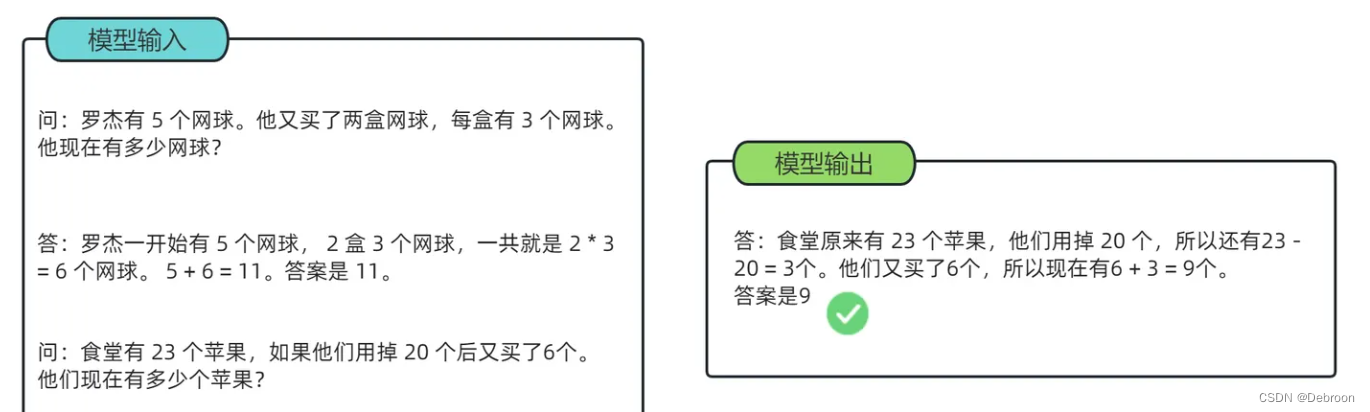
作者:黄晓萌(学仁)
背景
Job 表示短周期的作业,定时 Job 表示按照预定的时间运行Job,或者按照某一频率周期性的运行 Job。比如:

许多传统企业使用 Linux 自带的 crontab 来做定时任务的方案,该方案非常简单,适合做主机上的运维工作,比如定时清理日志、周期性做健康检查。随着信息化时代的高速发展,业务变得越来越复杂,很多场景都需要定时任务,但是 crontab 方案存在高可用问题,不适合应用在业务应用上。
在云原生时代,K8s CronJob 设计了一套高可用的定时任务解决方案,保障了业务的稳定。但是把 K8s CronJob 应用在生产上,发现定时任务真的出问题的时候排查起来很麻烦,于是越来越多用户对定时任务的可观测有了更多的诉求,阿里云也推出了自己的云原生定时任务解决方案,可以托管原生 K8s CronJob,提供可报警、可观测、可运维等能力,帮助企业提效。
Linux Crontab 方案面临的问题
什么是 Crontab
Crontab 是 Linux 系统中的一个服务,用于创建、编辑和管理定时任务。通过 crontab 命令,用户可以设置系统在指定时间自动执行某个命令或脚本。
Crontab 命令的语法分为两部分,分别是时间表达式和命令。时间表达式如下:
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
命令常用来执行某个脚本,举个例子:
- 每隔 5 分钟执行 hello.sh:*/5 * * * * sh /root/script/hello.sh
- 每天早上 6 点半执行 world.py: 30 6 * * * python /root/script/world.py
Crontab 的工作原理
Crontab 由一个名为"Crond"的守护进程负责调度任务,当 Crond 启动的时候,就会从配置文件(路径在 /var/spool/cron 下)加载所有的定时任务。当执行 crontab 命令的时候,会动态的添加新的定时任务,并加入到配置文件中。Crontab 每次执行任务,都会产生执行记录,目录在 /var/log/cron 下。
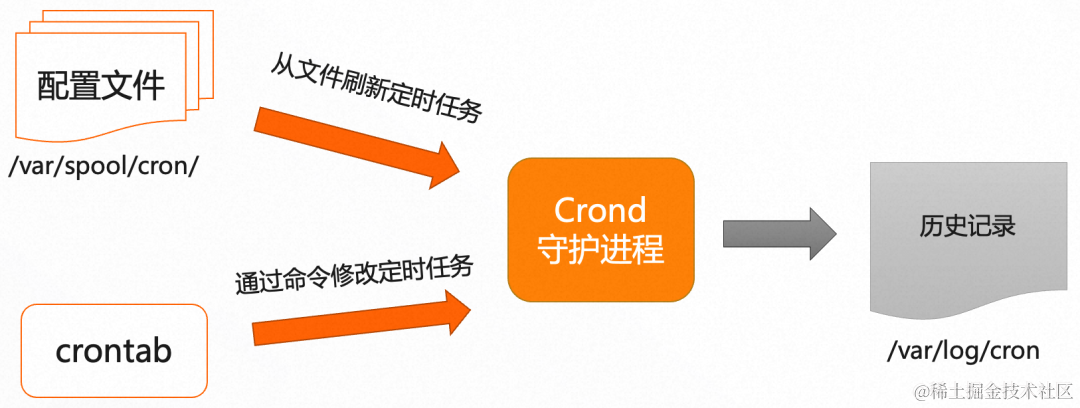
Crontab 的痛点问题
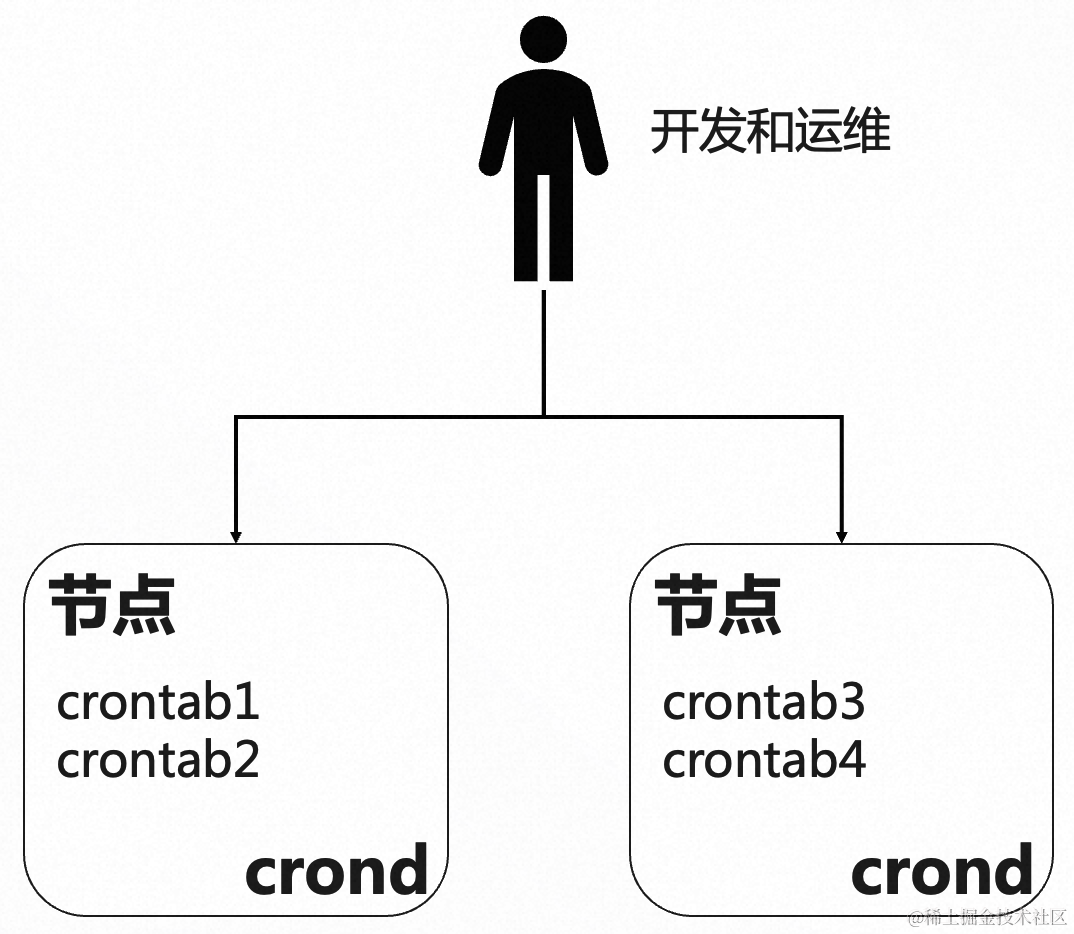
使用 crontab 主要有如下痛点:
- 无高可用: 为了保证业务幂等执行,需要在不同的机器配置不同的 crontab 任务。crontab 只能调度本机器上的定时任务,如果某一个机器挂了,那上面的定时任务也都不会执行了,有稳定性风险。
- 无自动负载均衡: 不同的脚本放在不同的机器上,需要手动负载均衡,如果脚本比较多,运维代价很高。
- 无权限隔离: 一般企业生产的机器只有运维才能登陆,但是开发要新增/修改脚本和定时任务,也需要登录到生产的机器上,没法做到权限隔离。
云原生 K8s CronJob 方案的优势
什么是 K8s CronJob
