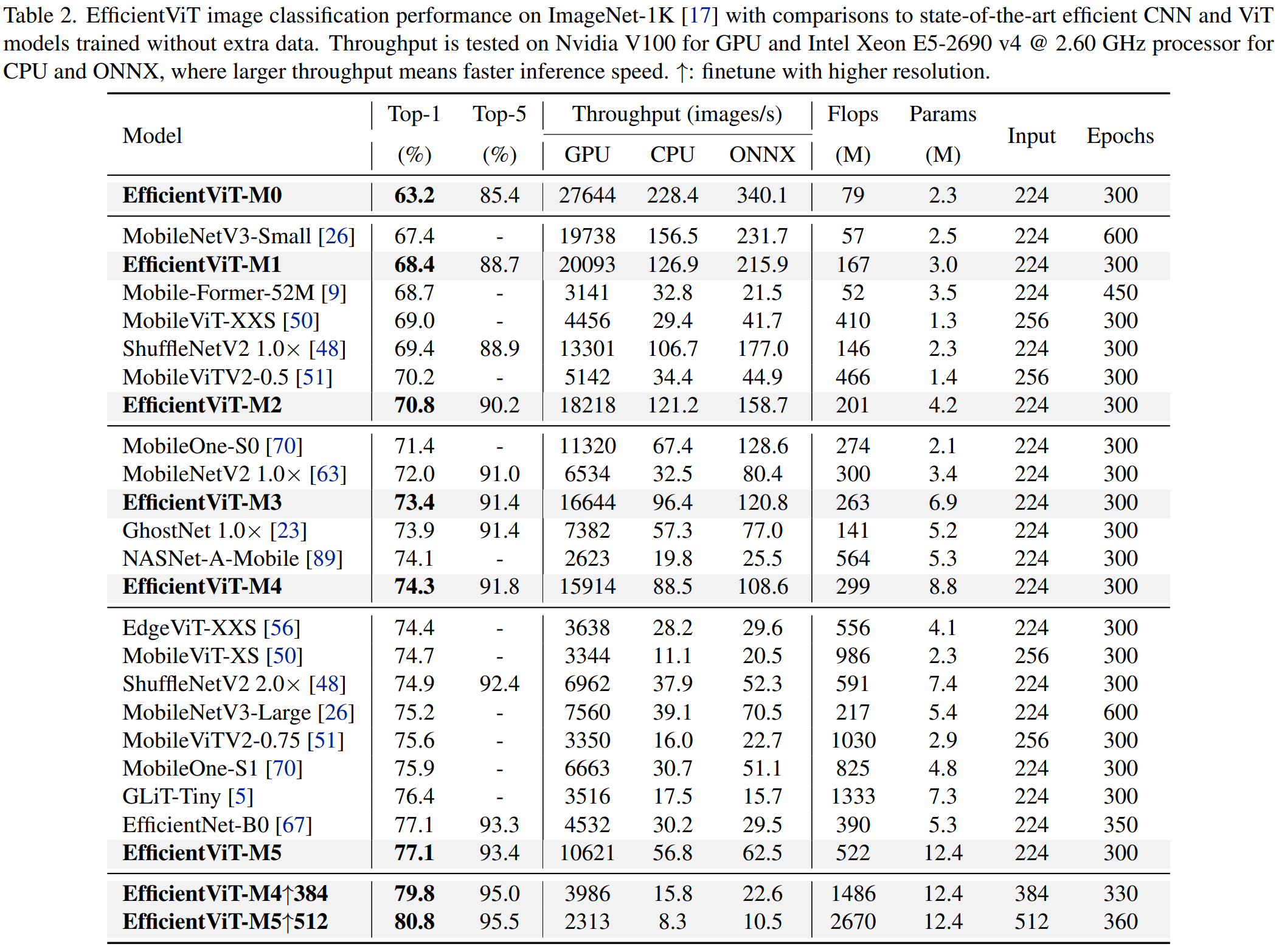
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
1、

