本质上是触发系统重新进行一次CPU竞争。因为在CPU竞争采用抢占式的系统中,线程需要进行抢占CPU资源,抢到之后会霸占CPU。
其它方面,可以埋入一个安全点,让GC线程进行工作。
如果“可数循环”for(int)太长,需要等循环结束,才达到安全点,这会推迟GC回收工作。
Java 6 之后synchronized的优化
自旋锁、适应性自旋锁、锁消除、锁粗化、轻量级锁。
synchronized 底层原理
通过监视器保证线程安全。在代码块前后插入监视器,线程要获取监视器的持有权才能
synchronized锁升级过程
- 无锁状态 - 没有线程获取锁,synchronized块直接进入。
- 偏向锁 - 锁偏向于第一个获得它的线程,如果线程没有改变则不需要撤销偏向。
- 轻量级锁 - 如果有另一个线程试图获得偏向锁,则会膨胀为轻量级锁,会有点 CAS 操作。
- 重量级锁 - 当竞争加剧,CAS操作无法 resolved 时,会进一步升级为重量级锁,会进入互斥区,性能降低。
- 批量重入锁 - 如果一个线程多次进入同步块,可以使用批量重入避免多次加锁。
synchronized锁降级过程
synchronized 和 volatile 有什么区别?
性能上volate更好,对原子性的保证有些差别,volate只保证单个共享变量读写操作的原子性,如i=1。synchronized可以保证多个操作的原子性。
ReentrantReadWriteLock 适合什么场景?
需要线程安全、读多写少的场景。
线程持有读锁还能获取写锁吗?
不能。反之可以,即持有写锁可以获取读锁。
ThreadLocal 有什么用?
每个线程多有自己的本地变量,避免了多线程操作共享变量,从而避免了线程安全问题。
ThreadLocal 原理了解吗?
ThreadLocal内部有一个静态类ThreadLocalMap,这个类是基于数组实现的hash表,数组元素继承了弱引用类,元素中包含key和value,其中key是弱引用。
每个Thread都拥有一个独立的ThreadLocalMap实例,这样就达到了封闭的效果。
ThreadLocal中Map的key为什么要使用弱引用?
key引用指向的是ThreadLocal,使用弱引用可以保证线程销毁的时候,ThreadLocal能及时被回收。
ThreadLocal为什么需要手动回收value?
如果线程一直运行,那么就一直持有ThreadLocalMap的实例的强引用,导致指向value的引用链也是强引用,这样GC线程无法回收。
ThreadLocal 内存泄露问题是怎么导致的?
假如线程一直运行,那么对value的引用是强引用,不会被回收,而ThreadLocal是弱引用,可以回收。
为什么使用线程池?
创建线程是比较重的操作,频繁的创建、销毁影响性能;
实现线程池可以实现资源隔离,达到一定程度的流量控制效果;
同时,由线程池维护线程,降低自己维护线程出错概率
线程池核心参数?
核心线程数、最大线程数、阻塞队列、拒绝策略、线程的存活时间、线程工厂;
拒绝策略有哪些?
直接抛出异、用调用线程执行当前任务、直接丢弃当前任务、丢去最早未处理的。
线程池处理任务流程?
大概流程:首先如果工作线程数小于核心线程数,那么就创建一个新线程并执行任务,否则,加入到阻塞队列,假设这个是有界的,当队列满了之后,就会判断是否达到最大线程数限制,没有达到的话,就创建一个线程并执行任务;如果达到最大线程数的限制,那么就触发拒绝策略。
public void execute(Runnable command) {if (command == null)throw new NullPointerException();/** Proceed in 3 steps:** 1. If fewer than corePoolSize threads are running, try to* start a new thread with the given command as its first* task. The call to addWorker atomically checks runState and* workerCount, and so prevents false alarms that would add* threads when it shouldn't, by returning false.** 2. If a task can be successfully queued, then we still need* to double-check whether we should have added a thread* (because existing ones died since last checking) or that* the pool shut down since entry into this method. So we* recheck state and if necessary roll back the enqueuing if* stopped, or start a new thread if there are none.** 3. If we cannot queue task, then we try to add a new* thread. If it fails, we know we are shut down or saturated* and so reject the task.*/int c = ctl.get();if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}else if (!addWorker(command, false))reject(command);}
设置多少线程数比较合适?
基于任务类型来判断。
CPU密集型的话,线程数可以设置得跟核数一样多。
IO密集型的话,考虑到可能经常阻塞,可以设置为核数得两倍。
AQS 是什么?
抽象队列同步器,是一个抽象类,可以用来构建锁和同步器。
AQS 原理是什么?
AQS的思想是我们有一定量的共享资源,当线程获取到足够的共享资源时,可以执行任务,否则就插入到队列。
内部核心组成包括 一个虚拟的双休队列CLH以及一个被volate修饰的state变量。
以可重入锁为例子,申请到资源的时候,state + 1,重入的时候继续+1,当state=0的时候,其它线程才能申请到这个锁。
Semaphore 的原理是什么?
基于AQS实现的一个共享锁。其思想是将适量的共享资源放入state变量,线程的执行需要申请到足够的资源才能执行。
用过 CountDownLatch 么?什么场景下用的?
将线程阻塞在一个地方,直到所有线程的任务执行完毕。
比如进行文件读取。
CountDownLatch有没有可以改进的地方呢?
结合CompletableFuture 使用。
JVM面试题
讲一下垃圾回收机制
在Java中,程序员不需要显式的去释放一个对象的内存,JVM会自动释放。
JVM中,有一类线程是垃圾回收线程,当堆内存不足的时候,会执行扫描、回收工作。
class加载机制
类是由类加载器及其子类实现。
类的声明周期包括:加载、连接、初始化、使用、卸载。
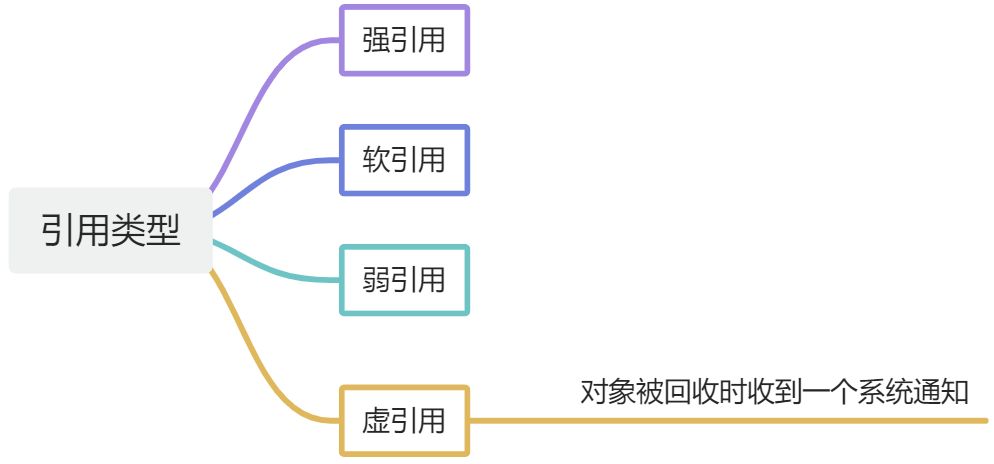
对象是否存活?