Job 是 K8s 中的一种资源,用来处理短周期的 Pod,相当于一次性任务,跑完就会把 Pod 销毁,不会一直占用资源,可以节省成本,提高资源利用率。CronJob 也是 K8s 中的资源,用来周期性的重复调度 Job。
下面是一个 CronJob 的示例,每隔 5 分钟调度脚本 edas/schedulerx-job.sh:
apiVersion: batch/v1
kind: CronJob
metadata:name: hello
spec:schedule: "*/5 * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busybox:1.28imagePullPolicy: IfNotPresentcommand: ["/bin/sh", "/root/script/edas/schedulerx-job.sh"]restartPolicy: OnFailure
K8s CronJob 的优势
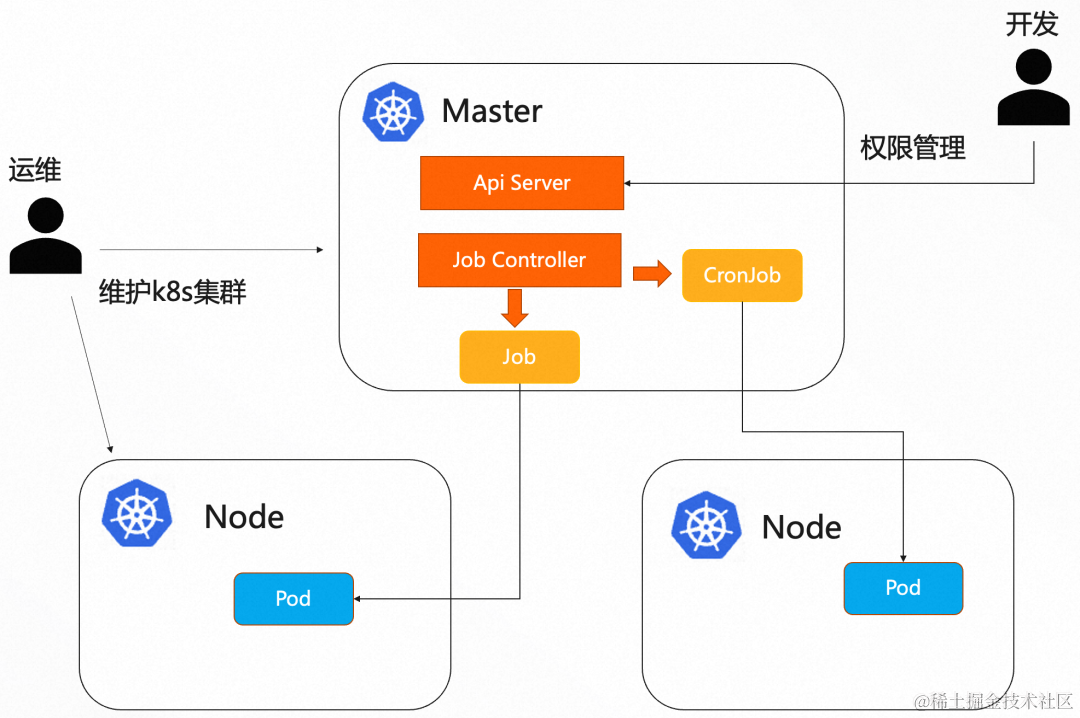
与单纯使用 Crontab 相比,使用 K8s CronJob 带来了如下优势:
- 高可用: K8s 会保证集群的高可用,如集群中有节点挂了,都不会影响定时任务的调度。
- 自动负载均衡: Pod 默认选择负载最低的 node 执行,支持 NodeSelector 和亲和性等多种负载均衡策略。
- 权限隔离: 只有运维可以登录 master 和 worker 节点,开发通过管控或者 ApiServer 来创建和更新 CronJob,并且支持命名空间隔离,RBAC 权限管理。
K8s CronJob 的进阶能力
Linux Crontab 只能周期性调度本机的脚本,功能比较简单,K8s 定时任务支持更多的进阶能力:
- 在 Job 资源上
-
- 并行执行: 通常一个 Job 只启动一个 Pod,可以通过配置 spec.completions 参数,来决定一个 Job 要执行多少个 Pod。
- 索引任务: 并行执行通常需要和索引任务结合使用,当配置 .spec.completionMode=“Indexed” 时,这个 Job 就是一个索引任务,每个 Pod 会获得一个不同的索引值,介于 0 和 .spec.completions-1 之间,这样就可以让不同的 Pod 根据索引值处理不同的数据。
- 并行限流: 并行执行的时候,通常还需要做限流,可以配置 .spec.parallelism 参数,来控制一个 Job 最多同时跑多少个 Pod。
- 失败自动重试: 可以配置 .spec.backoffLimit,来设置 Job 失败重试次数。
- 超时: 可以配置 .spec.activeDeadlineSeconds,来设置 Job 超时的时间。
- 在 CronJob 资源上
-
- 时区: 可以通过设置 .spec.timeZone 参数,决定 CronJob 按照哪个时区的时间来调度任务。
- 并发性规则: 当一个 Job 还在执行,下次调度时间到了,是否执行新的 Job,可以通过 .spec.concurrencyPolicy 来配置,取值为 Allow/Forbid/Replace。
