我们知道传统RNN输入和输出数据是等长的,这显然极大限制了他的应用范围。
前面几节我们讲到的循环神经网络的各种变体基本上都在解决一个序列的问题。还有一大类问题涉及到的是两个序列间转换。它是自然语言处理中的一个重要领域,包括机器翻译、语音识别和文本分类等任务。
当然,前面讲过的RNN、LSTM、GRU、BRNN等模型也都可以应用于这类问题。
但是专门设计的模型显然可以更加有针对性。
下面要介绍的编解码网络 (Encoder-Decoder Network)就是其中非常典型的一种。
1、编码器 - 解码器网络
1.1、基本原理
编解码器网络是由 Francois Cholet et al. 在 2014 年论文 "Sequence to Sequence Learning with Neural Networks"中提出的。
编解码器网络由两个独立的循环神经网络 (RNN) 组成,分别称为编码器和解码器。
编码器将输入序列进行编码,并将编码结果作为解码器的初始状态。
解码器利用编码结果,逐步生成输出序列。

编码器将输入序列 ![]() 进行编码,并将编码结果作为解码器的初始状态。解码器利用编码结果,逐步生成输出序列
进行编码,并将编码结果作为解码器的初始状态。解码器利用编码结果,逐步生成输出序列 ![]() 。
。
1.2、编码器
编码器是一个循环神经网络,用于将输入序列 X 进行编码。
把不定长的输入序列变换成定长的上下文变量 c ,并在变量中编码输入序列的信息。
不直接对输入序列进行编码,而是通过对应的隐藏状态进行编码。
在每个时间步 t ,编码器会将输入 x t 和上一时间步的隐藏状态 h t-1 作为输入,通过一个函数 f 来计算当前时间步的隐藏状态 h t 。
在整个输入序列的编码过程结束后,编码器会将最终的隐藏状态 h T 作为解码器的初始状态。

1.3、解码器
解码器也是一个循环神经网络,用于根据编码器的输出生成输出序列 Y 。
在每个时间步 t,解码器会将输出 y t-1 和上一时间步的隐藏状态 s t-1 作为输入,通过一个函数 f d 来计算当前时间步的隐藏状态 s t :
![]()
然后,解码器会将隐藏状态 s t 作为输入,通过一个函数 g 来生成当前时间步的输出 y t:
![]()
在整个输出序列的生成过程结束后,解码器会将最终的输出序列 作为编解码器网络的输出。
![]()
1.4、自回归编解码网络
自回归编解码器网络 (Autoregressive Encoder-Decoder Network)是一种特殊的编解码器。
它和一般的编解码网络 (Encoder-Decoder Network) 的区别在于,在自回归编解码器网络中,解码器的输入是上一时间步的输出 y t-1 和当前时间步的隐藏状态 s t-1 ,而在一般的编解码网络中,解码器的输入只是当前时间步的隐藏状态 s t-1 。
这样的网络结构称为自回归 (autoregressive),因为解码器的输入取决于解码器自身的输出。
我们前面学习了编码器解码器模型,它是文本处理领域非常流行的一个架构,它解决了传统方式输入大小固定的问题,能够将深度学习更好的应用于NLP任务中。
而基于这个架构的模型,我们可以构建出seq2seq模型,也就是序列到序列模型。故名思意,模型的输入是一个序列,输出也是一个序列。这样的任务大家随随便便就能说出好几种,比如,机器翻译,文本摘要,语音识别等等。
2、seq2seq模型
2.1、基本原理
Seq2seq模型最早在2014年,由Ilya Sutskever等提出。当时主要应用在机器翻译的相关问题中,其可以理解为一个适用于处理由句子(段落)X生成句子(段落)Y的通用模型。
对于给定的输入句子X,我们的目标是通过Seq2seq模型生成目标句子Y。X与Y并不限制为同一种语言。将X和Y的单词序列表示如下:
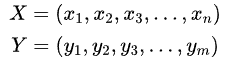
首先对输入的句子进行建模,循环神经网络将的输入特征向量 x t 和 h t-1 转换为了 h t:
![]()
编码器则通过选定的函数q,通过非线性变换将输入向量转化为了中间向量表示c,c也可以称为上下文向量:
![]()
而解码器则根据编码器生成的中间向量表示 c 和之前生成的历史信息,生成 t 时刻的输出 y t :
![]()
要注意的是,这里编码器和解码器的时间步都用的符号 t 表示,但实际上这两个 t 并不是一回事。通过上面的公式,可以看到 y t 的值取决于前面 t-1 步的输出,因此这里的解码器也是一个循环神经网络。
解码的过程是先利用上一个时间步的输出 y t-1 和上下文向量c,在当前时间步将上一个隐状态 h t-1 转化为当前步的隐状态 h t 。可以得出如下公式:
![]()
可以通过解码器的隐状态 h t ,计算出t时刻的输出 y t 。比较常见的计算方法则是softmax。
2.2、模型结构
seq2seq的模型结构有很多种,最简单的模型结构就是下面这样:

在这种结构中,上下文向量 c 只作用于了第一个解码器隐状态,也就是将c当成了初始隐藏状态。c 也可以作用于所有的隐藏状态,此时网络结构就是如下形式:

此时,这依然是比较简单的情况,不再把上下文向量 c 当成是 RNN 的初始隐藏状态,而是当成 RNN 每一个神经元的输入。可以看到在 Decoder 的每一个神经元都拥有相同的输入c。
第三种则是如下结构:
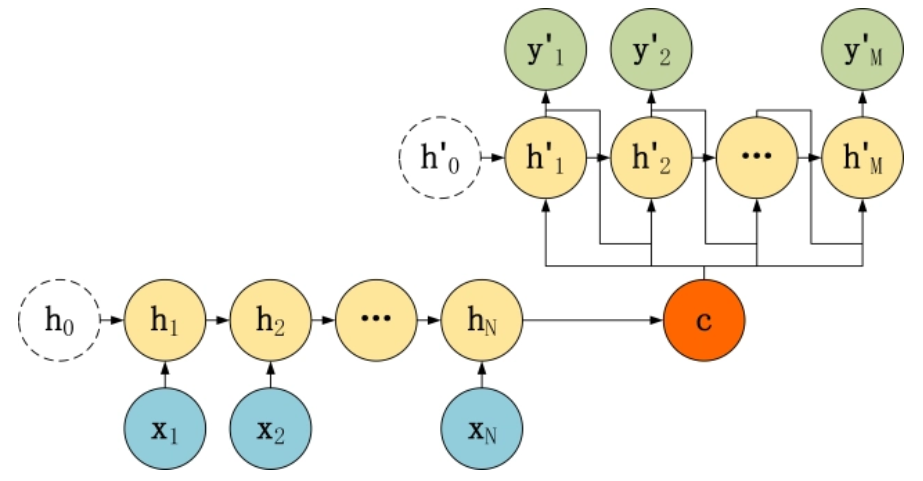
可以看到它在输入的部分多了上一个神经元的输出 y 。
即每一个神经元的输入包括:上一个神经元的隐藏层向量 h,上一个神经元的输出 y,上下文向量c。这里的解码器就和我们前面讲的公式![]() 完全吻合了。
完全吻合了。
对于第一个神经元的输入 y 0 ,通常是句子起始标志位的 embedding 向量。
通过计算:
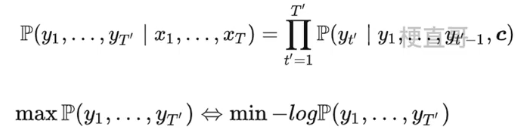
最大化输出序列的联合概率,等价于最小化负对数(其实就是交叉熵损失函数)。

模型训练时,根据最大似然估计,

老师在课上是这样引入的:
Sequence to Sequence Learning:两个循环神经网络组成。
红色部分和绿色部分都是RNN。
预测任务就是从一个序列到另一个序列。
第一个序列称之为原序列,第二个序列称为目标序列。两者长度可能不同。
