本文主要介绍性能优化领域常见的cache的命中率问题,旨在全面的介绍提高cache命中率的方法,以供大家编写出性能友好的代码,并且可以应对性能优化领域的面试问题。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:高性能算法开发优化
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
前言
1 Cache基本原理与概念
1.1 Cache定义及作用
1.2 Cache结构与工作原理
1.3 Cache一致性问题
2 影响Cache命中率因素分析
2.1 数据访问局部性原理
2.1.1 时间局部性
2.1.2 空间局部性
2.1.3 顺序局部性
2.2 Cache容量与配置
2.2.1 Cache容量
2.2.2 Cache行大小
2.2.3 Cache替换策略
2.3 数据存储方式及策略
2.3.1 数据存储方式
2.3.2 数据预取策略
2.3.3 数据压缩与加密
3 优化数据访问模式策略
3.1 顺序访问优化方法
3.2 循环访问优化方法
3.3 分块存储和预取技术
4 提升Cache替换算法效率
4.1 常见替换算法介绍及比较
4.2 基于预测模型动态调整替换策略
4.3 实现自适应替换算法
5 多级缓存设计与应用实践
5.1 多级缓存概念及优势
5.2 多级缓存设计原则和方法
5.3 典型应用场景分析
5.3.1 Web应用性能优化
5.3.2 大数据处理场景
5.3.3 移动应用性能优化
6 监控、诊断与调优工具介绍
6.1 常用监控工具简介
6.2 问题诊断方法和步骤
6.3 调优建议和最佳实践
前言
我们都知道现代CPU的处理速度极其的快,主频不断的提高,不考虑功耗的前提下,编写的程序应该速度是无限接近CPU的处理速度的。但是,似乎我们发现程序在运行时并不能达到CPU的处理速度。这是由于数据存储在内存上,内存的处理速度很低,CPU访问内存的数据,需要耗费时间,这在性能优化领域称为内存墙。内存的存取速度与CPU的运算速度的差距导致我们不能完全发挥出CPU的高速度运算。由此我们引入了cache,一种介于CPU寄存器和内存之间的存储介质,利用程序数据的局部性原理,取数据时将一部分数据从内存取到cache,下次取数据可以直接从cache上拿,这样就避开了访存的低速度问题。当数据在cache拿不到的时候再去内存取,这里涉及到cache的命中率和缓存一致性的问题。由于cache的价格比内存高很多,我们无法给电脑配备大量的cache,因此在有限的cache下,如何让程序的运行尽可能的减少访存频次,提高cache的命中率就显得尤为重要了。这是本文命题的主要来源。
对于代码的简洁与性能问题,切记,非必要不优化,优化容易出问题,需要更高深的技术,能系统性解决的不要去过分优化代码。
1 Cache基本原理与概念
1.1 Cache定义及作用
定义:
Cache是位于CPU与主存之间的高速缓冲存储器,它用高速SRAM组成,其存取速度与CPU相当。
作用:
由于CPU的速度远高于主存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。
1.2 Cache结构与工作原理
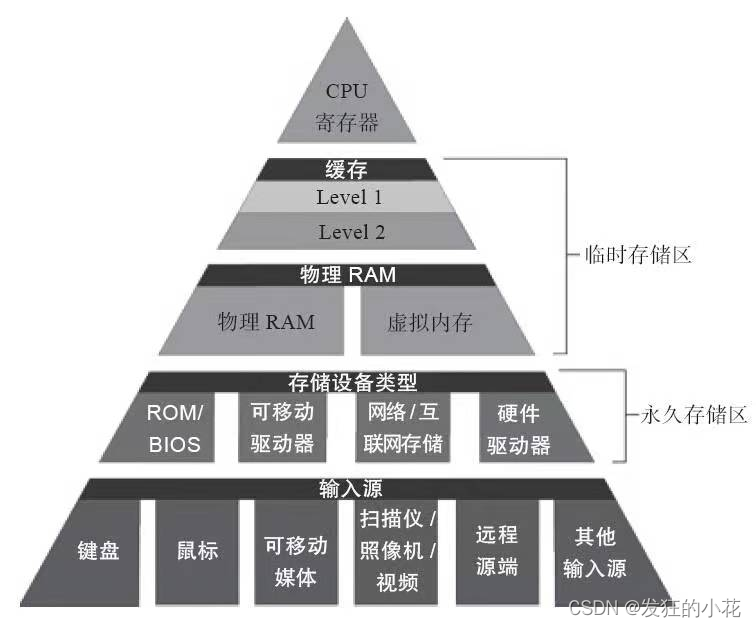
结构:
Cache通常分为L1 Cache(一级缓存)、L2 Cache(二级缓存)和L3 Cache(三级缓存),它们分别位于CPU内部、CPU外部但靠近CPU以及主存与CPU之间。三级Cache的大小L1->L2-L3逐渐增大,速度逐渐减小,价格逐渐降低。
工作原理:
当CPU要读取一个数据时,首先从L1 Cache中查找,如果没找到就从L2 Cache中查找,如果还是没找到就从L3 Cache或内存中查找。一般来说,L1 Cache的命中率最高,因为它的容量小且靠近CPU。这里涉及到几种Cache映射,后续会推出Cache设计相关的文章。