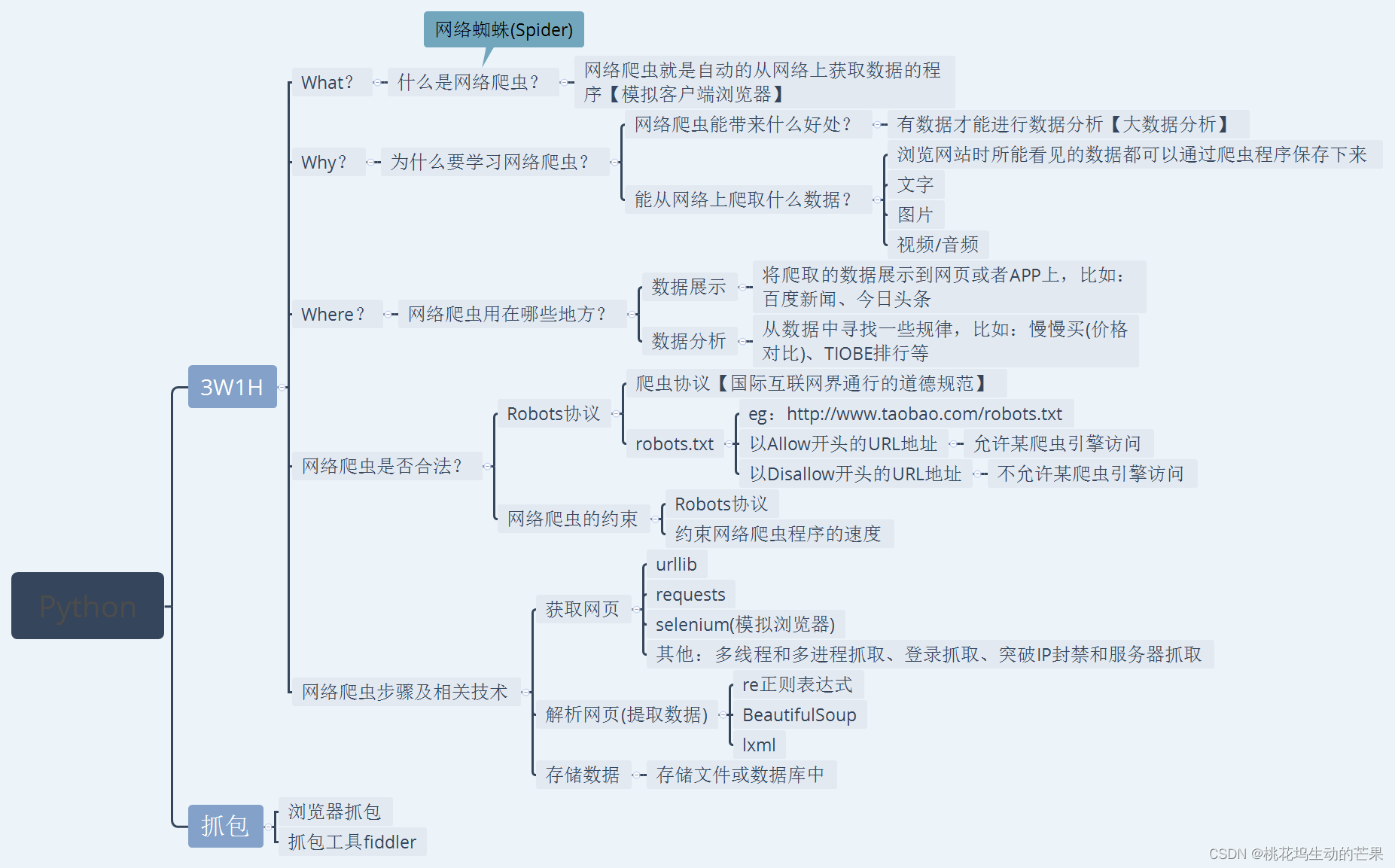
从三个角度探讨如何提高vision transformers的效率:内存访问、计算冗余和参数使用。
2.1. Memory Efficiency