- 任务历史限制: 可以通过配置 .spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit 来决定保留多少成功和失败的 Job。
阿里云 K8s CronJob 提效新模式
阿里云分布式任务调度 SchedulerX 和云原生结合,推出可视化 K8s Job 解决方案。针对脚本使用者,屏蔽了容器服务的细节,不用构建镜像就可以让不熟悉容器的同学(比如运维和运营同学)玩转 K8s Job,受益容器服务带来的降本增效福利。针对容器使用者,SchedulerX 不但完全兼容原生的 K8s Job,还能支持历史执行记录、日志服务、重跑任务、报警监控、可视化任务编排等能力,为企业级应用保驾护航。
快速迁移 Crontab 脚本任务
通过上面的章节,我们知道 Linux Crontab 存在许多问题,迁移到 K8s CronJob 可以带来很多好处,但是要从 crontab 迁移到 K8s CronJob 还是挺麻烦的,这里以通过 python 脚本访问数据库为例,来对比两种方案的差异。
K8s 原生解决方案
- 将 crontab 脚本拷贝到本地,取名为 edas/schedulerx-job.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-import MySQLdb# 打开数据库连接
db = MySQLdb.connect("localhost", "testuser", "test123", "TESTDB", charset='utf8' )# 使用cursor()方法获取操作游标
cursor = db.cursor()# SQL 查询语句
sql = "SELECT * FROM EMPLOYEE \
WHERE INCOME > %s" % (1000)
try:# 执行SQL语句cursor.execute(sql)# 获取所有记录列表results = cursor.fetchall()for row in results:fname = row[0]lname = row[1]age = row[2]sex = row[3]income = row[4]# 打印结果print "fname=%s,lname=%s,age=%s,sex=%s,income=%s" % \(fname, lname, age, sex, income )except:print "Error: unable to fetch data"# 关闭数据库连接
db.close()
- 在本地编写 Dockerfile
FROM python:3WORKDIR /usr/src/appCOPY requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txtCOPY edas/schedulerx-job.py /root/edas/schedulerx-job.pyCMD [ "python", "/root/edas/schedulerx-job.py" ]
- 制作 docker 镜像,推到镜像仓库中
docker build -t registry.cn-beijing.aliyuncs.com/demo/edas/schedulerx-job:1.0.0 .
