井盖、店杆、光交箱、通信箱、标石等为城市中常见部件,在方便居民生活的同时,因为后期维护的不及时往往会出现一些“井盖吃人”、“线杆、电杆、线缆伤人”事件。造成这类问题的原因是客观的多方面的,这也是城市化进程不断发展进步的过程中难以完全避免的问题,相信随着城市化的发展完善相应的问题会得到妥善解决。本文的核心目的并不是要来深度分析此类问题形成的深度原因等,而是考虑如何从技术的角度来助力此类问题的解决,这里我们的核心思想是想要基于实况的数据集来开发构建自动化的检测识别模型,对于摄像头所能覆盖的视角内存在的对应设施部件进行关注计算,后期,在业务应用层面可以考虑设定合理的规则和预警逻辑,结合AI的自动检测识别能力来对可能出现的损坏、倒塌、折断等问题进行及时的预警,通知到相关的工程技术人员来进行维护处理,在源头端尽可能地降低可能的损害,感觉这是一个不错的技术与实际生活场景相结合的落地点。
在前文中我们已经进行了相关的项目开发实践,感兴趣的话可以自行移步阅读:
《助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于DETR(DEtection TRansformer)开发构建生活场景下城市部件检测识别系统》
《助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv3开发构建生活场景下城市部件检测识别系统》
《助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv4开发构建生活场景下城市部件检测识别系统》
《助力城市部件[标石/电杆/光交箱/人井]精细化管理,基于YOLOv5全系列模型【n/s/m/l/x】开发构建生活场景下城市部件检测识别系统》
本文主要是选择YOLOv6来开发实现检测模型,首先看下实例效果:
Yolov6是美团开发的轻量级检测算法,截至目前为止该算法已经迭代到了4.0版本,每一个版本都包含了当时最优秀的检测技巧和最最先进的技术,YOLOv6的Backbone不再使用Cspdarknet,而是转为比Rep更高效的EfficientRep;它的Neck也是基于Rep和PAN搭建了Rep-PAN;而Head则和YOLOX一样,进行了解耦,并且加入了更为高效的结构。YOLOv6也是沿用anchor-free的方式,抛弃了以前基于anchor的方法。除了模型的结构之外,它的数据增强和YOLOv5的保持一致;而标签分配上则是和YOLOX一样,采用了simOTA;并且引入了新的边框回归损失:SIOU。
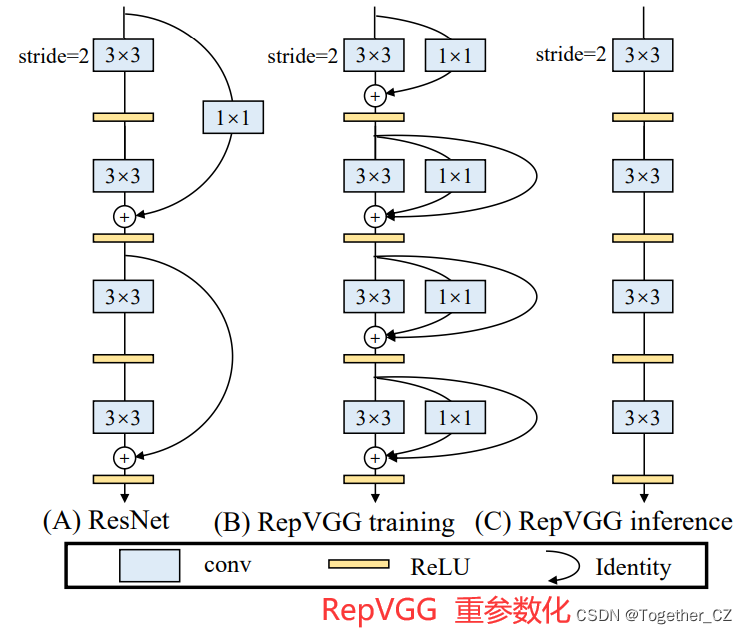
YOLOv5和YOLOX都是采用多分支的残差结构CSPNet,但是这种结构对于硬件来说并不是很友好。所以为了更加适应GPU设备,在backbone上就引入了ReVGG的结构,并且基于硬件又进行了改良,提出了效率更高的EfficientRep。RepVGG为每一个3×3的卷积添加平行了一个1x1的卷积分支和恒等映射的分支。这种结构就构成了构成一个RepVGG Block。和ResNet不同的是,RepVGG是每一层都添加这种结构,而ResNet是每隔两层或者三层才添加。RepVGG介绍称,通过融合而成的3x3卷积结构,对计算密集型的硬件设备很友好。
简单看下实例数据情况:

训练数据配置文件如下所示:
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR
train: ./dataset/images/train # train images
val: ./dataset/images/test # val images
test: ./dataset/images/test # test images (optional)# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False# Classes
nc: 4 # number of classes# class names
names: ['biaoshi', 'diangan', 'guangjiaoxiang', 'renjing']默认我先选择的是yolov6n系列的模型,基于finetune来进行模型的开发:
# YOLOv6s model
model = dict(type='YOLOv6n',pretrained='weights/yolov6n.pt',depth_multiple=0.33,width_multiple=0.25,backbone=dict(type='EfficientRep',num_repeats=[1, 6, 12, 18, 6],out_channels=[64, 128, 256, 512, 1024],fuse_P2=True,cspsppf=True,),neck=dict(type='RepBiFPANNeck',num_repeats=[12, 12, 12, 12],out_channels=[256, 128, 128, 256, 256, 512],),head=dict(type='EffiDeHead',in_channels=[128, 256, 512],num_layers=3,begin_indices=24,anchors=3,anchors_init=[[10,13, 19,19, 33,23],[30,61, 59,59, 59,119],[116,90, 185,185, 373,326]],out_indices=[17, 20, 23],strides=[8, 16, 32],atss_warmup_epoch=0,iou_type='siou',use_dfl=False, # set to True if you want to further train with distillationreg_max=0, # set to 16 if you want to further train with distillationdistill_weight={'class': 1.0,'dfl': 1.0,},)
)solver = dict(optim='SGD',lr_scheduler='Cosine',lr0=0.0032,lrf=0.12,momentum=0.843,weight_decay=0.00036,warmup_epochs=2.0,warmup_momentum=0.5,warmup_bias_lr=0.05
)data_aug = dict(hsv_h=0.0138,hsv_s=0.664,hsv_v=0.464,degrees=0.373,translate=0.245,scale=0.898,shear=0.602,flipud=0.00856,fliplr=0.5,mosaic=1.0,mixup=0.243,
)
终端执行:
python3 tools/train.py --batch-size 8 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2即可启动训练,当然了如果想要训练其他系列的模型也可以,参照命令如下:
#yolov6n
python3 tools/train.py --batch-size 8 --conf configs/yolov6n_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6n --epochs 100 --workers 2#yolov6s
python3 tools/train.py --batch-size 16 --conf configs/yolov6s_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6s --epochs 100 --workers 2#yolov6m
python3 tools/train.py --batch-size 16 --conf configs/yolov6m_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6m --epochs 100 --workers 2#yolov6l
python3 tools/train.py --batch-size 8 --conf configs/yolov6l_finetune.py --data data/self.yaml --fuse_ab --device 0 --name yolov6l --epochs 100 --workers 2
日志输出如下所示:
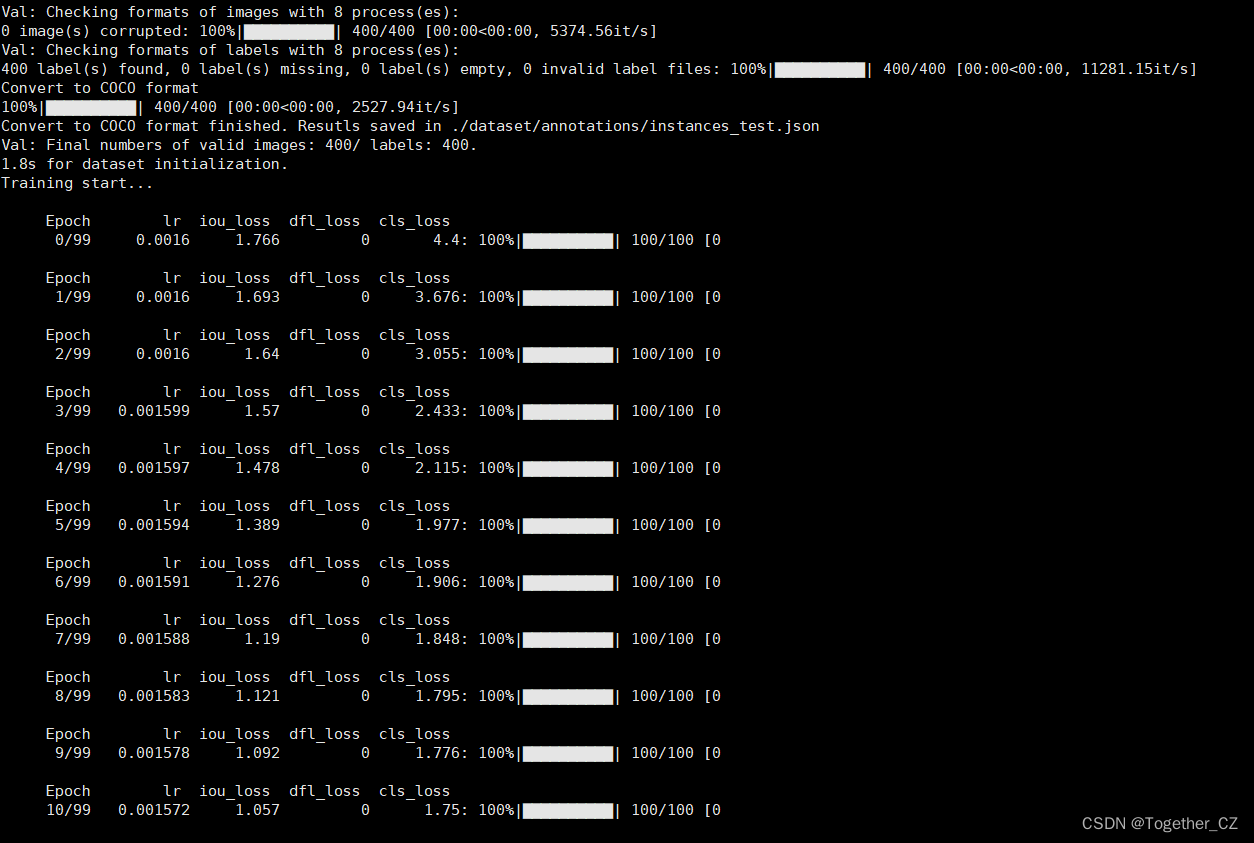
训练完成输出如下:
Inferencing model in train datasets.: 100%|█████| 13/13 [00:07<00:00, 1.70it/s]Evaluating speed.Evaluating mAP by pycocotools.