网络编码器接收原序列作为输入序列,最终在 t 时刻生成隐藏状态,我们称之为 z,有时也称之为 c,他将作为序列的编码值,是一个固定长度的向量。
解码器网络的输入为,当前的输入 y t 和 z ,输出为 I ,I 将作为下一时刻的输入。这样就可以计算出最终 y1到yT的条件概率。
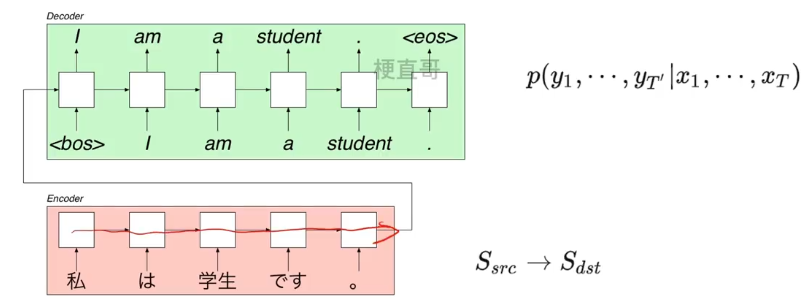
对于机器翻译而言,编码器依次处理源语言的每一个词,最终得到一个固定长的语义向量 z ,解码器以标志位bos(句子的开头)加上 z 作为输入,预测词的概率,选择概率最高的词 I ,I 和 z一起被送入下一时刻预测下一个词 am ,直到句子的结尾出现 EOS 标志位结束。
你可能会听到:
当需要进行不定长的序列输入输出处理时,既可以使用编码器-解码器的模型,也可以使用seq to seq的模型,有时会混用。
这两种模型是非常像的,只是RNN Cell是不同的,一个选用的是GRU,一个选用的是LSTM,本质都是两个RNN。

3、序列到序列模型代码实现
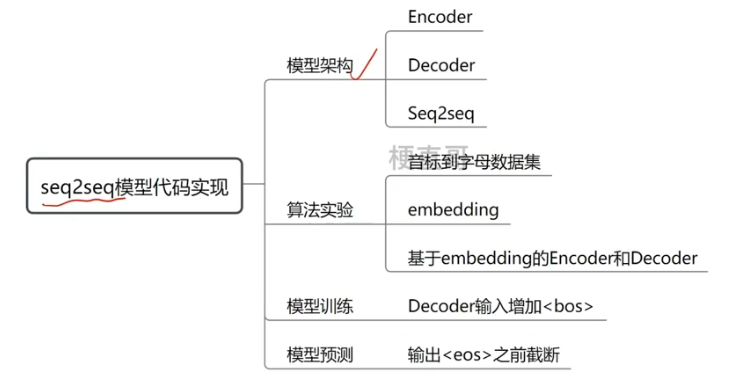
3.1、模型架构
3.1.1、 编码器
import torch
import torch.nn as nnclass Encoder(nn.Module):def __init__(self, input_size, hidden_size, num_layers):super(Encoder, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # LSTM模型def forward(self, x, hidden):x, hidden = self.lstm(x, hidden)return hidden # 只需要输出hidden3.1.2、 解码器
class Decoder(nn.Module):def __init__(self, output_size, hidden_size, num_layers):super(Decoder, self).__init__()self.lstm = nn.LSTM(output_size, hidden_size, num_layers) # LSTM模型self.linear = nn.Linear(hidden_size, output_size)def forward(self, x, hidden):x, state = self.lstm(x, hidden)x = self.linear(x)return x, state3.1.3、 seq2seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoderdef forward(self, encoder_inputs, decoder_inputs):return self.decoder(decoder_inputs, self.encoder(encoder_inputs))
3.2、序列到序列模型简单实现
3.2.1、 数据集准备
根据读音生成字母序列:
import random# 数据集生成
soundmark = ['ei', 'bi:', 'si:', 'di:', 'i:', 'ef', 'dʒi:', 'eit∫', 'ai', 'dʒei', 'kei', 'el', 'em', 'en', 'əu', 'pi:', 'kju:','ɑ:', 'es', 'ti:', 'ju:', 'vi:', 'd∧blju:', 'eks', 'wai', 'zi:']alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']t = 10000 #总条数
r = 0.9 #扰动项
seq_len = 6
src_tokens, tgt_tokens = [],[] #原始序列、目标序列列表for i in range(t):src, tgt = [],[]for j in range(seq_len):ind = random.randint(0,25)src.append(soundmark[ind])if random.random() < r:tgt.append(alphabet[ind])else:tgt.append(alphabet[random.randint(0,25)])src_tokens.append(src)tgt_tokens.append(tgt)
src_tokens[:2], tgt_tokens[:2]([['ei', 'si:', 'wai', 'ei', 'el', 'ef'],['em', 'ti:', 'ai', 'ai', 'ju:', 'ti:']],[['a', 'c', 'y', 'a', 'l', 'f'], ['m', 't', 'v', 'i', 'u', 't']])
from collections import Counter #计数类flatten = lambda l: [item for sublist in l for item in sublist] #展平数组# 构建词表
class Vocab:def __init__(self, tokens):self.tokens = tokens # 传入的tokens是二维列表self.token2index = {'<bos>': 0, '<eos>': 1} # 先存好特殊词元# 将词元按词频排序后生成列表self.token2index.update({token: index + 2for index, (token, freq) in enumerate(sorted(Counter(flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))}) #构建id到词元字典self.index2token = {index: token for token, index in self.token2index.items()}def __getitem__(self, query):# 单一索引if isinstance(query, (str, int)):if isinstance(query, str):return self.token2index.get(query, 0)elif isinstance(query, (int)):return self.index2token.get(query, '<unk>')# 数组索引elif isinstance(query, (list, tuple)):return [self.__getitem__(item) for item in query]def __len__(self):return len(self.index2token)from torch.utils.data import DataLoader, TensorDataset#实例化source和target词表
