| 博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,京东购书链接:https://item.jd.com/12677623.html,扫描左侧二维码进入京东手机购书页面。 |
1. 背景介绍
本文介绍的演练操作源于某真实案例,用户有一个接近 100 TB 的 HBase 数据库,其中有一张超大表,数据量约为数十TB,在一次迁移任务中,用户需要将该 HBase 数据库迁移到 Amazon EMR 上。 本文将讨论并演示:将一个数十TB HBase 单表不停机迁移数据到一个 HBase on S3 集群上。关于迁移后的例行灾备作业,请参考本文姊妹篇:[《HBase 例行灾备方案:快照备份与还原演练》](https://blog.csdn.net/bluishglc/article/details/135243028)
2. 知识储备
介绍详细的迁移操作前,有必要介绍一些与 HBase 相关的背景知识,这些知识对于理解迁移过程中的操作步骤至关重要,同时也是解决后文将会提及的若干错误的理论基础。HBase 数据迁移一般分为历史数据迁移和增量数据迁移两部分工作,分别使用不同的机制实现,历史数据的迁移使用 HBase Snapshot,增量数据的迁移使用 HBase Replication,下面我们详细介绍一下这两项机制。
2.1 HBase Snapshot
一个 HBase Snapshot 代表了一张 HBase 数据表在某一时刻的一份完整副本,但是,不同于习惯性的认知,在创建 Snapshot 时, HBase 并不会立即复制表数据,实际上,HBase 根本不会为创建快照复制任何数据,它只复制一份数据表的元数据并记录一份数据表当前所有HFile 的文件列表,一份 HBase Snapshot 就创建完成了。所以,create snapshot 是一个非常轻量的操作,即使是创建一张超大表的快照也可以在很短时间内完成。
HBase 之所以能用这种方式创建快照,一个非常重要的原因在于:在 HBase 中,所有的 HFile 都是 immutable 的,HFile 一旦落盘(MemStore 被持久化为 HFile),将不再更新,任何数据变更都只会记录在新的 HFile 中,(很多基于 LSM 树设计的数据库和 Hudi 等数据湖格式都是这样设计的),正是有这样一个前提作保证,HBase 的快照才只需要保存数据文件的“指针”,而不必复制一份“静态”数据出来。
不过,虽然 HFile 不会被改写,但它却可能会被删除,导致 HFile 被删除的主要原因就是 Compaction, 由于 Compaction 会定期将多个小的 HFile 合并成一个大的 HFile,合并后,原来的小文件就没有用了,为了节省空间,HBase 会把这些文件移动到 archive 文件夹下,然后一个定期执行的旧文件清理线程会在某个时刻将这些不再被使用的 HFile 彻底删除。 但是,这样会带来一个问题:之前创建好的快照会因为这些文件被删除而遭到“破坏”,为了避免这种情况发生,HBase 会跳过 archive 文件夹下那些被快照引用的 HFile。下图很好地解释了这一逻辑:
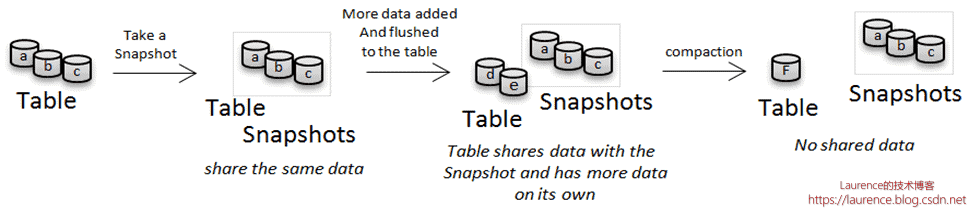
基于上述原理,在创建快照后,源端 HBase 集群的 Root Dir 上可能会看到两种情形:第一种是在创建快照后,archive 文件夹并无明显增长,甚至可能没有任何文件,第二种情况是在创建快照后,archive 文件夹的数据量会有所增长,涨幅不定,最大可以接近原表大小。导致这两种不同状况的原因取决于:在创建快照后,集群有没有执行过 Compaction,如果没有,就是第一种状况,如果有,就是第二种状况。当我们使用压测工具向 HBase 压入大量数据后,如果立即创建快照,会有很大概率引发第二种情况的发生,因为在持续写入大量数据后,Compaction 队列往往会积压大量的 Compaction 任务,如果此时创建快照,快照当时引用的 HFile 都是未进行 Compaction 前的文件,伴随着积压的 Compaction 任务被慢慢“消化”,这些文件会被逐步移动到 archive 文件夹下,由于它们都被快照所“引用”,所以不会被删除,所以最终看到的现象就是:archive 文件夹下的数据量会持续上涨。在还原快照时,HBase 也使用了对等的逻辑,快照还原出的 HFile 也是存放在 archive 文件夹下的,HBase 并不会在还原快照时复制一份数据到 data 目录(存放表数据的目录)下,而是在下次执行 Compaction 时仅将合并后的 HFile 写回到 data 目录。
2.2 HBase Replication
HBase 的 Replication 类似于关系型数据库上的 Binlong 同步,是实现 HBase 集群主从同步的主要手段。在数据库迁移场景下,它是实现增量数据同步的主要方式。由于 HBase Replication 机制是基于 WAL 日志回放实现的,而 WAL 日志通常不会全量保存,所以 Replication 机制只能用于同步近期增量数据,远期历史数据迁移还是要依靠快照完成。下图是 Replication 机制的一个示意图:

启用 Replication 后,在源端 HBase 集群的每个 RegionServer 上,会有一个 ReplicationSource 线程负责推送 WAL 日志,同时在目标端 HBase 集群的每个RegionServer 上也会启动一个 ReplicationSink 线程负责接收 WAL 日志并进行回放。ReplicationSource 会不断读取 WAL 日志中的内容(edits)并放入一个队列中,在这个过程中还能根据 Replication 的配置做一些过滤,然后通过 replicateWALEntry 这个 Rpc 调用将 edits 发送给目标集群的 RegionServer,目标集群的 ReplicationSink 线程会接收这些 edits 并转换为 put/delete 操作,以 batch 形式写入到目标集群中,从而完成 WAL 日志的回放。因为这一工作是后台线程异步进行的,所以这种 Replication 方式叫做异步 Replication,也是 HBase 默认的 Replication 工作模式。异步 Replication 有如下一些特点:
-
数据同步是 RegionServer 和 RegionServer 之间对拷的 (所以 Replication 有一个限速配置:set_peer_bandwidth,限制的也是单台 RegionServer 用于同步 WAL 日志的带宽)
-
RegionServer 会启动独立的线程异步执行 WAL 日志推送和接收
-
为了保证Region Server 和 Region Server 之间对拷数据的有序性,WAL Log 的 edits 是以队列形式按顺序推送到目标端并进行回放的
-
在目标端 edits 是以批量方式写入目标表的
3. 方案介绍
介绍了基本概念和原理后,我们看一下本次迁移给出的完整方案,方案可以简单归纳为:基于 Snapshot + Replication 进行全量快照 + 增量同步的不停机迁移方案,这是一种经典的 HBase 迁移方案,下图是方案的整体架构:
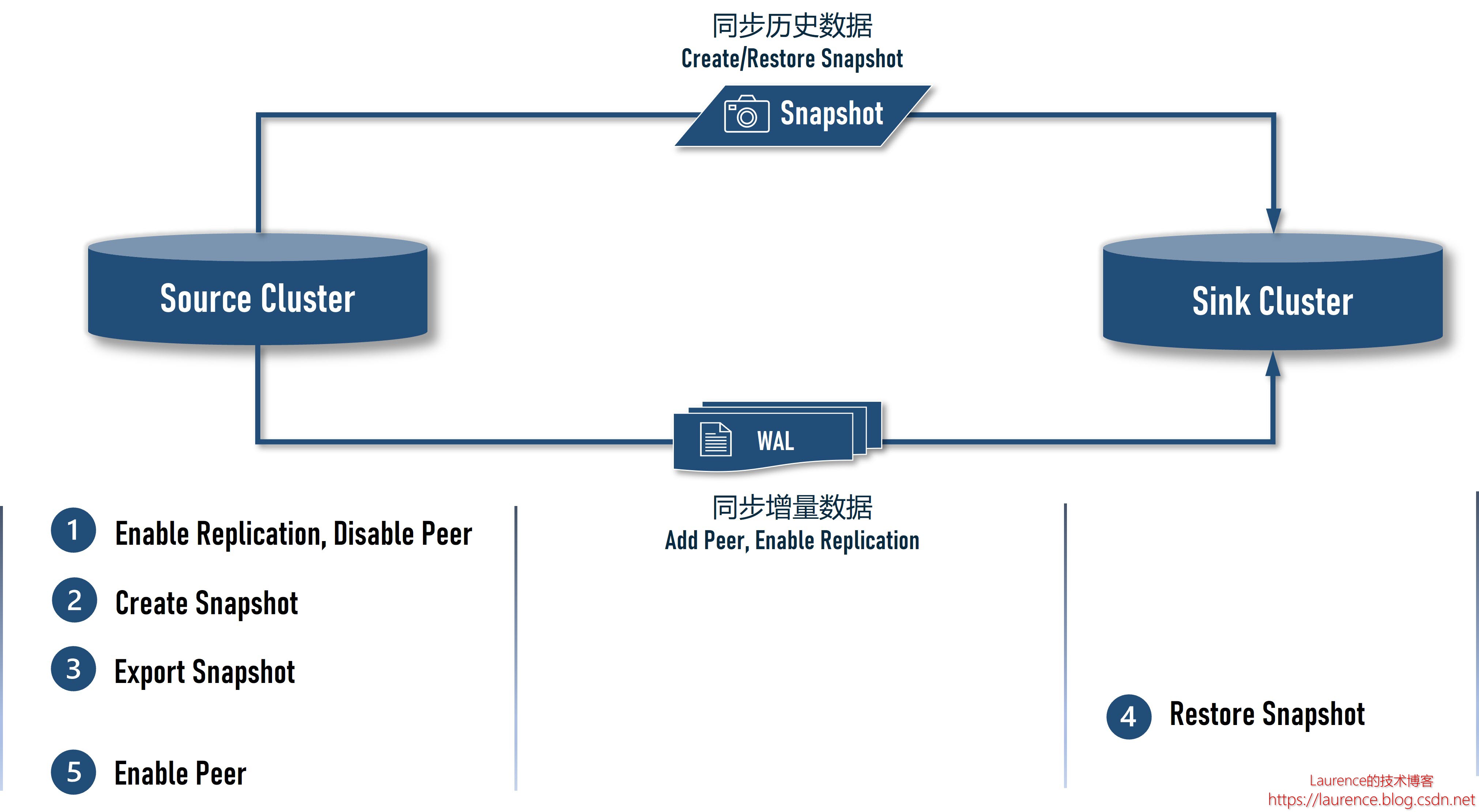
方案的核心操作如下:
- 在 Source Cluster 上将 Sink Cluster 添加为 peer,但需先 disable peer,然后再 enable 目标表的 replication,目的是让 Source Cluster 在创建前快照前先积累 WAL 日志,避免迁移过程中丢失数据
- 在 Source Cluster 上创建快照
- 在 Source Cluster 上将创建好的快照导出到 S3
- 在 Sink Cluster 上还原快照
- 在 Source Cluster 上 enable peer,恢复数据同步,直至数据追平
这5个核心操作须严格按顺序执行,如果执行顺序不当,就会丢失数据,下图从时间线上解释了 5 项操作和同步数据范围之间的关系:
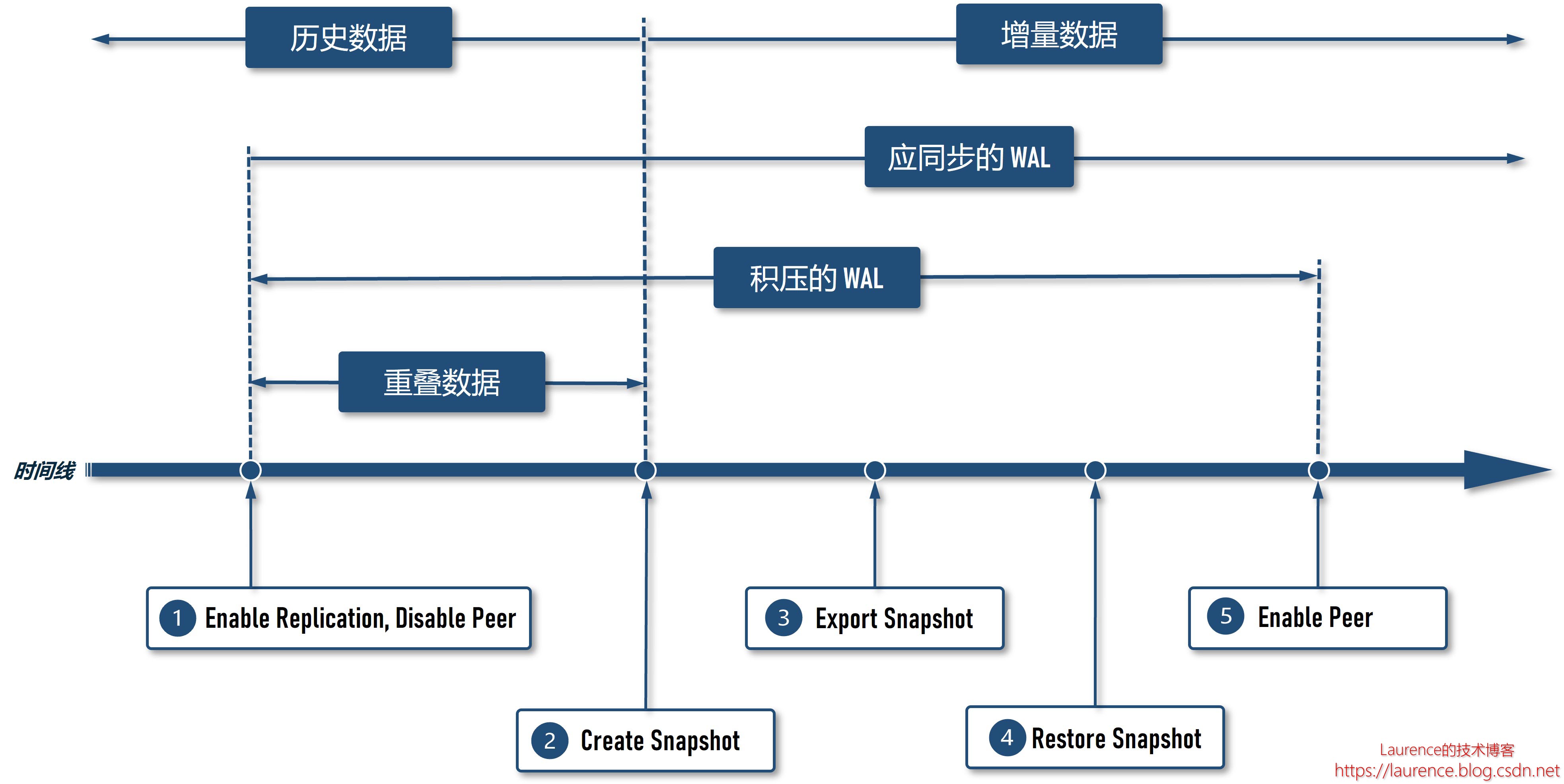
该设计方案的核心逻辑是:提前建立 replication 关系,但不 enable peer,以便让 Source Cluster 在创建快照前就开始积累 WAL 日志,然后再创建快照并在 Sink Cluster 上还原,最后再 enable peer,这期间,WAL 和 Snapshot 会有一部分“重叠数据”,正是这部分重叠数据确保了数据不会丢失,因为在不停机的情况下,我们无法在一个确切的时间点上完成数据从“写入快照”到“写入WAL日志”的“切换”(HBase 并不存在这种所谓的“切换”机制,这里只是一个比喻),因为 enable peer 和 create snapshot 是两个独立的操作,且各自都须要一定的执行时间,用户无法精准控制它们在同一时间点上同时完成,所以,为了确保不丢失数据,必须先启动 Replication,让 WAL 积累一部分“创建 Snapshot 前的数据(edits)”,这部分数据也必然会包含在后续创建的 Snapshot 中,等到后期 enable peer 后,Sink Cluster 会在快照基础上回放 WAL 日志中的这部分“重叠数据”,但这并不会产生任何副作用,基于 HBase 的数据写入特点可以推断这些回放操作不会在当前快照版本上遗留下任何变更,一旦过了 create snapshot 那个时间点,之后的 WAL 日志就是标准的增量数据了,此时就从“还原 snapshot 数据”平滑过度到了“接收 replication 数据”,实现了同步数据的“无缝接续”。
4. 环境说明
本次模拟演练使用的环境是:HBase 1.4.9 (EMR版本:5.23.0),集群节点配置是 R5.4xlarge (16 vCore,128 GB),集群规模是 3 个 Master Node + 25 个 Core Node,Source Cluster 和 Sink Cluster 保持一致配置,以下是两个集群的详细信息:
| 信息项 | Source Cluster | Sink Cluster |
|---|---|---|
| HBase 版本 | 1.4.9 | 1.4.9 |
| EMR 版本 | 5.23.0 | 5.23.0 |
| 实例机型 | R5.4xlarge | R5.4xlarge |
| 集群规模 | 3 Master Node + 25 Core Node | 3 Master Node + 25 Core Node |
| 数据量 | 50 TB | 50 TB |
| 存储介质 | HDFS (EBS) | S3 |
| 数据表 | usertable | usertable |
| Region 数量 | 9870 | 9870 |
5. 演练操作
接下来,我们就要开始演练整个迁移过程了。前文介绍了迁移的5个核心操作,但它们不是全部的操作流程,为了构建一套完整的演练环境,我们需要先创建 Source Cluster 和 Sink Cluster,并在 Source Cluster 上先压入 50 TB 历史数据,然后转为持续地增量写入,之后才是 5 个核心的迁移操作。以下与本次演练操作有关的说明和注意事项:
- 本演练的多数命令都需执行较长时间,因此,命令都使用了
nohup ... &形式转为了后台运行,以防 Linux 终端 Session 超时导致命令意外终止; - 本演练的操作必须按顺序执行,不可在前一个命令转为后台运行后,立即执行下一条命令;
- 演练过程中需要在 Source Cluster、Sink Cluster 和 AWS Console 上来回切换,为了提醒操作者,本文特意使用
[ 执行环境 ] :: ...形式的标题强调本节操作的执行环境
5.1. [ AWS Console ] :: 创建 Source Cluster
创建 EMR 集群的具体操作可以参考 AWS 的 [ 官方文档 ],本文不再赘述。本次演练使用的 R5.4xlarge 机型有 128 GB 内存,根据 EMR 的 [ 官方建议 ],分配的大数据服务的总内存(Yarn + HBase)可以设置为 120 GB,剩余的 8 GB 留给操作系统,考虑到迁移阶段 Source Cluster 需要执行快照导出和行数统计,这些都是 Map-Reduce 作业,因此,我们将一半的内存 60 GB 分配给了 Yarn,另一半 60 GB 内存分配给 HBase。以下是 Source Cluster 的 EMR 集群配置(请注意替换配置中出现的<your_aws_access_key_id> 和 <your_aws_secret_access_key>):
[{"Classification": "hdfs-site","Properties": {"dfs.replication": "1"}},{"Classification": "core-site","Properties": {"fs.s3.awsAccessKeyId": "<your_aws_access_key_id>","fs.s3.awsSecretAccessKey": "<your_aws_secret_access_key>"}},{"Classification": "yarn-site","Properties": {"yarn.nodemanager.resource.memory-mb": "61440","yarn.scheduler.maximum-allocation-mb": "61440"}},{"Classification": "hbase-env","Configurations": [{"Classification": "export","Properties": {"HBASE_MASTER_OPTS": "\"$HBASE_MASTER_OPTS -Xmx60g\"","HBASE_REGIONSERVER_OPTS": "\"$HBASE_REGIONSERVER_OPTS -Xmx60g\""}}],"Properties": {}},{"Classification": "hbase-site","Properties": {"hbase.rpc.timeout": "86400000","hbase.client.operation.timeout": "86400000","hbase.client.scanner.timeout.period": "86400000","hbase.client.sync.wait.timeout.msec": "86400000","hbase.client.procedure.future.get.timeout.msec": "86400000"}}
