本文主要介绍SAP中的表缓存在查询数据,更新数据时的工作情况以及对应概念。
SAP表缓存的工作
查询数据
更新数据
删除数据
表缓存的概念
表缓存技术设置属性
不允许缓冲:
允许缓冲,但已关闭:
缓冲已激活:
已缓冲单个记录
通用区域缓冲:
完全缓冲:
OPEN SQL不使用缓冲区的情
SAP表缓存的工作
查询数据
激活ST05并执行如下OPEN SQL查询语句(新建表,无数据)

缓冲监视器中出现一条记录(即使数据不存在,也会将对应键记录,下一次获取不存在的记录会更快)



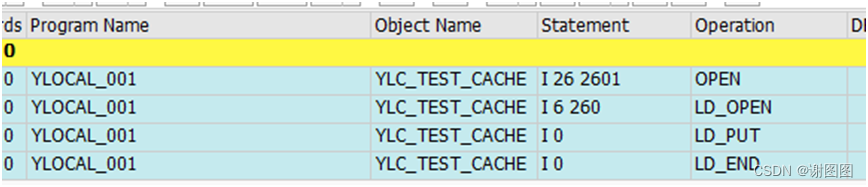

第一次执行OPEN SQL 时是做了三步操作
第二步:缓存中无该查询数据的记录,查询数据库该表当前client所有记录(表设置为通用区域缓冲,通用键值为client)并更新缓冲区(无数据,仍然记录键值,以备下一次查询)
更新数据
激活ST05并执行如下OEPN SQL更新语句


ST05跟踪记录(PS:这就是为什么modify比insert慢的原因)


更新数据库数据,并更新缓冲区


数据更新后五次的数据库访问将不经过缓存,第六次访问优先读取缓冲区,符合前述测试场景。
删除数据
激活ST05并执行如下OPEN SQL删除语句(被删除数据本身不存在)

缓冲监视器中记录无更新,ST05跟踪无缓冲更新记录,不影响后续执行查询语句的缓冲访问

激活ST05并执行如下OPEN SQL删除语句(被删除数据存在)


ST05跟踪记录中有缓冲失效记录

PS: 上述所有操作均基于OPEN SQL,多台服务器实例还涉及缓冲区同步,如下截图

表缓存的概念
SAP缓冲发生在每个应用程序服务器的共享内存中。SAP缓冲区由一个中央管理结构、一个按字母顺序排列的表目录和一个数据区组成。一般缓冲表或数据库视图的各个区域作为单独的完全缓冲表进行管理。缓冲的数据作为内部表保存在数据区域中。数据区域使用SAP内存管理进行管理。
当使用Open SQL访问缓冲表或视图时,首先在表目录中搜索表的名称,然后对数据进行二进制搜索。
在单记录缓冲和通用缓冲中,也会保存表或视图中不存在的行的信息。第一次读取不存在的行时,主键或泛型键的键值将加载到具有(否则为空)行和适当标志的相关数据区域中。下次尝试读取此行时,缓冲区已指示此行不存在。
单记录缓冲区的管理不如通用缓冲区或全缓冲区有效。在单记录缓冲中,行被逐个加载到数据区的内部表中。在通用缓冲和完全缓冲中,表或视图的所有数据都在一个步骤中加载并在数据库中排序。
缓冲区监视器是一个SAP内存管理工具(事务ST02),用于分析当前应用程序服务器的SAP缓冲区。这包括以下任务:
◾显示用于分析缓冲区有效性的表统计信息。当优化相关的配置文件参数和检测昂贵缓冲的表时,显示的值是有用的。
表缓存技术设置属性
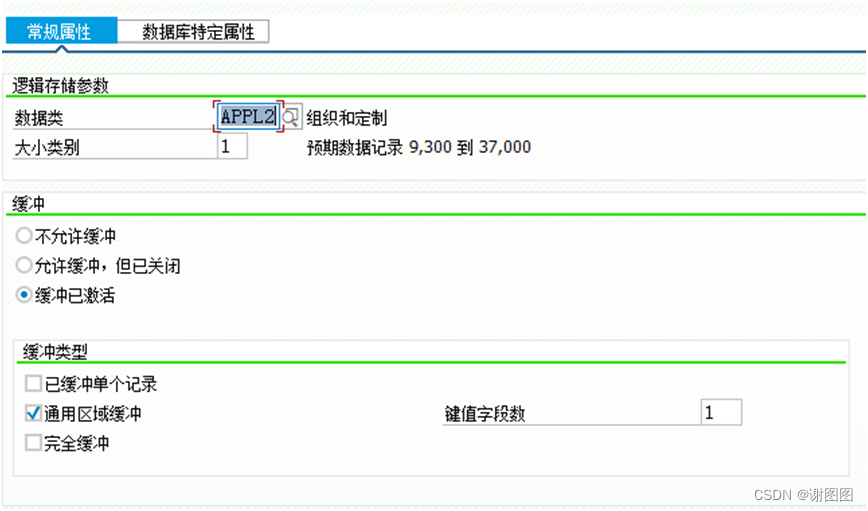
不允许缓冲:
Open SQL总是直接访问数据表的当前数据。该表在任何其他系统中也不应启用SAP缓冲。
允许缓冲,但已关闭:
交付时,该表不允许SAP缓冲,但是原则上在其它系统可以根据表的使用激活缓冲。
缓冲已激活:
该表执行缓冲,如果可能,Open SQL语句访问共享内存中的SAP缓冲而不是直接访问表。
已缓冲单个记录
只有表中那些实际被访问的行才被缓冲。与使用通用缓冲或完全缓冲相比,这需要更少的缓冲空间。另一方面,需要更多的管理工作,并且需要更直接的数据库访问。
如果WHERE子句用于访问非缓冲行,并且此子句指定使用and联接的相等条件,则会尝试加载此行。如果找不到该行,则会在缓冲区中进行记录,并使用完全指定的WHERE子句来避免在下次读取时访问新的数据库。
◾使用单记录缓冲时,任何Open SQL语句都必须尊重完整的主键,以防止它们绕过SAP缓冲。
◾对于经常读取单行的大型表,建议使用单记录缓冲。在读取许多行的较小表中,通常首选全缓冲,因为这减少了需要加载的直接数据库访问次数。
◾单记录缓冲区的使用仅由WHERE子句指定,而不使用single加法。
通用区域缓冲:
当对一行执行读取时,所有行都会加载到SAP缓冲区中,这些行与主键左对齐部分的此行相匹配。所涵盖的关键字段的数量在定义中指定,并且始终小于关键字段的总数。这些键字段合在一起就是通用键。
单独的泛型区域像独立的表或视图一样处理,它们的主键是泛型键,并且是完全缓冲的。
如果在Open SQL中使用完全指定的泛型键访问未缓冲的行,则会尝试加载该区域。如果找不到行,则会在缓冲区中记录这一点,并且下次使用完全指定的泛型键访问行时不会再次访问数据库。
◾使用通用缓冲时,任何Open SQL语句都必须考虑通用关键字,以防止它们绕过SAP缓冲。
◾如果通常只需要表或视图的某些区域,则应使用通用缓冲。这些区域不应太小,以防止创建过多的区域并使缓冲区管理过载。它们也不应该太大,以防止加载过多的数据。在某些情况下,完全缓冲也可能更有效。因此,通用关键字不能覆盖太多或太少的字段。
完全缓冲:
读取一行时,表或视图中的所有行都会加载到SAP缓冲区。缓冲的表或视图要么完全在缓冲区中,要么根本不在。在缓冲区中,缓冲的数据记录按表或视图的键进行排序。优化访问要求主键或辅助索引字段的左对齐部分尽可能大。如果不是,则以线性方式扫描缓冲区。
如果在特定于客户端的表或视图中打开了完全缓冲,则会在内部执行使用客户端列作为泛型键的泛型缓冲。
◾应在小表中使用完全缓冲,例如自定义表。在较大的表中,只有在频繁读取大量数据的情况下,完全缓冲才是值得的。应该很少对完全缓冲的表执行写入操作。
OPEN SQL不使用缓冲区的情况
SELECT 语句使用FOR UPDATE,DISTINCT,UNION,聚合表达式,JOIN连接,GROUP BY,ORDER BY
使用了关键字CLIENT SPECIFIED 但是WHERE 条件中没有client ID
WHERE条件将一列与from之后指定的数据库表或数据库视图中的另一列进行比较
访问具有单个记录缓冲的表或视图,而不指定(在WHERE条件中)主键的所有键字段的所有由AND连接的相等条件。
对一般缓冲区的访问,而不完全指定由WHERE条件中的AND连接的相等条件。
如果违反了精确指定通用区域的要求(如上所述),则在访问具有通用缓冲的表或视图时使用FOR ALL ENTRIES进行选择。FOR ALL ENTRIES之后的条件不能在多个常规区域之间产生OR关系。
WHRE条件列不是按正确顺序排列的主键的左对齐子集或者其中的列使用了DESCENDING
在使用写语句使缓冲区中的某个条目无效后,默认情况下,接下来五次本应访问该条目的读取将绕过当前应用程序服务器的缓冲区。对更改的条目执行的下一次读取会将其重新加载到缓冲区中,并删除无效项。在配置文件参数zcsa/sync_reload_c中指定了在重新加载之前绕过缓冲区的读取次数。
出于性能原因,访问缓冲的数据库表或视图时应注意使用上述添加绕过SAP缓冲区。要显式绕过SELECT语句中的SAP缓冲区,应始终使用添加的BYPASSING buffer。仅仅依靠上面添加的隐含行为是不够的。