src_vocab, tgt_vocab = Vocab(src_tokens), Vocab(tgt_tokens)#增加结尾标识<eos>
src_data = torch.tensor([src_vocab[line + ['<eos>']] for line in src_tokens])
tgt_data = torch.tensor([tgt_vocab[line + ['<eos>']] for line in tgt_tokens])# 训练集和测试集比例8比2,batch_size = 16
train_size = int(len(src_data) * 0.8)
test_size = len(src_data) - train_size
batch_size = 16train_loader = DataLoader(TensorDataset(src_data[:train_size], tgt_data[:train_size]), batch_size=batch_size)
test_loader = DataLoader(TensorDataset(src_data[-test_size:], tgt_data[-test_size:]), batch_size=1)
3.2.2、 模型架构
Embedding
若使用简单的独热编码:

# 定义编码器
class Encoder(nn.Module):def __init__(self, vocab_size, ebd_size, hidden_size, num_layers):super().__init__()self.embedding = nn.Embedding(vocab_size, ebd_size) # 将token表示为embeddingself.gru = nn.GRU(ebd_size, hidden_size, num_layers=num_layers)def forward(self, encoder_inputs):# encoder_inputs从(batch_size, seq_len)变成(batch_size, seq_len, emb_size)再调整为(seq_len, batch_size, emb_size)encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)output, hidden = self.gru(encoder_inputs)# hidden 的形状为 (num_layers, batch_size, hidden_size)# 最后时刻的最后一个隐层的输出的隐状态即为上下文向量return hidden# 定义解码器
class Decoder(nn.Module):def __init__(self, vocab_size, ebd_size, hidden_size, num_layers):super().__init__()self.embedding = nn.Embedding(vocab_size, ebd_size)# 拼接维度ebd_size + hidden_sizeself.gru = nn.GRU(ebd_size + hidden_size, hidden_size, num_layers=num_layers)self.linear = nn.Linear(hidden_size, vocab_size)def forward(self, decoder_inputs, encoder_states):'''decoder_inputs 为目标序列偏移一位的结果, 由初始形状: (batch_size, seq_len)变为(batch_size, seq_len)再调整为(batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)'''decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2)context = encoder_states[-1] # 上下文向量取编码器的最后一个隐层的输出# context 初始形状为 (batch_size, hidden_size),为下一步连接,需repeat为(seq_len, batch_size, hidden_size)形式 context = context.repeat(decoder_inputs.shape[0], 1, 1)output, hidden = self.gru(torch.cat((decoder_inputs, context), -1), encoder_states)# logits 的形状为 (seq_len, batch_size, vocab_size)logits = self.linear(output)return logits, hidden# seq2seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoderdef forward(self, encoder_inputs, decoder_inputs):return self.decoder(decoder_inputs, self.encoder(encoder_inputs))ebd= nn.Embedding(26, 26)