]
以下是关键配置项的解读:
| 配置项 | 说明 |
|---|---|
| dfs.replication | HDFS 数据副本数量,默认是 3, 此处设为 1 仅仅是为演练节省开支,实际生产应该设置为 3 |
| fs.s3.awsAccessKeyId fs.s3.awsSecretAccessKey | 让 EMR 使用 AKSK 访问 S3,这和一个 Unable to load AWS credentials 错误有关,后文会单独介绍 |
| yarn.nodemanager.resource.memory-mb | 将单个 Core 节点 (NodeManager)分配给 Yarn 的总内存设定为 60 GB |
| yarn.scheduler.maximum-allocation-mb | 将单个 Container 可分配的最大内存设定为 60 GB |
| HBASE_MASTER_OPTS | 将 HBase Master 的最大可用内存设定为 60 GB |
| HBASE_REGIONSERVER_OPTS | 将 HBase RegionServer 的最大可用内存设定为 60 GB |
| hbase.rpc.timeouth base.client.operation.timeout hbase.client.scanner.timeout.period hbase.client.sync.wait.timeout.msec hbase.client.procedure.future.get.timeout.msec | 将 HBase 各种超时上限设定为 24 小时,由于本次演练的数据量巨大,大多数操作的执行时间都超出了默认的 timeout 上限,需要特别提升上限 |
5.2. [ Source Cluster ] :: 全局变量
Source Cluster 建好后,我们需要登录 Master 节点,执行一些必要的准备工作。首先,为了让后续脚本更具可移植性,我们将所有环境相关的信息抽离出来,以变量形式统一声明和维护(请注意替换脚本中出现的 <your-hbase-sink-cluster-location>):
export SINK_CLUSTER_HBASE_ROOT_DIR="s3://<your-hbase-sink-cluster-location>"
export TABLE_NAME="usertable"
export SNAPSHOT_NAME="usertable-snapshot"
export YCSB_VERSION="0.17.0"
export HBASE_VERSION="hbase14"
export YCSB_HOME="/opt/ycsb-${HBASE_VERSION}-binding-${YCSB_VERSION}"
export YCSB_HISTORICAL_RECORD_COUNT=5242880 # history data volume: 50 TB
export YCSB_INCREMENTAL_RECORD_COUNT=524288 # incremental data volume: 5 TB
export YCSB_INCREMENTAL_RECORD_BATCH=0
export WORKER_NODES=25
export REGIN_SPLITS=$((9780-1))
export SNAPSHOT_EXPORT_MAPPERS=198
export YCSB_THREADS=$WORKER_NODES
以下是对各个变量的解释:
| 变量名 | 取值 | 说明 |
|---|---|---|
| SINK_CLUSTER_HBASE_ROOT_DIR | s3://<your-hbase-sink-cluster-location> | Sink Cluster 的 HBase Root Dir 的 S3 路径 |
| TABLE_NAME | usertable | 测试用的数据表(将使用 YCSB 压入数据) |
| SNAPSHOT_NAME | usertable-snapshot | 数据表的快照名 |
| YCSB_VERSION | 0.17.0 | 压测工具 YCSB 的版本 |
| HBASE_VERSION | hbase14 | 压测工具 YCSB 支持的 HBase 大版本号 |
| YCSB_HOME | /opt/ycsb-${HBASE_VERSION}-binding-${YCSB_VERSION} | YCSB 的安装目录 |
| YCSB_HISTORICAL_RECORD_COUNT | 5242880 | 历史数据的条数,单条记录10 MB,5242880条是 50 TB |
| YCSB_INCREMENTAL_RECORD_COUNT | 524288 | 增量数据的条数,单条记录10 MB,524288条是 5 TB |
| WORKER_NODES | 25 | 集群节点数量 |
| REGIN_SPLITS | $((9780-1)) | Region 数量,该值取自案例中的实际值 |
| SNAPSHOT_EXPORT_MAPPERS | 198 | 执行快照导出的 MR 作业的 Map Task 数量,该值应根据集群规模和MR配置决定,此处 198 为所建集群全部可用的 Map 容器数量 |
| YCSB_THREADS | $WORKER_NODES | YCSB 压测时的写入线程数,建议和节点数量对齐 |
5.3. [ Source Cluster ] :: 创建目标桶
接下来,我们为 Sink Cluster 创建一个 S3 存储桶,后面将要启动的统计脚本会定期检查这个桶的容量变化,如果你的 Source Cluster 的 IAM Role 不具备建桶权限,则需要改用 AKSK 或在 S3 控制台上完成建桶操作。
aws s3 mb $SINK_CLUSTER_HBASE_ROOT_DIR
# clean up in case the bucket is already in used, especially when re-run
nohup aws s3 rm --recursive $SINK_CLUSTER_HBASE_ROOT_DIR &> rm-root-dir.out &
tail -f rm-root-dir.out
5.4. [ Source Cluster ] :: 监控数据表目录容量
由于后续操作将在 Source Cluster 的 HDFS 和 Sink Cluster 的 S3 上写入大量数据,我们有必要监控几个关键文件夹的数据量,这对了解快照导入导出进度和剖析一些工作原理会有很大帮助:
pkill -f du-hdfs-s3