1.3 Cache一致性问题
在多处理器系统中,每个处理器都有自己的Cache,当多个处理器访问同一内存位置时,就可能出现Cache一致性问题。
为了解决Cache一致性问题,通常采用MESI协议或MOESI协议等。这些协议通过维护一个状态机来跟踪每个Cache行的状态,并根据状态机的变化来更新Cache行的数据。
Cache一致性问题一般不需要程序员自己去处理,Soc在设计时就提供了。
2 影响Cache命中率因素分析
2.1 数据访问局部性原理
2.1.1 时间局部性
近期被访问过的数据很可能在不久的将来再次被访问。
2.1.2 空间局部性
被访问数据附近的数据也有可能在不久的将来被访问。
2.1.3 顺序局部性
按照某种顺序访问的数据,后续访问也会按照相同的顺序进行。
2.2 Cache容量与配置
2.2.1 Cache容量
Cache容量越大,能够存储的数据越多,命中率越高。
2.2.2 Cache行大小
Cache行大小与数据块大小匹配时,Cache利用率最高。
2.2.3 Cache替换策略
不同的替换策略会对Cache命中率产生影响,如LRU(Least Recently Used)和LFU(Least Frequently Used)等。
2.3 数据存储方式及策略
2.3.1 数据存储方式
数据的存储方式(如按块存储、按对象存储等)会影响Cache的命中率和效率。
2.3.2 数据预取策略
通过预测未来可能被访问的数据,提前将其加载到Cache中,可以提高命中率。
2.3.3 数据压缩与加密
对数据进行压缩和加密处理,可以在有限的空间内存储更多数据,但可能会增加访问时间和处理开销。
3 优化数据访问模式策略
3.1 顺序访问优化方法
(1)空间局部性原理
将相邻的数据块存储在连续的内存空间中,利用Cache的空间局部性原理提高命中率。
(2)预取技术
通过分析数据访问模式,预测未来可能被访问的数据块,并提前将其加载到Cache中。
(3)增大Cache容量
通过增加Cache的容量,可以存储更多的数据块,从而提高命中率。但需要权衡成本和性能。
3.2 循环访问优化方法
(1)循环展开
将循环体内的操作展开,减少循环次数,从而降低Cache的失效次数。
(2)循环交换
改变循环嵌套的顺序,使得内层循环访问的数据更有可能被Cache命中。
(3)循环合并
将多个循环合并为一个循环,减少循环控制开销和Cache失效次数。
3.3 分块存储和预取技术
(1)分块存储
将数据按照一定的大小分成块,并存储在连续的内存空间中。这样可以利用Cache的空间局部性原理提高命中率。
(2)预取技术
通过分析数据访问模式,预测未来可能被访问的数据块,并提前将其加载到Cache中。预取技术可以进一步提高Cache的命中率。
(3) 多级Cache
采用多级Cache结构,使得不同级别的Cache分别存储不同粒度的数据块。这样可以充分利用各级Cache的优势,提高整体命中率。
4 提升Cache替换算法效率
4.1 常见替换算法介绍及比较
(1)LRU(Least Recently Used)算法
将最近最少使用的数据块替换出Cache,适用于数据访问具有时间局部性的场景。
(2)LFU(Least Frequently Used)…
将访问频率最低的数据块替换出Cache,适用于数据访问具有频率局部性的场景。
(3)FIFO(First In First Out)算法
按照数据块进入Cache的时间顺序进行替换,不考虑访问频率和时间局部性。
4.2 基于预测模型动态调整替换策略
(1)基于时间序列分析的预测模型
利用历史访问数据建立时间序列模型,预测未来数据访问模式,并据此调整替换策略。
(2)基于机器学习的预测模型
利用机器学习算法对历史访问数据进行训练,得到数据访问模式的分类器或回归模型,并据此动态调整替换策略。
4.3 实现自适应替换算法