Saving runs/train/yolov6n/predictions.json...
Results saved to runs/train/yolov6n
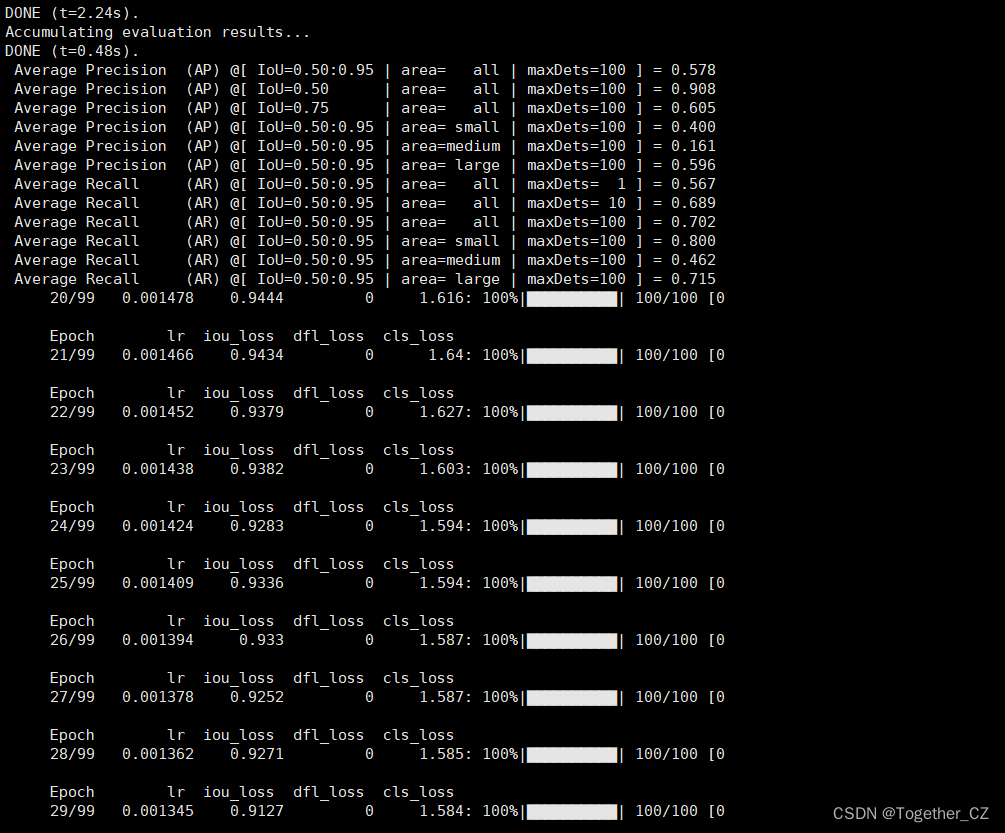
Epoch: 98 | mAP@0.5: 0.9564649861258367 | mAP@0.50:0.95: 0.6238790353332472Epoch lr iou_loss dfl_loss cls_loss
loading annotations into memory...
Done (t=0.11s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.04s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=1.10s).
Accumulating evaluation results...
DONE (t=0.23s).Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.624Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.956Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.658Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.800Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.221Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.639Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.599Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.707Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.716Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.800Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.478Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.728离线推理实例如下:




在实际应用开发的时候可以考虑如何更好地基于目标检测模型的检测计算结果来产生业务上的有效事件,这里大都是需要结合业务需求来设定合理有效的规则和预警逻辑的,这里暂时不是本文的重点,感兴趣的话都可以自行动手尝试下!