docker push registry.cn-beijing.aliyuncs.com/demo/edas/schedulerx-job:1.0.0
- 编写 K8s CronJob 的 YAML 文件,image 选择第 3 步制作的镜像,command 的命令为执行脚本
apiVersion: batch/v1
kind: CronJob
metadata:name: demo-python
spec:schedule: "*/5 * * * *"jobTemplate:spec:template:spec:containers:- name: demo-pythonimage: registry.cn-beijing.aliyuncs.com/demo/edas/schedulerx-job:1.0.0imagePullPolicy: IfNotPresentcommand: ["python", "/root/edas/schedulerx-job.py"]restartPolicy: OnFailure
我们看到把一个 contab 迁移到 K8s CronJob,就需要这么多步骤,如果之后要修改脚本,还需要重新构建镜像和重新发布 K8s CronJob,这里先不计算开始之前的学习成本,单纯从使用角度来看,有着较高的上手成本。
阿里云解决方案
阿里任务调度 SchedulerX 结合云原生技术,提出了一套可视化的脚本任务解决方案,通过任务调度系统来管理脚本,直接在线编写脚本,不需要构建镜像,就可以将脚本以 Pod 的方式在用户的 K8s 集群当中运行起来,使用非常方便,如下图:
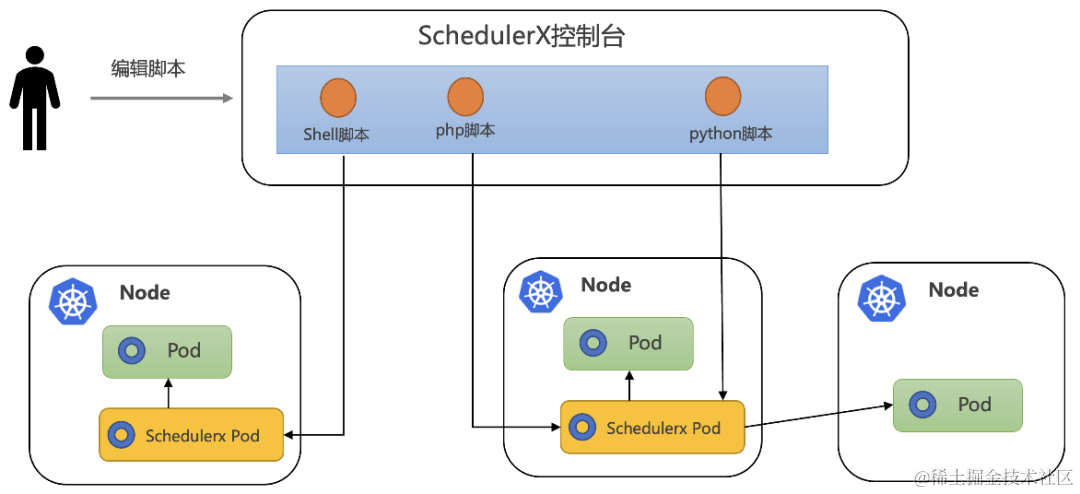
-
在你的 K8s 集群中部署一个 schedulerx-deployment(只需要装一次),注册到 SchedulerX 上来,让 SchedulerX 可以调度你的 K8s 上的 Pod
-
在 SchedulerX 任务管理新建一个 K8s 任务,资源类型选择 Python-Script(当前支持 shell/python/php/nodejs 四种脚本类型),把脚本拷贝进去,然后配置定时表达式
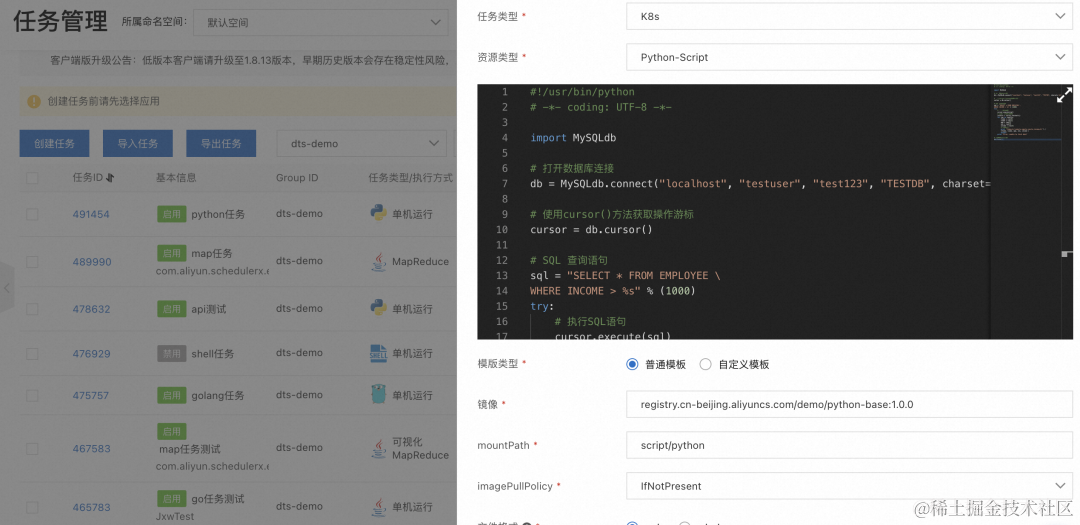
这里的镜像只需要构建一个基础镜像即可,如果脚本内容有修改,只要依赖的库没有改变,就不需要重新构建镜像。
- 等调度时间到了,或者通过控制台手动运行一次,可以在 K8s 集群中看到以 Pod 的方式运行脚本,Pod 名称为 schedulerx-python-{JobId}

下面通过一个表格更方便的看到两个方案的差异:
| K8s原生解决方案 | 阿里云解决方案 | |
|---|---|---|
| 脚本管理 | 不支持 | 支持,通过SchedulerX控制台可以进行脚本管理 |
| 开发效率 | 慢,每次修改脚本都需要重新构建镜像 | 快,在线修改脚本,不需要构建镜像,自动部署 |
| 学习成本 | 高,需要学习Docker和K8s等容器相关知识 | 低,不需要容器相关知识,会写脚本就行 |
增强原生 K8s CronJob
