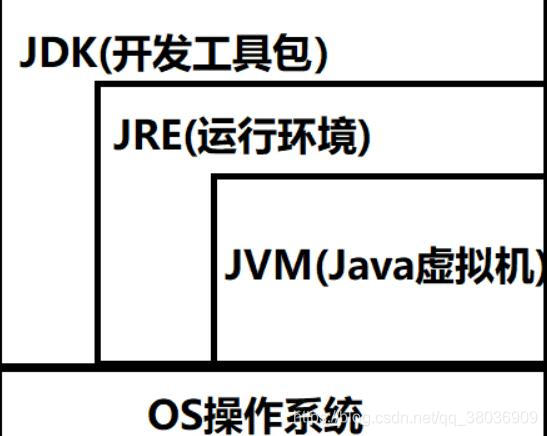
1前言

正则表达式(Regular Expression)是一种用来描述字符串模式的表达式。它是一种强大的文本匹配工具,可以用来搜索、替换和提取符合特定模式的文本。
正则表达式由普通字符(例如字母、数字、符号等)和元字符(用于描述模式的特殊字符)组成。通过结合这些字符,可以创建一个模式,用来匹配文本中符合特定规则的部分。
正则表达式在我们日常开发中十分常用,可以用来数据提取和文本处理,同时也是面试中比较常问的问题,学好正则表达式是Python开发工程师的必备项!
看了一下网上很多正则表达式的文章,对于小白来说实在有点难接受
1 符号 .
匹配任意的单个字符
import re
context = '''苹果是绿色的,橘子是黄色的,头发是黑色的
'''
## r 表达不发生转义
p = re.compile(r'.色')
print(p.findall(context))
## ['绿色', '黄色', '黑色']2 符号 *
匹配前面子表达式任意次(包括0次) 常常与 . 搭配使用
p = re.compile(r'是.*')
print(p.findall(context))
#['是绿色的,', '是黄色的,', '是黑色的']
p = re.compile(r'.*是')
print(p.findall(context))
#['苹果是', '橘子是', '头发是']
context = "我是是是是大帅哥,\n你是嘿嘿黑,\n欸我的饭呢"
p = re.compile(r'是*')
print(p.findall(context))
#['', '是是是是', '', '', '', '', '', '', '是', '', '', '', '', '', '', '', '', '', '', '']3 符号 +
和 * 类似 表示至少出现一次
context = "我是是是是大帅哥,\n你是嘿嘿黑,\n欸我的饭呢"
p = re.compile(r'是+')
print(p.findall(context))
#['是是是是', '是']4 符号 {}
指定匹配次数
p = re.compile(r'是{2,5}')
#print(p.findall(context))
#['是是是是']
context = '''我的电话号码是12345678901,地址在深圳技术大学'''
p = re.compile(r'\d{11}')
print(p.findall(context))
#['12345678901']5 符号 ?
是否贪心:
贪婪模式和非贪婪模式
'*' '+' 都是贪心的,会尽量多地匹配
在 '*' '+' 之后加上 '?' 表示非贪心
context = '''<1><2><3><4>'''
p = re.compile(r'<.*?>')
#print(p.findall(context))
#['<1>', '<2>', '<3>', '<4>']
p = re.compile(r'<.*>')
#print(p.findall(context))
#['<1><2><3><4>'] #贪心6 符号 \
①转义
②特定字符
\d 匹配数字 \D 匹配不是数字的
\s 匹配任意地空白字符 \S 匹配非空白
\w 匹配文字字符(数字、字母、下划线)\W 匹配非文字字符
7 符号 []
或
context = '''
leo,qq1234567890,18
penry,qq2234567890,19
anry,qq09878976454,20
makerry,qq1456789091,18'''
p = re.compile(r'qq[123]\d{9}')
print(p.findall(context))
#['qq1234567890', 'qq2234567890', 'qq1456789091']8 符号 ^
非 与 [] 搭配 也可以表示匹配开口
context = "abc123,123abc,hekl1,his12,213f,abc"
p = re.compile(r'[a-z]+[0-9]{3}')
#print(p.findall(context))
#['abc123']
p = re.compile(r'[^0-9]{3}')
print(p.findall(context))
#['abc', 'abc', ',he', ',hi', 'f,a']单行模式:匹配文本的起始位置
多行模式:匹配文本每行的起始位置
context = '''
001-apple-60,\n
002-pear-70,\n
003-banner-30'''
p = re.compile(r'^\d+',re.MULTILINE) ## 缺省是单行 M是多行模式
print(p.findall(context))
#['001', '002', '003']9 符号 $
从文本末开始匹配
context = '''
001-apple-60
002-pear-70
003-banner-30'''
p = re.compile(r'^\d+',re.MULTILINE) ## 缺省是单行 M是多行模式
print(p.findall(context))
#['001', '002', '003']
p = re.compile(r'\d+$',re.MULTILINE)
print(p.findall(context))
#['60', '70', '30']10 符号 ()
分组提取
context = '''
苹果是绿色的,\n橘子是黄色的,\n头发是黑色的
'''
## 消除标识符
p = re.compile(r'(.+)是')
#print(p.findall(context))
#['苹果', '橘子', '头发']
p = re.compile(r'(.+)是(.+色)的')
#print(p.findall(context))
#[('苹果', '绿色'), ('橘子', '黄色'), ('头发', '黑色')]
context = '''
leo,qq1234567890,18
penry,qq2234567890,19
anry,qq09878976454,20
makerry,qq1456789091,18'''
p = re.compile(r'(.+),qq([123]\d{9})')
#print(p.findall(context))
#[('leo', '1234567890'), ('penry', '2234567890'), ('makerry', '1456789091')]11 \number
分组概念的举例:匹配ABAC或者AABB的成语
引用前面匹配的第n个组的内容
## 找出 ABAC AABB 型的成语
# 123 45 6
pattern = r'(((.).\3.)|((.)\5(.)\6))'
# A B AC | A A B B
## 找出 AABC ABAC 型的成语
# 123 45
pattern = r'(((.)\3..)|((.).\5.))'
# A ABC A B AC看到这里你已经掌握了基本的正则表达式的使用‘姿势’了,在日常的大部分使用场景中都足以应对了,恭喜你!