ebd(train_loader.dataset[0][0])tensor([[ 0.4887, -0.6628, -1.8760, -0.1039, -0.3671, -0.0545, 0.8259, 1.7120,1.0536, 0.1105, -2.2157, 0.1826, -0.9814, 0.6896, 1.9313, -0.4203,0.4704, -0.3540, -2.5149, 1.6691, 0.7668, -1.2259, -0.0838, -0.8457,-0.7388, 0.7919],[-0.3271, -0.9200, 1.4683, -1.0719, -0.9968, -0.5890, 0.0442, -0.4679,-0.6279, -0.7677, -1.8178, 0.0872, 0.6651, -1.2833, -0.5265, -0.2333,0.1615, -0.1019, 0.6508, 0.3404, -1.2946, 0.1573, -0.7420, -2.0256,1.6652, 0.7278],[-0.3090, -0.6615, -0.2852, -0.4307, -1.7267, -1.2491, 1.1952, -1.7489,0.1471, 1.2763, -0.2151, -0.2278, 0.4850, 0.6540, 1.8243, 1.2390,0.2089, -1.3072, 0.2947, 0.3472, 1.1848, -1.0279, -0.8024, 0.1165,-0.0939, 0.0841],[ 0.4887, -0.6628, -1.8760, -0.1039, -0.3671, -0.0545, 0.8259, 1.7120,1.0536, 0.1105, -2.2157, 0.1826, -0.9814, 0.6896, 1.9313, -0.4203,0.4704, -0.3540, -2.5149, 1.6691, 0.7668, -1.2259, -0.0838, -0.8457,-0.7388, 0.7919],[ 0.2450, 0.2942, -0.6478, -1.1449, 0.8370, 0.2286, 1.2670, -0.2990,-1.2017, 1.9527, 0.2588, -0.7598, 1.4220, -1.9788, -1.0234, 0.5749,-0.3605, -0.5907, 1.6407, 0.2505, -0.4432, -0.4119, 0.1512, -0.5205,-2.3585, 1.8493],[-0.6333, 0.7932, 0.2204, 0.8744, 1.3206, -1.3566, -1.3790, -1.0874,1.1842, -0.2754, -0.7049, -1.1859, 0.9867, 1.7082, -0.3269, -0.6141,0.4234, 0.2091, -0.7511, 1.0062, 0.3373, -0.3307, -1.2813, 0.2178,-0.3695, -0.1869],[ 1.6062, -0.9316, 0.7249, 0.1260, 1.2153, 0.7596, -1.4848, 0.4740,-0.1286, 0.7063, 0.9402, -0.0867, -0.2397, -1.2286, 2.3666, -1.9981,0.4441, -0.3359, -2.6526, -1.9506, -0.4288, 0.7680, 1.0715, 0.0294,-0.0815, -1.4052]], grad_fn=<EmbeddingBackward0>)
3.2.3、 模型训练
from tqdm import *
import matplotlib.pyplot as plt# 设置超参数
lr = 0.001
num_epochs = 20
hidden_size = 128# 建立模型
encoder = Encoder(len(src_vocab), len(src_vocab), hidden_size, num_layers=2)
decoder = Decoder(len(tgt_vocab), len(tgt_vocab), hidden_size, num_layers=2)
model = Seq2Seq(encoder, decoder)# 交叉熵损失及adam优化器
criterion = nn.CrossEntropyLoss(reduction='none')
optimizer = torch.optim.Adam(model.parameters(), lr=lr)# 记录损失变化
loss_history = []#开始训练
model.train()
for epoch in tqdm(range(num_epochs)):for encoder_inputs, decoder_targets in train_loader:encoder_inputs, decoder_targets = encoder_inputs, decoder_targets# 偏移一位作为decoder的输入# decoder的输入第一位是<bos>bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1)decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)# pred的形状为 (seq_len, batch_size, vocab_size)pred, _ = model(encoder_inputs, decoder_inputs)# decoder_targets 的形状为 (batch_size, seq_len),我们需要改变pred的形状以保证它能够正确输入# loss 的形状为 (batch_size, seq_len),其中的每个元素都代表了一个词元的损失loss = criterion(pred.permute(1, 2, 0), decoder_targets).mean()# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()loss_history.append(loss.item())100%|██████████| 20/20 [03:35<00:00, 10.79s/it]
plt.plot(loss_history)
plt.ylabel('train loss')
plt.show()
3.2.4、 模型验证
model.eval()
translation_results = []correct = 0
error = 0