cat << EOF > /tmp/du-hdfs-s3.sh
for i in {1..1008};doecho -ne "[ \$(date +'%F %R') ]\n\n"hdfs dfs -du -h /user/hbase/dataVolume=\$(aws s3 ls --summarize --human-readable --recursive $SINK_CLUSTER_HBASE_ROOT_DIR/data/default/ | \sed -n "s/\s*Total Size:\s\(.*\)/\1/p")echo "\$dataVolume $SINK_CLUSTER_HBASE_ROOT_DIR/data/default/" archiveVolume=\$(aws s3 ls --summarize --human-readable --recursive $SINK_CLUSTER_HBASE_ROOT_DIR/archive/data/default/ | \sed -n "s/\s*Total Size:\s\(.*\)/\1/p")echo "\$archiveVolume $SINK_CLUSTER_HBASE_ROOT_DIR/archive/data/default/" sleep 600
done
EOF
nohup sh /tmp/du-hdfs-s3.sh &> du-hdfs-s3.out &
tail -f du-hdfs-s3.out
上述脚本监控了四个关键文件夹的容量变化,它们是:
| 文件夹 | 说明 |
|---|---|
/user/hbase/data/default/ | Souce Cluster 上存放 HBase 数据表的 HDFS 目录 |
/user/hbase/archive/data/default/ | Souce Cluster 上存放 HBase 归档文件的 HFDS 目录 |
s3://<your-hbase-sink-cluster-location>/data/default/ | Sink Cluster 上存放 HBase 数据表的 S3 目录 |
s3://<your-hbase-sink-cluster-location>/archive/data/default/ | Sink Cluster 上存放 HBase 归档文件的 S3 目录 |
5.5. [ Source Cluster ] :: 创建测试表
下面创建本次迁移演练使用的测试表:
cat << EOF | sudo -u hbase hbase shell
create '${TABLE_NAME}', 'cf', {SPLITS => (1..${REGIN_SPLITS}).map {|i| "user#{10000+i*(99999-10000)/${REGIN_SPLITS}}"}}
describe '${TABLE_NAME}'
EOF
5.6. [ Source Cluster ] :: 安装 YCSB
然后执行以下脚本安装 HBase 压测工具 YCSB:
YCSB_URL="https://github.com/brianfrankcooper/YCSB/releases/download/${YCSB_VERSION}/ycsb-${HBASE_VERSION}-binding-${YCSB_VERSION}.tar.gz"
wget -c $YCSB_URL -P /tmp/
sudo tar -xzf /tmp/$(basename $YCSB_URL) -C /opt
5.7. [ Source Cluster ] :: 压入全量数据
启动 YCSB 数据加载作业,向测试表写入 50TB 数据:
sudo pkill -f ycsb
nohup sudo -u hbase $YCSB_HOME/bin/ycsb load $HBASE_VERSION \-cp /etc/hbase/conf/ \-p table=$TABLE_NAME \-p columnfamily=cf \-p recordcount=$YCSB_HISTORICAL_RECORD_COUNT \-p fieldcount=10 \-p fieldlength=1048576 \-p workload=site.ycsb.workloads.CoreWorkload \-p clientSideBuffering=true \-p writebuffersize=34359738368 \-threads $YCSB_THREADS \-s &> ycsb-historical-load.out &tail -f ycsb-historical-load.out
5.8. ※ 等待 25 小时 ※
根据实操测试,完成 50 TB 数据的写入大概需要 25 个小时,期间,观察 du-hdfs-s3.out 中的统计数据,可以发现如下规律:
-
用于存储表数据的文件夹
/user/hbase/data/default/usertable其数据量整体保持持续上涨态势,但在固定周期内会有一定的小幅缩减,这是因为在周期内发生了 Compaction,文件总体积会有一定的缩减; -
用于存储表归档文件的文件夹
/user/hbase/archive/data/default/usertable其数据量维持在几百GB到1TB之间波动,原因是:周期性执行 Compaction 后,旧的 HFile 会被移动到该文件夹下,此时文件夹的总容量是上涨的,但是另一个周期性的清理线程又会定期删除该文件夹下的数据,所以该文件夹的总容量不会一直增长,而是在一个范围内波动。
5.9. [ Source Cluster ] :: 检查全量数据
全量写入完成后,在 ycsb-historical-load.out 文件中会输出汇总信息,如果想核实一下写入数据的体量和条数,可以使用下面的命令:
① 检查数据文件体量:
hdfs dfs -du -h /user/hbase/data/default/ /user/hbase/archive/data/default/
② 统计记录总数:
方法一:提交 RowCounter Map-Reduce 作业(推荐)
nohup sudo -u hbase hbase org.apache.hadoop.hbase.mapreduce.RowCounter $TABLE_NAME &> rowcounter-$TABLE_NAME.out &
tail -f rowcounter-$TABLE_NAME.out
方法二:使用 HBase Shell 的 count 命令(速度较慢,谨慎使用)
nohup sudo -u hbase hbase shell <<< "count '$TABLE_NAME', INTERVAL => 1000000" &> count.out &
tail -f count.out
5.10. [ Source Cluster ] :: 压入增量数据
为了模拟不停机迁移的场景,本文档会启动一个增量数据的写入任务,并将负载适当调低,如果中途遇到数据表被 disable 而不可写入,任务会不断重试,直至数据表被重新 enable。以下脚本将会向测试表压入 5 TB 的增量数据:
# incremental insert, retry every 60 seconds if write failed, keep trying 6 hours.
cat << EOF > incremental.workload
recordcount=$YCSB_INCREMENTAL_RECORD_COUNT
insertstart=$((YCSB_HISTORICAL_RECORD_COUNT + (YCSB_INCREMENTAL_RECORD_BATCH++) * YCSB_INCREMENTAL_RECORD_COUNT))
fieldcount=10
fieldlength=1048576
workload=site.ycsb.workloads.CoreWorkload
clientSideBuffering=true
writebuffersize=1073741824
core_workload_insertion_retry_limit=360
core_workload_insertion_retry_interval=60
EOF# downgrade concurrency, 1 thread only.
nohup sudo -u hbase $YCSB_HOME/bin/ycsb load $HBASE_VERSION \-cp /etc/hbase/conf/ \-p table=$TABLE_NAME \-p columnfamily=cf \-P incremental.workload \-threads 1 \-s &> ycsb-incremental-load-$YCSB_INCREMENTAL_RECORD_BATCH.out &tail -f ycsb-incremental-load-$YCSB_INCREMENTAL_RECORD_BATCH.out
需要解释的是:和压入全量数据不同,这里我们使用了 YCSB 的自定义workload 文件配置压测参数,因为测试表明:core_workload_insertion_retry_limit 和 core_workload_insertion_retry_interval 两个配置项不能通过-p 参数直接设置,但是配置在 workload 文件是可以的。这里我们需要调大这两个配置的默认值,特别是重试次数,以确保后续在 disable 数据表期间,增量数据的写入进程不会中断。
5.11. [ AWS Console ] :: 创建 Sink Cluster
Sink Cluster 在集群规模、节点配置上与 Source Cluster 保持一致,在 Hadoop & HBase 配置上区别于 Source Cluster 的一个最重要项是 hbase.master.cleaner.interval,如果不调大该配置项的值,在还原快照时就会遇到 can't find hfile 错误,导致还原失败。产生这个问题的原因是:我们将快照导出到了 Sink Cluster 的 hbase.rootdir(具体是写到 archive 文件夹)下,因为这样 Sink Cluster 可以直接识别导出的快照并进行还原(与 Sink Cluster 自己创建快照类似),是效率最高的一种做法,但是,在 50 TB 数量级下,由于快照导出的时间过长,Sink Cluster 上负责定期清理旧文件的线程会将尚未导出完成的快照文件判定为 Sink Cluster 自己的旧文件而将其删除。解决这一问题的方法是调大旧文件的扫描周期或调大文件被判定为旧文件的时效,它们对应下面两项配置:
| 配置项 | 说明 | 默认值 |
|---|---|---|
| hbase.master.cleaner.interval | 多久扫描一次过期文件 | 10 分钟 |
| hbase.master.hfilecleaner.ttl | 多久以前的文件会被视作旧文件 | 1 小时 |
本文,我们选择调大前者。 此外,同样是因为快照巨大,还原耗时长,操作期间会报各种超时错误,为此要在 Sink Cluster 上添加更多的超时配置项。以下是使用命令行结合前面设置的环境变量动态生成 Sink Cluster 配置的脚本:
jq . << EOF | tee sink-cluster.json | jq
[{"Classification": "hdfs-site","Properties": {"dfs.replication": "3"}},{"Classification": "yarn-site","Properties": {"yarn.nodemanager.resource.memory-mb": "61440","yarn.scheduler.maximum-allocation-mb": "61440"}},{"Classification": "hbase-env","Configurations": [{"Classification": "export","Properties": {"HBASE_MASTER_OPTS": "\"\$HBASE_MASTER_OPTS -Xmx60g\"","HBASE_REGIONSERVER_OPTS": "\"\$HBASE_REGIONSERVER_OPTS -Xmx60g\""}}],"Properties": {}},{"Classification": "hbase","Properties": {"hbase.emr.storageMode": "s3"}},{"Classification": "emrfs-site","Properties": {"fs.s3.maxConnections": "50000"}},{"Classification": "hbase-site","Properties": {"hbase.rootdir": "$SINK_CLUSTER_HBASE_ROOT_DIR/","hbase.hregion.majorcompaction": "0","hbase.master.cleaner.interval": "604800000","hbase.rpc.timeout": "86400000","hbase.client.sync.wait.timeout.msec": "86400000","hbase.client.operation.timeout": "86400000","hbase.client.scanner.timeout.period": "86400000","hbase.client.procedure.future.get.timeout.msec": "86400000","hbase.snapshot.master.timeoutMillis": "86400000","hbase.snapshot.master.timeout.millis": "86400000","hbase.snapshot.region.timeout": "86400000"}}
]
EOF
以下是各键配置项的解读:
| 配置项 | 说明 |
|---|---|
| dfs.replication | HDFS 数据副本数量,默认即为 3 (注意:在 HBase on S3 上,WAL 依然是写到 HDFS 上的,保持 3 副本是有必要的) |
| fs.s3.maxConnections | 增大 S3 的最大链接数,在大数据集下,如果不调大该值,会遇到:Unable to execute HTTP request: Timeout waiting for connection from pool 错误 |
| yarn.nodemanager.resource.memory-mb | 将单个 Core 节点 (NodeManager)分配给 Yarn 的总内存设定为 60 GB,完成 Row Counter 验证后,应将该值调小,把资源归还给 HBase |
| yarn.scheduler.maximum-allocation-mb | 将单个 Container 可分配的最大内存设定为 60 GB,完成 Row Counter 验证后,应将该值调小,把资源归还给 HBase |
| HBASE_MASTER_OPTS | 将 HBase Master 的最大可用内存设定为 60 GB,完成 Row Counter 验证后,应将该值调大,接收 Yarn 归还的资源 |
| HBASE_REGIONSERVER_OPTS | 将 HBase RegionServer 的最大可用内存设定为 60 GB,完成 Row Counter 验证后,应将该值调大,接收 Yarn 归还的资源 |
| hbase.emr.storageMode | 使用 S3 作为 HBase 的底层存储 |
| hbase.rootdir | HBase Root Dir 的 S3 路径 |
| hbase.master.cleaner.interval | HBase 扫描并清理旧文件的周期,默认为 10 分钟,此处改为 7 天 |
| hbase.rpc.timeout hbase.client.sync.wait.timeout.msec hbase.client.operation.timeout hbase.client.scanner.timeout.period hbase.client.procedure.future.get.timeout.msec hbase.snapshot.master.timeoutMillis hbase.snapshot.master.timeout.millis hbase.snapshot.region.timeout | 将 HBase 各种超时上限设定为 24 小时,由于本次演练的数据量巨大,大多数操作的执行时间都超出了默认的 timeout 上限,需要特别提升上限 |
这里,要特别注意 hbase.master.cleaner.interval 的取值,这个时间必须大于快照导出+还原的操作总时长,如果设置的时间小于操作用时,就会出现 can't find hfile 错误,也就是操作途中文件被自动删除了。此外,还要留心的是:这是一个周期时间 ,如果我们没有在启动集群后马上进行快照导出和还原操作,那么,之后再操作时将处于文件清理时间窗口的什么位置就不太容易确定了(HBase 没有关于文件清理的 Info 级别日志),遇上自动删除文件的概率会增大,这一点要始终保持清醒的认识。在本文的操作演示中,为了避免这些问题,我们特意将 hbase.master.cleaner.interval 配置为了一个很大的值:7 天,操作完成后,需要将该项和其他超时相关的配置项都改回默认值。
集群创建成功后,需要到 Source Cluster 的主节点上声明一下 Sink Cluster 的 ZkQuorum,因为后续在 add peer 时需要使用这个信息,使用如下命令可快速获得 ZkQuorum:
sudo yum -y install xmlstarlet
xmlstarlet sel -t -v '/configuration/property[name = "hbase.zookeeper.quorum"]/value' -n /etc/hbase/conf/hbase-site.xml
将获得的 ZkQuorum 值赋给全局变量,在 Source Cluster 上执行一遍(注意替换脚本中的 <your-sink-cluster-hbase-master-host-list>):