(1)自适应LRU算法
结合LRU算法和访问频率信息,动态调整数据块在Cache中的位置,使得更常用的数据块能够更长时间地停留在Cache中。
(2)自适应LFU算法
在LFU算法的基础上引入时间衰减因子,使得长时间未被访问的数据块逐渐降低其访问频率,从而更容易被替换出Cache。
(3)自适应FIFO算法
对FIFO算法进行改进,当Cache空间不足时,优先替换出最早进入Cache且长时间未被访问的数据块。
5 多级缓存设计与应用实践
5.1 多级缓存概念及优势
定义:
多级缓存是指在计算机系统中采用不同层级、不同速度和容量的缓存组合,以优化数据访问性能。
优势分析:
多级缓存能够减少访问延迟,提高数据访问速度;同时减轻对后端存储系统的压力,提升系统整体性能。
5.2 多级缓存设计原则和方法
(1) 缓存一致性:
确保各级缓存中数据的一致性,避免数据不一致导致的问题。
(2)缓存容量规划:
根据业务需求合理规划各级缓存的容量,避免缓存溢出或浪费资源。
(3)访问性能优化:
优先使用快速、高效的缓存层级,减少数据访问延迟。
(4)分层设计:
将数据按照访问频率、重要性等因素进行分层存储,高频访问数据放在前端缓存,低频访问数据放在后端缓存。
(5) 缓存淘汰策略:
制定合理的缓存淘汰策略,如LRU、LFU等,以充分利用缓存空间。
(6)缓存预热与懒加载:
通过缓存预热提前加载热点数据,采用懒加载方式延迟加载非热点数据,提高缓存命中率。
5.3 典型应用场景分析
5.3.1 Web应用性能优化
在Web应用中,多级缓存可以有效缓解数据库压力,提高页面加载速度。例如,使用CDN作为第一级缓存,将静态资源缓存在离用户最近的节点上;使用Redis等内存数据库作为第二级缓存,存储热点数据和会话信息等;最后使用数据库作为持久化存储。
5.3.2 大数据处理场景
在大数据处理场景中,多级缓存可以减少对HDFS等分布式文件系统的访问次数,提高数据处理速度。例如,使用本地内存作为第一级缓存存储中间计算结果;使用分布式缓存如Redis Cluster作为第二级缓存共享数据;最终将处理结果写入HDFS等持久化存储系统。
5.3.3 移动应用性能优化
在移动应用中,多级缓存可以减少网络请求次数和响应时间,提升用户体验。例如,在客户端本地使用SQLite等轻量级数据库作为第一级缓存存储用户数据;使用服务器端的Redis等内存数据库作为第二级缓存共享数据;最终将数据持久化到MySQL等关系型数据库中。
6 监控、诊断与调优工具介绍
6.1 常用监控工具简介
Cache监控工具:
用于实时监控Cache的命中率、响应时间、缓存数据量等关键指标,帮助开发人员及时发现问题。
应用性能监控工具:
能够监控整个应用系统的性能表现,包括Cache的使用情况,从而定位性能瓶颈。
日志分析工具:
通过对系统日志的深入挖掘和分析,可以发现Cache使用的异常情况和潜在问题。
6.2 问题诊断方法和步骤
观察监控数据:
通过监控工具收集的数据,观察Cache命中率、响应时间等指标的变化趋势,初步判断是否存在问题。
分析日志信息:
利用日志分析工具,对系统日志进行挖掘和分析,找出与Cache相关的异常信息和错误记录。
重现问题场景:
尝试重现问题场景,模拟用户请求和操作,以便更深入地了解问题发生的原因和过程。
6.3 调优建议和最佳实践
调整缓存大小:
根据监控数据和业务需求,适当调整Cache的大小,以平衡命中率和资源消耗。
定期清理无效缓存:
定期清理过期或无效的缓存数据,避免占用宝贵的缓存空间,同时减少Cache失效的可能性。
合理设置缓存策略:
根据业务需求和数据特点,选择合适的缓存策略,如LRU、LFU等,以提高Cache命中率。
优化数据结构和算法:
优化数据结构和算法可以降低Cache的查找和替换时间,从而提高Cache命中率。
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!