# 因为batch_size是1,所以每次取出来的都是单个句子
for src_seq, tgt_seq in test_loader:encoder_inputs = src_seqhidden = model.encoder(encoder_inputs)pred_seq = [tgt_vocab['<bos>']]for _ in range(8):# 一步步输出,decoder的输入的形状为(batch_size, seq_len)=(1,1)decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1)# pred形状为 (seq_len, batch_size, vocab_size) = (1, 1, vocab_size)pred, hidden = model.decoder(decoder_inputs, hidden)next_token_index = pred.squeeze().argmax().item()if next_token_index == tgt_vocab['<eos>']:breakpred_seq.append(next_token_index)# 去掉开头的<bos>pred_seq = tgt_vocab[pred_seq[1:]]# 因为tgt_seq的形状为(1, seq_len),我们需要将其转化成(seq_len, )的形状tgt_seq = tgt_seq.squeeze().tolist()# 需要注意在<eos>之前截断if tgt_vocab['<eos>'] in tgt_seq:eos_idx = tgt_seq.index(tgt_vocab['<eos>'])tgt_seq = tgt_vocab[tgt_seq[:eos_idx]]else:tgt_seq = tgt_vocab[tgt_seq]translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))for i in range(len(tgt_seq)):if i >= len(pred_seq) or pred_seq[i] != tgt_seq[i]:error += 1else:correct += 1print(correct/(correct+error))0.507
translation_results
4、束搜索算法
束搜索 (Beam Search) 是一种在自然语言处理和计算机视觉中都经常使用的搜索算法。它用于在大量可能的候选解中查找最优解。
束搜索通过保留一个有限数量的候选解来减少搜索空间的大小。
它的基本思想是,在每一步搜索中,保留当前状态的最优的几个候选解(称为束)。每次进行扩展时,都只考虑束中的候选解。这样,在后续的搜索过程中,束中的候选解会越来越接近最优解。
束搜索在 NLP 任务中被广泛使用,比如机器翻译、语音识别、语音合成等。
4.1、解码过程的挑战
解码器输出需要基于历史生成结果的条件概率 。
。
4.2、贪心搜索
从词汇表V中获取条件概率最高的标记。
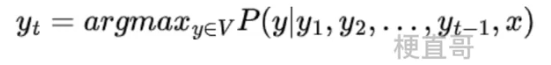 。
。
4.3、束搜索
Beam Search:保留多种可能序列。

举例说明:
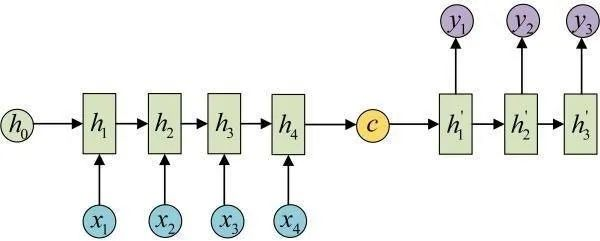
假定一个Seq2Seq过程如上图所示,束搜索一般应用于Decoder过程的预测阶段。
假设词表大小为3,内容分别为a、b、c,为了便于理解,下面用一个概率图模型来表示它们之间的关系。

以上图为例,这里假设beam size为2,则具体流程为:
-
生成第1个词,从词表中选择概率最大的2个词。以图中的概率数据,那么当前的2个序列就是a和b。
-
生成第2个词,我们将当前序列a和b,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ba bb bc,计算每个序列的得分并选择得分最高2个列,作为新的当前序列,得到aa和ac。
-
生成第3个词,再次进行组合,得到6个序列aaa aab aac aca acb acc,再次计算序列得分,得到acb和aaa。
4.4、算法流程
适当总结一下示例中的过程,束搜索的算法流程如下:
-
初始化:设置束的大小 beam size,并将起始状态加入束中。
-
扩展:对束中每个状态进行扩展,生成所有可能的下一步状态。
-
评估:对于每个扩展出的状态,计算其可能性评分。
-
更新:将所有扩展出的状态按照评分从大到小排序,保留评分最大的 beam size 个状态。
-
重复步骤2-4,直到搜索到终止状态或者达到最大搜索步骤。
-
输出:束中的最优状态即为最终的最优解。
束搜索在每一步只考虑当前状态最优的几个候选解,这样可以大大减少搜索空间的大小,提高算法的执行效率。并且束搜索会不断更新束中的候选解,使得束中的解越来越接近最优解。
在确定束的大小合适时束搜索是一种很有效的算法,能很好的解决Seq2Seq等自然语言处理问题。束搜索其实就是一种贪心算法的扩展版,理论上设置 beam size=1 就是贪心算法,束搜索通过保留多个候选解来尽可能避免陷入局部最优。
4.4、改进策略

4.5、优缺点

束搜索主要起到以下作用:
-
防止爆炸式搜索:在使用解码器生成目标序列时,需要对所有可能的输出序列进行打分。如果直接穷举搜索所有可能的序列,将会有很高的时间和空间复杂度。束搜索通过只考虑当前搜索状态的最优几个候选解,来减少搜索空间大小。
-
提高生成质量:更加注重当前搜索状态的最优候选解,这样更可能生成更加合理的输出序列。
-
防止生成错误的序列:保留一个有限数量的候选解能更好地避免不符合语法或语义的序列被选中。同时束搜索会在每次扩展时选择具有最高可能性的解,最大限度减少了错误解的生成。
总结起来就是一句话,本质上就是在尽可能平衡搜索质量和效率之间的关系。
5、机器翻译代码实现
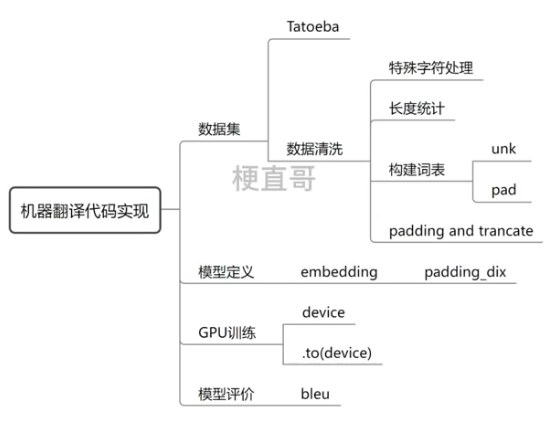
1、数据准备
1.1、数据集引入
import torch
import torch.nn as nn# 直接读取
with open('data/有英语-中文普通话对应句 - 2023-02-18.tsv', encoding='utf-8') as f:lines = f.readlines()