# run on [ Source Cluster ] !
export SINK_CLUSTER_HBASE_MASTER_HOST="<your-sink-cluster-hbase-master-host-list>"
5.12. ※ 暂停写入 ※
① 生产环境
由于后续两项操作: “配置 Replication” 和 “创建快照” 需要 disable 源端集群上的数据表,这会导致源端集群短时间内无法写入,这两项操作的总耗时不会太长,大概在数十分钟左右,主要取决数据表的 Region 数量。如果条件允许,应该有计划地暂停应用端的数据写入。测试表明:如果在启用 Replication 和打快照期间在向源端集群高速压入数据的话,会有一定的概率导致后续 enable peer 时 WAL Log 无法接续,导致 Sink Cluster 无法同步 Source Cluster 的增量数据。
② 模拟环境
此前,我们启动了增量数据的写入用于模拟前端业务系统产生的线上数据,为了尽可能地模拟不停机场景,可以不用终止增量数据的写入,当操作过程中 disable table 时,增量写入程序会自动重试直到数据表重新 enable。
5.13. [ Source Cluster ] :: 建立与 Sink Cluster 的同步
现在,我们要开始执行 5 个核心操作中的第 1 项操作了:建立同步,脚本如下:
cat << EOF | nohup sudo -u hbase hbase shell &> enable-replication.out &
# disable table first...
disable '${TABLE_NAME}'
# replication config ops...
alter '${TABLE_NAME}',{NAME => 'cf', REPLICATION_SCOPE => '1'}
add_peer 'sink_cluster', CLUSTER_KEY => '$SINK_CLUSTER_HBASE_MASTER_HOST:2181:/hbase'
disable_peer 'sink_cluster'
list_peers
enable_table_replication '$TABLE_NAME'
list_replicated_tables
status 'replication'
# enable table
enable '${TABLE_NAME}'
EOF
tail -f enable-replication.out
这是一种典型的 Replication 配置操作,其核心逻辑是:add peer 后,立即 disable peer,然后再 enable replication,这样做的目的是:让源端集群开始积压 WAL Log ,但先不同步到目标端,等目标集群从快照恢复后,再同步过去。值得注意的一个细节是:一旦执行 enable_table_replication, Sink Cluster 上会自动创建对应的被同步表。
5.14. [ Source Cluster ] :: 创建快照
接下来是第 2 项核心操作:创建快照。这是一个很轻量的动作,只需一条命令即可在短时间内完成。不过,创建快照前,如果条件允许,最好先 disable table,这样可以屏蔽外部外读写,同时能将 MemStore 中的数据主动 flush 到磁盘上,这种方式打出来的快照叫 Offline Snapshot。当然,不 disable table 也是可以的,在这种情况下,由于提交命令时各个 RegionServer 可能处于不同的状态,所以是由各个 RegionServer 自行决定在什么时候创建自己所辖 Region 的快照,当所有 RegionServer 都打完快照时,再由 Master 统一标记 Snapshot 完成,这个过程很像分布式事务中的两阶段提交,使用这种方式创建的快照叫 Online Snapshot。本文创建的是 Offline Snapshot:
# disble table
sudo -u hbase hbase shell <<< "disable '$TABLE_NAME'"
# create snapshot
sudo -u hbase hbase snapshot create -n $SNAPSHOT_NAME -t $TABLE_NAME
# sleep for a while, snapshot may be NOT available immediately.
sleep 120
# check if snapshot is available
sudo -u hbase hbase snapshot info -list-snapshots
# enable table
sudo -u hbase hbase shell <<< "enable '$TABLE_NAME'"
5.15. ※ 恢复写入 ※
如果是在生产环境上,创建完快照后,脚本会重新 enable 数据表,这时就可以恢复应用端的写入了。
5.16. [ Source Cluster ] :: 导出快照
接下来是 5 个核心操作中的第 3 项操作:导出快照,这其实是一个 Map-Reduce 作业,需要动用 Source Cluster 的 Yarn 资源将快照文件写入到目标位置,该作业执行时间较长,一般在 3 小时左右。
# export snapshot to sink cluster hbase root dir
nohup sudo -u hbase hbase snapshot export \-snapshot $SNAPSHOT_NAME \-copy-to "$SINK_CLUSTER_HBASE_ROOT_DIR/" \-mappers $SNAPSHOT_EXPORT_MAPPERS &> export-snapshot.out &
tail -f /var/log/hbase/hbase.log
其中,--mappers 控制的是导出作业的 map task 的数量,该值过大或过小都会影响导出性能,建议配置为可用容器(Yarn Container)数量的整数倍(例如4倍)。
5.17. ※ 等待 3 小时 ※
50 TB 快照导出大概需要 3 个小时,期间可以登录 Yarn 的 ResourceManager 页面查看作业进度。
5.18. [ Sink Cluster ] :: 还原快照
现在是 5 个核心操作中的第 4 项操作:还原快照,提醒注意的是,这一步我们要移步到 SinkCluster 上操作,并且在执行脚本前,须先执行一遍 5.2 节:”全局变量“ 的操作,然后执行如下命令:
- 确认快照已存在
sudo -u hbase hbase snapshot info -list-snapshots
- 还原快照
cat << EOF | nohup sudo -u hbase hbase shell &> restore-snapshot.out &
disable '$TABLE_NAME'
restore_snapshot '$SNAPSHOT_NAME'
enable '$TABLE_NAME'
EOF
tail -f restore-snapshot.out
5.19. ※ 等待 2 小时 ※
整个快照的恢复时间大概在 2 个小时内,期间可以从 HBase Master UI 上观察还原的进度。通常,在 Tasks 页面上,我们会先看到一个 RestoreSnapshot 的Task,这个 Task 大概会执行接近 1 小时 45 分钟,之后会有一个清理作业,最后在 UI 上会显示一条绿色的还原完成的信息:

5.20. [ Sink Cluster ] :: 修改配置并重启
注意:本节和 5.22 为二选一操作,若选择重启集群,则不需要再进行 5.22 节操作!