SchedulerX 不但能够快速开发 K8s 脚本任务,屏蔽容器服务的细节,给不熟悉容器服务的同学带来福音,同时还能托管原生 K8s Job/CronJob,增强可运维可观测等能力。
K8s 原生解决方案
以官方提供的 CronJob 为例。
- 编写 hello.yaml
apiVersion: batch/v1
kind: CronJob
metadata:name: hello
spec:schedule: "* * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: perl:5.34command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(100)"]restartPolicy: OnFailure
- 在 K8s 集群中运行该 CronJob,查看 pod 历史记录和日志
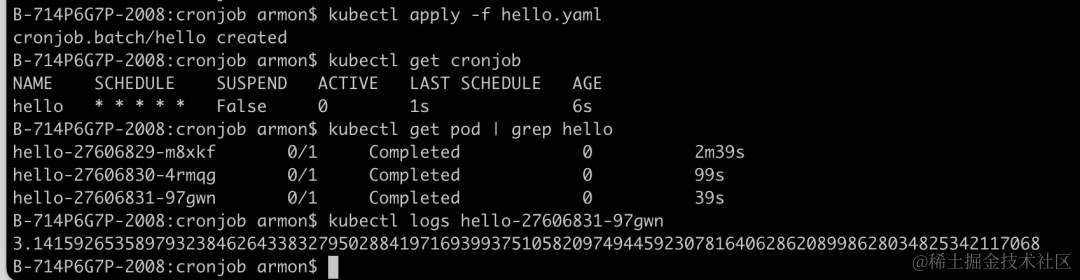
发现原生的 CronJob 只能查看最近 3 条执行记录和日志,想要查看更久之前的记录无法看到,这在业务出现问题想排查的时候就变得尤为困难。虽然可以通过配置 .spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit 来保留更多的 Pod 历史记录,但是保留更多的 Pod,就会更加占用 K8s 集群的资源,因为 Job 已经跑完了,只是为了查看日志保留更多历史记录,成本太高了。
阿里云解决方案