print(lines[:5])# 只读取有效内容
with open('data/有英语-中文普通话对应句 - 2023-02-18.tsv', encoding='utf-8') as f:data = []for line in f.readlines():data.append(line.strip().split('\t')[1]+'\t'+line.strip().split('\t')[3])
print(data[:5])# 找出特殊字符
import re
import stringcontent = ''.join(data)
special_char = re.sub(r'[\u4e00-\u9fa5]', ' ', content) # 匹配中文,将中文替换掉print(set(special_char) - set(string.ascii_letters) - set(string.digits))
1.2、数据清洗
def cleaning(data):for i in range(len(data)):# 替换特殊字符data[i] = data[i].replace('\u200b', '')data[i] = data[i].replace('\u200f', '')data[i] = data[i].replace('\xad', '')data[i] = data[i].replace('\u3000', ' ')eng_mark = [',', '.', '!', '?'] # 因为标点前加空格for mark in eng_mark:data[i] = data[i].replace(mark, ' '+mark)data[i] = data[i].lower() # 统一替换为小写return datacleaning(data)def tokenize(data):# 分别存储源语言和目标语言的词元src_tokens, tgt_tokens = [], []for line in data:pair = line.split('\t')src = pair[0].split(' ')tgt = list(pair[1])src_tokens.append(src)tgt_tokens.append(tgt)return src_tokens, tgt_tokenssrc_tokens, tgt_tokens = tokenize(data)
print("src:", src_tokens[:6])
print("tgt:", tgt_tokens[:6])import numpy as np
def statistics(tokens):max_len = 80 #只统计长度80以下的len_list = range(max_len) # 长度值freq_list = np.zeros(max_len) # 频率值for token in tokens:if len(token) < max_len:freq_list[len_list.index(len(token))] += 1return len_list, freq_lists1, s2 = statistics(src_tokens)
t1, t2 = statistics(tgt_tokens)import matplotlib.pyplot as plt
plt.plot(s1,s2)
plt.plot(t1,t2)[<matplotlib.lines.Line2D at 0x7fc43528fd90>]

1.3、构建词表
from collections import Counter #计数类flatten = lambda l: [item for sublist in l for item in sublist] #展平数组# 构建词表
class Vocab:def __init__(self, tokens):self.tokens = tokens # 传入的tokens是二维列表self.token2index = {'<bos>': 0, '<eos>': 1, '<unk>':2, '<pad>':3} # 先存好特殊词元# 将词元按词频排序后生成列表self.token2index.update({token: index + 4for index, (token, freq) in enumerate(sorted(Counter(flatten(self.tokens)).items(), key=lambda x: x[1], reverse=True))}) #构建id到词元字典self.index2token = {index: token for token, index in self.token2index.items()}def __getitem__(self, query):# 单一索引if isinstance(query, (str, int)):if isinstance(query, str):return self.token2index.get(query, 0)elif isinstance(query, (int)):return self.index2token.get(query, '<unk>')# 数组索引elif isinstance(query, (list, tuple)):return [self.__getitem__(item) for item in query]def __len__(self):return len(self.index2token)1.4、构建数据集
from torch.utils.data import DataLoader, TensorDatasetseq_len = 48 # 序列最大长度# 对数据按照最大长度进行截断和填充
def padding(tokens, seq_len):# 该函数针对单个句子进行处理# 传入的句子是词元形式return tokens[:seq_len] if len(tokens) > seq_len else tokens + ['<pad>'] * (seq_len - len(tokens))#实例化source和target词表
src_vocab, tgt_vocab = Vocab(src_tokens), Vocab(tgt_tokens)#增加结尾标识<eos>
