1.2 SparkStreaming实时处理入门
1.2.1 工程创建
导入maven依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.12</artifactId><version>3.1.2</version>
</dependency>
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.1.2</version></dependency>1.2.2 入口类StreamingContext
SparkStreaming中的入口类,称之为StreamingContext,但是底层还是得需要依赖SparkContext。
object SparkStreamingWordCountOps {def main(args: Array[String]): Unit = {/*StreamingContext的初始化,需要至少两个参数,SparkConf和BatchDurationSparkConf不用多说batchDuration:提交两次作业之间的时间间隔,每次会提交一个DStream,将数据转化batch--->RDD所以说:sparkStreaming的计算,就是每隔多长时间计算一次数据*/val conf = new SparkConf().setAppName("SparkStreamingWordCount").setMaster("local[*]")val duration = Seconds(2)val ssc = new StreamingContext(conf, duration) //批次
//业务//为了执行的流式计算,必须要调用start来启动ssc.start()//为了不至于start启动程序结束,必须要调用awaitTermination方法等待程序业务完成之后调用stop方法结束程序,或者异常ssc.awaitTermination()}
}
1.2.3 业务编写
SparkStreaming是一个流式计算的计算引擎,那么 就模拟一个对流式数据进行单词统计

代码实现
package com.qianfeng.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Durations, StreamingContext}
/*** sparkStreaming的流程序*/
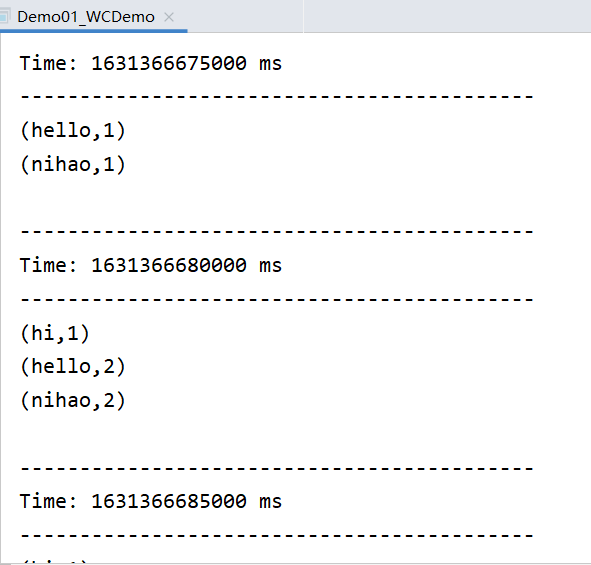
object Demo01_SparkStreaming_WC {def main(args: Array[String]): Unit = {//1、获取streamingcontextval conf = new SparkConf().setAppName("streaming wc").setMaster("local[*]")val sc = new StreamingContext(conf, Durations.seconds(2)) //微批次微2s//2、初始化数据val ds = sc.socketTextStream("qianfeng01", 6666)//3、对数据进行操作val sumDS = ds.flatMap(_.split(" "))#判断H开头 5位.filter(x=>x.startsWith("H") && x.length == 5).map((_, 1)).reduceByKey(_ + _)//4、对数据做输出sumDS.print()
//5、开启scsc.start()//6、等待结束 --- 实时不能停止sc.awaitTermination()}
}
使用netcat进行测试(如果没有请先安装,有则忽略如下)
需要在任意一台节点上安装工具:
[root@qianfeng01 home]# yum install -y nc
启动监听端口:
[root@qianfeng01 home]# nc -lk 6666 hello nihao nihao hello hi hello nihao
Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客