由于快照还原阶段的特殊需求,我们在创建 Sink Cluster 时修改了很多超时配置的默认值,更重要的是调高了 hbase.master.cleaner.interval的值,这会使得文件大量积压,虽然 HFile 存放于 S3 上,不存在磁盘写满的情况,但是 HBase on S3 的 WAL 文件却是存放在 HDFS 上的,如不能及时改回默认配置,磁盘会有被写满的危险。而重启 HBase 集群是有一定风险的,最好是在关停读写并disable 所有数据表的前提下操作。在整个操作流程中,此时修改配置并重启 Sink Cluster 集群是最好的时机,因为此时集群尚未接入实时写入的数据,方便 disable table,重启集群会比较安全。
通常,EMR 控制台支持修改配置并自动重启相关服务,但是,该功能仅在 5.27(针对多主集群)之后可用,详情可参考:[ 官方文档 ] ,因此,我们只能手动重启。手动重启集群的方法可参考 EMR 官方文档:[ Managing the production environment ] 和 [ Appendix A: Command reference ] 。
5.21. [ Source Cluster ] :: 放开与 Sink Cluster 的同步
我们已经进入到了 5 个核心操作中最后一项操作:放开同步。在放开同步前,先执行如下脚本,将 replication 的状态持续输出的文件中,便于观察 WAL 的同步进度:
pkill -f status-replication
cat << EOF > /tmp/status-replication.sh
for i in {1..1008};dosudo -u hbase hbase shell <<< "status 'replication'"sleep 60
done
EOF
nohup sh /tmp/status-replication.sh &> status-replication.out &
tail -f status-replication.out
然后,执行正式的放开同步操作,也就是 enable peer 操作:
sudo -u hbase hbase shell <<< "enable_peer 'sink_cluster'"
恢复 peer 之后,可以观察 status-replication.out 中输出的 replication 状态信息,如果一切正常,SOURCE 的 SizeOfLogQueue 应该开始下降,表明 WAL 开始项 Sink 端发送,就如同下面这样:


5.22. ※ 等待日志追平 ※
持续观察 tail -f status-replication.out 的输出,当 SizeOfLogQueue 降为 1 后,就表明 WAL 日志已经追平。
5.23. [ Sink Cluster ] :: 使用新配置创建新集群
注意:本节和 5.19 为二选一操作,若选择创建新集群,则不需要再进行 5.19 节操作!
如果担心重启集群有潜在问题,可以放弃 5.19 节的操作,选择第二种方案:关停现有集群,然后启动一个新的 EMR 集群。因为对于 HBase on S3 来说,数据和元数据都存放在 S3 上,所以关停集群并不会导致数据丢失,而重启新集群可以自动加载 HBase 的数据和元数据,所以这种方式是可行的。如果选择这一方式,则此时是最合适的时机,因为此时 Source Cluster 与 Sink Cluster 的 WAL 日志已经追平,两个集群保持实时同步状态,此时替换集群,只需短暂暂停 Source Cluster 的写入即可,不会对 Source Cluster 产生过多影响。具体操作如下:
- 暂停 Source Cluster 的写入
- 关停旧集群(具体操作请遵循此官方文档:[ HBase on Amazon S3 (Amazon S3 storage mode) ] 的 “Shutting down and restoring a cluster without data loss” 一节)
- 移除 Source Cluster 与 旧的 Sink Cluster 之间的 replication 关系
- 使用正常配置创建新的 Sink Cluster
- 配置 Source Cluster 与新的 Sink Cluster 之间的 replication 关系
- 恢复 Source Cluster 的写入
由于上述操作步骤有的有官方文档,有的与前面章节的操作一致,所以,本文不再赘述。
5.24. ※ 核对数据 ※
完成上述所有操作后,迁移工作就完成了,最后一步就是核对 Source Cluster 和 Sink Cluster 之间数据是否一致了。如果是在生产环境上,核对数据会有一些困难,主要是统计数据往往需要较长时间 ,这期间数据有可能会发生变更。所以,需要根据系统的业务特点,制定灵活的统计方式和核对策略,例如:如果业务属性决定了数据在超过某个时间后就不再变动的话,可以针对远期数据进行静态比对;如果数据量过大,可以采取随机抽样和小范围的求和,求平均值等方法进行多轮迭代比对。
针对本次演练,我们只简单统计一下两边数据表的总行数就足以说明数据一致性了。如果此前写入增量数据的进程还没有结束,此时就应主动停止进程,以方便数据比对:
sudo pkill -f ycsb
然后分别在 Source Cluster 和 Sink Cluster 上执行 HBase 的 RowCounter 命令:
nohup sudo -u hbase hbase org.apache.hadoop.hbase.mapreduce.RowCounter $TABLE_NAME &> rowcounter-$TABLE_NAME.out &
tail -f /var/log/hbase/hbase.log
RowCounter 作业大概会持续 1 个小时,期间可以登录 Yarn 的 ResourceManager 页面查看作业进度。当两侧的 RowCounter 作业执行完毕后,登录各自集群的主节点,打开 /var/log/hbase/hbase.log 可以在文件末尾看到 RowCounter 输出的统计结果,如果 ROWS 数据一致,就表明数据一致,迁移过程中没有丢失数据:

至此,整个迁移演练全部结束!
6. 资源清理
如需重复本演练的操作,可在现有 Source Cluster 和 Sink Cluster 上清理掉相关资源,以下是资源清理脚本。
6.1. 移除同步
cat << EOF | sudo -u hbase hbase shell &> remove-peer.out &
disable_table_replication '$TABLE_NAME'
alter '${TABLE_NAME}',{NAME => 'cf',REPLICATION_SCOPE => '0'}
disable_peer 'sink_cluster'
remove_peer 'sink_cluster'
status 'replication'
EOF
tail -f remove-peer.out
6.2. 删除快照
sudo -u hbase hbase shell <<< "delete_snapshot '$SNAPSHOT_NAME'"
6.3. 删除测试表
cat << EOF | sudo -u hbase hbase shell &> drop-table.out &
truncate '${TABLE_NAME}'
disable '${TABLE_NAME}'
drop '${TABLE_NAME}'
EOF
tail -f drop-table.out
7. 已知错误
作为一次超大数据集的迁移案例,我们在操作过程中遇到了很多问题,这些问题都与数据体量巨大有着密切关系。以下是汇总的问题列表,谨供参考。
7.1. 导出快照时报:Unable to load AWS credentials 错误
该问题发生在快照导出过程中,根据日志信息,在导出的最后阶段,Export 操作会对导出的快照进行一次验证,在验证时会报出如下错误:
ERROR [main] snapshot.ExportSnapshot: Snapshot export failed
....
Caused by: com.amazon.ws.emr.hadoop.fs.shaded.com.amazonaws.SdkClientException: Unable to load AWS credentials from any provider in the chain:
....