src_data = torch.tensor([src_vocab[padding(line + ['<eos>'], seq_len)] for line in src_tokens])
tgt_data = torch.tensor([tgt_vocab[padding(line + ['<eos>'], seq_len)] for line in tgt_tokens])# 训练集和测试集比例8比2,batch_size = 16
train_size = int(len(src_data) * 0.8)
test_size = len(src_data) - train_size
batch_size = 256train_loader = DataLoader(TensorDataset(src_data[:train_size], tgt_data[:train_size]), batch_size=batch_size)
test_loader = DataLoader(TensorDataset(src_data[-test_size:], tgt_data[-test_size:]), batch_size=1)
2、模型训练
2.1、模型定义
# 定义编码器
class Encoder(nn.Module):def __init__(self, vocab_size, ebd_size, hidden_size, num_layers):super().__init__()self.embedding = nn.Embedding(vocab_size, ebd_size, padding_idx=3) # 将token表示为embeddingself.gru = nn.GRU(ebd_size, hidden_size, num_layers=num_layers)def forward(self, encoder_inputs):# encoder_inputs从(batch_size, seq_len)变成(batch_size, seq_len, emb_size)再调整为(seq_len, batch_size, emb_size)encoder_inputs = self.embedding(encoder_inputs).permute(1, 0, 2)output, hidden = self.gru(encoder_inputs)# hidden 的形状为 (num_layers, batch_size, hidden_size)# 最后时刻的最后一个隐层的输出的隐状态即为上下文向量return hidden# 定义解码器
class Decoder(nn.Module):def __init__(self, vocab_size, ebd_size, hidden_size, num_layers):super().__init__()self.embedding = nn.Embedding(vocab_size, ebd_size, padding_idx=3)# 拼接维度ebd_size + hidden_sizeself.gru = nn.GRU(ebd_size + hidden_size, hidden_size, num_layers=num_layers)self.linear = nn.Linear(hidden_size, vocab_size)def forward(self, decoder_inputs, encoder_states):'''decoder_inputs 为目标序列偏移一位的结果, 由初始形状: (batch_size, seq_len)变为(batch_size, seq_len)再调整为(batch_size, seq_len, emb_size) -> (seq_len, batch_size, emb_size)'''decoder_inputs = self.embedding(decoder_inputs).permute(1, 0, 2)context = encoder_states[-1] # 上下文向量取编码器的最后一个隐层的输出# context 初始形状为 (batch_size, hidden_size),为下一步连接,需repeat为(seq_len, batch_size, hidden_size)形式 context = context.repeat(decoder_inputs.shape[0], 1, 1)output, hidden = self.gru(torch.cat((decoder_inputs, context), -1), encoder_states)# logits 的形状为 (seq_len, batch_size, vocab_size)logits = self.linear(output)return logits, hidden# seq2seq模型
class Seq2Seq(nn.Module):def __init__(self, encoder, decoder):super().__init__()self.encoder = encoderself.decoder = decoderdef forward(self, encoder_inputs, decoder_inputs):return self.decoder(decoder_inputs, self.encoder(encoder_inputs))2.2、模型训练
from tqdm import *
import matplotlib.pyplot as plt# 设置是否使用GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 设置超参数
lr = 0.001
num_epochs = 50
hidden_size = 256# 建立模型
encoder = Encoder(len(src_vocab), len(src_vocab), hidden_size, num_layers=2)
decoder = Decoder(len(tgt_vocab), len(tgt_vocab), hidden_size, num_layers=2)
model = Seq2Seq(encoder, decoder)