阿里任务调度 SchedulerX 可以托管原生 K8s Job/CronJob,方便移植,使用 SchedulerX 托管,可以具有更强的可运维可观测能力,比如任务重跑、日志服务、报警监控等。
- 新建 K8s 任务,任务类型选择 K8s,资源类型选择 Job-YAML,打印 bpi(-1)
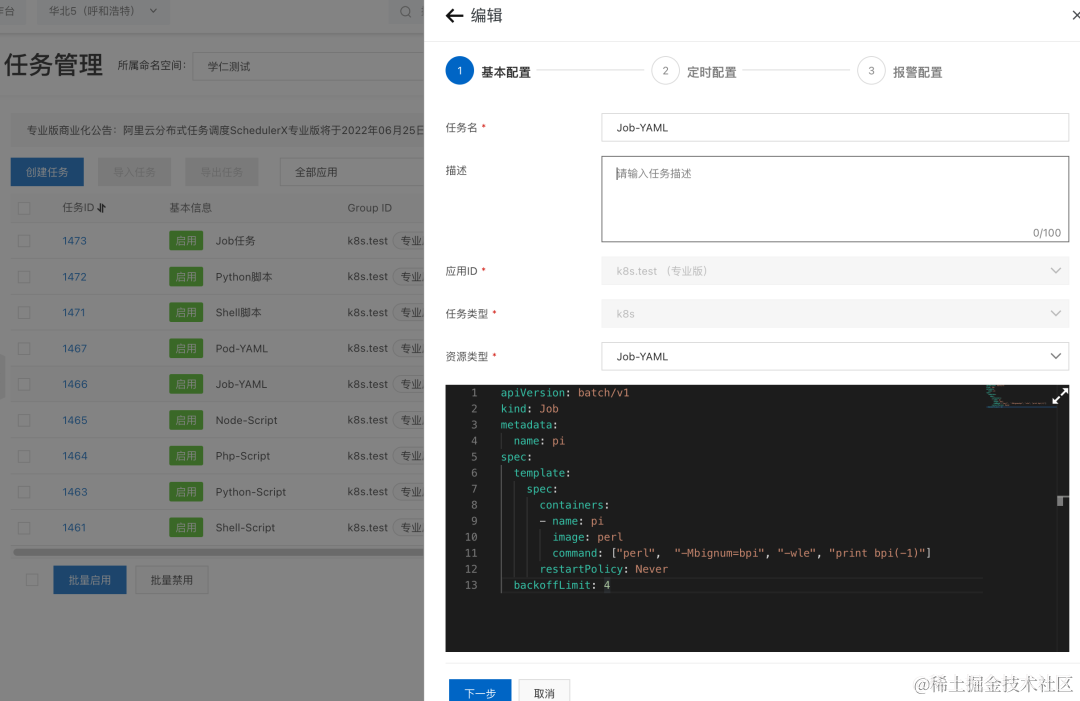
- 通过工具来生成 cron 表达式,比如每小时第 8 分钟跑
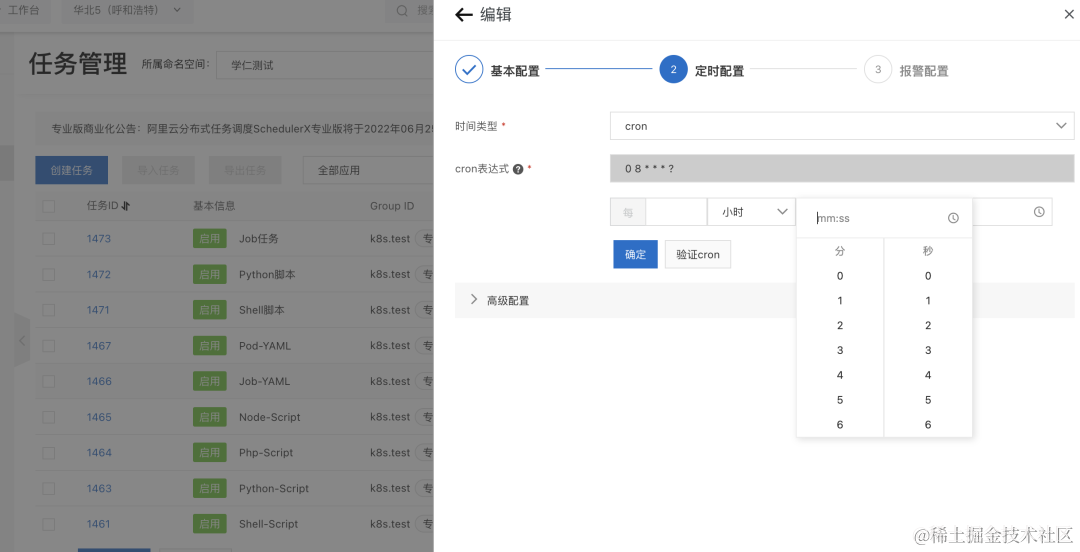
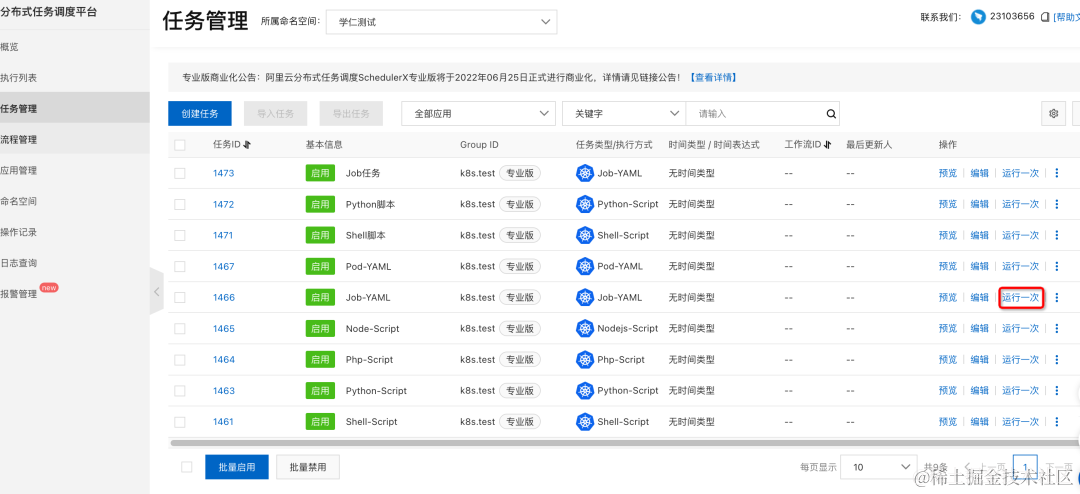
- 调度时间还没到,也可以手动点击“运行一次”来进行测试
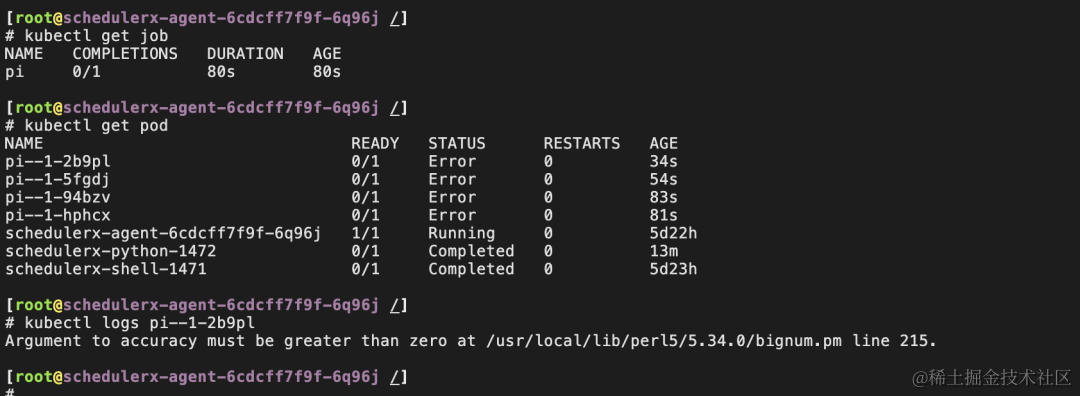
- 在 K8s 集群中可以看到 Job 和 Pod 启动成功,每个任务只会保留最近一次调度的 Pod,减少 K8s 集群的资源占用
- 在 SchedulerX 控制台也可以看到历史执行记录,发现运行失败
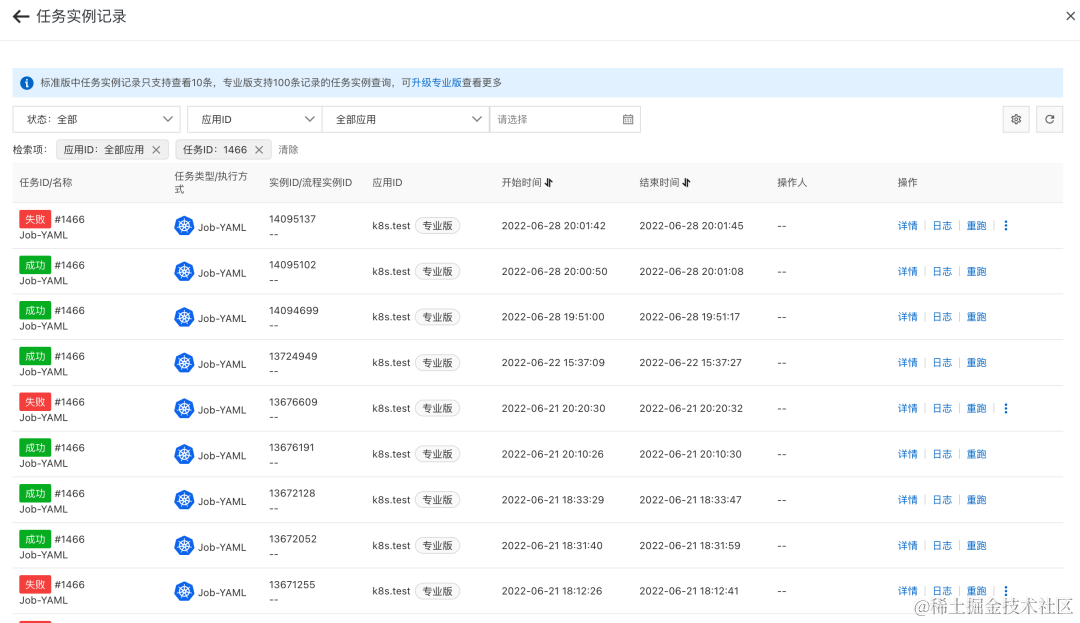
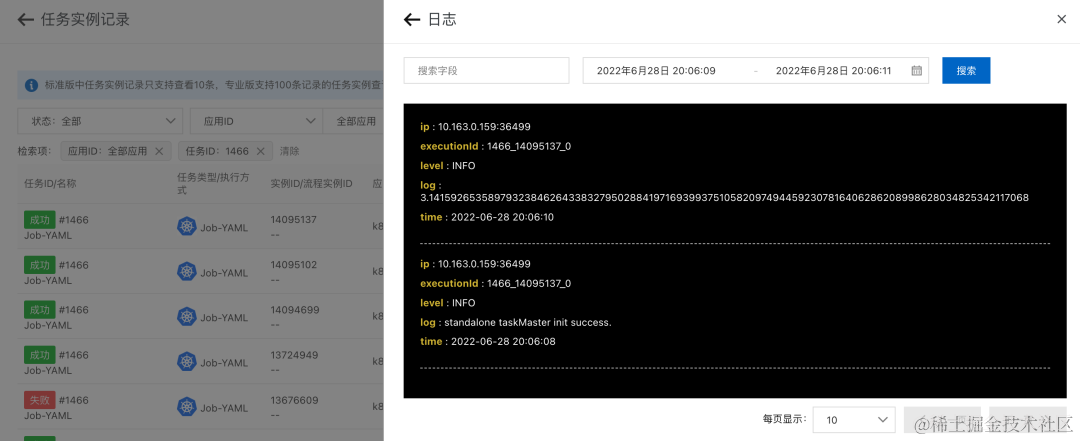
- 在 SchedulerX 控制台可以看到任务运行日志,查看失败原因
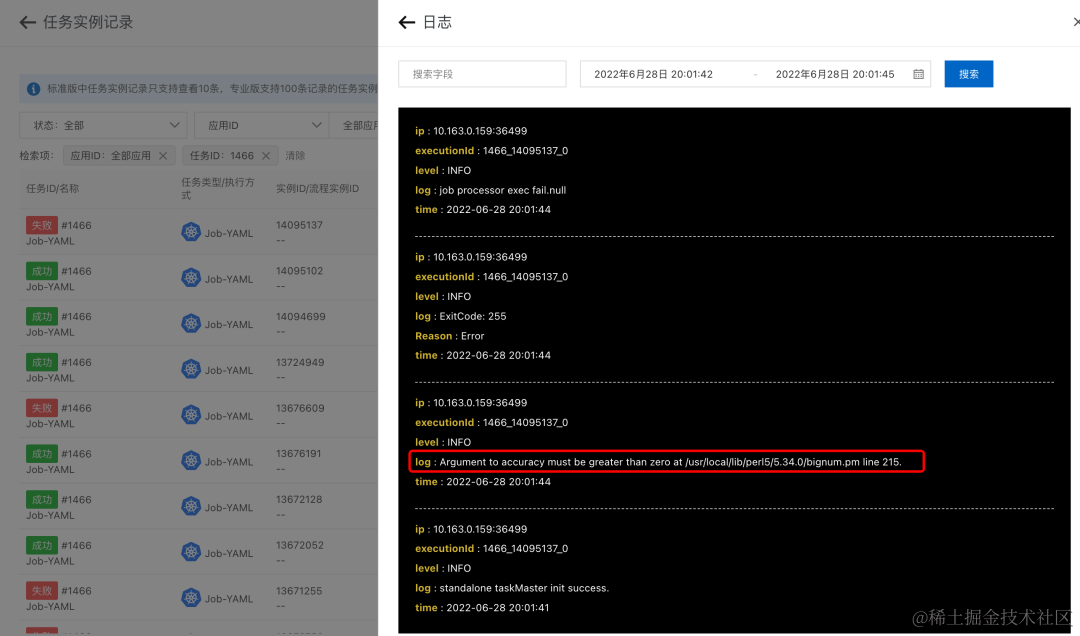
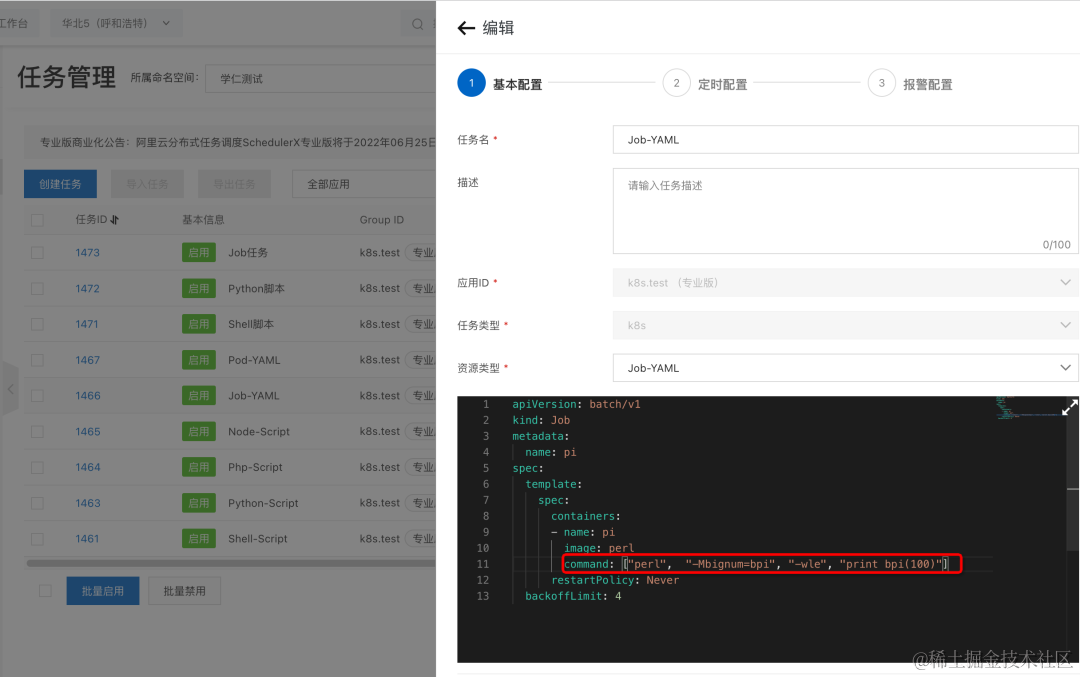
- 在线修改任务的 YAML,打印 bpi(100)