引用类型
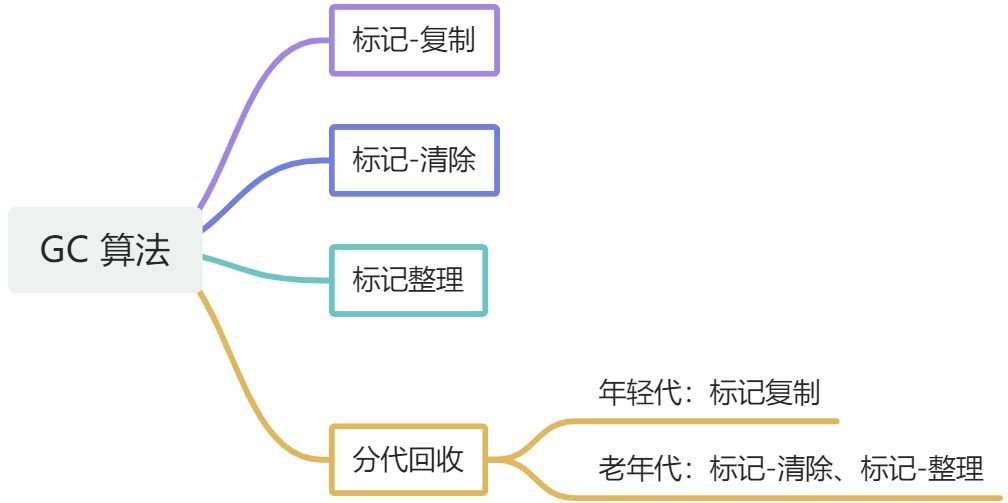
垃圾回收算法
内存分配策略

Full GC触发条件

程序计数器是什么?
一个行号指示器,用于标识下一条要执行的命令的位置。
Java 虚拟机栈的作用?
线程调用方法进行入栈操作,相关信息被封装到栈帧中,包括本地变量表、动态连接、方法出口、操作栈等信息;当方法执行完成,就进行一个出栈操作。
堆的作用是什么?
存放对象的实例。
方法区的作用是什么?
存放被虚拟机加载的类型信息、静态变量、常量、即时编译器编译后的代码缓存等数据。
运行时常量池的作用是什么?
存放字面量和符号引用。
直接内存是什么?
不属于运行时内存区域,不受JVM管理,不受JVM堆大小的限制。
直接内存导致的溢出一个明显的特征就是堆快照文件明显看不出异常,快照文件很小,而程序直接、间接使用了直接内存(如NIO),那么就可以考虑检查直接内存。