model.to(device)# 交叉熵损失及adam优化器
criterion = nn.CrossEntropyLoss(reduction='none', ignore_index =3)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)# 记录损失变化
loss_history = []#开始训练
model.train()
for epoch in tqdm(range(num_epochs)):for encoder_inputs, decoder_targets in train_loader:encoder_inputs, decoder_targets = encoder_inputs.to(device), decoder_targets.to(device)# 偏移一位作为decoder的输入# decoder的输入第一位是<bos>bos_column = torch.tensor([tgt_vocab['<bos>']] * decoder_targets.shape[0]).reshape(-1, 1).to(device)decoder_inputs = torch.cat((bos_column, decoder_targets[:, :-1]), dim=1)# pred的形状为 (seq_len, batch_size, vocab_size)pred, _ = model(encoder_inputs, decoder_inputs)# decoder_targets 的形状为 (batch_size, seq_len),我们需要改变pred的形状以保证它能够正确输入# loss 的形状为 (batch_size, seq_len),其中的每个元素都代表了一个词元的损失loss = criterion(pred.permute(1, 2, 0), decoder_targets).mean()# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()loss_history.append(loss.item())100%|██████████| 50/50 [1:36:32<00:00, 115.86s/it]
plt.plot(loss_history)
plt.ylabel('train loss')
plt.show()
2.3、模型保存
# 保存模型
torch.save(model.state_dict(), 'seq2seq_params.pt')
3、模型评估
3.1、bleu指标

import math
# 计算bleu分数
def bleu(label, pred, n):score = math.exp(min(0, 1 - len(label) / len(pred)))for k in range(1, n + 1):num_matches = 0hashtable = Counter([' '.join(label[i:i + k]) for i in range(len(label) - k + 1)])for i in range(len(pred) - k + 1):ngram = ' '.join(pred[i:i + k])if ngram in hashtable and hashtable[ngram] > 0:num_matches += 1hashtable[ngram] -= 1score *= pow(num_matches / (len(pred) - k + 1), pow(0.5, k))return score3.2、测试集评估
model.eval()
translation_results = []
bleu_scores = []
# 因为batch_size是1,所以每次取出来的都是单个句子
for src_seq, tgt_seq in test_loader:encoder_inputs = src_seqhidden = model.encoder(encoder_inputs.to(device))pred_seq = [tgt_vocab['<bos>']]for _ in range(8):# 一步步输出,decoder的输入的形状为(batch_size, seq_len)=(1,1)decoder_inputs = torch.tensor(pred_seq[-1]).reshape(1, 1).to(device)# pred形状为 (seq_len, batch_size, vocab_size) = (1, 1, vocab_size)pred, hidden = model.decoder(decoder_inputs, hidden)next_token_index = pred.squeeze().argmax().item()if next_token_index == tgt_vocab['<eos>']:breakpred_seq.append(next_token_index)# 去掉开头的<bos>pred_seq = tgt_vocab[pred_seq[1:]]# 因为tgt_seq的形状为(1, seq_len),我们需要将其转化成(seq_len, )的形状tgt_seq = tgt_seq.squeeze().tolist()# 需要注意在<eos>之前截断if tgt_vocab['<eos>'] in tgt_seq:eos_idx = tgt_seq.index(tgt_vocab['<eos>'])tgt_seq = tgt_vocab[tgt_seq[:eos_idx]]else:tgt_seq = tgt_vocab[tgt_seq]translation_results.append((' '.join(tgt_seq), ' '.join(pred_seq)))bleu_scores.append(bleu(tgt_seq, pred_seq, n=2))print(sum(bleu_scores) / test_size)0.16821586571116853
3.3、模型效果
translation_results
参考
Deep-Learning-Code: 《深度学习必修课:进击算法工程师》配套代码 - Gitee.com
10-5 编解码器网络
10-7 束搜索