产生这一错误的直接原因是节点使用的 EC2 Assume Role 的 Temporary Credential 的 Token Session 过期,但具体是什么操作或情景导致的,目前尚不清楚,并且该问题并非每次都会发生。针对该问题最初尝试的解决方案是:将 EC2 Assume Role 的 “Maximum session duration” 调整为最大值 12 小时:

但是重试后依然报错,查阅相关文档发现,该配置对 AWS Service Assume Role 并不起作用:

经和后台协商,决定在EMR 集群上显式地配置AKSK,用AKSK访问 S3,规避基于 Token 方式访问 S3 的 Session 过期问题。
7.2. 还原快照时报: can’t find hfile 错误
在还原快照时,发现有 HFile 丢失,该问题在很多文档中都有所提及,原因是:在快照导出至目标集群的过程中,文件会被自动删除。产生这一问题的原因首先是因为:快照导出的目录选择了目标 HBase 集群的 ROOT DIR(具体是写到 archive 下),而在目标集群上运行着 HBase 定期清理旧 HFile 的线程,当导出时间过长时(超过1个小时),这些刚刚导入的 HFile 文件会被视作“旧文件”从而被定时启动的清理作业删除,这些文件被错误地判定“旧文件”的原因是:由于快照尚未还原,目标 HBase 集群中还没有这些 HFile 的元数据,相当于这些文件还没有“注册”,而当它们在目标 HBase 集群的 ROOT DIR 下存在时间一长,就被自动判定为了“旧文件”。解决这一问题的方法是:延长清理旧文件作业执行周期,或者提高旧文件判定标准(TTL)的阈值,与这两点相对应的配置项分别是:
| 配置项 | 说明 | 默认值 |
|---|---|---|
| hbase.master.cleaner.interval | 多久扫描一次过期文件 | 10 分钟 |
| hbase.master.hfilecleaner.ttl | 多久以前的文件会被视作旧文件 | 1 小时 |
本文选择了调大扫描周期。不过,要注意的是:这一配置是在快照导出和还原期间不得不做出的改动,对于线上的生产集群来说,这个值不宜过大,过大会积压大量文件,有将集群磁盘写满的风险,所以在完成还原后,需改回默认值。
7.3. HDFS 空间耗尽
测试过程中,出现过一个意料之外的情况:在使用 20 TB 数据做测试时,源集群规划了 40 TB 存储空间,数据表是 20 TB,集群有接近一倍的富余空间,但是在导出结束前发现存储空间已经写满。检查 HDFS 目录,发现 archive 文件夹下数据表的目录几乎与原表目录一样大:

这说明数据表的数据接近冗余了一倍,这里非常容易让人误解为:是创建快照导致了容量翻倍,但如文章开头所介绍的,创建快照本身并不会复制任何文件,触发文件复制的其实是 Compaction。由于在 YCSB 持续写入的过程中,HBase 积压了大量的 Compaction 任务,如果写入完成立即创建快照,积压的 Compaction 会在创建快照后继续执行,这会导致 archive 文件夹不断地膨胀。不过,该情况不一定会发生在生产集群上,因为生产集群的吞吐量通常没有压测工具写入时那么大,从创建快照到快照删除期间,未必会经历大量的 Compaction 作业。
7.4. HBase Shell 报 ERROR: The procedure x is still running 或 Snapshot … wasn’t completed in expectedTime 错误
在通过 HBase Shell 执行操作时,有可能会出现 “ERROR: The procedure x is still running” 错误,特别是在执行一些耗时非常长的命令,例如:enable_table_replication 和 restore_snapshot 时。这些错误都和超时相关,需要在 EMR 配置上添加几个与 TimeOut 相关的配置。此外,在 HBase Shell 上,我们也可以使用如下方式配置 Session 级别的超时上限,也能解决这一问题:
@shell.hbase.configuration.setInt("hbase.rpc.timeout", 86400000)
@shell.hbase.configuration.setInt("hbase.client.operation.timeout", 86400000)
@shell.hbase.configuration.setInt("hbase.client.sync.wait.timeout.msec", 86400000)
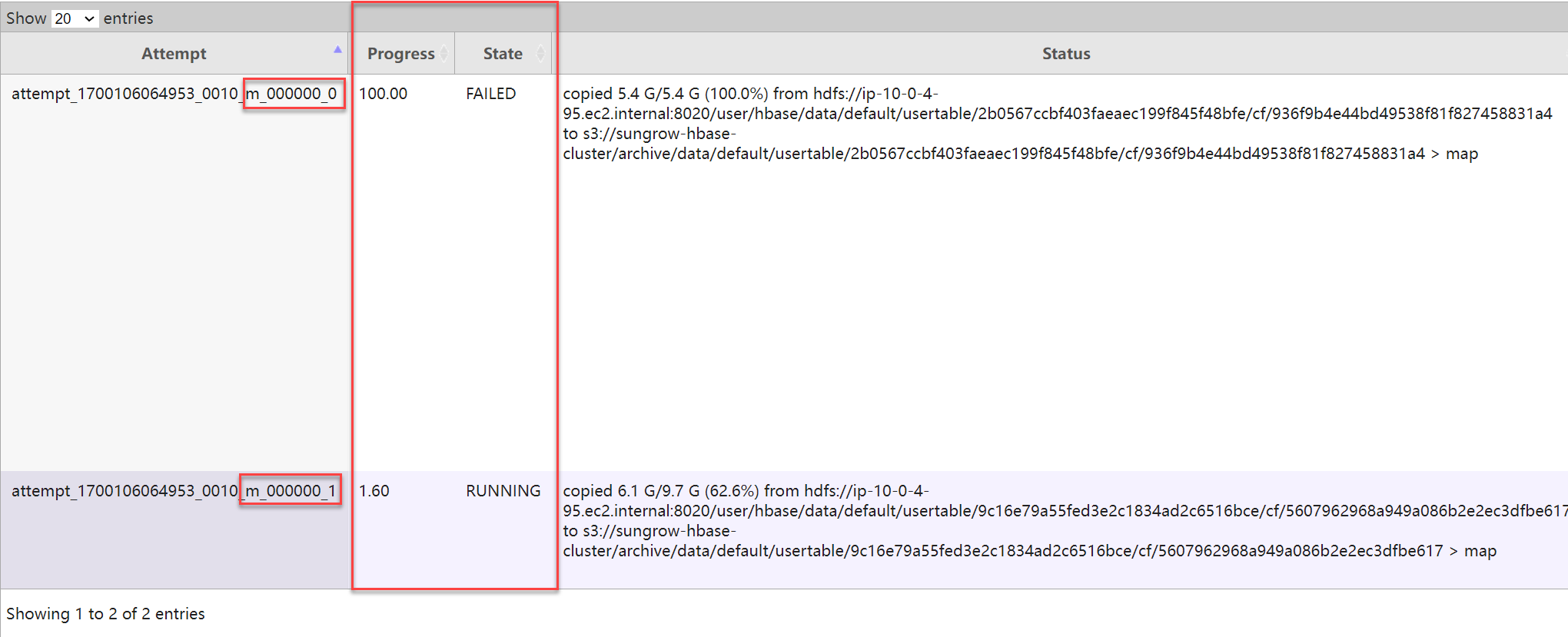
7.5. 导出快照时报错: IllegalStateException: Reached max limit of upload attempts for part 错误
这一错误发成在导出快照的 MR 作业中,原因是因为数据量过大,MR 的 map task 数量过多,对 S3 的连接请求超出了上限,解决这一问题的方法是调大 fs.s3.maxConnections。此外,如果在作业执行过程中偶有几次这样的报错,并不会导致整个导出作业失败,因为Hadoop 会自动重试失败的 map 任务。以下是 MR 作业重试的截图: