文章目录
- 错误原因
- 解决问题
错误原因
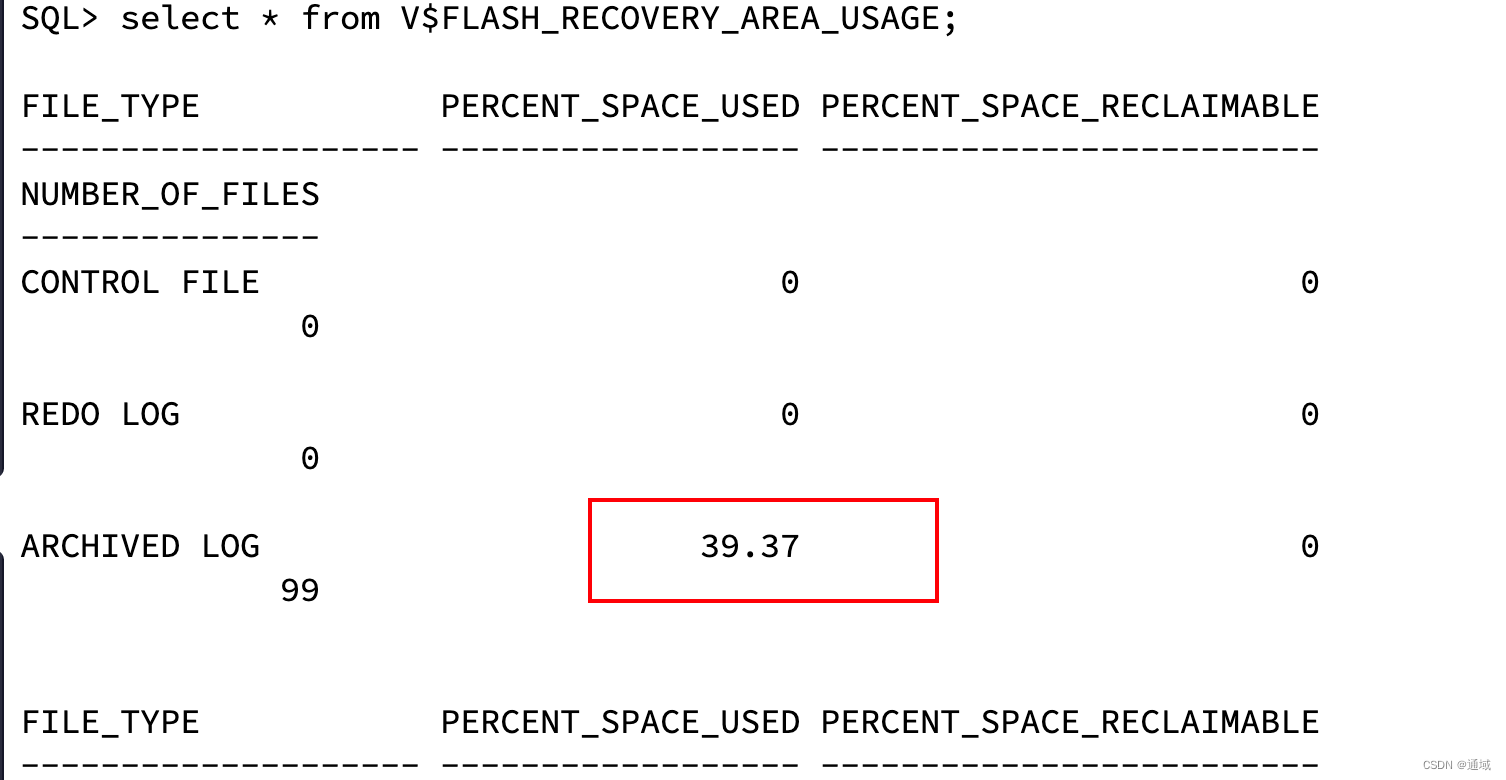
出现错误cuDNN error: CUDNN_STATUS_INTERNAL_ERROR,从这个名字就可以看出,出错原因其实有可能有很多种,我这里说一种比较常见的,就是:显存不足。
一个困惑点在于,在我们的印象中,显存不足不是报另外一个错吗?RuntimeError: CUDA Out of memory。事实上,后者是运行时错误,一般通过降低batch size, 向量维度,神经网络层数可以解决。
前者报错我的理解是当使用CUDA的时候Pytorch内部有一个初始化,默认运行在第0块GPU(即使模型被指定运行在其他GPU),然后显存不足指的是在初始化的时候显存不足,也就是第0块GPU显存不足以支撑初始化了,一般初始化其实并不消耗多少显存,比模型运行时一般小多了,那为什么还会报错呢?一般是因为第0块GPU被别的童鞋占用了。我的情况如下:gpu0被别人使用了24059MB,然后一共只有24268MB,所以初始化失败,就会报上述错误。

解决问题
我们其实就是要解决Pytorch指定了gpu但还是会占用了一点0号gpu(初始化默认会在0上面)。解决办法如下:
假设我们指定模型要全部运行在5号gpu上(包括初始化也要在5号上)。
import os
import torch
os.environ['CUDA_VISIBLE_DEVICES'] = "5"
device=torch.device("cuda:{}".format(0))
第一行代码:将5号gpu设置为可见,此时其他gpu全部无法再见到。
第二行代码:仅有5号gpu可见,此时gpu编号会改变,5号gpu会变成0号gpu,所以指定0号gpu,其实就是指定原来的5号gpu。
作为对比,平常我们大多数人其实是下面这样运行的
import os
import torch
device=torch.device("cuda:5")