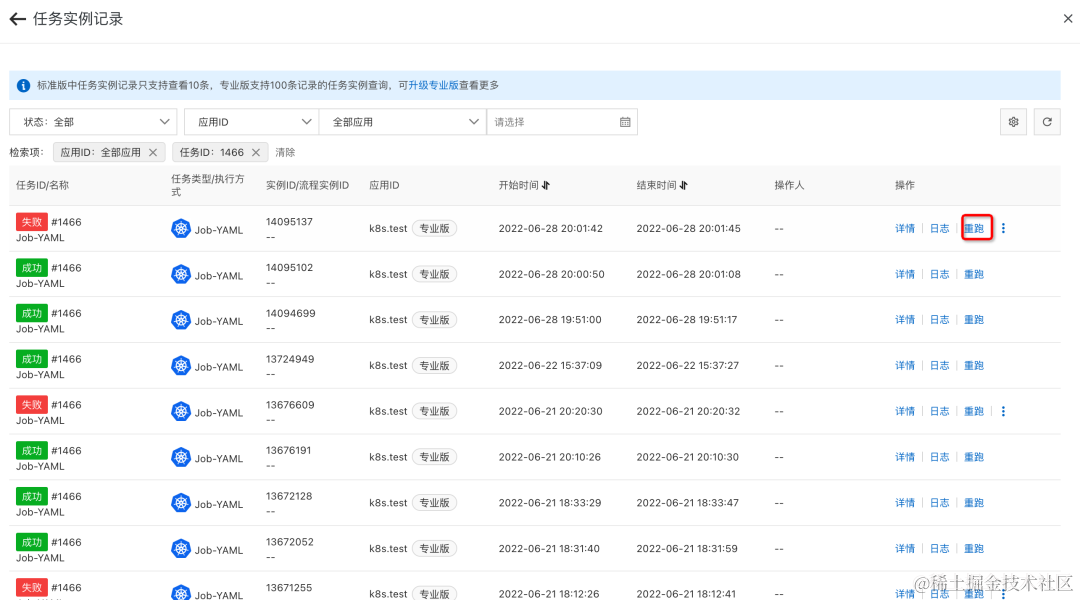
- 不需要删除 Job,通过控制台来重跑任务
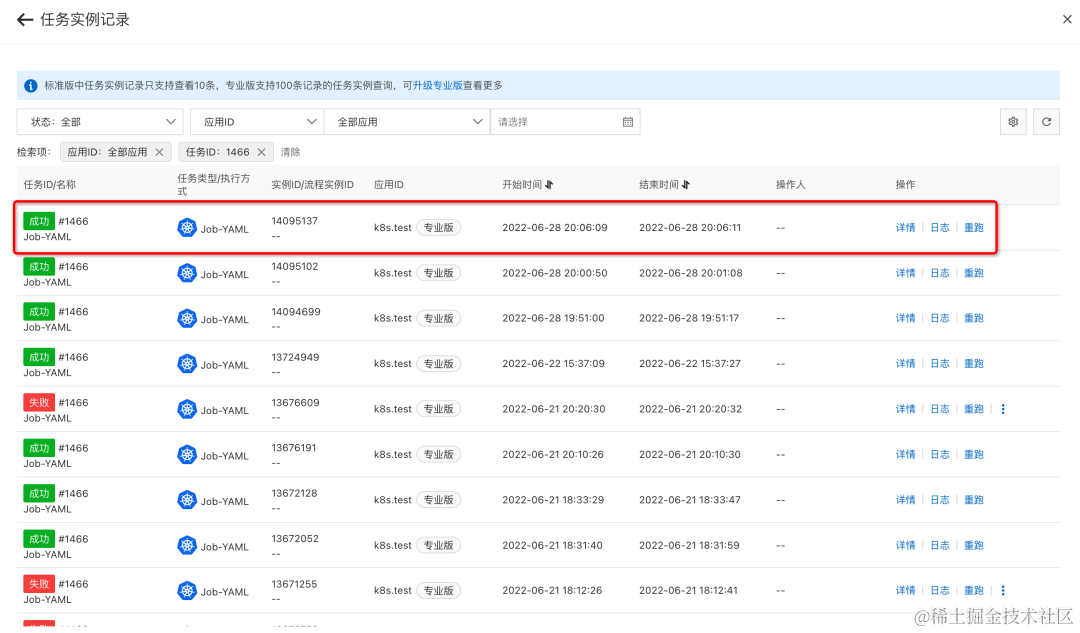
- 任务重跑成功,且能看到新的日志
下面通过一个表格来对比两个方案的差异:
| K8s原生解决方案 | 阿里云解决方案 | |
|---|---|---|
| 手动运行一次 | 不支持 | 支持 |
| 手动重跑任务 | 不支持 | 支持 |
| Cron定时调度 | 支持,YAML配置 | 支持,兼容开源CronJob的YAML,也支持通过控制台动态配置 |
| K8s资源占用 | 高,保留最近3次Pod | 低,仅保留最近1次Pod |
| 历史记录 | 最近3次 | 最近300次 |
| 日志 | 最近3次 | 最近2周,支持搜索 |
| 报警 | 不支持 | 支持,企业级报警通知服务 |
| 操作记录 | 不支持 | 支持 |
总结
在云原生时代,使用 K8s CronJob 在很多场景下可以作为 Linux Crontab 替换的解决方案,解决了crontab的一系列痛点问题。通过阿里云 SchedulerX 来调度你的 K8s CronJob,能够降低学习成本,加快开发效率,让你的任务失败可报警,出问题可排查, 打造云原生可观测体系下的定时任务。
![[Linux] MySQL数据库的备份与恢复](https://img-blog.csdnimg.cn/direct/1be5bfa02e6a4043a50643cd5ff816d7.png)