红色字体表示操作所花费的时间主要由内存访问决定,而用于计算的时间要小得多。
vision transformers中内存不高效的操作:reshaping, element-wise addition, and normalization
本文通过通过减少内存低效层来节省内存访问成本。
存储低效的层MHSA 层比FFN层多。大多数模型使用相同数量的这两层,无法实现最佳效率。于是作者探索了不同比例MHSA 层比FFN层设置。20%-40% MHSA 层效果比较好。

结果表明,适当降低MHSA层利用率可以在提高模型性能的同时提高内存效率。
2.2. Computation Efficiency
注意力计算非常耗费资源,并且有一些其实不重要。于是,作者探索了如何减少冗余注意力计算。测量每个头部和每个块内的剩余头部的最大余弦相似性。结果如下:

在注意力头之间存在较高相似性,尤其最后几个block。这一现象表明,许多头部学习相同完整特征的相似投影,并产生计算冗余。为了明确地鼓励头部学习不同的模式,我们应用了一种直观的解决方案,只给每个头部提供完整特征的一部分。我们用改进的MHSA训练缩减模型的变体,并计算相似性,如图4所示。这表明在不同的头部中使用不同的通道分割特征,而不是像MHSA那样对所有头部使用相同的完整特征,可以有效地减少注意力计算冗余。
2.3. Parameter Efficiency

典型的ViT主要继承了NLP变换器的设计策略,例如,使用Q、K、V投影的等效宽度,逐级增加头,并将FFN中的膨胀比设置为4。在轻量级模型中这些组成部件应该被重新精细设计。作者采用Taylor structured pruning -Taylor结构修剪来自动找到Swin-T和DeiT-T中的重要成分,并探索参数分配的基本原理。修剪方法在一定的资源约束下去除不重要的通道,并保留最关键的通道以最好地保持准确性。它使用梯度和权重的乘积作为信道重要性,这近似于去除信道时的损耗波动。
图5 表明:1) 前两个阶段保留了更多的维度,而最后一个阶段保留的维度要少得多;2) Q、K和FFN的尺寸在很大程度上被修剪,而V的维度几乎被保留下来,并且仅在最后几个块处减小。这些现象表明:1)典型的通道配置,在每个阶段后将通道加倍,或对所有块使用等效通道,可能会在最后几个块中产生大量冗余;2) 当它们具有相同的维度时,Q、K中的冗余度远大于V。V更喜欢相对较大的通道,接近输入嵌入维度。
3. Efficient Vision Transformer

3.1. EfficientViT Building Blocks
Sandwich Layout:
self-attention layers减少,FFN layers增加。额外每个FFN之前使用深度卷积(DWConv)增加token interaction。引入局部结构信息的归纳偏差,提高模型的性能。
Cascaded Group Attention:
提出级联组注意力(CGA),它向每个头部提供完整特征的不同分割,从而明确地分解头部之间的注意力计算。


把heads分开分别计算注意力,再合起来,具体看图6.c
将每个头部的输出添加到后续头部,以逐步细化特征表示:
![]()
Parameter Reallocation:
Q和K投影设置了小通道尺寸。对于V投影,允许它具有与输入嵌入相同的维度。由于其参数冗余,FFN中的膨胀比也从4降低到2。
3.2. EfficientViT Network Architectures
每个阶段堆叠所提出的Ef ficientViT构建块,并且在每个子采样层,令牌的数量减少4倍(分辨率的2倍子采样)。为了实现高效的二次采样,提出了一种高效的ViT二次采样块,它也具有三明治布局,只是自注意层被倒置的残差块取代,以减少二次采样过程中的信息损失。在整个模型中采用BatchNorm(BN)而不是Layer Norm(LN),因为BN可以折叠到前面的卷积或线性层中,这是比LN的运行时优势。我们还使用ReLU[54]作为激活函数,因为常用的GELU或HardSwish要慢得多,而且有时不能很好地得到某些推理部署平台的支持。
4. Experiments