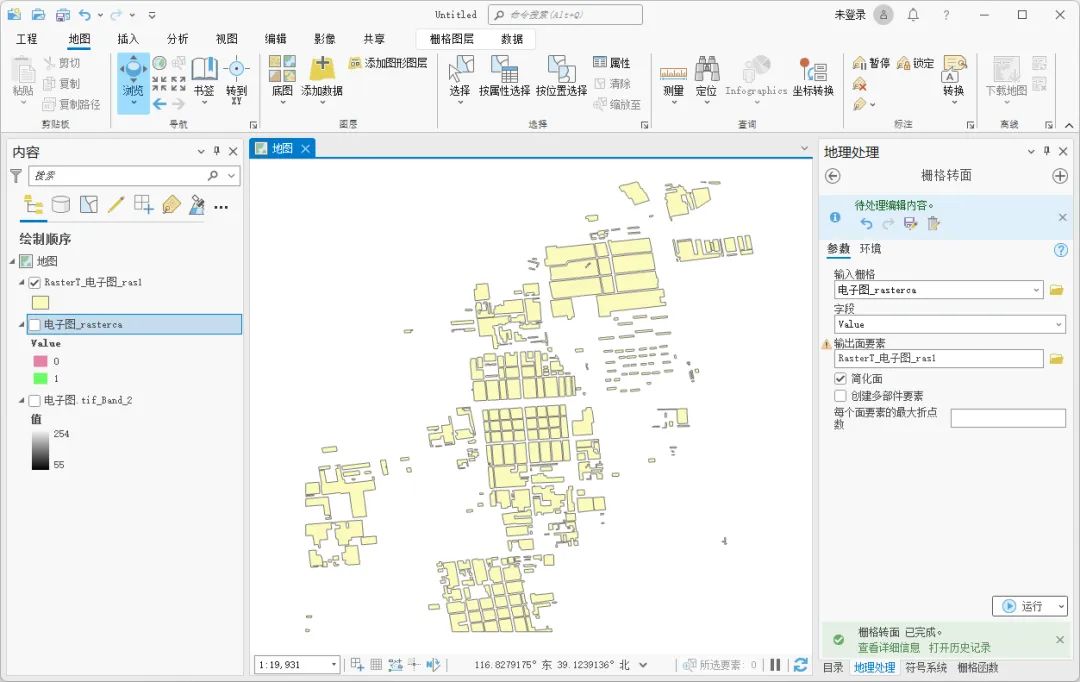
词法说明
(1)关键字
main, int, char, if, else, for, while, void
(2)运算符
= + - * / < <= > >= == !=
(3)界符
; ( ) { }
(4)标识符
ID = letter(letter|digit)*
(5)整型常数
NUM = digit digit*
(6)空格
‘ ‘ ‘\n’ ‘\r’ ‘\t’
空格用来分隔ID,NUM,运算符,界符和关键字
上下文无关文法描述
<程序> ::= main()<语句块>
<语句块> ::= ‘{’<语句串>‘}’
<语句串> ::= <语句>{;<语句>};
<语句> ::= <赋值语句> | <条件语句> | <循环语句>
<赋值语句> ::= ID=<表达式>
<条件语句> ::= if(<条件>) <语句块>
<循环语句> ::= while(<条件>) <语句块>
<条件> ::= <表达式><关系运算符><表达式>
<因子> ::= ID | NUM | (<表达式>)
<项> ::= <因子>{*<因子> | /<因子>}
<表达式> ::= <项>{+<项> | -<项>}
<关系运算符> ::= < | <= | > | >= | == | !=
单词的种别编码方案
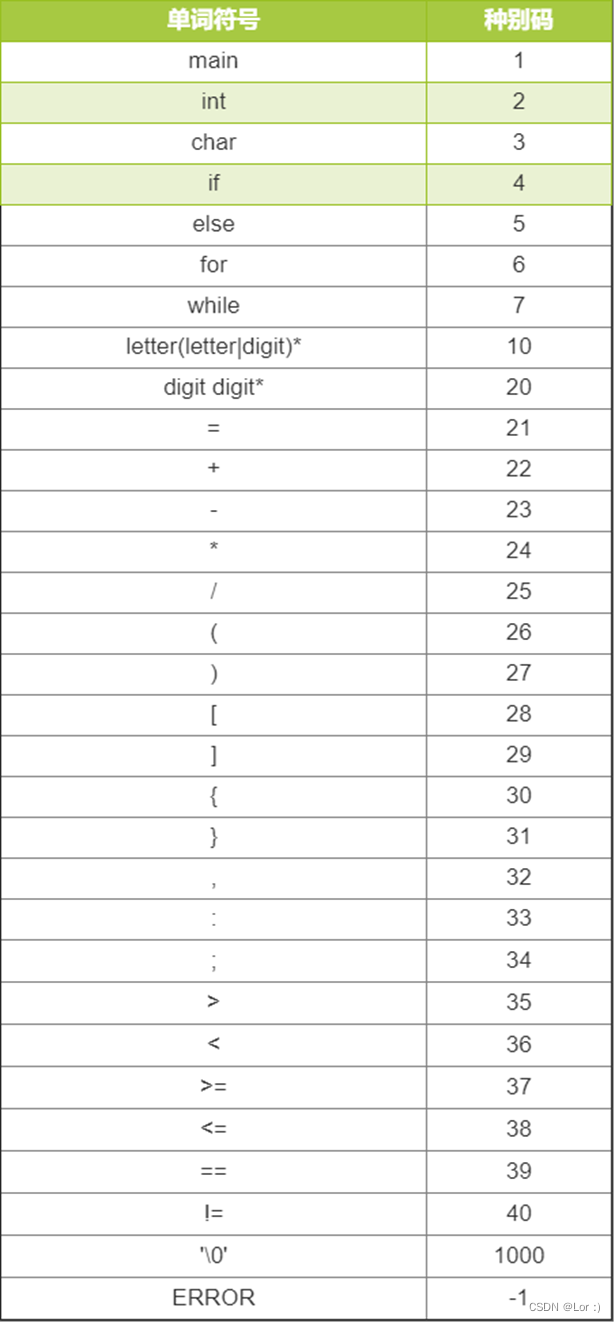
词法分析程序的主要算法思想
- 设置单词种别码
- 用正规式编写词法规则
- 根据正规式构造出识别语言单词的状态转换图
- 让状态转换图中的每一个状态对应一小段程序,根据扫描到单词符号的第一个字种类,拼出相应的单词符号
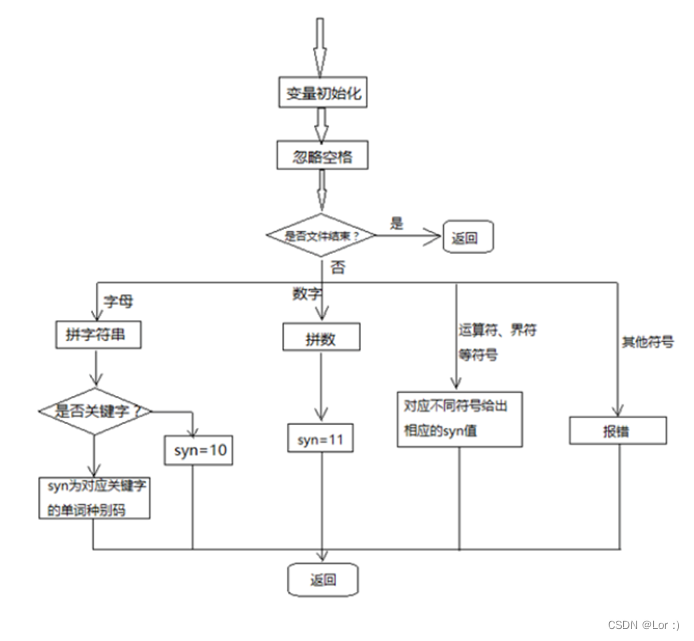
语法分析方法的算法思想的详细描述
递归下降语法分析
- 根据程序语言规则编写上下文无关文法
- 对每一个非终结符构造分析函数,根据前导符号来指导函数的选择,识别该非终结符所表示的语法成分。当该非终结符的规则有多个时,按LL(1)文法的条件能唯一地选择一个候选规则。
①遇到终结符号a时:if(当前输入符号==a)读入下一个输入符号
②遇到非终结符号A时:调用A();
③遇到规则A → ε: if(当前输入符号ϵFOLLOW(A)){ } else error()
语义分析方法的算法思想的详细描述
递归下降语法制导翻译
将语义子程序嵌入到每个递归过程中,通过递归子程序内部的局部量和参数传递语义信息。
- 每个A构造一个函数,函数的返回值为A的综合属性;出现在A的产生式中的每个符号X的每个属性都在函数中设一个局部变量;
- A的函数过程中,根据当前输入符号决定使用哪个候选式;
- 每个产生式对应的程序代码,按照从左到右的顺序,对b、B、{}分别进行:
(1)对带综合属性x的终结符b,存x的值到相应变量中;产生一个匹配b的调用,继续读入下一个输入符号。
(2)对每个B,产生一个右边带有函数调用的赋值语句c:=B(),其中c为B的综合属性对应变量。
(3)对{},把动作代码抄进分析器中,用代表属性的变量来代替对属性的每一次引用。
赋值语句翻译
在表达式分析函数和项分析函数中加入赋值语句语义分析程序,为每个子表达式和项生成四元式,在表达式分析函数中下一个读取到的符号仍然为‘+’或‘-’则生成临时变量存储计算结果并继续生成四元式,项分析函数中则读取到符号为‘*’或‘-’则继续生成四元式,算法与表达式分析函数同理。
if语句翻译
在条件语句分析函数中加入if语句翻译处理,为if语句生成两条四元式,分别为条件成立的跳转和条件不成立的跳转四元式,这里应注意通过ntc、nfc、nNXQ变量记录真链、假链和下一条语句的生成式位置,先将nNXQ通过bp()函数回填到ntc所指四元式中,再在if语句语法分析的末尾将if语句的结束位置回填到nfc所指四元式中。
while语句翻译
while语句翻译和if语句相似,但要注意while语句语法分析结束后的处理和if不同,因为while语句若条件继续成立就会继续执行,所以要在末尾多生成一个跳转四元式跳转回while的条件判断四元式。